JavaSE学习笔记-10
集合
数组灵活性不够,所以我们引出了集合。
 集合框架体系图(背下来)
集合框架体系图(背下来)

第一类集合实现继承图:
 第二类集合实现继承图:
第二类集合实现继承图:
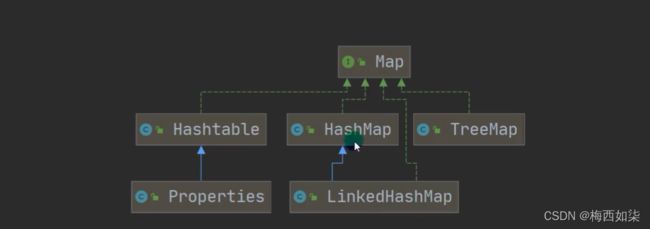
【蓝色实线表示继承类 绿色虚线表示实现接口】
总结:
双列集合就是存放着键值对的元素,即是 Key-Value这样的形式。。。。。
对于单列和双列集合的举例:

对于警告如何抑制?(一劳永逸法)

Collection接口的实现类的特点

接口作为对象引用的类型类似于多态
我们知道接口和抽象类都是不可以被实例化的,但是我们可以new实现接口的实现类

List是接口 ArrayList是实现类。我们可以这样写,
一种类似于多态的形式,我们实例化的时候,只可以对实现类ArrayList进行实例化。在堆空间创建的内存空间也是ArrayList类new出来的对象空间。。。。接口List类型的对象引用list指向这个堆空间中实例化出来的对象
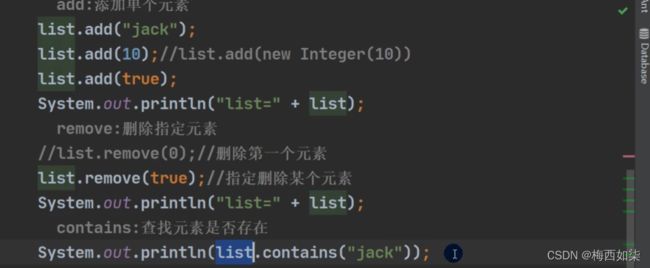

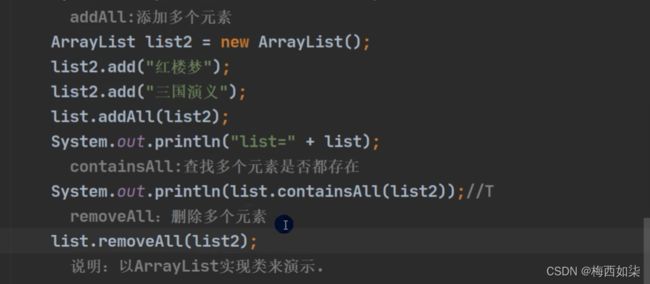
对于addAll,containsAll和removeAll来说,都是对于一个集合进行的增加和删除的。
【图中Collection是一个接口,我们可以把这个接口的实现类(如ArrayList类型的对象引用)传入进去(类似一种多态传参的形式)】



Collection接口是实现Iterable接口的,所以一旦实现了Collection接口,那么必须要实现Iterable接口中的迭代器方法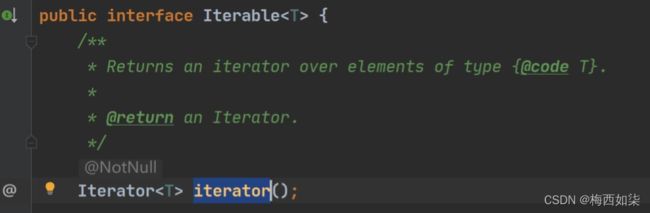
迭代器的执行原理:

对于hasNext方法表示的意思是:判断是否还有下一个元素



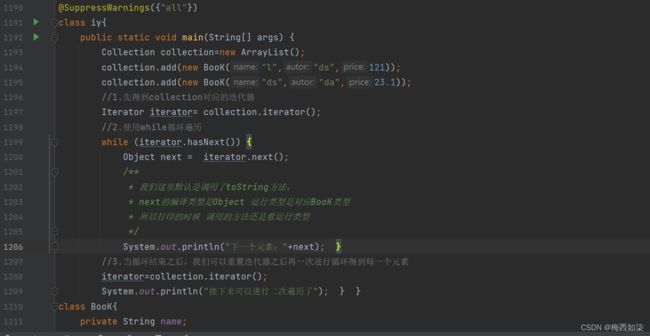 细节:
细节:
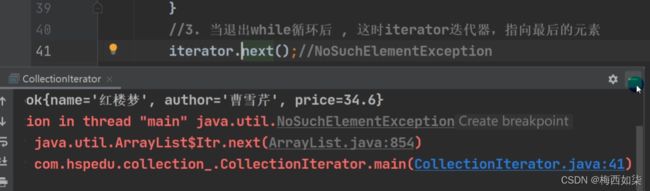
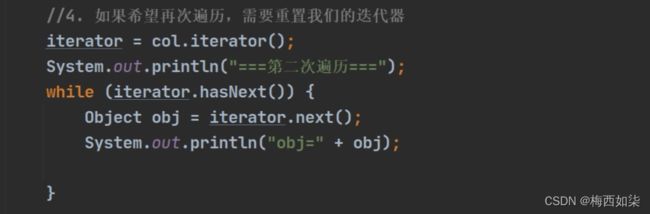 快捷键提示
快捷键提示
 增强for循环
增强for循环

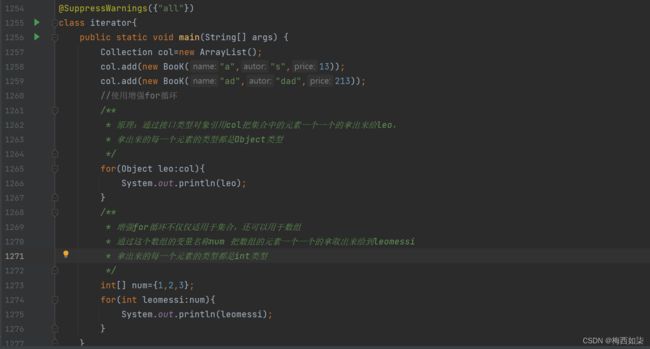
增强for循环底层依旧是迭代器
debug一下:


总结:增强for循环就是一个简化版的迭代器
2022年1月5日,这一天我很开心。我和我最好的兄弟一起玩了一天。
我和晓东认识于2015年,那一年我刚上初一,我到现在还记得刚见他时,他的样子,他拿着一瓶激素功能饮料,喝的还剩一点。第一天上学还没有排座位,我看他旁边没人坐,所以我就坐到了他的旁边。这兄弟一交就是七年,我也不知道下一次见面是什么时候,也许一百天,也许一年,也许两年。。。我也不知道,兄弟祝你一切好运。我是老李,辈子兄弟。后会有期。
2022年1月6日晚


以上都是Collection接口公共拥有的方法,下面会分开讲解List接口和Set接口的实现方法及其细节。
单独讲解List接口
实现List接口的实现类的实例对象中的元素【企业中简称List接口对象的元素】特点 有序可重复,有索引
如图就是List接口对象的创建:

1.
List集合类中元素是有序的
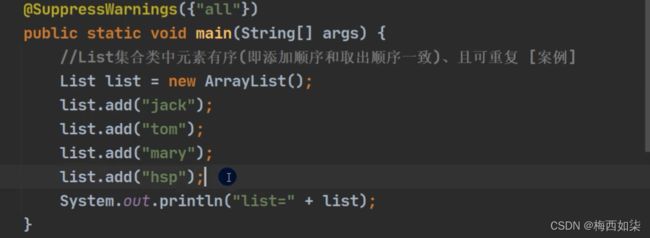
并且元素是可重复的

2.
 3.实现List接口的实现类挺多的
3.实现List接口的实现类挺多的

List接口常用方法



 实现set替换的时候,那个索引坐标必须是存在的,不可以是越界或者不存在的下标
实现set替换的时候,那个索引坐标必须是存在的,不可以是越界或者不存在的下标

返回左闭右开区间的子集合
 List对应练习
List对应练习

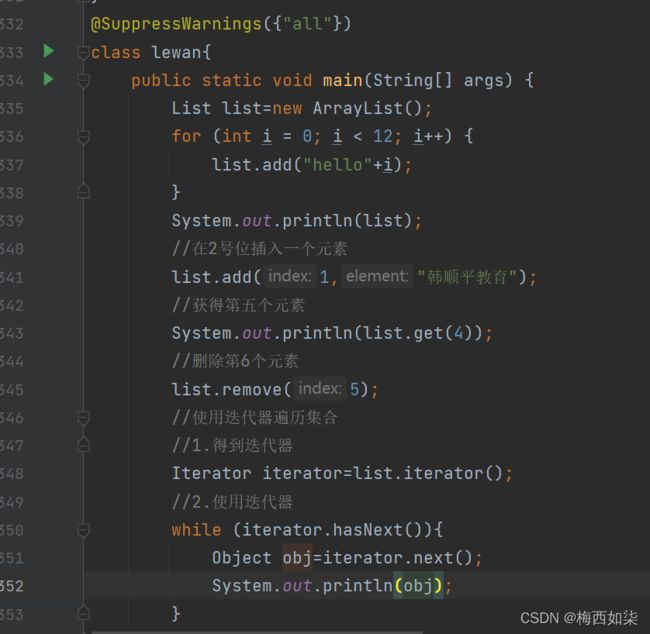
List的三种遍历方式



ArrayList底层源码(重点)

transient:

————————————————



标注:DEFAULT_CAPACITY==10

自己再追踪一遍集合add的操作:
追踪ArrayList集合调用无参构造器时,add方法的源码:
1.对于集合add的操作,我们追踪一下底层的源码

先构建一个Integer对象,先进行装箱操作

2.

3.
 4.
4.
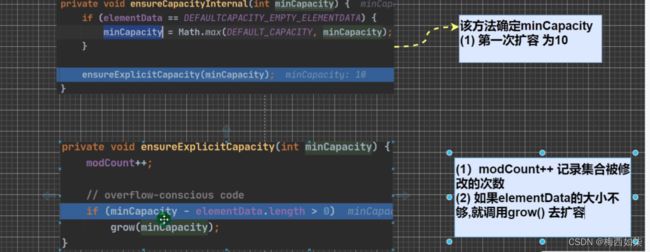
标注:DEFAULT_CAPACITY==10
相等之后再进行取得二者较大值,一开始传进来的时候 minCapacity==1
【一开始为什么二者相等?因为一开始的时候elementData为null,是空的。所以才相等,等以后不是空的时候就不会相等了。】
那么返回较大值肯定是10啊 返回到上一步的结果处

5.
接收上一步的返回值 即是10 -> ensureExplicitCapacity(10)

6.
调用这个方法,modCount表示的意思是对进来确定是否扩容次数的记录
一开始elementData.length==0 那么肯定会执行扩容机制grow

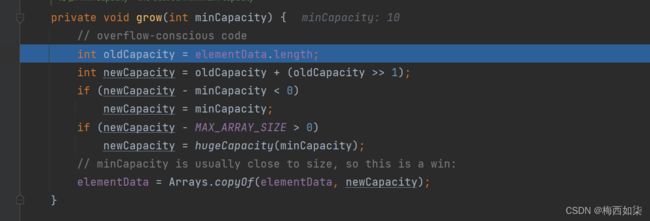
7. 扩容机制核心方法grow
执行扩容机制grow 目的在于更新elementData的大小,当进行第2 3 4次等等的添加的时候,不用每一次都执行扩容操作 ,第一次扩容扩容到10
追踪ArrayList集合调用有参构造器时,add方法的源码:

1.

进行装箱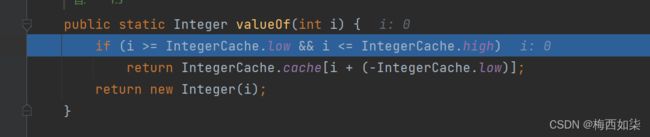
2.
调用有参构造器初始化集合大小为8

3.

4.
 5.
5.
由于这是调用的有参构造器,所以一开始集合是有初始值的,所以一开始它就不相等。
直接跳转到 return minCapacity;
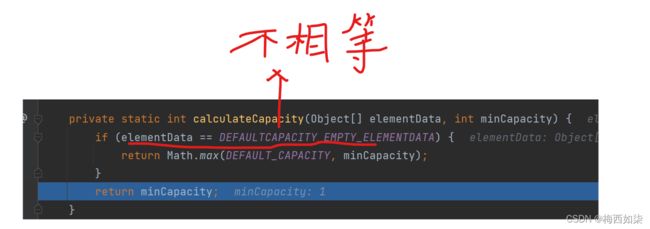 6.
6.

7.
由于这个是带参数的构造器,一开始集合是带大小的。所以执行前8次的时候,直接加到集合中去根本不需要扩容这个操作,直到进行到第八次,我们才需要进行扩容
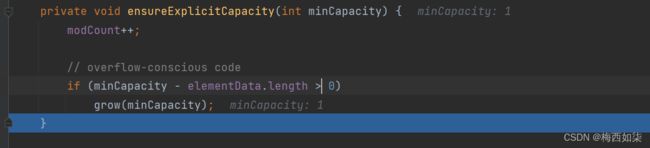
8.
为了看到扩容机制,我们这里使用快捷键F8,一次F8可以快速进行一次for循环的调试

9.

10.
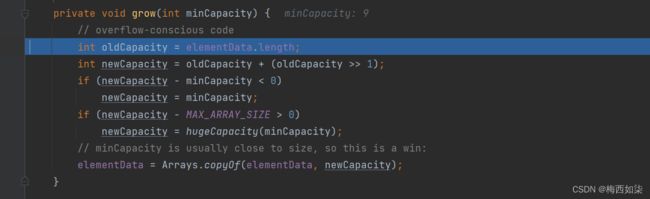
进行Arrays类的扩容机制方法

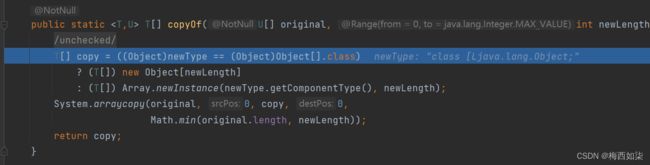
总结:
当我们进行无参构造器初始化的时候,我们需要进入这个地方
去进行初始化它的初值为10
但是如果我们使用的是有参构造器初始化它的初始大小值的时候,我们就可以跳过这一步初始化为10,当大小不够用的时候我们再进行扩容即可。
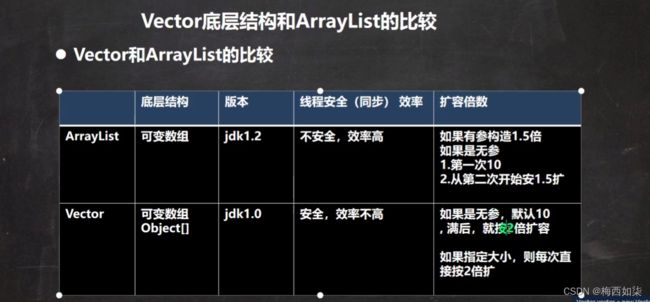
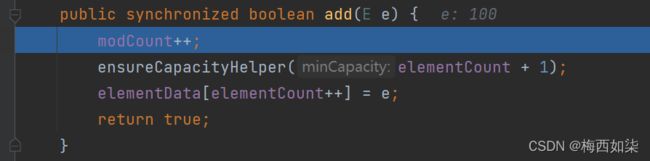
Vector底层结构和源码剖析


这个黄色的字体代表的意思是支持线程同步以及互斥,使线程比较安全


 LinkedList底层结构
LinkedList底层结构

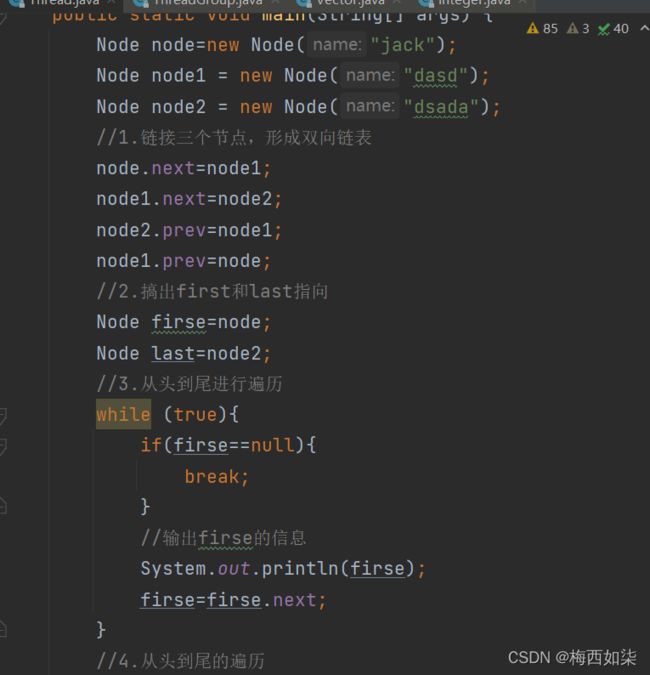
 模拟一个双向列表:
模拟一个双向列表:

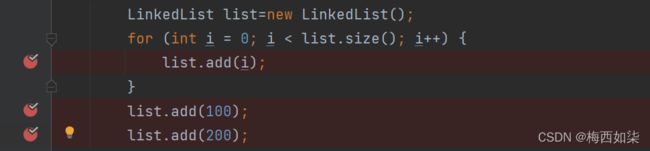
LinkedList中add源码
1.先进行装箱,生成包装类
 2.add方法
2.add方法
3.底层是一个双向链表
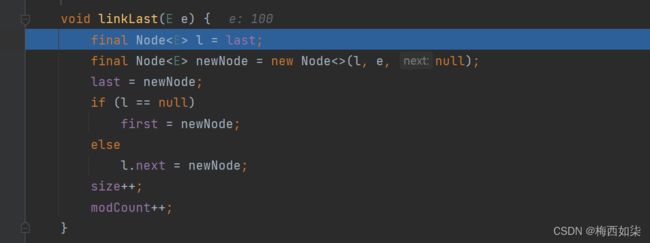 4.进入内部类进行创建节点对象
4.进入内部类进行创建节点对象

5.进行双向链表的连接

增加完100之后,add(100)之后,我们再进行add(200)的操作。
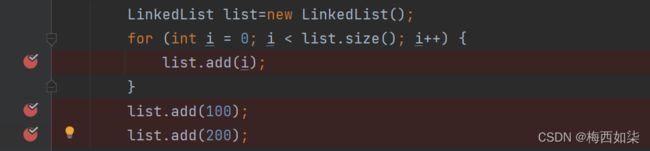
前面的代码都是同理可得的。但是后面的代码发生变化
:
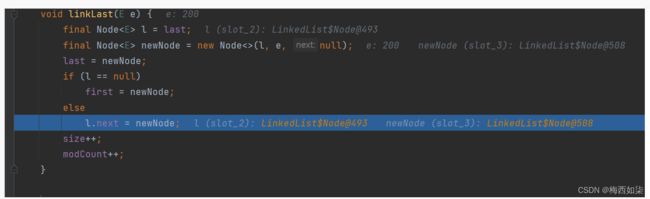 双向链表,两个节点进行链接的操作,自己再演示一遍。。。。
双向链表,两个节点进行链接的操作,自己再演示一遍。。。。
赞不绝口,源码妙哉,妙哉。。。。 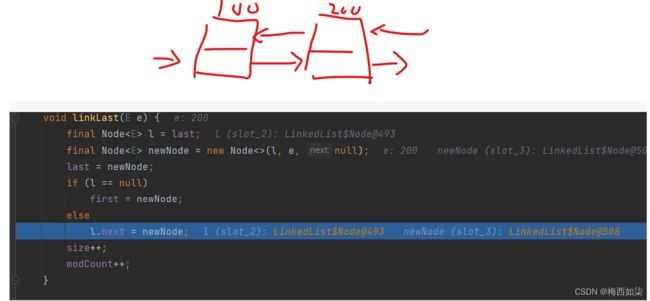
LinkedList中 remove() 源码
1.开始


2.进入删除
 3. f==first
3. f==first
如果f==null,证明双向链表本来就是空的,无法进行删除操作,所以要抛出异常的。
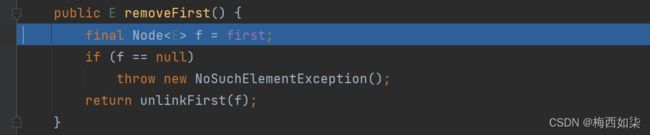 4.
4.
进入 unlinkFirst这个方法,
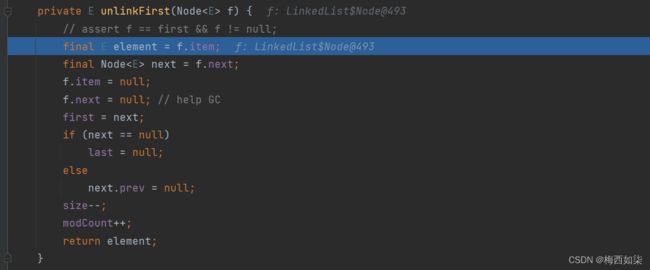
我们前面执行了add(100)和add(200),所以这里remove()操作默认是删除100这个节点

执行完删除之后再一层层的进行返回即可


ArrayList和LinkedList的比较以及该如何选择 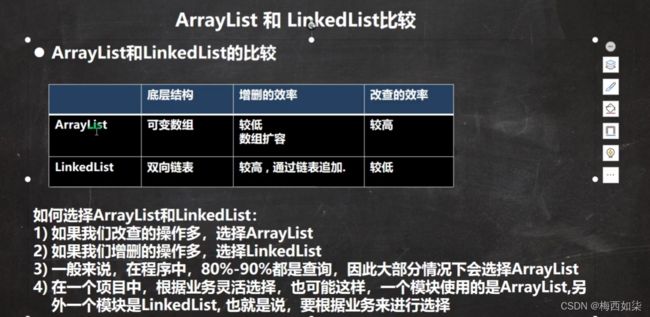
还有就是记住一点,这两者都是属于线程不安全的,所以我们进行选择的场景一般都是属于单线程的业务场景,如果是多线程和并发的情况下我们最好慎重使用。
单独讲解Set接口
实现Set接口的实现类的实例对象的元素【企业中简称Set接口对象的元素】特点:无序 无索引 不可重复【和List正好相反】
如图就是Set接口对象的创建:


记住一点:我们不可以使用索引的方式来获取遍历,因为Set接口中的内容元素是无序的
set添加和删除的顺序都是无序的

细节:虽然它的顺序是无序增加和删除的,但是它的无序顺序排列出来是一个固定顺序的
 使用迭代器和增强for来遍历得出Set集合中的每一个元素
使用迭代器和增强for来遍历得出Set集合中的每一个元素

Set接口实现类之HashSet
Set接口是:无序 不重复 无索引的
HashSet底层是实现HashMap,然而HashMap是实现了红黑树加链表加数组的,在后面会仔细分析这个机制。。。。。
HashSet案例【面试重点】:

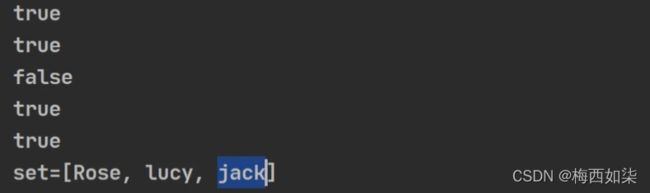
add增加的时候,增加的元素不可以是相互重复的。
remove可以正常删除集合中的对象
输出Set集合中的对象时,是无序的。
难度升级
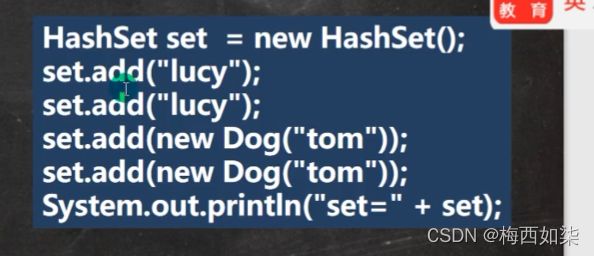
我们重新置空set,之后再进行add添加操作
注意一点:这里虽然 tom的名字是一样的,但是new出来的对象是不一样的,所以都可以添加成功。
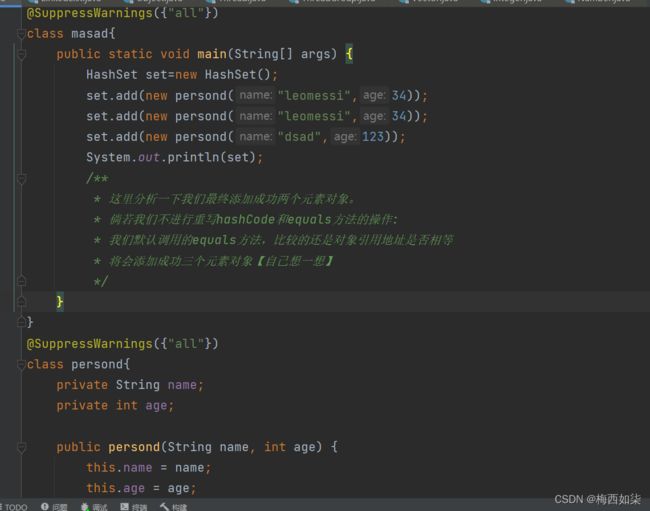
经典面试题:

分析:
因为我在HashSet的底层实现就是HashMap来实现的,我们知道过程【下面会细讲】,一开始我们会根据这个元素得到一个哈希值,我们进行比较如果与table数组中某个元素的哈希值相等,那么再进行equals方法进行比较,如果equals方法得出结果说两个元素对象不相等,那么直接加在这个索引位置形成链表的最后面。如果equals方法得出结果说两个元素对象相等,那么不会再进行添加。。。但是这道题和上道添加Dog类型对象的题的不同之处在于,这题是添加String类型的对象,那么这里new出来两个对象,我们知道String类的equals方法经过重写之后,这两个对象虽然引用地址不相同,但是equals方法返回结果为True。【因为是String类的equals方法,以前笔记中记载过详细过程,不多赘述了】,所以这里不可以再添加。
——————————————————————————
这个题我们要底层源码进行分析一下:
HashSet模拟链表加数组的结构【面试重点】
原因:单纯用数组去处理元素的话,存储取出的效率实在是太低了。所以HashMap底层搞出了这样一套的优化机制


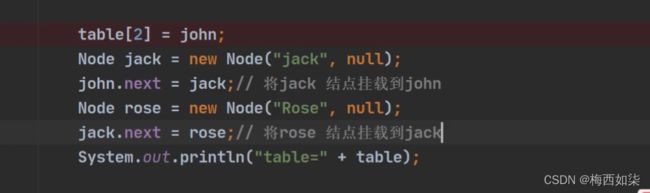
 在索引为2处,已经形成一个链表了
在索引为2处,已经形成一个链表了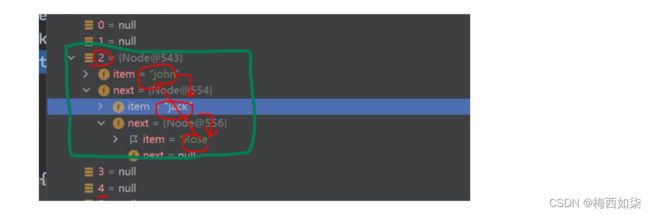
假如说链表的长度达到8之后,且整个table数组的节点数达到64之后。会把这个链表会进行树化,这棵树叫做红黑树
为什么变成红黑树呢?
因为红黑树的效率更高


把lucy挂载到索引3处数组元素处
 链表加数组,使对元素的作用存储效率更高
链表加数组,使对元素的作用存储效率更高
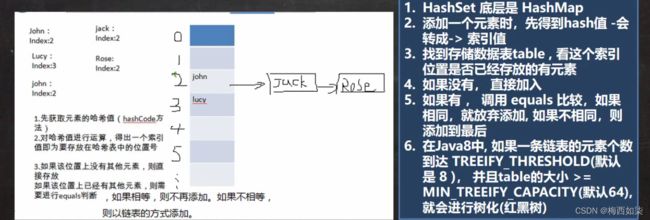
分析HashSet的添加元素底层是如何实现的?【面试重点,难点】
结论:
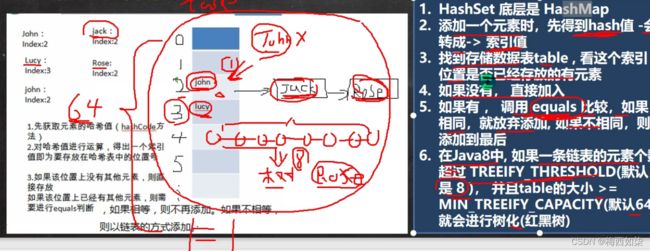
1.HashSet的底层是HashMap,
2.当添加一个元素的时候,先获取元素的哈希值,把哈希值转换为数组的索引值
3.找到存储数据表table,看这个索引位置是否已经存放的有元素
4.如果没有,直接加入
5.如果有,调用equals方法进行比较,如果相同,就放弃添加,如果不相同,则添加到最后。【这样就形成一条链表的模式】
6.在Java8中,如果一条链表上的元素达到8的时候就不再进行添加,如果table数组未达到64个元素,那么继续进行扩容机制【后面会细讲扩容机制】。如果链表上的元素达到8个元素的时候并且table数组达到64个元素的时候,才会开始进行树化【形成红黑树】。


哈希值不是hashCode()方法得到的值【面试重点】
它会在底层进行一个异或^操作,这样计算得到的值才是哈希值
这个算法作用是:减少进行哈希值计算时可能会发生的哈希冲突【哈希冲突的意思就是不同的key值结果得到的哈希值相同,位于一个索引值,最终发生哈希冲突】
![]()
二进制位左移一位,相当于乘以2
二进制右移一位,相当于除以2
HashSet中add方法底层源码追溯【重点】
即是HashMap底层源码 HashSet底层就是HashMap
我们通常HashSet调用add方法,其实底层还是调用的是put方法
首先我们add第一个元素对象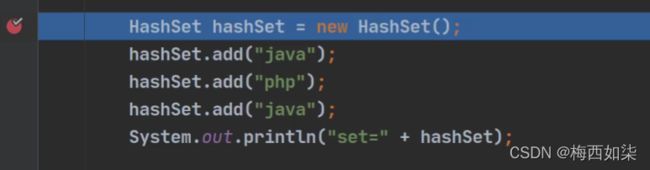



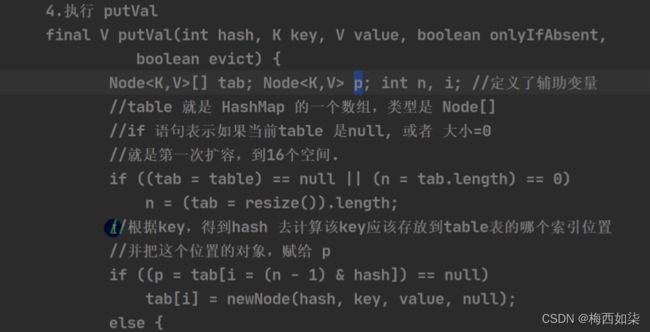
 开始add第二个元素对象
开始add第二个元素对象
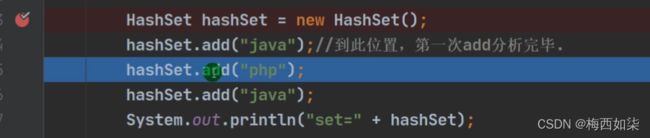
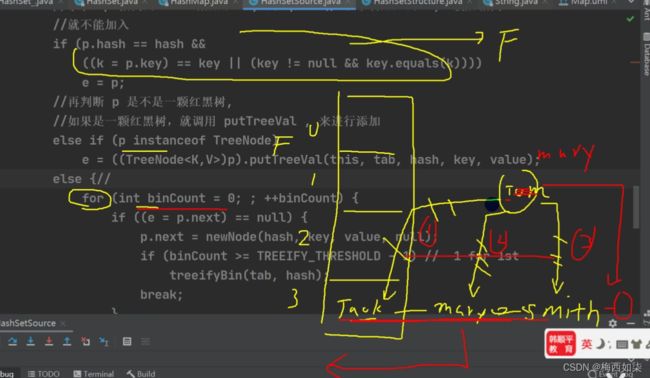
第一句if不为空,那么执行else语句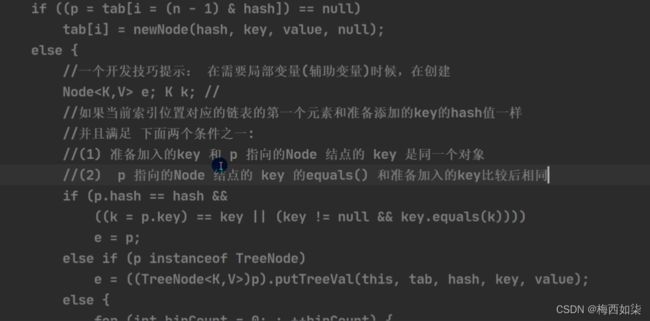


下图三个判断语句:
第一个:先判断哈希值是否相等,相等再判断key值,key值相等则直接退出。key值的判断可以由equals方法【可由程序员重写方法自己制定比较的规则】来判断,也可以直接进行判断。
第二个:else if进入,判断是否是一颗红黑树,如果是则调用对应方法进行添加。
第三个:else 这个else包括两个if
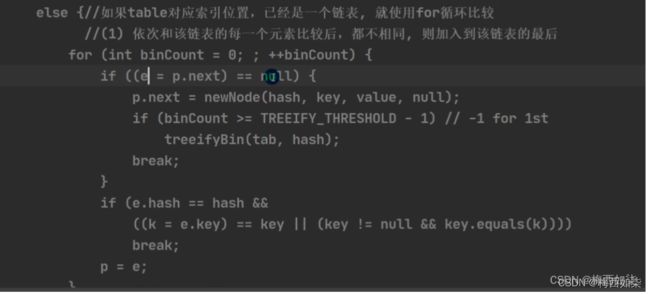
第1个if:这是一个死循环。用e和p着两个变量,不断的变化p【不断地进行p.next】
如果e=p.next==null时,直接把该新节点加在该链表的最后一个。如果链条上的元素个数大于等于8时,要进行红黑树化。
第2个if:就是为了和链条上的对象挨个比较看,是否有一个元素对象的key值与之相等,如果相等,那么直接退出
p=e表示的意思是:重新规定p的指向【自己好好看看即可】
PRESENT:
这个是一个静态的final常量,值是一个Objec对象,是被公共使用的一个值。。。
在这里的作用是为了充当Value值,为了能够底层调用HashMap的put方法。因为put方法必须是要键值对的参数的

HashSet底层扩容机制【面试重点】:

对于第二条进行分析:
我们不可能说非得等到把内存用完之后再进行扩容,假设:如果还剩内存不多,但是短时间内激增多个任务的话,就会导致不安全。
所以当我们到达一个临界值的时候,我们就会进行扩容。这个临界值我们第一次设置为12,扩容到32。这里会乘以一个扩容因子 0.75,32*0.75==24。那么下一次的临界值就是32了,再进行扩容的时候,即是64。64*扩容因子0.75==48,我们把48作为下一次临界值。以此类推进行即可。。。


记住这一点:
分析一道题【面试重点】:

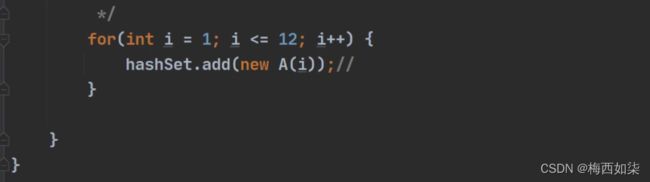
先说结论:
这个for循环调用HashSet的add方法,在一个元素后面形成一个链表,一直加,直到加8个元素,再进行加到数组别的索引位置,直到扩容到table数组为64时,链表上的元素再进行树化【红黑树】。
原因:
HashSet底层还是调用HashMap的,在调用add方法的时候,我们根据前面说添加的底层原理来分析,一开始根据运行时绑定可以调用我们在 A类中重写的hashCode()方法,这样保证每一次for循环得到的元素的哈希值是相等的。但是每一次我们new一个对象,传进去的 i 值是不相等的。等到再进行equals方法比较的时候,每一次比较都是false,所以可以每一次直接添加到该对应链表的最后面。
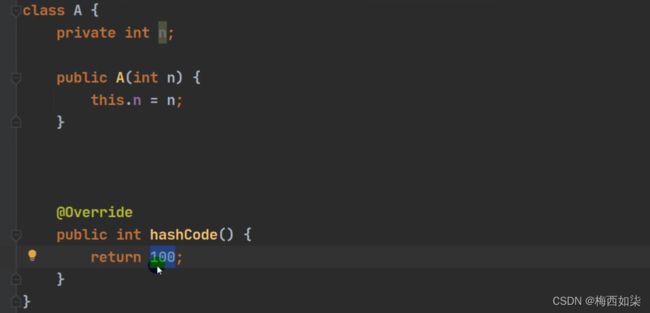
变式上一题
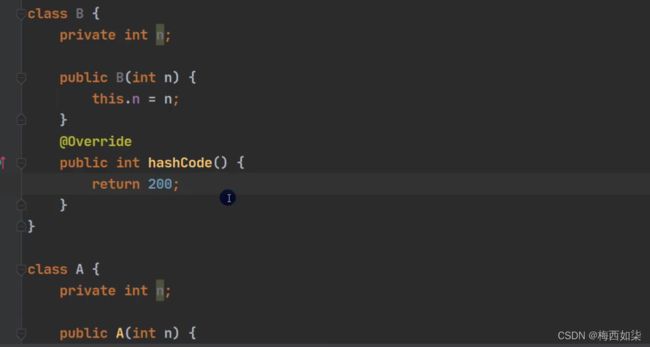
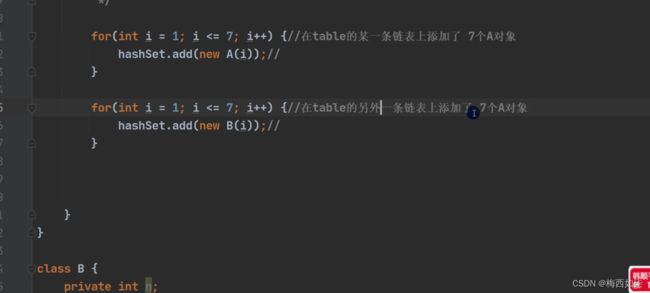 分析:这里我们再一次增加了一个B类,这里我们重写hashCode方法,返回的值是不一样的。所以得到的哈希值是不同的,所以我们添加到数组的索引位置是不同的。因此是在table数组的另外一条链表上添加了7个元素
分析:这里我们再一次增加了一个B类,这里我们重写hashCode方法,返回的值是不一样的。所以得到的哈希值是不同的,所以我们添加到数组的索引位置是不同的。因此是在table数组的另外一条链表上添加了7个元素
HashSet练习

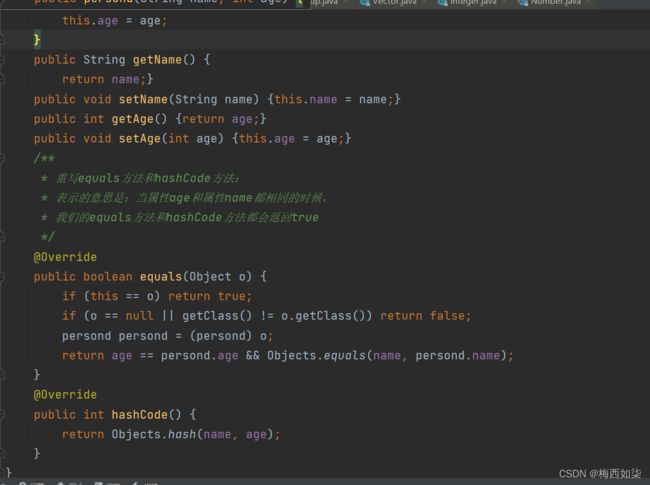
细节:
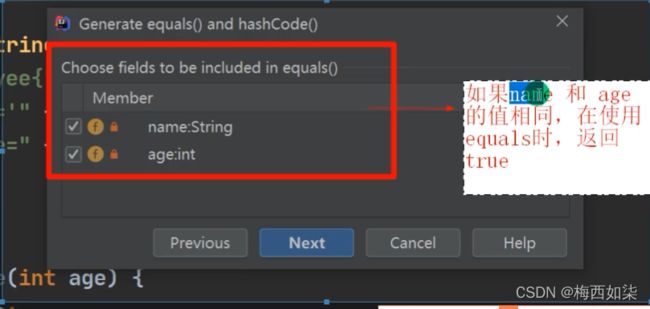
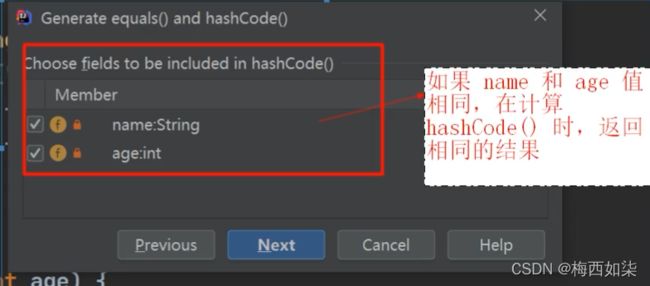

Set接口实现类之LinkedHashSet[LinkedHashSet是HashSet的子类]
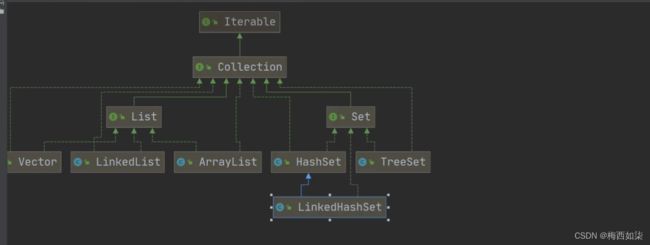


记住一点就是LinkedHashSet底层是双向链表加数组,注意是双向链表。。。。添加的时候的机制和HashSet类似,但是唯一不同之处就在于 LinkedHashSet底层是双向链表来维护的。。。。。
————————————————————————————————————
总结一下HashSet和LinkedHashSet的区别:
HashSet底层是HashMap,是由数组加红黑树加单向链表来维护的。是不可以得到有顺序的,是无序的。
LinkedHashSet底层是LinkedHashMap,是由数组加双向链表来维护的。是可以得到有顺序的,我们得到数组元素时,是带有顺序的。
对于LinkedHashSet添加add是可以有序添加的【如图所示】
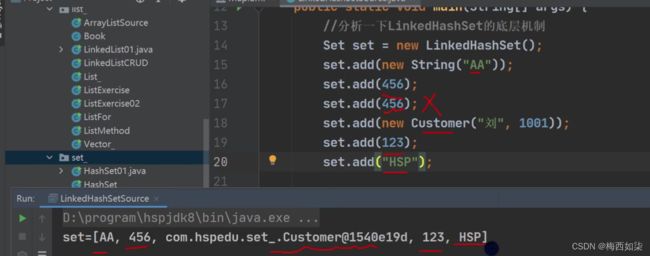
LinkedHashMap是HashMap的子类
LinkedHashSet底层是LinkedHashMap
HashSet底层是HashMap
LinkedHashMap的初始化table数组的大小和HashMap一样,都是16.
但是LinkedHashMap的内部存放的这个类不再是Node,而是Entry。
————————————————————————————————————
为什么table数组【数组是HashMap$Node类型】可以存放LinkedHashMap$Entry类型的元素呢?
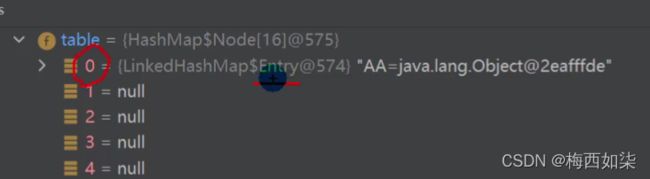
LinkedHashMap继承HashMap
Entry继承Node
【分析如下】
Entry继承Node
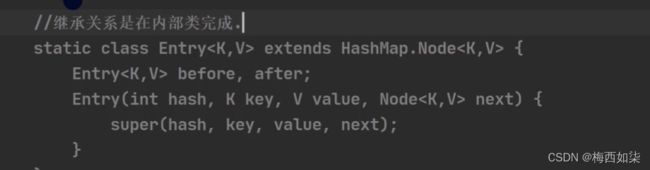
LinkedHashMap继承HashMap

调试之后,形成双向链表形式的结构



对于LinkedHashSet底层调用的还是HashSet的底层的HashMap,因为LinkedHashSet继承HashSet,


先进行对哈希值进行计算:
1.先看传入是否为null




得出哈希值传入putVal方法进行执行



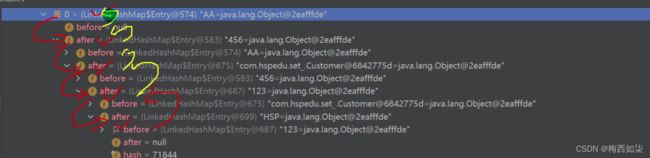
LinkedHashSet练习

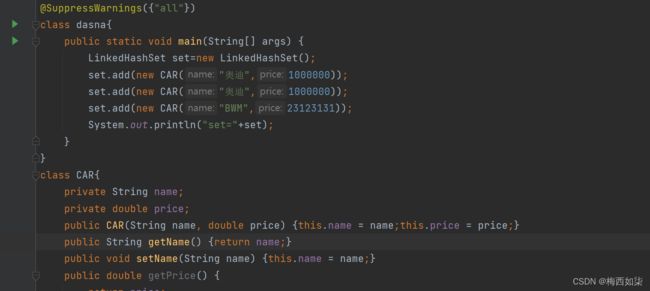
这题注意重写这个两个方法即可,以name和price为标准即可

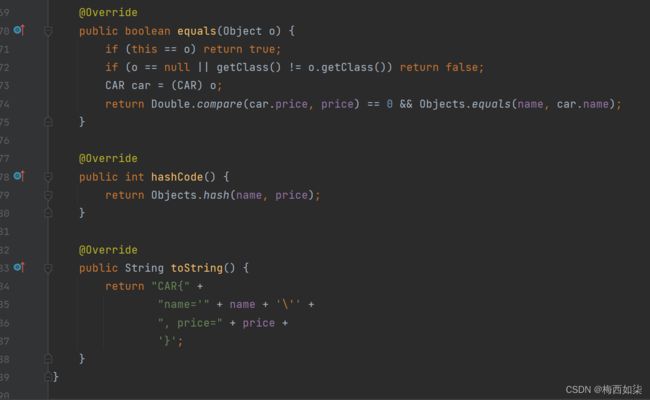
【499-530】