[2022-09-12]神经网络与深度学习第1章-regression
contents
- regression
-
- 写在开头
- 前期准备
- 线性回归
-
- 数据集构建
- 模型构建
- 损失函数
- 模型优化
-
- 经验风险最小化
- 优化函数
- 模型训练
- 模型评估
- 样本数量 & 正则化系数
- 多项式回归
-
- 数据集构建
- 模型构建
- 模型训练
- 模型评估
-
- 使用均方误差评估
- 多项式回归(以sin函数为例)
- 自定义Runner类
- 基于线性回归的波士顿房价预测
-
- 数据处理
-
- 准备工作
- 数据清洗
- 数据集划分
- 模型构建
- 完善Runner类
- 模型训练
- 模型测试
- 模型预测
- 其他问题
- 写在最后
regression
写在开头
回归是指研究一组随机变量和另一组变量之间关系的统计分析方法,又称多重回归分析。在机器学习课程中,我们已经初步了解了线性回归,即使用一个线性模型(一个通过属性的线性组合来进行预测的函数,一般写为 f ( x ) = x A T + b f(x)=xA^T+b f(x)=xAT+b)尽可能准确地预测实值输出标记。通过使用pytorch实现线性回归,我们将
- 熟悉pytorch框架的开发方式
- 熟悉线性回归、多项式回归
- 了解构建数据集的方法和数据的转化
- 了解损失函数、模型优化、模型训练
- 了解模型评估的基本方法
- 了解数据处理的正则化及其对模型性能的影响
- 熟悉Runner类及其基本使用方式
- 实际数据处理应用
前期准备
本实验使用Jupyter Notebook,事先引用以下库:
import torch
import numpy as np
import matplotlib.pyplot as plt
线性回归
数据集构建
回归的数据集中所有的离散点,其分布需要近似为线性函数,因此需要我们设置好一个现存的线性函数作为基础,在此之上添加噪声,由此构建数据集的代码如下(以一元线性函数 f ( x ) = 114 x + 514 f(x)=114x + 514 f(x)=114x+514为例),生成150个带噪音的样本:
eps = torch.normal(0.,0.1,size=(150,2)) # 服从N(0,0.01) 的随机噪声
x = torch.hstack((torch.randn(150,1),torch.ones(150).reshape(-1,1))) # 随机的150个二元值
w = torch.Tensor([[114,514]]) # 系数矩阵
y = torch.mm(w,x.T).reshape(-1,1) # 计算y并进行计算得到函数值
dataset = torch.hstack(((x[:,0] + eps[:,0]).reshape(-1,1),y + eps[:,1])) # 构建数据集
plt.scatter(dataset[:,0],dataset[:,1])
得到150个线性函数分布的离散点:
![[2022-09-12]神经网络与深度学习第1章-regression_第1张图片](http://img.e-com-net.com/image/info8/10897010f75f411f82745c4adcf8522e.jpg)
接下来进行训练集和测试集的划分,由于已经是随机的乱序点,不需要进行shuffle操作:
dataset_train, dataset_test = dataset[:100],dataset[-50:]
p_tr = plt.scatter(dataset_train[:,0],dataset_train[:,1],c='r')
p_te = plt.scatter(dataset_test[:,0],dataset_test[:,1],c='g')
plt.legend((p_tr,p_te),('train','test'))
数据点可视化分布如下:
![[2022-09-12]神经网络与深度学习第1章-regression_第2张图片](http://img.e-com-net.com/image/info8/dbe9d61d92f048f2a48389a28e7c44e1.jpg)
模型构建
显而易见,模型参数由一个系数、一个常数项构成,输出为一个值,这边可以使用torch.nn.Linear。由此可得pytorch模型构成如下(两种形式等价):
class Func(torch.nn.Module):
def __init__(self):
super(Func,self).__init__()
self.linear = torch.tensor(torch.randn(1),requires_grad=True)
self.b = torch.tensor(torch.randn(1),requires_grad=True)
def forward(self,x):
return torch.mm(x,self.linear.T) + self.b
或
class Func(torch.nn.Module):
def __init__(self):
super(Func,self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
return self.linear(x)
注意,第一种代码需要手动添加追踪变量并重写parameters函数。
传送门:torch.nn.Linear
损失函数
线性回归中常用均方误差(mean squad error,MSE)来计算损失,其公式非常简单:
m s e ( y ; y ^ ) = 1 M ∑ i = 1 M ( y − y ^ ) 2 mse(y;\hat{y}) = \frac{1}{M}\sum_{i=1}^{M}(y-\hat{y})^2 mse(y;y^)=M1i=1∑M(y−y^)2
在实际使用中,我们使用torch.nn.MSELoss即可。下面两种代码均可:
def loss_func(y,y_hat):
M = y.size()[0]
tsum = 0.
for i in range(M):
tsum += (y[i] - y_hat[i]) ** 2
return (1./M) * tsum
或
loss_func = torch.nn.MSELoss()
- 代码实现中没有除2。思考:这样合理么?
答: 合理。均方误差除以2作用是在模型优化时,消除因为计算均方误差中平方的梯度时存在的2倍系数,不除以2依然能够在后续优化时正确计算。
模型优化
经验风险最小化
经验风险最小化(empirical risk minimization,ERM)是统计学理论中的一个原则,其认为经验风险最小的模型是最优的模型,即
min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( x i ) ) \min_{f∈F}\frac{1}{N}\sum_{i=1}^{N}L(y_i,f(x_i)) f∈FminN1i=1∑NL(yi,f(xi))
由公式显然可知,样本容量足够大时,经验风险最小化能够保证有很好的学习效果,但是样本容量过小时,容易导致过拟合。
模型训练的循环,本质就是通过上述的经验风险最小化来训练模型。
- 经验风险最小化为了简单起见省略均方误差的系数 1 N \frac{1}{N} N1,为什么不影响效果?
答: 在优化模型求梯度时,去除 1 N \frac{1}{N} N1只是在原来梯度的基础上减少了一个系数,而且由于有学习率这个非常小的值存在,省略 1 N \frac{1}{N} N1对模型来说没有影响,梯度下降最终还是会达到局部最优解。 - 什么是最小二乘法?
答: 最小二乘法是用于优化损失的方法。是一种数学优化技术。通过最小化离差寻找最佳的函数匹配。过程如下:- 1.由模型初始的预测值和真实值得到数据的离差:
L ( y , y ^ ) = ∑ i = 1 M ( y i − y i ^ ) 2 L(y,\hat{y}) = \sum_{i=1}^{M}(y_i-\hat{y_i})^2 L(y,y^)=i=1∑M(yi−yi^)2 - 2.对线性函数中的每个系数求偏导,令其为0得到新的系数矩阵。
可以发现,最小二乘法和梯度下降法比较相似,都使用梯度进行优化,不同的是梯度下降法需要学习率且需要多次迭代才能达到最优值,最小二乘法则比较快;另外,最小二乘法显而易见具有较高时间复杂度、以及收敛点不一定时最优值,如果不是线性模型,我们最好还是不要使用最小二乘法。
- 1.由模型初始的预测值和真实值得到数据的离差:
优化函数
对于误差的优化,我们采用随机梯度下降(stochastic gradient descent,SGD),每一个数据计算一次损失函数后使用梯度更新参数,公式如下:
θ i = W i − 1 − η ∇ f θ ( θ i − 1 ) \theta_{i}=W_{i-1}-\eta\nabla f_{\theta}(\theta_{i-1}) θi=Wi−1−η∇fθ(θi−1)
这里我们不展开描述,直接使用torch自带的SGD定义优化函数。注意,使用前需要实例化线性模型类。
func = Func()
optimizer = torch.optim.SGD(func.parameters(),0.01)
# 将参数加入梯度监控表中便于计算梯度,学习率设置为0.01
模型训练
经过前面的铺垫,我们只需要循环进行参数优化即可。代码如下:
EPOCHS = 800
for i in range(EPOCHS):
y = func(dataset_train[:,0].reshape(-1,1))
loss = loss_func(y,dataset_train[:,1].reshape(-1,1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0 or i + 1 == EPOCHS:
print('epoch {} / {} : MSE Loss = {}'.format(i+1,EPOCHS,loss))
结果如下:
![[2022-09-12]神经网络与深度学习第1章-regression_第3张图片](http://img.e-com-net.com/image/info8/097cb3bcda51495f8d69705c5829cc1d.jpg)
在训练完成后,我们能够得到所需的相关系数和偏置值:
print('f(x) = {:.2f}x + {:.2f}'.format(float(func.linear.weight[0,0]),float(func.linear.bias[0])))
结果如下,和原函数非常接近:
![]()
模型评估
使用预测好的模型在测试集上运行,得到结果。
代码如下:
ys = func(dataset_test[:,0].reshape(-1,1))
loss = loss_func(y,dataset_train[:,1].reshape(-1,1))
print('loss={}'.format(float(loss)))
p_te = plt.scatter(dataset_test[:,0],dataset_test[:,1],c='g')
p_pr = plt.scatter(dataset_test[:,0],ys.detach(),c='b')
plt.legend((p_te,p_pr),('actual','pred'))
输出和图像如下:
![[2022-09-12]神经网络与深度学习第1章-regression_第4张图片](http://img.e-com-net.com/image/info8/15cbf69f042d4806839eb6aa94524bc6.jpg)
可见线性回归达到了一个比较好的效果,但是如果线性模型比较简单,且受到噪声影响,则效果优势不明显。
样本数量 & 正则化系数
- 调整训练数据的样本数量,由100调整到5000,观察对模型性能的影响。
将前面的代码修改数量,得到如下结果:
![[2022-09-12]神经网络与深度学习第1章-regression_第5张图片](http://img.e-com-net.com/image/info8/2ed4c6a91bc948448880451d5dda41f2.jpg)
新的数据集分布
![[2022-09-12]神经网络与深度学习第1章-regression_第6张图片](http://img.e-com-net.com/image/info8/5598c79d639f4ce7bb1daa6a7e43f977.jpg)
新的训练输出和最终函数
![[2022-09-12]神经网络与深度学习第1章-regression_第7张图片](http://img.e-com-net.com/image/info8/5e0942083cc346538b590d089950e02d.jpg)
新的测试集结果和测试集上的损失
- 调整正则化系数,观察对模型性能的影响。
正则化是为了降低过拟合风险而加入的一种计算方式,一般有L1和L2正则化。由于 L1 正则化最后得到 w 向量中将存在大量的 0,使模型变得稀疏化,因此 L2 正则化更加常用。其定义为:
W = W − α ( ∂ L ∂ w + λ m W ) W = W - \alpha(\frac{\partial L}{\partial w}+\frac{\lambda}{m}W) W=W−α(∂w∂L+mλW)
也称之为权重衰减(weights decay)
修改代码权重衰减需要在优化器中进行设置,修改的代码如下:
optimizer = torch.optim.SGD(func.parameters(),0.01,weight_decay=0.1)
分别尝试0.1,0.01和0.001进行测试,结果如下:
![[2022-09-12]神经网络与深度学习第1章-regression_第8张图片](http://img.e-com-net.com/image/info8/a8da05bb6494455489175d31867f4835.jpg)
weights_decay=0.1
![[2022-09-12]神经网络与深度学习第1章-regression_第9张图片](http://img.e-com-net.com/image/info8/1e9f68b33fb0425c90d5d5b7ef50a365.jpg)
weights_decay=0.01
![[2022-09-12]神经网络与深度学习第1章-regression_第10张图片](http://img.e-com-net.com/image/info8/577cbf35efa74197929075a9221835f8.jpg)
weights_decay=0.001
在线性回归中,随着正则化系数不断变小,损失越来越小。
多项式回归
多项式不同于前面的线性回归,其定义式存在高次项:
f ( x ; w ) = w 1 x + w 2 x 2 + ⋯ + w M x M + b = w T ϕ ( x ) + b f(x;w)=w_1x+w_2x^2+\dots+w_Mx^M+b =w^T\phi(x) + b f(x;w)=w1x+w2x2+⋯+wMxM+b=wTϕ(x)+b
数据集构建
数据集构建方法和前面比较类似,再次不多赘述,代码如下:
import torch
import numpy as np
import matplotlib.pyplot as plt
eps = torch.randn(25,2) * 0.01 # torch.randn 为方差1的高斯噪声
xs = torch.rand(25,1).reshape(-1,1)
xs = torch.hstack((xs,xs ** 2,xs ** 3)) # 定义每项次数
w = torch.tensor([[11.,45.,14.]]).reshape(-1,1)
ys = torch.matmul(xs,w) + 191
dataset = torch.hstack((xs,ys)) # 保存x,x^2,x^3用于后面使用nn.Linear,拟合每个次数前的系数w
dataset_train,dataset_test = dataset[:15],dataset[-10:]
p_tr = plt.scatter(dataset_train[:,0],dataset_train[:,-1],c='r')
p_te = plt.scatter(dataset_test[:,0],dataset_test[:,-1],c='g')
plt.legend((p_tr,p_te),('train','test'))
结果如下:
![[2022-09-12]神经网络与深度学习第1章-regression_第11张图片](http://img.e-com-net.com/image/info8/b974307a9b6f4f20b4d149730ccfb495.jpg)
模型构建
基于预处理好的输入数据,可以直接使用nn.Linear,因为:
原本的nn.Linear(M,1)为
f ( x ) = ∑ i = 1 M w i x i + b f(x)=\sum_{i=1}^{M}w_ix_i +b f(x)=i=1∑Mwixi+b
经过预处理,公式更新为:
f ( x ) = ∑ i = 1 M w i x i + b f(x)=\sum_{i=1}^{M}w_ix^i+b f(x)=i=1∑Mwixi+b
模型定义、损失函数和优化器代码如下:
class PolyFunc(torch.nn.Module):
def __init__(self):
super(PolyFunc,self).__init__()
self.linear = torch.nn.Linear(3,1)
def forward(self,x):
return self.linear(x)
func = PolyFunc()
loss_func = torch.nn.MSELoss()
optimizer = torch.optim.SGD(func.parameters(),0.01)
模型训练
类比前面线性模型,很容易得到模型训练的代码:
EPOCHS = 100000
for i in range(EPOCHS):
y = func(dataset_train[:,:-1])
loss = loss_func(y,dataset_train[:,-1].reshape(-1,1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 10000 == 0 or i + 1 == EPOCHS:
print('epoch {} / {} : MSE Loss = {}'.format(i+1,EPOCHS,loss))
print('f(x) = {}x + {}x^2 + {}x^3 + {}'.format(
float(func.linear.weight[0,0]),
float(func.linear.weight[0,1]),
float(func.linear.weight[0,2]),
float(func.linear.bias[0])
))
输出:![[2022-09-12]神经网络与深度学习第1章-regression_第12张图片](http://img.e-com-net.com/image/info8/4838ff021d89404d868372e51bd684c9.jpg)
模型评估
使用均方误差评估
训练时误差已经体现,下面代码用于体现测试时的误差:
ys = func(dataset_test[:,:-1])
loss = loss_func(y,dataset_train[:,-1].reshape(-1,1))
print('loss={}'.format(float(loss)))
p_te = plt.scatter(dataset_test[:,0],dataset_test[:,-1],c='g')
p_pr = plt.scatter(dataset_test[:,0],ys.detach(),c='b')
plt.legend((p_te,p_pr),('actual','pred'))
得到输出:
![[2022-09-12]神经网络与深度学习第1章-regression_第13张图片](http://img.e-com-net.com/image/info8/b40735102a8f4e1faecfc52497f6c4b6.jpg)
多项式回归(以sin函数为例)
该实验内容,因为近似二次函数,将前面代码进行微调即可。这里不再赘述,结果如下:
![[2022-09-12]神经网络与深度学习第1章-regression_第14张图片](http://img.e-com-net.com/image/info8/026e59ef58cf492e808e07df2036c0d3.jpg)
数据集分布
![[2022-09-12]神经网络与深度学习第1章-regression_第15张图片](http://img.e-com-net.com/image/info8/ba20e8ae0a7f4a7fa98e85dcb9aaa158.jpg)
训练结果
![[2022-09-12]神经网络与深度学习第1章-regression_第16张图片](http://img.e-com-net.com/image/info8/c206efac699640d9ae49c45c7a9e33ca.jpg)
测试结果
自定义Runner类
Runner类的成员函数定义如下:
- __init__函数:实例化Runner类,需要传入模型、损失函数、优化器和评价指标等;
- train函数:模型训练,指定模型训练需要的训练集和验证集;
- evaluate函数:通过对训练好的模型进行评价,在验证集或测试集上查看模型训练效果;
- predict函数:选取一条数据对训练好的模型进行预测;
- save_model函数:模型在训练过程和训练结束后需要进行保存;
- load_model函数:调用加载之前保存的模型。
此部分为前面各部分的综合运用,本文仅实现最简单的Runner类。代码经过整理如下:
class Runner():
def __init__(self, model, loss_fn, optimizer,eval=None):
self.model = model
self.loss_fn = loss_fn
self.optimizer = optimizer
if eval is None:
self.eval = loss_fn
else:
self.eval = eval
def train(self,train_x, train_y,epochs):
losses = []
from rich.progress import track
for i in track(range(epochs),description='training...'):
pred = self.model(train_x)
self.loss = self.loss_fn(train_y,pred.reshape(-1,1))
self.optimizer.zero_grad()
self.loss.backward()
self.optimizer.step()
return self.loss
def eval(self,eval_x,eval_y):
pred = self.model(eval_x)
eval_val = self.eval(pred.reshape(-1,1),eval_y)
return eval_val
def predict(self,x):
pred = self.model(x)
return pred
def save_model(self, path):
torch.save(self.model.state_dict(),path)
def load_model(self,path):
self.model = torch.load(path)
该类的使用将在下一部分给出。
基于线性回归的波士顿房价预测
数据处理
准备工作
引入需要使用的库:
import torch
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston # 波士顿房价数据集
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler # 数据归一化处理
from random import shuffle # 用于打乱数据集
数据清洗
首先我们通过sklearn的内置数据集读取波士顿房价数据,检查是否存在缺失值或异常值:
df = load_boston()
dataset = torch.hstack((torch.tensor(df.data),torch.tensor(df.target).reshape(-1,1)))
df = pd.DataFrame(dataset.numpy())
print(df[df.isnull().T.any()])
结果如下:
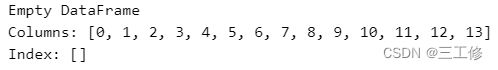
可知数据一切正常。
数据集划分
通过查阅资料可知,波士顿房价数据中,最后一列为房价,前面的内容均为参数,也即data属性为参数,target属性为结果,由此可构建数据集:
df = load_boston()
dataset = torch.hstack((torch.tensor(df.data),torch.tensor(df.target).reshape(-1,1)))
df = pd.DataFrame(dataset.numpy())
print(df[df.isnull().T.any()])
shuffle(dataset)
scaler = MinMaxScaler()
dataset = scaler.fit_transform(dataset) # 归一化处理
dataset_train, dataset_test = torch.tensor(dataset[:-50]),torch.tensor(dataset[-50:]) # 使用前456个数据进行训练,后50个数据用于测试
注意,由于数据范围跨度较大,在训练中可能出现梯度消失的问题,因此需要使用归一化来防止数据过拟合。
模型构建
通过数据集可知,如果使用线性回归,则需要回归12个参数的相关系数和偏置值,由此易得模型定义代码:
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear = torch.nn.Linear(12,1)
def forward(self,x):
return self.linear(x)
完善Runner类
Runner类定义和前面的定义相同,在此不多赘述,下面展示Runner类的初始化过程:
model = Model()
runner = Runner(model,torch.nn.MSELoss(),torch.optim.SGD(model.parameters(),0.01))
模型训练
由于使用Runner类,模型训练非常简单,代码如下:
loss_last = runner.train(dataset_train[:,:-1],dataset_train[:,-1].reshape(-1,1),1000)
print('loss=%f'%float(loss_last))
输出如下:
![[2022-09-12]神经网络与深度学习第1章-regression_第17张图片](http://img.e-com-net.com/image/info8/0919af36354f430ab1936e64a87bd40f.jpg)
模型测试
模型测试使用测试集进行运算,并计算损失:
loss = runner.eval(dataset_test[:,:-1],dataset_test[:,-1].reshape(-1,1))
print('eval loss=%f'%loss)
输出结果如下:
![]()
模型预测
模型预测相对来说比较简单,这里使用整个数据集数据进行测试。代码如下:
plt.plot(dataset[:,-1],label='actual')
plt.plot(runner.predict(dataset[:,:-1]).detach().numpy(),label='pred')
plt.legend()
数据可视化如下:
![[2022-09-12]神经网络与深度学习第1章-regression_第18张图片](http://img.e-com-net.com/image/info8/d6e117c279db492e84954ca8c06a46bf.jpg)
测试集的预测图像如下:
![[2022-09-12]神经网络与深度学习第1章-regression_第19张图片](http://img.e-com-net.com/image/info8/d31504c329384e07900857abbc18ffdd.jpg)
其他问题
- 使用类实现机器学习模型的基本要素有什么优点?
答: 优点有①集成度高,封装成一个类,简化其他部分的代码;②泛用性好,能够多次复用,比较零活,比如算子等;③便于后期维护,机器学习中常常有一些异常数据,使用类实现在增加兼容性和排除故障方面更加便于使用。 - 算子op、优化器opitimizer放在单独的文件中,主程序在使用时调用该文件。这样做有什么优点?
答: 放在单独的文件夹中,能够更好地针对其功能分门别类,且能够更好地进行复用和功能增减,也可以方便后期开发时针对功能进行技术文档的编辑。 - 线性回归通常使用平方损失函数,能否使用交叉熵损失函数?为什么?
答: 不能使用交叉熵损失函数。平方损失函数用于计算回归过程中数据的误差离散程度,而交叉熵损失则只聚焦于正确分类的结果;平方误差用于数据拟合,交叉熵适合离散的数据分类。因此不能使用。
写在最后
这次实验我们了解到了回归及其基本方法。回归还有逻辑回归等众多内容等待我们进行学习。本次实验对于项目中代码的复用、封装和面向对象特点的认识均有帮助,也指导我们如何进行数据处理以及如何将回归这一数学概念应用于现实生活。