生成器工作内幕分析
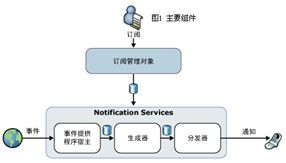
通知服务由上图所示组件组成。当事件提供者收集到事件后,会把这些事件一次全部提交给生成器,此操作作为一个事务管理,因此要么全部事件提交,要么全部放弃提交。在我们定义的ADF文件中的每个事件,在生成通知服务实例后都会对应两个表(NS<Event>EventBatches和NS<Event>Events),分别对应批与单个事件记录。批表中有两个字段StartCollectionTime与EndCollectionTime分别对应一个批的开始创建时间与批记录插入的完成时间。
每个计划订阅对应的表名为NS<SubscriptionClassName>Schedules。此表中会记录此订阅的执行时间及执行间隔。对于事件驱动的订阅对应的表名称为NS<SubscriptionClassName>Subscriptions。
生成器在内部维护了两个时钟:系统时钟与量程时钟。系统时钟对应真实的时间,而量程时钟根据在ADF中的QuantumDuration元素所指定的数值把时间划分成一个个时间段。
系统时钟与量程时钟的关系如下图所示:
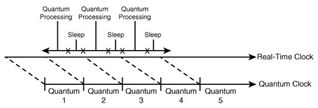
可以看到量程时钟始终滞后系统时钟一个量程间隔。如果在这一个量程间隔内,能处理完成所有的订阅,那么量程时钟会休眠。直到下一个量程开始才再一次执行。
那么,在每个量程间隔内生成器完成了些什么操作呢?
首先,它会根据量程的起始与结束时间,在规则中(也就是产生消息的SQL语句中)所引用到的事件表中对应的事件批表中根据EndCollectionTime的值来把符合该范围内的事件表填充至一个被物化的与事件表同名的视图中。这就是我们为什么在ADF中定义匹配的规则时并没有对事件进行任何筛选的原因。如果一个批的结束时间正好位于一个量程的结束时间,则此事件批会在下一个量程进行匹配。在我们定义的所有规则中,被访问的对象,其实都是生成器所创建的物化的视图。因此,这也给我们调试规则时带来了问题,因为我们只能通过生成才会创建这些视图。在联机文档中有介绍内部提供的用于调试的存储过程。
其次,在选择了事件之后,会检查事件驱动的订阅中有哪些引用了这些事件。然后把所有涉及到的有对应事件的订阅信息选择出来,同样也被物化为一个视图。
最后,选择计划订阅中在该量程间隔时间范围内要执行的订阅。因为计划订阅和事件类是没有关联的。因此,生成器会计算所有计划订阅表中是否有符合条件的订阅。而不像是事件驱动的订阅,只选择与事件相关的订阅信息。
上述步骤保证了所有的事件及时发送给订阅者,但是没有保证消息的发送顺序(消息的实时性取决于各组件的执行时间间隔及网络原因)。要保证消息是按照事件的顺序进行发送的,我们只要在ADF中进行简单的配置<ProcessEventsInOrder>true</ProcessEventsInOrder>,联机文档中有关于量程顺序与子量程顺序的详细介绍,但是这会对生成器性能造成影响,因此默认ProcessEventsInOrder元素值为false。但是内部如果因为系统负载过重,或是因为有太多的事件,或者是因为生成器服务停止,都会使得量程时钟远远滞后于系统时钟。这时生成器就会一直执行,并不休眠,以试图能追赶上系统时钟,直到与系统时钟保持同步后,才会在空闲时进行休眠。如下图:
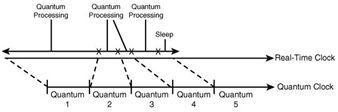
这种延迟可能会对订阅者产生一些过时消息。试想在股票价格的订阅中,如果因为生成器服务停止一小时后重新启动。这时量程时钟还是继续从停止服务的时间开始进行事件的匹配,以产生消息(从而保证所有的事件都能发送给订阅者)。用户可能不会再关心1小时之前的股票信息。这时为了能让生成器把这些垃圾事件过滤掉,我们需要明确指定生成器只匹配多少个量程间隔内的事件。如下图中指定的只进行40个量程间隔内的事件匹配和10个计划订阅的匹配。如果量程间隔设置的过小,会加快消息的响应速度,但是这也加重了生成器服务所在机器的负担。设置过大,会降低消息的及时性。因此就根据事件及订阅的数据量,合理的设置此间隔。

通知服务也是一种Windows服务,但是它提供了比我们自定义的通知服务更好的可扩展性、伸缩性和安全控制及快速的开发模型。我们不再需要去关心消息是如何发送、何时发送、发送失败后的处理及历史数据的维护等底层实现,而只需要根据消息、订阅的规则编写相应的T-SQL语句以执行这些匹配操作即可。在得到了生成的消息之后,你可以任意扩展消息发送的方式,默认提供了发送到文件、邮件的方式。有了数据,怎么显示你可以自由发挥了。