计算机视觉大型攻略 —— SLAM(3) Visual SLAM
之前写了SLAM的理论和基础算法,这一篇是关于视觉SLAM的综述。
[1] Parallel Tracking and Mapping for Small AR Workspaces
[2] Keyframe-based monocular SLAM: design, survey, and future directions
[3] Visual SLAM: Why Filter?
Visual SLAM
视觉SLAM只采用camera作为传感器。常见的传感器有单目,双目与RGB-D相机。
算法分类
关于算法分类。根据优化算法的不同可以分为滤波与图优化,更多滤波算法与图优化算法的内容可参见前两篇文章。另外,根据跟踪算法的不同,还可以分为直接法与间接法。
传送门:SLAM概率模型与EKF
Graph-based SLAM
滤波与图优化
视觉SLAM同样可以分为滤波与图优化两类。如采用EKF的MonoSLAM,采用基于Keyframe的图优化的PTAM等。由于学者们逐步认识到图优化信息矩阵的稀疏性以及KeyFrame方法的介入,Keyframe-based的图优化算法成为了主流。论文[3]比较了滤波和基于Keyframe的图优化算法。下文主要介绍基于KeyFrame的图优化算法。
直接法与间接法
视觉SLAM算法还可以分为直接算法(direct method)与间接(indirect/Feature-Based method)算法。
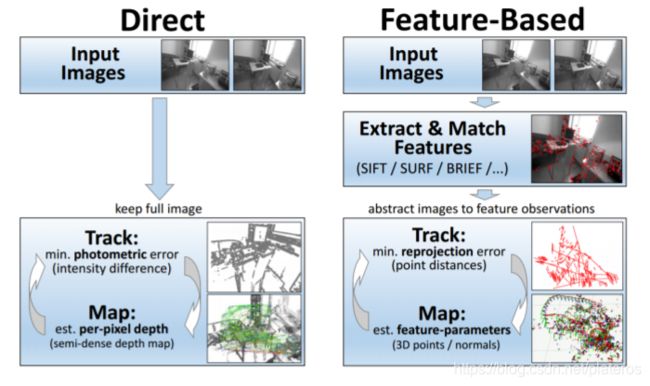
直接法(Direct Method/Apperance Method)
Direct Method直接使用像素光强去求解相机运动。可以是稠密的,半稠密的,稀疏的。
直接法不需要显式的求关键点的匹配对应关系,他优化的是投影误差。这种方法与求解稠密光流或深度图的方法类似。
直接法运行慢,不容易去外点,而且需要一个好的初始化。但是这种方法在估计地图或者重建的效果很好,结合GPU的使用,也可以大大提高效率。采用这种方法的算法有DTAM,LSD SLAM,DSO等。
间接法(Indirect/Feature-based Method)
间接方法首先将像素转换到特征空间(feature space),如SIFT, SURF, BRIEF等,提取关键点,通过匹配关键点,计算相机运动。
很明显,基于特征点的算法计算量小,运算速度快,可以方便的去外点。很多经典的VO(视觉里程计)算法采用了这种方法,如libviso2。
更多关于特征点匹配的文章可移步我的专栏:特征匹配专栏。
传送门:视觉里程计综述 简要的介绍了视觉里程计算法。
libviso2 详细解析了一个基于特征的视觉里程计算法。
下面以Feature-based Method为例,详细说明一下视觉SLAM的组成部分。
基于特征的图优化算法
基于特征的视觉SLAM的算法通常为以下几个模块。
- 特征点检测匹配
- 相机位姿R, t与地图的估计。
- 关键帧(Key-Frame)。
- 重定位和回环(Loop closing)。
特征点检测与匹配

输入图像,首先要做特征点的检测与匹配。常用的算法有SURF, SIFT, ORB等。更多关于特征点与特征匹配的内容可移步我的专栏。
传送门:特征与匹配
位姿与地图估计
基于特征的SLAM算法通常创建和使用特征地图。特征地图使用稀疏特征点作为路标,而地图由路标组成。更多地图分类可阅读这篇文章:SLAM与概率模型。
数学模型
首先说一下数学模型。
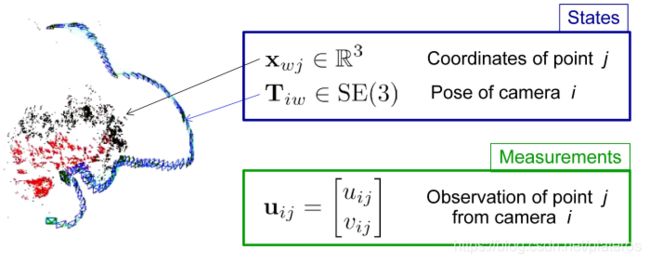
如上图,![]() 是特征点
是特征点  在相机
在相机  坐标系下的3D坐标,即路标(LandMark)。
坐标系下的3D坐标,即路标(LandMark)。![]() 是相机到
是相机到  的刚体变换。与VO不同,SLAM同时估计位姿与地图,这两个向量组成了系统状态向量。
的刚体变换。与VO不同,SLAM同时估计位姿与地图,这两个向量组成了系统状态向量。
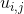 为观测向量。
为观测向量。
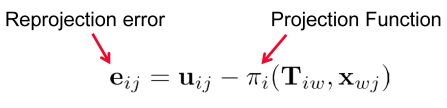
误差项定义为投影误差![]() ,即路标 在相机 的预测位置的投影与观测的差。
,即路标 在相机 的预测位置的投影与观测的差。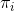 为投影函数。
为投影函数。

![]() 为相机的位姿由旋转和平移矩阵构成。
为相机的位姿由旋转和平移矩阵构成。![]() 经过旋转平移,转换成
经过旋转平移,转换成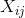 , 即 在相机 坐标系下的3d坐标。再通过投影函数,求出 在 相机 下的图像坐标(预测过程)。与观测到的坐标相减,得到投影误差
, 即 在相机 坐标系下的3d坐标。再通过投影函数,求出 在 相机 下的图像坐标(预测过程)。与观测到的坐标相减,得到投影误差![]() 。
。

上图是针孔相机模型下的投影关系,f, c为相机焦距和principal point。假设相机已经校准过,他们是常量。
因此,投影函数可以写成,
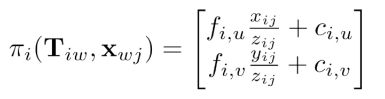
光束法平差(Bundle Adjustment)
基于![]() ,可定义全局优化函数,
,可定义全局优化函数,

求解最优的T, x组合,使误差项![]() 最小。
最小。![]() 为信息矩阵。该函数可以使用非线性优化函数求解,如牛顿高斯等。详细求解过程在上一篇Graph-based SLAM里写过了。
为信息矩阵。该函数可以使用非线性优化函数求解,如牛顿高斯等。详细求解过程在上一篇Graph-based SLAM里写过了。
![]() 为鲁棒性回归损失函数。比如L1,L2, Huber。
为鲁棒性回归损失函数。比如L1,L2, Huber。
L1 cost:
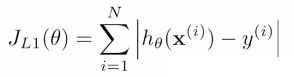
L2 cost:

Huber:
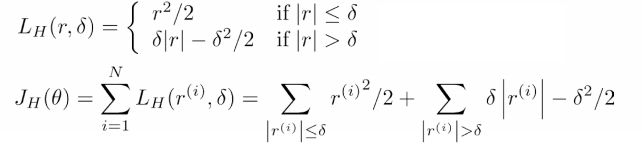
下图是这三种函数的比较
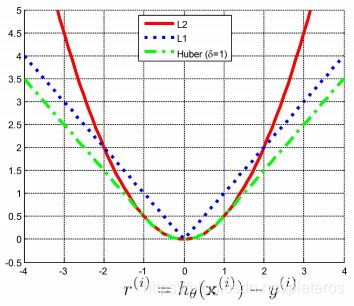
由于图像中特征点通常会很多,如果位姿, 特征点一起估计,上面的函数优化起来复杂度非常高。很多SLAM算法采用局部BA,或者滑动窗口BA。为了进一步提高性能,还可以配合关键帧算法。
关键帧(KeyFrame)
只在关键帧上估计地图(LandMark)。
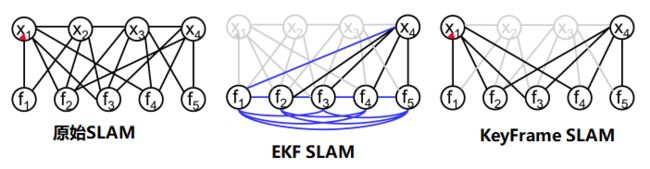
- 如上图,原始的SLAM每一帧估计相机位姿X与路标f。
- EKF仅保留最新的位姿。算法复杂度为
 ,取决于特征点的个数。
,取决于特征点的个数。 - KeyFrame SLAM仅在关键帧优化地图(路标)。
[2]中Figure 2给出了基于KeyFrame的KSLAM算法的基本框架,如下图。
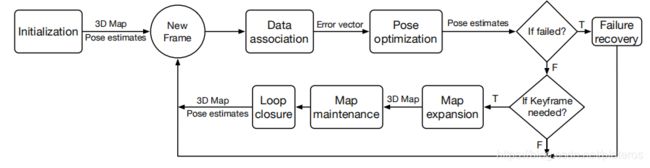
PTAM算法[1]最早采用了关键帧技术。
重定位和回环(Loop closing)
考虑以下两种情况,
- 在SLAM跟踪过程中,由于出现低纹理或者遮挡的情况,会出现跟踪失败的情况,此时算法需要重定位功能以重新获得位姿和继续建图。
- 机器人回到了曾经创建过地图的区域。此时,无需重新创建地图,而且,还可以通过loop correction提高地图的准确性。
无论哪一种情景,均需要位置识别功能。
词袋(Bag of Words)

顾名思义,词袋就是一袋子"词"。

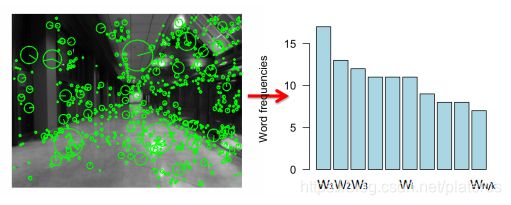
我们把图像用一组“words"来表示。这些"words"相对独立,与顺序无关。
输入一组训练图像,BoW算法首先在这些图中提取特征,并建立词典(visual vocabulary)。
给定一个测试图像,提取特征,对每个特征,到词典里进行匹配。
1. 为一组训练图像提取特征

2. 特征分类并创建词典。

使用K-means聚类,构成由Word{Wi}组成的词典。
3. 量化每幅图片,为图片的特征寻找词典内最接近的words,生成直方图。
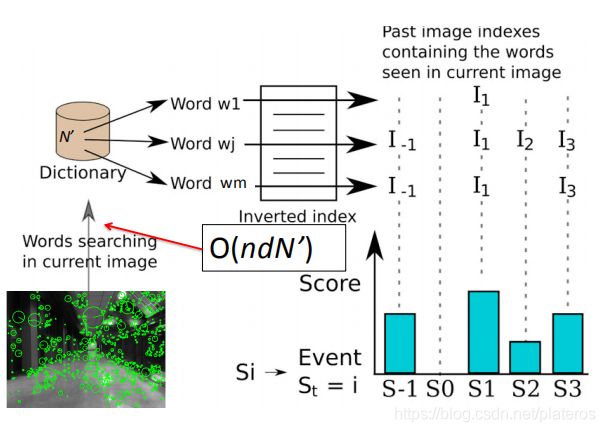
4. 反向映射到图像(documents),生成Inverted Index。
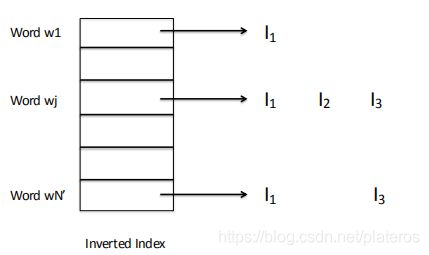
5. 测试图像通过Inverted index在词典中快速匹配。