人工智能——分类算法
目录
7 K 近领算法
7.1 本章工作任务
7.2 本章技能目标
7.3 本章简介
7.4 编程实战
7.5 本章总结
7.6 本章作业
本章已完结!
7 K 近领算法
摘要:
本章实现的工作是:首先用Python导入包含学生成绩和学生类别的样本数据,然后采用 K 近邻分类算法,配置算法模型中的 k值,以 N 维空间的欧式距离为度量标准,求解待分类学生样本的预测标签。将预测标签与真实标签进行对比得出分类结果准确率。最后将预测结果可视化。
本章掌握的技能是:1、通过编写 KNN 算法的底层代码,实现 KNN 算法模型的构建及参数配置,对样本数据进行预测分类并计算分类结果准确率。2、使用sklearn模块中的neighbors最近邻模块,导入其中的 KNeighborsClassifier模型实现预测分类和模型打分。3、使用Matplotlib库实现数据的可视化,绘制散点图。
7.1 本章工作任务
采用K近领(K-Nearest Neighbors, KNN) 算法编写程序,根据每一位学生的数学和英语成绩将学生划分为不同类别(理科生、综合生、文科生)。1、算法的输入是:600位学生的英语和数学成绩及分类信息。2、算法模型需要配置的参数是:决定分类结果的近领数量k。3、算法的结果是:对学生的预测分类结果及分类结果的准确率。
7.2 本章技能目标
掌握 K 近领分类算法原理。
使用Python导入学生成绩数据。
使用Python实现 K 近领模型建模、参数配置与求解。
使用Python实现 KNN 算法对样本数据集的分类。
使用Python对算法分类结果进行可视化。
7.3 本章简介
KNN 分类算法:是一种相对简单的分类方法,如果一个样本 x 在特征空间中的 k 个最相邻的样本中的大多数样本都属于某一类别 y,则该样本也属于类别 y。
KNN 分类算法可以解决的科学问题是: 已知包含N个正确分类的样本数据集,找到离待分类样本点距离(以空间中的欧式距离)最近的k个样本,统计k个样本中出现频率最高的标签值,即为待分类样本的预测分类结果。
KNN 分类算法可以解决的实际应用问题是:如果根据某个学生的成绩对该学生进行分类,可根据已知的学生成绩属性值(语文成绩及数学成绩),找到待分类学生成绩欧式距离最近的k个学生,统计这k个学生中出现频率最高的分类标签,即为待分类学生的分类结果。
本章的重点是:KNN 分类算法的理解和使用。
7.4 编程实战
方法一 引入sklearn模块,实现KNN分类算法。基本过程为:创建KNeighborsClassifier对象。调用fit方法,调用predict方法进行预测。
步骤1 引入sklearn模块中的neighbors最近邻模块,导入其中的KNeighborsClassifier模型,用于实现 K 近领分类。
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier #导入sklearn.neighbors模块中KNN类
import os #引入os模块,用于获取及修改当前工作目录路径步骤2 读取文件
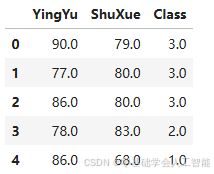
dataSet = pd.read_csv('spider04_forClassifyMyMake.csv', usecols = ['YingYu', 'ShuXue', 'Class'])
dataSet.head()输出结果:
步骤3 获取并修改当前路径(不同的设备显示的路径可能不同)。
thisFilePath = os.path.abspath('.')
os.chdir(thisFilePath)
os.getcwd()
输出结果:
'D:\\MyPythonFiles'步骤4 引入sklearn包中的sklearn.model_selection.train_test_split模块,用于划分训练集及测试集。
from sklearn.model_selection import train_test_split
train_set = np.array(dataSet.iloc[:, 0:2]) #取样本前三列为所要划分的样本特征集,并将数据转换成数组形式,以用于算法分类及作图
train_label = list(dataSet.iloc[:, 2]) #训练集中的标签,用list形式