导言
在信息技术飞速发展的今天,各种类型数据库层出不穷。由于支持数据在异构数据库间同步,逻辑复制的重要性与日俱增。当前openGauss逻辑复制串行解码平均性能为3~5MBps,在业务压力大的场景下难以满足实时同步的需求,导致日志堆积,从而影响生产集群业务。因此,我们设计了并行解码特性,令多个线程协同并行解码从而提高解码性能,在基础场景下解码性能可达到100MBps.
设计思路——为什么考虑并行解码?
原有的串行解码逻辑,从读取日志,到日志解码,以及结果拼接发送都是由单线程处理的,主要流程及耗时的大致比例如下图所示:
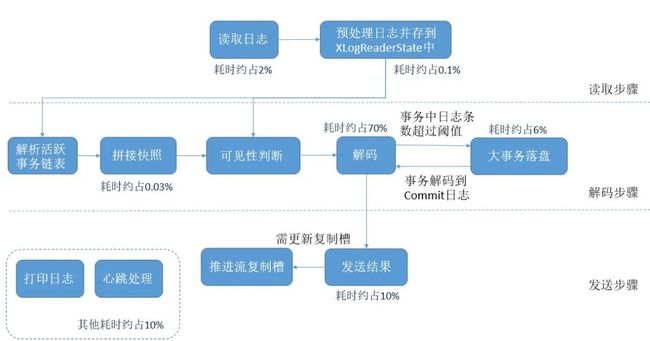
可以看出,整个流程的主要时间消耗在解码步骤中,需要通过多线程解码来进行优化;而发送步骤的耗时也较为明显,可以使用批量发送来做进一步优化。
工作流程——并行解码消息序列图
如下所示,在并行解码中,openGauss的数据节点(Data Node, DN)上的工作线程被分为三种:
1. Sender/Collector线程,负责接收客户的解码请求,以及拼接各解码线程的结果并发送给客户,该线程在一次解码请求中仅建立一个; 2. Reader/Dispatcher线程,负责读取WAL日志并分发给各解码线程进行解码,该线程在一次解码请求中仅建立一个; 3. Decoder线程,即解码线程,负责将Reader/Dispatcher线程发给自己的日志解码(当该线程已经在解码时,该部分日志暂存于read change队列中),并将解码结果(当尚未解到提交日志时,该部分结果暂存于decode change队列中)发给Sender/Collector线程,该线程在一次解码请求中可以建立多个。
该消息序列图说明如下:
1. 客户端向DN发送逻辑复制请求,该DN可为主机或备机。逻辑复制选项里可以设置参数选择仅连接备机,以防止主机压力过大。
2. 除了接收到客户请求的Sender线程外,DN还需建立Reader/Dispatcher线程和若干Decoder线程。
3. Reader读取xlog日志,进行预处理。如果相关日志涉及TOAST列,需在此步骤完成TOAST拼接。
4. Dispatcher将预处理后的日志派发给各Decoder线程。
5. Decoder线程各自独立进行解码。这里可以通过配置选项来设置解码格式(json、text或bin)。
6. Decoder将解码结果发送给Collector。
7. Collector以事务为单位汇总解码结果。
8. 为减少发送次数,降低网络I/O对解码性能的影响,在开启批量发送功能(即sending-batch参数设置为1)时,Sender积攒一定量的日志后(阈值设置为1MB),批量向客户返回解码结果。
9. 客户如需停止逻辑复制流程,断开与DN的逻辑复制连接即可。
10. Sender向Reader/Dispatcher线程和Decoder线程发送退出信号。
11. 各线程收到退出信号后,释放占用的资源,完成环境清理并退出。
技术细节1——可见性改造
在逻辑解码中,由于是对历史日志进行解析,因此对日志中元组的可见性判断至关重要。在原有串行解码的逻辑里,我们使用活跃事务链表机制来进行可见性判断。但是对于并行解码,每个解码线程各自维护一个活跃事务链表代价较大,会对解码性能产生不利影响,因此我们做了可见性改造,使用CSN(Commit Sequence Number,即提交事务号)来进行元组可见性判断。针对每一个事务号xid,其可见性流程如下:

其主要流程为:
1. 根据xid获取用来判断可见性的CSN,这里确保可以根据任一xid获取到CSN值。如果xid为异常值,会返回表示特定状态的CSN,这种CSN也可用于可见性判断; 2. 若CSN已提交,将其与快照中CSN比较,该事务CSN较小则不可见,否则可见;3. 若CSN不是正在提交,则不可见。
基于上述逻辑,在并行解码中,判断一个元组的快照可见性的逻辑则为依次判断元组Xmin(插入时的事务号)和Xmax(删除/更新时的事务号)的快照可见性。这里的整体思路是,Xmin不可见/未提交或Xmax可见则元组不可见,而Xmin可见且Xmax不可见/未提交则元组可见。元组中的各标记位维持其原有含义参与可见性判断。
技术细节2——批量发送
在使用并行解码之后,解码过程占用的时间出现显著下降,但此时解码结果发送线程又将成为瓶颈,对于每条解码结果均执行一次完整的发送流程代价太大。因此这里我们采用了批量发送的方式,将解码的结果暂时收集起来,在超过阈值时一并发送给客户端。在批量发送时,需额外记录每条解码结果的长度,以及约定好的分隔符,以便并行解码功能的使用者对批量发送的日志进行拆分处理。
使用方式
我们为并行解码新增了一些可选配置项:
1. 解码线程并发度
通过配置选项parallel-decode-num,指定并行解码的Decoder线程数量。其取值范围为1~20的int型,取1表示按照原有的串行逻辑进行解码,不会进入本特性代码逻辑。默认值为1。当该选项配置为1时,禁止配置下面的解码格式选项decode-style。
2. 解码白名单
通过配置选项white-table-list,指定需要解码的表。其取值为text类型包含白名单中表名的字符串,不同的表以','为分隔符进行隔离。例:select * from pg_logical_slot_peek_changes('slot1', NULL, 4096, 'white-table-list', 'public.t1,public.t2');。
3. 限制仅备机解码
通过配置选项standby-connection,指定是否限制仅备机解码。其取值为bool型,取true代表限制仅允许连接备机解码,连接主机解码时会报错退出;取false时不做限制。默认值为false。
4. 解码格式
通过配置选项decode-style,指定解码格式。其取值为char型的字符’j’、’t’或’b’,分别代表json格式、text格式及二进制格式。默认值为’b’即二进制格式解码。
5. 批量发送
通过配置选项sending-batch,指定是否批量发送解码结果。其取值为int型的0或1,0代表不开启批量发送,1代表解码结果累计达到或刚超过1MB时批量发送解码结果,这里默认值为0,即默认不开启批量发送。
以使用JDBC进行并行解码为例,建立连接时需进行如下配置:
PGReplicationStream stream = conn.getReplicationAPI().replicationStream().logical().withSlotName(replSlotName).withSlotOption("include-xids", true).withSlotOption("skip-empty-xacts", true).withSlotOption("parallel-decode-num", 10).withSlotOption("white-table-list", "public.t1,public.t2").withSlotOption("standby-connection", true).withSlotOption("decode-style", "t").withSlotOption("sending-bacth", 1).start();
从倒数第6行到倒数第2行为新增逻辑,代表10并发解码、仅解码表public.t1和public.t2、启用备机连接、解码格式为text且开启批量发送功能,在配置参数超出范围时,会报错并提示参数允许取值范围。
辅助功能——监控函数
在进行并行解码时,为在解码速度较慢的场景下方便定位解码性能瓶颈,我们增加了gs_get_parallel_decode_status()函数,用来查看当前DN上各解码线程的存储尚未解码日志的read change队列和存储尚未发送解码结果的decode change队列的长度。
该函数没有入参,返回结果共四列,分别是slot_name、parallel_decode_num、read_change_queue_length、decode_change_queue_length。
slot_name为复制槽名,类型为text;parallel_decode_num为并行解码线程数,类型为int;read_change_queue_length类型为text,其记录了每个解码线程的read change)队列长度;decode_change_queue_length类型为text,其记录了每个解码线程的decode change队列长度。使用方式如下所示:

对于解码失速场景,在解码DN上执行此函数,然后查看查询结果的read_change_queue_length,这里记录每个解码线程里读取日志队列长度,如果这里的值过小表示日志读取阻塞,需继续定位是否为磁盘I/O不足。查看查询结果的decode_change_queue_length,这里记录每个解码线程里解码日志队列长度,如果这里值过小表示解码速度过慢,可以适当增加解码线程数量。如果read_change_queue_length和decode_change_queue_length均比较大,说明解码日志发送被阻塞,需检测并行解码使用者在目标数据库的回放日志速度。通常来说,解码失速场景一般有CPU、I/O、或内存资源不足造成,通过使用备机解码保证以上资源充足一般可以避免解码失速问题。
结语
并行解码可以大幅提升逻辑复制解码性能,其对解码实例增加的业务压力相较而言显得不那么重要。作为异构数据库数据复制的关键技术方案,并行解码对于openGauss的重要性也是不言而喻的。
欢迎访问openGauss官方网站

openGauss开源社区官方网站:
https://opengauss.org
openGauss组织仓库:
https://gitee.com/opengauss
openGauss镜像仓库:
https://github.com/opengauss-mirror

扫码关注我们
微信公众号|openGauss
微信社群小助手|openGauss-bot
本文分享自微信公众号 - openGauss(openGauss)。
如有侵权,请联系 [email protected] 删除。
本文参与“ OSC源创计划 ”,欢迎正在阅读的你也加入,一起分享。