大数据ClickHouse进阶(六):Distributed引擎深入了解

文章目录
Distributed引擎深入了解
一、简单介绍
二、分布式表插入数据
三、分片规则
四、删除分布式表
Distributed引擎深入了解
一、简单介绍
Distributed引擎和Merge引擎类似,本身不存放数据,功能是在不同的server上把多张相同结构的物理表合并为一张逻辑表。
Distributed分布式引擎语法:
Distributed(cluster_name, database_name, table_name[, sharding_key])对以上语法解释:
- cluster_name:集群名称,与集群配置文件metrika.xml中的自定义名称相对应。
- database_name:数据库名称。
- table_name:表名称。
- sharding_key:可选的,用于分片的key值,在数据写入的过程中,分布式表会依据分片key的规则,将数据分布到各个节点的本地表。
注意:创建分布式表是读时检查的机制,也就是说对创建分布式表和本地表的顺序并没有强制要求。
我们在ClickHouse集群中各个节点上创建好了本地表person_socre,每个节点上也有不同的数据,我们需要创建分布式表来映射当前表所有数据,方便查询数据结果,如下图所示:
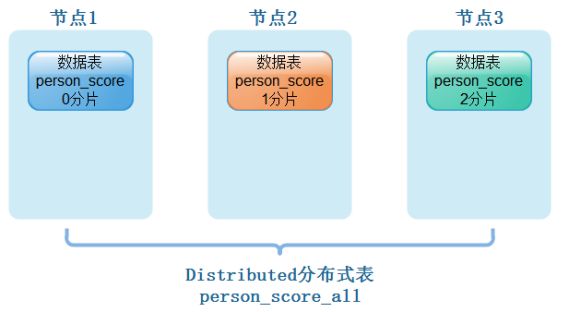
从实体表层面上来看,一张分片表由两部分组成:
- 本地表:通常以_local为后缀进行命名。本地表是承接数据的载体,可以使用非Distributed的任意表引擎,一张本地表对应了一个数据分片。
- 分布式表:通常以_all为后缀进行命名,分布式表只能使用Distribute表引擎,它与本地表形成一对多的映射关系,日后将通过分布式表代理操作多张本地表。
创建person_score_all分布式表:
Create table person_score_all on cluster ClickHouse_cluster_3shards_1replicas (
id UInt32,
name String,
age UInt32,
gender String,
score Decimal(9,2)
)engine = Distributed(ClickHouse_cluster_3shards_1replicas,default,person_score,id);任意一台ClickHouse节点查询分布式表person_score_all中的数据:
select * from person_score_all;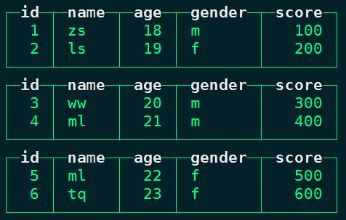
有了分布式表之后,我们就可以向分布式表中插入数据,那么分布式表会根据配置的sharding_key将数据写入到不同的节点分片中。
二、分布式表插入数据
在任意节点向分布式表person_score_all中插入数据:
insert into person_score_all values (7,'a1',30,'f',1000),(8,'a2',31,'f',1001),(9,'a3',32,'f',1002),(10,'a4',33,'f',1003),(11,'a5',34,'f',1004),(12,'a6',35,'f',1005);任意节点查询对应的person_score_all表:
select * from person_score_all;
#可以针对每张本地表进行optimize 合并数据,不能针对分布式表进行合并
#在node1上执行如下命令
node1 :) optimize table person_score;
#在node2上执行如下命令
node1 :) optimize table person_score;
#在node3上执行如下命令
node1 :) optimize table person_score;
#最终查询分布式表person_score_all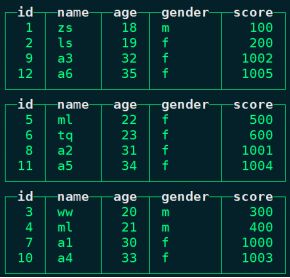
三、分片规则
分片键sharding_key要求返回一个整形类型的取值,包括Int系列和UInt系列,分片键sharding_key可以使如下几种情况:
可以是一个具体的整形列字段:
Distributed(cluster,database,table,userid)可以按照随机数划分:
Distributed(cluster,database,table,rand())可以按照某个整形列进行散列值划分:
Distributed(cluster,database,table,intHash64(userid))注意:如果不声明分片键,那么分布式表只能包含一个分片,这意味着只能映射一张本地表,否则,在写入数据时将会报错。如果分布式表只包含一个分片,也就失去了分布式的意义,所以虽然分片键是选填参数,但是通常都会按照业务规则进行设置。
四、删除分布式表
删除分布式表person_score_all,任意ClickHouse节点直接执行如下命令:
drop table person_score_all on cluster ClickHouse_cluster_3shards_1replicas;- 博客主页:https://lansonli.blog.csdn.net
- 欢迎点赞 收藏 ⭐留言 如有错误敬请指正!
- 本文由 Lansonli 原创,首发于 CSDN博客
- 停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨