【C++MiNiSTL项目开发笔记】
目录
Part1-从git与github开始
Part2-对STL的初步概览
六大组件
template
代码概览
Part3-源码阅读与剖析
【分配器】
C++中的new
分配器概述
【迭代器】
【容器】
【算法】
序列容器
关联容器
【仿函数】
【适配器】
Part1-从git与github开始
GitHub 是一个用于版本控制和协作的代码托管平台,ta能够让你和任何地方的其他工作者一起做项目。
Git是目前世界上最先进的分布式版本控制系统
git clone
用于从github上下载源码


git init
如果是自己新创建一个文件夹,就在里边git
然后告诉git管理这个文件夹下的代码
就是输入git init
在工作区写完文件夹时,提交
git add .(如果不是提交这个文件夹下所有的,就把点改成要提交的文件名就行)
此时,那个文件就会进入准备提交的状态(把文件加入暂存区)
git comit -m "这里写备注"
这样,git会以数据库的形式把代码保存在git仓库中
用git log 来查看提交的历史记录
git checkout HEAD 要恢复的文件
Part2-对STL的初步概览
六大组件
- 分配器:用来管理内存。
- 迭代器:将容器和算法粘合在一起,用来遍历STL容器中的部分或全部元素。
- 容器:封装了大量常用的数据结构。
- 算法:定义了一些常用算法。
- 仿函数:具有函数特质的对象。
- 适配器:主要用来修改接口。

template
STL都用到了template!很重要
在C++中,除了面向对象,还有一种编程思想:泛型编程
主要基于模板来实现
【1.函数模板】





【2.类模板】

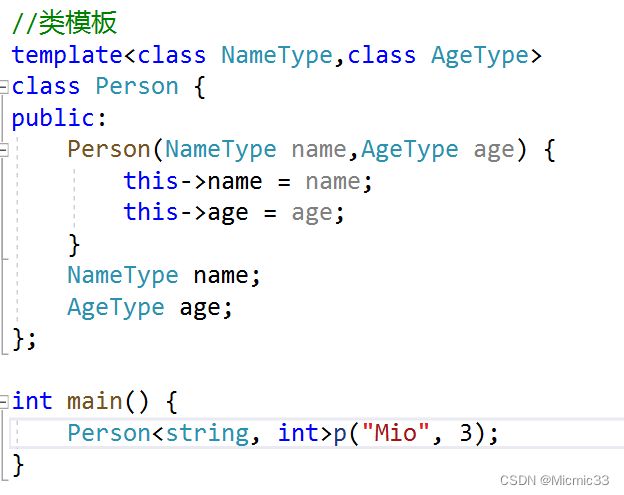

(C++新特性支持自动类型推导了)


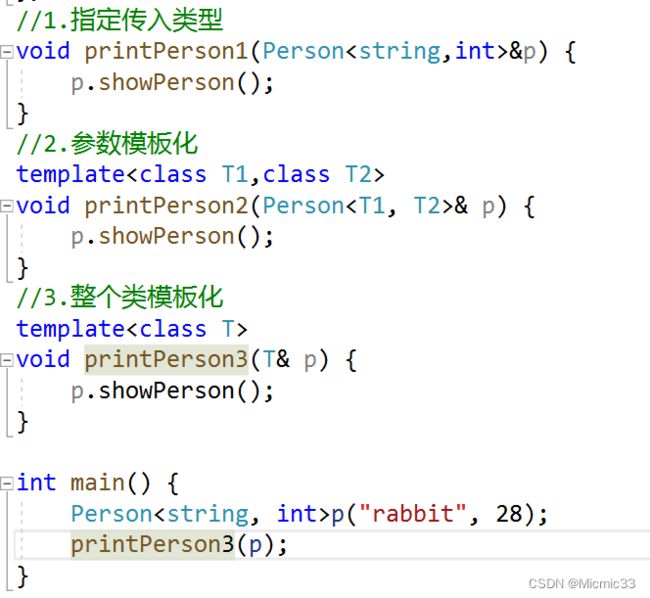


若要灵活指定:

代码概览
![]()
定义了输出的颜色


Part3-源码阅读与剖析
【分配器】
参考文章1
参考文章2
C++中的new
new(new operator)做两件事
调用opeartor new分配内存(operator new会间接调用malloc)
调用构造函数初始化内存中的对象(placement new)
同样的,delete负责
调用析构函数
调用free释放内存
分配器概述
allocate()实现空间的申请
申请内存分为一级配置器和二级配置器, 分配的空间小于128字节的就调用二级配置器, 大于就直接使用一级配置器, 一级配置器直接调用malloc申请, 二级使用内存池.
template
inline T* allocate(ptrdiff_t size, T*)
{
set_new_handler(0);
T* tmp = (T*)(::operator new(size)(size * sizeof(T)));
if(!tmp)
{
cerr << "out of memort" << endl;
exit(1);
}
return tmp;
}
construct()实现在已获得的内存里建立一个对象
// 这里的construct调用的是placement new, 在一个已经获得的内存里建立一个对象
template
inline void construct(T1* p, const T2& value)
{
new (p) T1(value);
}
“delete”实现:
destory()实现调用析构函数,有两个版本
// 第一版本, 接收指针
template inline void destroy(T* pointer)
{
pointer->~T();
}
// 第二个版本的, 接受两个迭代器, 并设法找出元素的类型. 通过__type_trais<> 找出最佳措施
template
inline void destroy(ForwardIterator first, ForwardIterator last)
{
__destroy(first, last, value_type(first));
}
// 接受两个迭代器, 以__type_trais<> 判断是否有traival destructor
template
inline void __destroy(ForwardIterator first, ForwardIterator last, T*)
{
typedef typename __type_traits::has_trivial_destructor trivial_destructor;
__destroy_aux(first, last, trivial_destructor());
}
__type_traits为__false_type时
// 没有non-travial destructor
template
inline void __destroy_aux(ForwardIterator first, ForwardIterator last, __false_type)
{
for ( ; first < last; ++first)
destroy(&*first);
}
__type_traits为__true_type时
什么也不做,因为这样效率很高,不需要执行析构函数
// 有travial destructor
template
inline void __destroy_aux(ForwardIterator, ForwardIterator, __true_type) {}
版本2的特化版
inline void destroy(char*, char*) {}
inline void destroy(wchar_t*, wchar_t*) {}
一级分配器(是一个类)
STL对malloc和free用函数重新进行了封装
allocate
// 在分配和再次分配中, 都会检查内存不足, 在不足的时候直接调用private中相应的函数
static void * allocate(size_t n)
{
void *result = malloc(n);
if (0 == result) result = oom_malloc(n);
return result;
}
deallocate
static void deallocate(void *p, size_t /* n */)
{
free(p); //一级配置器直接调用free释放内存
}
统一的接口
// 定义符合STL规格的配置器接口, 不管是一级配置器还是二级配置器都是使用这个接口进行分配的
template
class simple_alloc {
public:
static T *allocate(size_t n)
{ return 0 == n? 0 : (T*) Alloc::allocate(n * sizeof (T)); }
static T *allocate(void)
{ return (T*) Alloc::allocate(sizeof (T)); }
static void deallocate(T *p, size_t n)
{ if (0 != n) Alloc::deallocate(p, n * sizeof (T)); }
static void deallocate(T *p)
{ Alloc::deallocate(p, sizeof (T)); }
};
第二级分配器
第一级是直接调用malloc分配空间, 调用free释放空间, 第二级就是建立一个内存池
用链表来保存不同字节大小的内存块, 就很容易的进行维护, 而且每次的内存分配都直接可以从链表或者内存池中获得, 提升了我们申请内存的效率, 毕竟每次调用malloc和free有开销, 特别是很小内存的时候
STL将第二级配置器设置为默认的
3个常量&一个宏操作
// 二级配置器
enum {__ALIGN = 8}; // 设置对齐要求. 对齐为8字节, 没有8字节自动补齐
enum {__MAX_BYTES = 128}; // 第二级配置器的最大一次性申请大小, 大于128就直接调用第一级配置器
enum {__NFREELISTS = __MAX_BYTES/__ALIGN}; // 链表个数, 分别代表8, 16, 32....字节的链表
static size_t FREELIST_INDEX(size_t bytes) \
{\
return (((bytes) + ALIGN-1) / __ALIGN - 1);\
}
allocate()
- 先判断申请的字节大小是不是大于128字节, 是, 则交给第一级配置器来处理. 否, 继续往下执行
- 找到分配的地址对齐后分配的是第几个大小的链表.
- 获得该链表指向的首地址, 如果链表没有多余的内存, 就先填充链表.
- 返回链表的首地址, 和一块能容纳一个对象的内存, 并更新链表的首地址
static void * allocate(size_t n)
{
obj * __VOLATILE * my_free_list;
obj * __RESTRICT result;
if (n > (size_t) __MAX_BYTES)
{
return(malloc_alloc::allocate(n));
}
my_free_list = free_list + FREELIST_INDEX(n);
result = *my_free_list;
if (result == 0) // 没有多余的内存, 就先填充链表.
{
void *r = refill(ROUND_UP(n));
return r;
}
*my_free_list = result -> free_list_link;
return (result);
};
refill()内存填充
- 向内存池申请空间的起始地址
- 如果只申请到一个对象的大小, 就直接返回一个内存的大小, 如果有更多的内存, 就继续执行
- 从第二个块内存开始, 把从内存池里面分配的内存用链表给串起来, 并返回一个块内存的地址给用户
// 内存填充
template
void* __default_alloc_template::refill(size_t n)
{
int nobjs = 20;
char * chunk = chunk_alloc(n, nobjs); // 向内存池申请空间的起始地址
obj * __VOLATILE * my_free_list;
obj * result;
obj * current_obj, * next_obj;
int i;
// 如果只申请到一个对象的大小, 就直接返回一个内存的大小
if (1 == nobjs) return(chunk);
my_free_list = free_list + FREELIST_INDEX(n);
// 申请的大小不只一个对象的大小的时候
result = (obj *)chunk;
// my_free_list指向内存池返回的地址的下一个对齐后的地址
*my_free_list = next_obj = (obj *)(chunk + n);
// 这里从第二个开始的原因主要是第一块地址返回给了用户, 现在需要把从内存池里面分配的内存用链表给串起来
for (i = 1; ; i++)
{
current_obj = next_obj;
next_obj = (obj *)((char *)next_obj + n);
if (nobjs - 1 == i)
{
current_obj -> free_list_link = 0;
break;
}
else
{
current_obj -> free_list_link = next_obj;
}
}
return(result);
}
deallocate()
- 释放的内存大于128字节直接调用一级配置器进行释放
- 将内存直接还给对应大小的链表就行了, 并不用直接释放内存, 以便后面分配内存
static void deallocate(void *p, size_t n)
{
obj *q = (obj *)p;
obj * __VOLATILE * my_free_list;
// 释放的内存大于128字节直接调用一级配置器进行释放
if (n > (size_t) __MAX_BYTES)
{
malloc_alloc::deallocate(p, n);
return;
}
my_free_list = free_list + FREELIST_INDEX(n);
q -> free_list_link = *my_free_list;
*my_free_list = q;
}
内存池
// 内存池
template
char* __default_alloc_template::chunk_alloc(size_t size, int& nobjs)
{
char * result;
size_t total_bytes = size * nobjs; // 链表需要申请的内存大小
size_t bytes_left = end_free - start_free; // 内存池里面总共还有多少内存空间
// 内存池的大小大于需要的空间, 直接返回起始地址
if (bytes_left >= total_bytes)
{
result = start_free;
start_free += total_bytes; // 内存池的首地址往后移
return(result);
}
// 内存池的内存不足以马上分配那么多内存, 但是还能满足分配一个即以上的大小, 那就按对齐方式全部分配出去
else if (bytes_left >= size)
{
nobjs = bytes_left/size;
total_bytes = size * nobjs;
result = start_free;
start_free += total_bytes; // 内存池的首地址往后移
return(result);
}
else
{
// 如果一个对象的大小都已经提供不了了, 那就准备调用malloc申请两倍+额外大小的内存
size_t bytes_to_get = 2 * total_bytes + ROUND_UP(heap_size >> 4);
// Try to make use of the left-over piece.
// 内存池还剩下的零头内存分给给其他能利用的链表, 也就是绝不浪费一点.
if (bytes_left > 0)
{
// 链表指向申请内存的地址
obj * __VOLATILE * my_free_list = free_list + FREELIST_INDEX(bytes_left);
((obj *)start_free) -> free_list_link = *my_free_list;
*my_free_list = (obj *)start_free;
}
start_free = (char *)malloc(bytes_to_get);
// 内存不足了
if (0 == start_free)
{
int i;
obj * __VOLATILE * my_free_list, *p;
// 充分利用剩余链表的内存, 通过递归来申请
for (i = size; i <= __MAX_BYTES; i += __ALIGN)
{
my_free_list = free_list + FREELIST_INDEX(i);
p = *my_free_list;
if (0 != p)
{
*my_free_list = p -> free_list_link;
start_free = (char *)p;
end_free = start_free + i;
return(chunk_alloc(size, nobjs));
}
}
// 如果一点内存都没有了的话, 就只有调用一级配置器来申请内存了, 并且用户没有设置处理例程就抛出异常
end_free = 0; // In case of exception.
start_free = (char *)malloc_alloc::allocate(bytes_to_get);
}
// 申请内存成功后重新修改内存起始地址和结束地址, 重新调用chunk_alloc分配内存
heap_size += bytes_to_get;
end_free = start_free + bytes_to_get;
return(chunk_alloc(size, nobjs));
}
}
【迭代器】
每个组件都可能涉及到对元素的操作,每个组件的数据类型可能不同,所以每个组件可能都要自己设计对自己的操作。将每个组件的实现成统一的接口就是迭代器
迭代器的优点
- 能屏蔽掉底层数据类型差异的
- 迭代器将容器和算法粘合在一起, 使版块之间更加的紧凑, 同时提高了执行效率, 让算法更加的得到优化
这些实现大都通过traits编程实现的. 它的定义了一个类型名规则, 满足traits编程规则就可以自己实现对STL的扩展, 也体现了STL的灵活性. 同时traits编程让程序根据不同的参数类型选择执行更加合适参数类型的处理函数, 也就提高了STL的执行效率. 可见迭代器对STL的重要性
迭代器最重要的就是对operator*和operator->进行重载,使它表现得像一个指针
- input iterator(输入迭代器) : 迭代器所指的内容不能被修改, 只读且只能执行一次读操作.
- output iterator(输出迭代器) : 只写并且一次只能执行一次写操作.
- forward iterator(正向迭代器) : 支持读写操作且支持多次读写操作.
- bidirectional iterator(双向迭代器) : 支持双向的移动且支持多次读写操作.
- random access iterator(随即访问迭代器) : 支持双向移动且支持多次读写操作. p+n, p-n等.
五种迭代器和其继承关系
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};
都是空类,只是为了调用时通过类选择不同的重载函数,继承是为了,当不存在某种迭代器类型匹配时编译器会根据继承层次向上查找进行传递
用distance(计算两个迭代器之间的距离)来理解“如何选择最优调用”
template
inline void distance(InputIterator first, InputIterator last, Distance& n)
{
__distance(first, last, n, iterator_category(first));
}
template
inline void __distance(InputIterator first, InputIterator last, Distance& n,
input_iterator_tag)
{
while (first != last)
{ ++first; ++n; }
}
template
inline void __distance(RandomAccessIterator first, RandomAccessIterator last,
Distance& n, random_access_iterator_tag)
{
n += last - first; //不同的迭代器有自己最佳的效率,通过iterator_category进行最优选择
}
五类迭代器源码
template struct input_iterator
{
typedef input_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
struct output_iterator {
typedef output_iterator_tag iterator_category;
typedef void value_type;
typedef void difference_type;
typedef void pointer;
typedef void reference;
};
template struct forward_iterator {
typedef forward_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
template struct bidirectional_iterator {
typedef bidirectional_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
template struct random_access_iterator {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
在这里介绍一下typename相较于class的主要作用:
- 对于模板参数是类的时候,
typename能够提取(萃取)出该类所定义的参数类型
template
class people
{
public:
typedef T value_type;
typedef T* pointer;
typedef T& reference;
};
template
struct man
{
public:
typedef typename T::value_type value_type;
typedef typename T::pointer pointer;
typedef typename T::reference reference;
void print()
{
cout << "man" << endl;
}
};
int main()
{
man> Man;
Man.print();
exit(0);
}

迭代器所指向对象的型别被称为value type. 传入参数的类型可以通过编译器自行推断出来, 但是如果是函数的返回值的话, 就无法通过value type让编译器自行推断出来了. 而traits就解决了函数返回值类型. 同样原生指针不能内嵌型别声明,所以内嵌型别在这里不适用, 迭代器无法表示原生指针(int *, char *等称为原生指针)
---------->这些问题如何被解决
iterator_traits结构
使用typename对参数类型进行萃取,并且对参数类型再进行一次命名
template
struct iterator_traits {
typedef typename Iterator::iterator_category iterator_category; //迭代器类型
typedef typename Iterator::value_type value_type; // 迭代器所指对象的类型
typedef typename Iterator::difference_type difference_type; // 两个迭代器之间的距离
typedef typename Iterator::pointer pointer; // 迭代器所指对象的类型指针
typedef typename Iterator::reference reference; // 迭代器所指对象的类型引用
};
上面的traits结构体并没有对原生指针做处理, 所以还要为特化, 偏特化版本(即原生指针)做统一
// 针对原生指针 T* 生成的 traits 偏特化
template
struct iterator_traits {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
// 针对原生指针 const T* 生成的 traits 偏特化
template
struct iterator_traits {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef const T* pointer;
typedef const T& reference;
};
__type_traits
iterator_traits是萃取迭代器的特性,而__type_traits是萃取型别的特性
萃取型别如下:

编译器会为每个类构造以上四种默认的函数,如果没有定义自己的,就会用编译器默认函数,如果使用默认的函数,我们可以使用memcpy(),memmove(),malloc()等函数来加快速度,提高效率
__iterator_traits允许针对不同的型别属性在编译期间决定执行哪个重载函数而不是在运行时才处理, 这大大提升了运行效率. 这就需要STL提前做好选择的准备. 是否为POD, non-trivial型别用__true_type和__false_type 来区分
(之前的空间配置器就提过)
__true_type和__false_type不是bool值,因为需要在编译期间就决定使用哪个函数。
将它们表现为空类——无额外负担,能表示真假,还能在编译时类型推导确定执行相应的函数
struct __true_type {};
struct __false_type {};
__type_traits源码
__STL_TEMPLATE_NULL struct __type_traits {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
__STL_TEMPLATE_NULL struct __type_traits {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
...
以上是将基础的类型都设置为__true_type型别
这里将指针进行特化处理, 同样是__true_type型别
#ifdef __STL_CLASS_PARTIAL_SPECIALIZATION
template
struct __type_traits {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
#else /* __STL_CLASS_PARTIAL_SPECIALIZATION */
struct __type_traits {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
struct __type_traits {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
struct __type_traits {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
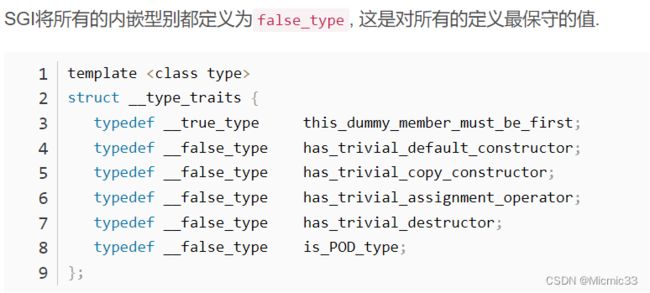
SGI对traits进行扩展,使得所有类型都满足traits编程规范, 这样SGI STL算法可以通过__type_traits获取类型信息在编译期间就能决定出使用哪一个重载函数, 解决了template是在运行时决定重载选择的问题. 并且通过true和false来确定POD和travial destructor, 让程序能选择更加符合其类型的处理函数, 大大提高了对基本类型的快速处理能力并保证了效率最高
【容器】
容器封装了大量常用的数据结构
容器分为序列式和关联式
序列式:vector list deque等,序列容器有头或尾,甚至有头有尾
关联式:map set hashtable等,没有所谓头尾,只有最大值,最小值
uninitialized系列函数
uninitialized_copy功能 : 从first到last范围内的元素复制到从 result地址开始的内存
template
inline ForwardIterator uninitialized_copy(InputIterator first, InputIterator last,
ForwardIterator result) {
return __uninitialized_copy(first, last, result, value_type(result));
} inline char* uninitialized_copy(const char* first, const char* last,
char* result) {
memmove(result, first, last - first);
return result + (last - first);
}
inline wchar_t* uninitialized_copy(const wchar_t* first, const wchar_t* last,
wchar_t* result) {
memmove(result, first, sizeof(wchar_t) * (last - first));
return result + (last - first);
}__uninitialized_copy函数
template
inline ForwardIterator __uninitialized_copy(InputIterator first, InputIterator last,
ForwardIterator result, T*) {
typedef typename __type_traits::is_POD_type is_POD;
return __uninitialized_copy_aux(first, last, result, is_POD());
} __uninitialized_copy使用了typename进行萃取, 并且萃取的类型是POD, 看来这里准备对__uninitialized_copy 进行最优化处理了, 我们接着来分析它是怎么实现优化处理的
template
inline ForwardIterator __uninitialized_copy_aux(InputIterator first, InputIterator last,
ForwardIterator result,
__true_type) {
return copy(first, last, result);
}
template
ForwardIterator __uninitialized_copy_aux(InputIterator first, InputIterator last,
ForwardIterator result,
__false_type) {
ForwardIterator cur = result;
__STL_TRY {
for ( ; first != last; ++first, ++cur)
construct(&*cur, *first);
return cur;
}
__STL_UNWIND(destroy(result, cur));
} uninitialized_copy_n也做了跟uninitialized_copy类似的处理, 只是它是采用tratis编程里iterator_category迭代器的类型来选择最优的处理函数.
template
inline pair
uninitialized_copy_n(InputIterator first, Size count,
ForwardIterator result) {
return __uninitialized_copy_n(first, count, result, iterator_category(first)); // 根据iterator_category选择最优函数
}
template
pair
__uninitialized_copy_n(InputIterator first, Size count, ForwardIterator result,
input_iterator_tag) // input_iterator_tag类型的迭代器
{
ForwardIterator cur = result;
__STL_TRY {
for ( ; count > 0 ; --count, ++first, ++cur)
construct(&*cur, *first);
return pair(first, cur);
}
__STL_UNWIND(destroy(result, cur));
}
template
inline pair
__uninitialized_copy_n(RandomAccessIterator first, Size count, ForwardIterator result,
random_access_iterator_tag) // random_access_iterator_tag类型的迭代器
{
RandomAccessIterator last = first + count;
return make_pair(last, uninitialized_copy(first, last, result));
} uninitialized_fill功能 : 从first到last范围内的都填充为 x 的值.
uninitialized_fill采用了与uninitialized_copy一样的处理方法选择最优处理函数, 这里就不过多的分析了
template
inline void uninitialized_fill(ForwardIterator first, ForwardIterator last, const T& x)
{
__uninitialized_fill(first, last, x, value_type(first));
}
template
inline void __uninitialized_fill(ForwardIterator first, ForwardIterator last, const T& x, T1*)
{
typedef typename __type_traits::is_POD_type is_POD;
__uninitialized_fill_aux(first, last, x, is_POD());
}
template
inline void
__uninitialized_fill_aux(ForwardIterator first, ForwardIterator last, const T& x, __true_type)
{
fill(first, last, x);
}
template
void
__uninitialized_fill_aux(ForwardIterator first, ForwardIterator last, const T& x, __false_type)
{
ForwardIterator cur = first;
__STL_TRY {
for ( ; cur != last; ++cur)
construct(&*cur, x);
}
__STL_UNWIND(destroy(first, cur));
} uninitialized_fill_n功能 : 从first开始n 个元素填充成 x 值
template
inline ForwardIterator uninitialized_fill_n(ForwardIterator first, Size n, const T& x)
{
return __uninitialized_fill_n(first, n, x, value_type(first));
}
template
inline ForwardIterator __uninitialized_fill_n(ForwardIterator first, Size n, const T& x, T1*)
{
typedef typename __type_traits::is_POD_type is_POD;
return __uninitialized_fill_n_aux(first, n, x, is_POD());
}
template
inline ForwardIterator __uninitialized_fill_n_aux(ForwardIterator first, Size n, const T& x, __true_type)
{
return fill_n(first, n, x);
}
template
ForwardIterator __uninitialized_fill_n_aux(ForwardIterator first, Size n, const T& x, __false_type)
{
ForwardIterator cur = first;
__STL_TRY
{
for ( ; n > 0; --n, ++cur)
construct(&*cur, x);
return cur;
}
__STL_UNWIND(destroy(first, cur));
}
uninitialized_copy是为两段内存进行复制的函数, uninitialized_fill是为对一段内存进行初始化一个值的函数. 两者都对了traits编程中的迭代器类型和__type_traits定义的__false_type和__true_type的不同执行不同的处理函数, 也使效率最优化