算法工程师面经 —— python 面试常问问题
文章目录
- ☆ 文章前言
- 85道精品面试题
-
- 1. 什么是解释型语言,什么是编译型语言?
- 2. python 的运行过程?
- 3. Python 的作用域?
- 4. python 的数据结构?
- 5. python 可变与不可变类型?
- 6. 进程与线程?
- 7. python 中的多线程?
- 8. python 中的多进程?
- 9. python 互斥锁与死锁?
- 10. Lambda?
- 11. python 的深拷贝与浅拷贝?
- 12. python 多线程是否能用多个CPU?
- 13. python 垃圾回收机制?
- 14. python 里的生成器?
- 15. Python 迭代器
- 15. 迭代器与生成器的区别?
- 16. python 列表 pop, remove、 del 等用法的区别?
- 17. 什么是闭包?
- 18. Python 装饰器?
- 19. Python 中 yield 和 return 的区别?
- 20. Python 中 set 的底层实现?
- 21. Python 中 dict 与 set 区别?
- 22. Python 中 __ init __ 和 __ new __ 和 __ call__ 的区别?
- 23. Python 内存管理?
- 24. Python 中类方法和静态方法的区别?
- 25. 点积和矩阵相乘的区别?
- 26. Python 中错误和异常处理?
- 27. Python 中 try else 与 finally 区别?
- 28. 什么是猴子补丁?
- 29. Python 中的 is 和 == 的区别?
- 30. GBK 和 UTF-8的区别?
- 31. 遍历字典的方法?
- 32. 反转列表的方法?
- 33. 元组转为字典的方法?
- 34. init.py 文件的作用与意义?
- 35. 函数调用参数的传递方式是值传递还是引用传递?
- 36. 对缺省参数的理解?
- 37. 你知道的列表去重的所有方式?
- 38. Python 常见的列表推导式?
- 39. map 和 reduce 函数?
- 40. hasattr()、getattr()、setattr() 函数的使用详解?
- 41. except 的作用和用法?
- 42. 在 except 中 return 后还会不会执行 finally 中的代码?怎么抛出自定义异常?
- 43. 什么是断言?
- 44. 如何理解 Python 中字符串的 \ 字符?
- 45. Python 是如何进行类型转换的?
- 46. 提高 Python 运行效率的方法?
- 47. Python 中的 any() 和 all() 方法?
- 48. Python 中什么元素为假?
- 49. Python 中的列表和元组有什么区别?
- 50. Python 的主要功能是什么?
- 51. Python 是通用编程语言吗?
- 52. 什么是 pep?
- 53. Python 中的命名空间是什么?
- 54. 什么是 PYTHONPATH?
- 55. 什么是 Python 模块?Python 中有哪些常用的内置模块?
- 56. Python 数组和列表有什么区别?
- 57. Python 中的 self 是什么?
- 58. range&xrange 有什么区别?
- 59. 什么是 pickling 和 unpickling?
- 60. Python 是如何进行内存管理的?
- 61. 谈谈装饰器?
- 62. Python 如何定义一个私有变量?
- 63. 为什么使用装饰器?
- 64. Python 如何实现单例模式?
- 65. Python 如何实现多线程?
- 66. Python多线程的限制?多进程中如何传递参数?
- 67. 解释下继承?
- 68. Python 中 pass 语句的作用是什么?
- 69. *arg 与 **kwarg 的作用?
- 70. Python 里面 match() 和 search() 的区别?
- 71. 单引号,双引号,三引号的区别?
- 72. Python 的局限性?
- 72. Python 是否有 main 函数?
- 73. iterables 和 iterators 之间的区别?
- 74. Python中 OOPS 是什么?
- 75. 什么是抽象?
- 76. 什么是封装?
- 77. 什么是多态?
- 78. Python 中使用的 zip 函数是什么?
- 79. 装饰器的作用和功能?
- 80. 简单谈下GIL?
- 81. find 和 grep?
- 82. python字符串格式化中,%s和.format的主要区别是什么?
- 83. 请描述Unicode,UTF-8,GBK之间的关系?
- 84. eval 和 exce 的区别 ?
- 85. cookie 和 session 的区别?
☆ 文章前言
~~~~ 本文内容收集整理了各大平台与博主大佬的面试题,并融入了部分个人理解,由于平台数量较多,不便逐一引用,在此郑重向各位大佬致谢,Solute!
85道精品面试题
1. 什么是解释型语言,什么是编译型语言?
~~~~ 1.Python是一种解释型编程语言,Java 和 C++ 编译型语言
~~~~ 2. 计算机不能直接理解高级语言,只能直接理解机器语言,所以必须要把高级语言翻译成机器语言(也就是机器码),计算机才能执行高级语言编写的程序。
~~~~ 3. 解释性语言在运行程序的时候才会进行翻译,每次都需要将源代码进行翻译为机器码,效率低。
~~~~ 4. 编译型语言写的程序在执行之前,需要一个专门的编译过程,把程序编译成机器语言(可执行文件,比如exe文件),以后要运行的话就不用重新翻译了,直接使用编译的结果就行了(exe文件),一次编译,多次执行,效率高。
注:
~~~~ 1.跨平台的意思是最终生成的软件直接可以在各个平台使用。编译型语言需要为不同的平台编译后生成各平台不同的可执行文件。跨平台不是说各平台下要重新写新的代码,而是代码可以一样的,但是需要经过不同的处理后才能在各平台运行。而解释型语言就需要平台提供相应的解释器即可。
~~~~ 2.部分解释型语言的解释器通过在运行时动态优化代码,甚至能够使解释型语言的性能超过编译型语言
~~~~ 解释型语言和编译型语言详细介绍
2. python 的运行过程?
Python程序在解释器上执行分两个过程:
编译:~~~~ 当 Python 程序运行时,将编译的过程结果存放至内存中的 PyCodeObject 中,当程序运行结束后,Python 解释器将 PyCodeObject 回写到 .pyc 文件中,即首先把程序的字节码保存为一个以 .pyc 为扩展名的文件。作为一种启动速度的优化。下一次运行程序时,如果上没有修改过源码的话,Python 将会加载 .pyc 文件并跳过编译这个步骤。
执行:
~~~~ 当程序编译成字节码后,发送到 Python 虚拟机上来执行。虚拟机是 Python 的运行引擎。是 Python 解释器的最后一步。
注:解释器即让其他程序运行起来的程序,是代码与机器的计算机硬件之间的软件逻辑层。Python 也是一个名为解释器的软件包。
~~~~ python执行过程
3. Python 的作用域?
Python中的作用域分4种情况:
L : local,局部作用域,即函数中定义的变量;
E : enclosing,嵌套的父级函数的局部作用域,即包含此函数的上级函数的局部作用域;
G : global,全局变量,就是模块级别定义的变量;
B : built-in,系统固定模块里面的变量,比如 int、byte、array 等。搜索变量的优先级顺序依次是:局部作用域 > 外层作用域 > 当前模块中的全局 > Python内置作用域,也就是LEGB。~~~~ 小结:
~~~~ 内部作用域要修改外部作用域变量的值时,全局变量要使用 global 关键字,嵌套作用域变量要使用 nonlocal 关键字。nonlocal 是 Python3 新增的关键字,有了这个 关键字,就能完美的实现闭包了。
~~~~ python作用域
x = int(2.9) # int built-in
g_count = 0 # global
def outer():
o_count = 1 # enclosing
def inner():
i_count = 2 # local
print(o_count)
# print(i_count) 找不到
inner()
outer()
# print(o_count) #找不到
4. python 的数据结构?
Python 中的绝大部分数据结构可以被最终分解为三种类型:集合(Set),序列(Sequence),映射(Mapping)。
1、集合是独立于标量,序列和映射之外的特殊数据结构,它支持数学理论的各种集合的运算。它的存在使得用程序代码实现数学理论变得方便。
2、序列是Python中最为基础的内建类型。它分为七种类型:列表、字符串、元组、Unicode 字符串、字节数组、缓冲区和 xrange 对象。常用的是:列表(List) 、字符串(String)、元组(Tuple)。
3、映射在 Python 的实现是数据结构字典(Dictionary)。作为第三种基本单位,映射的灵活使得它在多种场合中都有广泛的应用和良好的可拓展性。~~~~ xrange介绍:即通过内部实现getitem,index 等方法,让对象实现索引切片等操作
~~~~ 基本数据类型的操作强推
~~~~ 注:元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用;字典中的键是不可变的,所以列表这一类来充当键值是不行的;字典也有推导式;同时也有集合推导式
5. python 可变与不可变类型?
Python 可变类型是列表、集合、字典,不可变有字符串、元组、数字。
可变与不可变类型
6. 进程与线程?
~~~~ 进程:一个运行的程序(代码)就是一个进程,没有运行的代码叫程序,进程是系统资源分配的最小单位,进程拥有自己独立的内存空间,所有进程间数据不共享,开销大。
~~~~ 线程: cpu调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程存在,一个进程至少有一个线程,叫主线程,而多个线程共享内存(数据共享,共享全局变量),从而极大地提高了程序的运行效率。
~~~~ 进程与线程的理论
~~~~ 进程与线程的运用
7. python 中的多线程?
~~~~ Python 在任意时刻,只有一个线程在解释器中运行。对 Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同—时刻只有一个线程在运行。
~~~~ 多线程共享主进程的资源,所以可能还会改变其中的变量,这个需加上线程锁,每次执行完一个线程再执行下一个线程。
~~~~ 一个CPU在同一个时刻只能执行一个线程,但是当遇到 I/O 操作或者运行一定的代码量的时候就会释放全局解释器锁,执行另外一个线程。
~~~~ python 中的多线程详解
8. python 中的多进程?
~~~~ Python中的多进程是通过 multiprocessing 包来实现,每个进程中所有数据((包括全局变量)都各自拥有一份,互不影响。它可以利用 Process 类来创建一个进程对象。
~~~~ 进程对象的方法和线程对象的方法差不多,也有 start)、run()、join()等,但是,Thread 线程对象中的守护线程方法是 setDeamon ,而 Process 进程对象的守护进程是通过设置 daemon 属性来完成。
python 中的多进程
9. python 互斥锁与死锁?
~~~~ 互斥锁:即确保某段关键代码的数据只能又一个线程从头到尾完整执行,保证了这段代码数据的安全性,但是这样就会导致死锁。
~~~~ 死锁:多个子线程在等待对方解除占用状态,但是都不先解锁,互相等待,这就是死锁。
~~~~ python 互斥锁与死锁
10. Lambda?
~~~~ lambda函数是一个可以接收任意多个参数(包括可选参数)并且返回单个表达式值的函数
~~~~ 1.lambda函数比较轻便,即用即仍,很适合需要完成一项功能,但是此功能只在此一处使用,连名字都很随意的情况下
~~~~ 2.匿名函数,一般用来给filter,map这样的函数式编程服务lambda函数是一个可以接收任意多个参数(包括可选参数)并且返回单个表达式值的函数
~~~~ 3.作为回调函数,传递给某些应用,比如消息处理
~~~~ Lambda
11. python 的深拷贝与浅拷贝?
注:浅拷贝中,调用 copy 函数,当改变原有序列,copy 的对象不会改变,单改变 copy 后的对象,原序列也会跟着改变
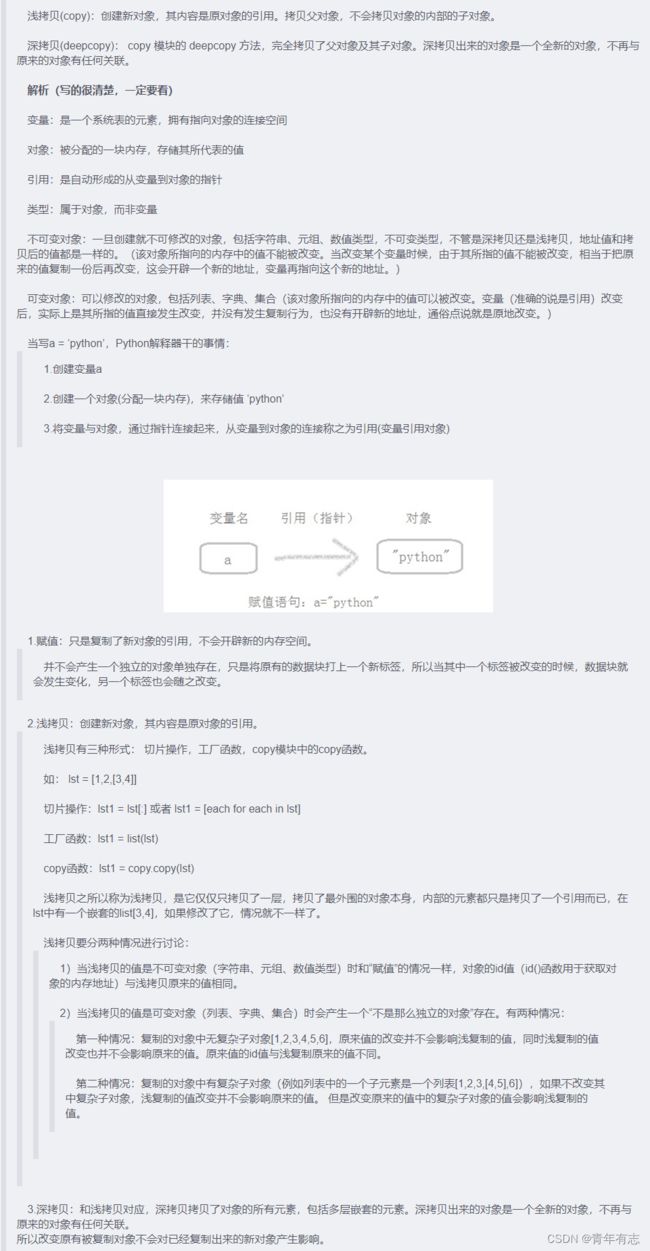
Python 深拷贝与浅拷贝
12. python 多线程是否能用多个CPU?
~~~~ Python 的多线程不能利用多核CPU。
~~~~ 因为 Python 解释器使用了 GIL(Global lnterpreter Lock),在任意时刻中只允许单个 Python 线程运行。无论系统有多少个 CPU 核心,Python 程序都只能在一个 CPU 上运行。
~~~~ 注:GIL的功能是:在 CPython 解释器中执行的每一个 Python 线程,都会先锁住自己,以阻止别的线程执行。
13. python 垃圾回收机制?

Python 垃圾回收机制
14. python 里的生成器?
~~~~ 生成器可以用于返回函数的中间结果像,常规函数一样撰写,但是在需要返回数据时使用 yield 语句。每当对它调用 next() 函数,生成器从它上次停止的地方重新开始 ( 它会记住所有的数据值和上次执行的语句 )。
~~~~ 一边循环一边计算的机制,不像列表创建出来就占了全部空间,极大的节约了内存空间
~~~~ 生成器详解
~~~~ 生成器中的 send 方法
~~~~ send 方法续
15. Python 迭代器
Python 迭代器的理解与使用
15. 迭代器与生成器的区别?
迭代器:
~~~~ 1. 是Python最强大的功能之一,是访问集合元素的一种方式;
~~~~ 2. 迭代器是一个可以记住遍历位置的对象;
~~~~ 3. 迭代器从集合的第一个元素来开始访问,直到访问完所有的元素,只能向前,不能后退;
~~~~ 4. 迭代器有两个方法:next()和 iter()。生成器:
~~~~ 1. python中,使用了yield的函数,被称为生成器;
~~~~ 2. 与普通函数不同,生成器返回的是一个迭代器对象,用于迭代;
~~~~ 3. 在调用生成器运行过程中,每次遇到yield就暂停,并保存当前所有的运行信息,返回yield值,并在下一次执行next()时从当前位置继续执行;
~~~~ 4. 调用一个生成器,返回迭代器对象。

迭代器与生成器的区别
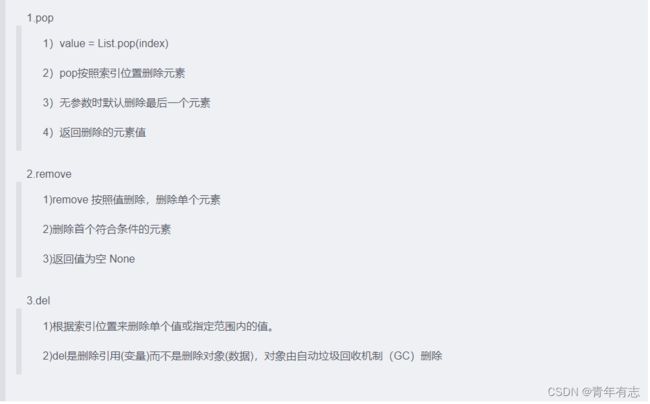
16. python 列表 pop, remove、 del 等用法的区别?
17. 什么是闭包?
—句话说就是,在函数中再嵌套一个函数,并且引用外部函数的变量,最终返回函数内层函数,这就是一个闭包
def outer(x):
def inner(y):
return x + y
return inner
print(outer(6)(5))
-----------------------------
>>>11
~~~~ 如代码所示,在 outer 函数内,又定义了一个 inner 函数,并且 inner 函数又引用了外部函数 outer 的变量 x (自由变量),这就是一个闭包了。在输出时, outer(6)(5),第一个括号传进去的值返回 inner 函数,其实就是返回 6+y,所以再传第二个参数进去,就可以得到返回值,6+5。
~~~~ 闭包介绍
~~~~ 闭包解释
18. Python 装饰器?

装饰器详解必读
19. Python 中 yield 和 return 的区别?
~~~~ 共同点:return 和 yield 都用来返回值;在一次性地返回所有值场景中 return 和 yield 的作用是一样的。
~~~~ 不同点:如果要返回的数据是通过 for 等循环生成的迭代器类型数据(如列表、元组),return 只能在循环外部一次性地返回,yeild 则可以在循环内部逐个元素返回( yield 函数会暂停并保存当前所有的运行信息,返回 yield 的值,并在下一次执行 next() 方法时从当前位置继续运行)
~~~~ 区别
20. Python 中 set 的底层实现?
~~~~ 散列表(哈希表)。set 只是默认键和值是相同的
~~~~ 注:散列表是根据关键字而直接进行访问值的数据结构。也就是说散列表建立了关键字和存储地址之间的一种直接映射关系。
~~~~ set 的底层实现
21. Python 中 dict 与 set 区别?
~~~~ 1.字典是一系列无序的键值对的组合;集合 set() 里的元素默认键值是一样的,是单一的一个元素。
~~~~ 2.从 python3.6 后,字典有序;集合无序
~~~~ 3.字典键不能重复; set() 集合内元素不能重复
~~~~ 注: set 内的元素必须是不可变类型, dict 中的键也必须是不可变类型,不能是列表这类
~~~~ 字典与 set 区别必看系列
22. Python 中 __ init __ 和 __ new __ 和 __ call__ 的区别?
~~~~ __init__是初始化方法,
~~~~ __new__实例化对象
~~~~ __call__允许一个类的实例像函数一样被调用。实质上说,这意味着 x() 与 x.cal() 是相同
~~~~ 构造方法 = 创建对象 + 初始化对象 = new + init
~~~~ __new__方法是在实例创建之前被调用,是一个静态方法,主要的功能就是创建一个类的实例并返回
~~~~ __init__方法是在实例创建之后被调用,主要的功能是设置实例的一些属性初始值
~~~~ 实际测试:__new__在__init__之前被调用,__new__的返回值 ( 实例 ) 将传递给__init__方法的第一个参数 ( self ),然后__init__给这个实例 ( self ) 设置—些参数
~~~~ 更细致的讲解
23. Python 内存管理?
~~~~ 1.垃圾回收
~~~~ 2.引用计数
~~~~ 3.内存池机制
~~~~ python 内存管理
24. Python 中类方法和静态方法的区别?
~~~~ Python 类方法和实例方法相似,它最少也要包含一个参数,只不过类方法中通常将其命名为 cls,Python 会自动将类本身绑定给 cls 参数(注意,绑定的不是类对象)。也就是说,在调用类方法时,无需显式为 cls 参数传参。
~~~~ 静态方法没有类似 self、cls 这样的特殊参数,因此 Python 解释器不会对它包含的参数做任何类或对象的绑定。也正因为如此,类的静态方法中无法调用任何类属性和类方法。
~~~~ 实例方法只能被实例对象调用 ( Python3 中,如果类调用实例方法,需要显示的传 self,也就是实例对象自己),静态方法(由 @staticmethod 装饰的方法)、类方法(由 @classmethod 装饰的方法),可以被类或类的实例对象调用。
~~~~ 实例方法,第一个参数必须要默认传实例对象,一般习惯用 self。 静态方法,参数没有要求。 类方法,第一个参数必须要默认传类,一般习惯用 cls。
~~~~ 参考
25. 点积和矩阵相乘的区别?
~~~~ 点积:维度完全—致的两个向量相乘,得到一个标量
~~~~ 矩阵相乘:需要满足维度匹配才可以进行乘积,XN NY==>X*Y,得到的依然是一个矩阵
26. Python 中错误和异常处理?
~~~~ Python中会发生两种类型的错误。
~~~~ 1、语法错误:如果未遵循正确的语言语法,则会引发语法错误。
~~~~ 2、逻辑错误(异常)︰在运行时中,通过语法测试后发生错误的情况称为异常或逻辑类型。~~~~ 异常处理
~~~~ 通过使用 try…except 来处理异常状况。一般来说会把通常的语句放在 try 代码块中,将错误处理器代码放置在 except 代码块中。
~~~~ Python 错误和异常处理
27. Python 中 try else 与 finally 区别?
~~~~ try …else 语句:else 语句是在 try 语句中的代码没有任何异常的情况下,再执行 else 语句下的代码。
~~~~ try…finally 语句 : finally 语句就是不管上面有没有异常,都要执行 finally 语句下的代码,通常是做一些必须要释放的资源的代码,最典型的就是文件操作和数据库操作。
~~~~ 抛出异常 raise:raise 语句是抛出一个指定的异常。
28. 什么是猴子补丁?
~~~~ 所谓的猴子补丁的含义是指在动态语言中,不去改变源码而对功能进行追加和变更。即在导入模块后,用自己的代码去替换模块的源代码。
~~~~ 大佬详解
29. Python 中的 is 和 == 的区别?
~~~~ is 比较的是两个对象的 id 值是否相等,也就是比较两个对象是否为同一个实例对象,是否指向同一个内存地址。
~~~~ == 比较的是两个对象的内容是否相等,默认会调用对象的 eq() 方法。
30. GBK 和 UTF-8的区别?
~~~~ GBK 是在国家标准 GB2312 基础上扩容后兼容 GB2312 的标准。GBK 编码专门用来解决中文编码的,是双字节的。不论中英文都是双字节的。
~~~~ UTF-8 编码是用以解决国际上字符的一种多字节编码,它对英文使用 8 位(即一个字节),中文使用 24 位(三个字节)来编码。对于英文字符较多的论坛则用 UTF-8 节省空间。另外,如果是外国人访问 GBK 网页,需要下载中文语言包支持。访问 UTF-8 编码的网页则不出现这问题。可以直接访问。
~~~~ GBK 包含全部中文字符; UTF-8 则包含全世界所有国家需要用到的字符。
~~~~ GBK 和 UTF-8 的区别
31. 遍历字典的方法?
dic1 = {'date':'2018.11.2','name':'carlber','work':"遍历",'number':3}
for i in dic1:
print(i)
for key in dic1.keys(): #遍历字典中的键
print(key)
for value in dic1.values(): #遍历字典中的值
print(value)
for item in dic1.items(): #遍历字典中的元素
print(item)
32. 反转列表的方法?
# 1. 内建函数reversed()
li=[1,2,3,4,5,6]
a= list(reversed(li))
# 2. 内建函数sorted()
li=[1,2,3,4,5,6]
c=sorted(a, reverse=True)
# 3. 使用分片[::-1]
li=[1,2,3,4,5,6]
li[::-1]
33. 元组转为字典的方法?
#create a tuple
tuplex = ((2, "w"),(3, "r"))
print(dict((y, x) for x, y in tuplex))
34. init.py 文件的作用与意义?
~~~~ 这个文件定义了包的属性和方法,它可以什么也不定义;可以只是一个空文件,但是必须存在。
~~~~ 如果 init.py 不存在,这个目录就仅仅是一个目录,而不是一个包,它就不能被导入或者包含其它的模块和嵌套包。
~~~~ 或者可以这样理解。这样,当导入这个包的时候,init.py 文件自动运行。帮导入了这么多个模块,就不需要将所有的 import 语句写在—个文件里了,也可以减少代码量。
~~~~ 详情
35. 函数调用参数的传递方式是值传递还是引用传递?
~~~~ Python的参数传递有:位置参数、默认参数、可变参数、关键字参数。 函数的传值到底是值传递还是引用传递、要分情况:
~~~~ 不可变参数用值传递:像整数和字符串这样的不可变对象,是通过拷贝进行传递的,因为你无论如何都不可能在原处改变不可变对象。
~~~~ 可变参数是引用传递:比如像列表,字典这样的对象是通过引用传递、和 C 语言里面的用指针传递数组很相似,可变对象能在函数内部改变。
36. 对缺省参数的理解?
~~~~ 缺省参数指在调用函数的时候没有传入参数的情况下,调用默认的参数,在调用函数的同时赋值时,所传入的参数会替代默认参数。
~~~~ *args 是不定长参数,它可以表示输入参数是不确定的,可以是任意多个。 缺省参数指在调用函数的时候没有传入参数的情况下,调用默认的参数,在调用函数的同时赋值时,所传入的参数会替代默认参数。
~~~~ *args 是不定长参数,它可以表示输入参数是不确定的,可以是任意多个。
~~~~ **kwargs 是关键字参数,赋值的时候是以键值对的方式,参数可以是任意多对在定义函数的时候
~~~~ 不确定会有多少参数会传入时,就可以使用两个参数
37. 你知道的列表去重的所有方式?
def distFunc1(a):
"""使用集合去重"""
a = list(set(a))
print(a)
def distFunc2(a):
"""将一个列表的数据取出放到另一个列表中,中间作判断"""
list = []
for i in a:
if i not in list:
list.append(i)
#如果需要排序的话用sort
list.sort()
print(list)
def distFunc3(a):
"""使用字典"""
b = {}
b = b.fromkeys(a)
c = list(b.keys())
print(c)
if __name__ == "__main__":
a = [1,2,4,2,4,5,7,10,5,5,7,8,9,0,3]
distFunc1(a)
distFunc2(a)
distFunc3(a)
38. Python 常见的列表推导式?
[表达式 for 变量 in 列表]
[表达式 for 变量 in 列表 if 条件]
39. map 和 reduce 函数?
~~~~ map() 是将传入的函数依次作用到序列的每个元素,每个元素都是独自被函数 “作用” 一次。返回的是一个迭代器
~~~~ reduce() 是将传入的函数作用在序列的第一个元素得到结果后,把这个结果继续与下一个元素作用(累积计算)。
~~~~ map(func, 可迭代对象)
~~~~ reduce(func, iterable[, initializer])
~~~~ 注:map() 接收一个参数, reduce() 接收两个参数
~~~~ 一文搞懂 map 和 reduce
map(lambda x: x * x, [1, 2, 3, 4]) # 使用 lambda
# [1, 4, 9, 16]
reduce(lambda x, y: x * y, [1, 2, 3, 4]) # 相当于 ((1 * 2) * 3) * 4
# 24
40. hasattr()、getattr()、setattr() 函数的使用详解?
~~~~ hasattr(object,name) 函数:
~~~~ 判断一个对象里面是否有 name 属性或者 name 方法,返回 bool 值,有 name 属性(方法)返回 True,否则返回 False,
class function_demo(object):
name = 'demo'
def run(self):
return "hello function"
functiondemo = function_demo()
res = hasattr(functiondemo, "name") # 判断对象是否有name属性,True
res = hasattr(functiondemo, "run") # 判断对象是否有run方法,True
res = hasattr(functiondemo, "age") # 判断对象是否有age属性,False
print(res)
~~~~ getattr(object, name[,default]) 函数:
~~~~ 获取对象 object 的属性或者方法,如果存在则打印出来,如果不存在,打印默认值,默认值可选。
~~~~ 注意:如果返回的是对象的方法,则打印结果是:方法的内存地址,如果需要运行这个方法,可以在后面添加括号()
functiondemo = function_demo()
getattr(functiondemo, "name")# 获取name属性,存在就打印出来 --- demo
getattr(functiondemo, "run") # 获取run 方法,存在打印出方法的内存地址
getattr(functiondemo, "age") # 获取不存在的属性,报错
getattr(functiondemo, "age", 18)# 获取不存在的属性,返回一个默认值
~~~~ setattr(object, name, values) 函数:
~~~~ 给对象的属性赋值,若属性不存在,先创建再赋值
class function_demo(object):
name = "demo"
def run(self):
return "hello function"
functiondemo = function_demo()
res = hasattr(functiondemo, "age") # 判断age属性是否存在,False
print(res)
setattr(functiondemo, "age", 18) # 对age属性进行赋值,无返回值
res1 = hasattr(functiondemo, "age") # 再次判断属性是否存在,True
综合使用
class function_demo(object):
name = "demo"
def run(self):
return "hello function"
functiondemo = function_demo()
res = hasattr(functiondemo, "addr") # 先判断是否存在
if res:
addr = getattr(functiondemo, "addr")
print(addr)
else:
addr = getattr(functiondemo, "addr", setattr(functiondemo, "addr", "北京首都"))
print(addr)
三个函数的使用
41. except 的作用和用法?
~~~~ except:捕获所有异常
~~~~ except:<异常名>:捕获指定异常
~~~~ except:<异常名1,异常名2>:捕获异常1或者异常2
~~~~ except:<异常名>,<数据>:捕获指定异常及其附加的数据
~~~~ except:<异常名1,异常名2>:<数据>:捕获异常名1或者异常名2,及附加的数据
~~~~ 值得一看的常见异常
42. 在 except 中 return 后还会不会执行 finally 中的代码?怎么抛出自定义异常?
~~~~ 不管异常是否发生,finally 中的语句都会执行,所以即使有 return 也会继续处理 finally 中的代码;
~~~~ raise 方法可以抛出自定义异常。
43. 什么是断言?
~~~~ assert 断言——声明其布尔值必须为真判定,发生异常则为假。
~~~~ 详细介绍 Python 中的断言
44. 如何理解 Python 中字符串的 \ 字符?
~~~~ 1、转义字符
~~~~ 2、路径名中用来连接路径名
~~~~ 3、编写太长代码用于手动软换行
45. Python 是如何进行类型转换的?
~~~~ 内置函数封装了各种转换函数,可以使用目标类型关键字强制类型转换
~~~~ 进制之间的转换可以用 int(str’,base=in’) 将特定进制的字符串转换为十进制,再用相应的进制转换函数将十进制转换为目标进制。
46. 提高 Python 运行效率的方法?
~~~~ 1、使用生成器,因为可以节约大量内存
~~~~ 2、循环代码优化,避免过多重复代码的执行
~~~~ 3、核心模块用 Cython PyPy 等,提高效率
~~~~ 4、多进程、多线程、协程
~~~~ 5、多个 if elif 条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率
47. Python 中的 any() 和 all() 方法?
~~~~ any():只要迭代器中有一个元素为真就为真
~~~~ all():迭代器中所有的判断项返回都是真,结果才为真
~~~~ 代码举例
48. Python 中什么元素为假?
~~~~ 0、空字符串、空列表、空字典、空元组、None、False
49. Python 中的列表和元组有什么区别?
~~~~ 1. 列表是动态的,属于可变序列,它的元素可以随时增加、修改或者删除,而元组是静态的,属于不可变序列,无法增加、删除、修改元素,除非整体替换。
~~~~ 2. 列表可以使用 append()、extend()、insert()、remove() 和 pop() 等方法实现添加和修改列表元素,而元组则没有这几个方法,因为不能向元组中添加和修改元素。同样,也不能删除元素,可以整体替换。
~~~~ 3. 列表可以使用切片访问和修改列表中的元素。元组也支持切片,但是它只支持通过切片访问元组中的元素,不支持修改。
~~~~ 4. 元组比列表的访问和处理速度快。所以如果只需要对其中的元素进行访问,而不进行任何修改,建议使用元组而不使用列表。
~~~~ 5. 因为列表可以修改,元组不可以修改,因此元组比列表具有更高的安全性。
~~~~ 6. 列表不能作为字典的键,而元组可以。
~~~~ 7. 存储方式不同:空列表比空元组多占用16个字节。
50. Python 的主要功能是什么?
~~~~ 1. Python 是一种解释型语言。与 C 语言等语言不同,Python 不需要在运行之前进行编译。
~~~~ 2. Python 是动态语言,当您声明变量或类似变量时,您不需要声明变量的类型。
~~~~ 3. Python 适合面向对象的编程,因为它允许类的定义以及组合和继承。Python 没有访问说明(如 C++ 的 public,private)。
~~~~ 4. 在 Python 中,函数是第一类对象。它们可以分配给变量。类也是第一类对象
~~~~ 5. 编写 Python 代码很快,但运行比较慢。Python 允许基于 C 的扩展,例如 numpy 函数库。
~~~~ 6. Python 可用于许多领域。Web 应用程序开发、自动化、数学建模、大数据应用程序、人工智能等等。它也经常被用作“胶水”代码。
51. Python 是通用编程语言吗?
~~~~ Python 能够编写脚本,但从一般意义上讲,它被认为是一种通用编程语言。
52. 什么是 pep?
~~~~ PEP 代表 Python Enhancement Proposal。它是一组规则,指定如何格式化 Python 代码以获得最大可读性。
53. Python 中的命名空间是什么?
~~~~ 命名空间指的是变量存储的位置,每一个变量都需要存储到指定的命名空间当中,实际上就是一个字典,是一个专门用来存储变量的字典。
~~~~ 命名空间
~~~~ 命名空间
54. 什么是 PYTHONPATH?
~~~~ 它是导入模块时使用的环境变量。每当导入模块时,也会查找 PYTHONPATH 以检查各个目录中是否存在导入的模块。解释器使用它来确定要加载的模块。
55. 什么是 Python 模块?Python 中有哪些常用的内置模块?
~~~~ Python 模块是包含 Python 代码的 .py 文件。此代码可以是函数类或变量。一些常用的内置模块包括:sys、math、random、data time、JSON。
~~~~ Python 模块详细解答
~~~~ Python 超全常用模块大全
56. Python 数组和列表有什么区别?
~~~~ Python 中的数组和列表具有相同的存储数据方式。但是,数组只能包含单个数据类型元素,而列表可以包含任何数据类型元素。
57. Python 中的 self 是什么?
~~~~ self 是类的实例或对象。在 Python 中,self 包含在第一个参数中。但是,Java 中的情况并非如此,它是可选的。它有助于区分具有局部变量的类的方法和属性。init 方法中的 self 变量引用新创建的对象,而在其他方法中,它引用其方法被调用的对象。
58. range&xrange 有什么区别?
~~~~ 在大多数情况下,xrange 和 range 在功能方面完全相同。它们都提供了一种生成整数列表的方法,唯一的区别是 range 返回一个 Python 列表对象,xrange 返回一个 xrange 对象。这就表示 xrange 实际上在运行时并不是生成静态列表。它使用称为 yielding 的特殊技术根据需要创建值。该技术与生成器的对象一起使用。因此如果你有一个非常巨大的列表,那么就要考虑 xrange, xrange 不会直接生成一个list,而是每次调用返回其中的一个值。
~~~~ 两者区别代码介绍
59. 什么是 pickling 和 unpickling?
~~~~ pickling 是将 Python 对象(甚至是 Python 代码),转换为字符串的过程。
~~~~ unpickling 是将字符串,转换为原来对象的逆过程。
60. Python 是如何进行内存管理的?
~~~~ 1. Python 利用内存池机制用于管理小块内存的申请和释放;
~~~~ 2. 当创建大量占用内存小的对象时,即频繁调用 new / malloc,会导致大量内存碎片,致使效率降低,所以需要内存池机制。
~~~~ 3. 内存池机制需要在内存中预先申请一定数量的、大小相同的内存块留作备用,当有新的内存需求时,先从内存池中给这个需求分配内存,如果不够了,就再重新申请。
~~~~ 内存管理介绍
61. 谈谈装饰器?
~~~~ 1. 本质:闭包函数;
~~~~ 2. 作用:使其他函数在不修改代码的前提下增加额外功能;
~~~~ 3. 返回值:函数对象;
~~~~ 4. 优点:少写很多重复性代码,提高工作效率。
62. Python 如何定义一个私有变量?
~~~~ 1._xx 以单下划线开头的表示的是 protected 类型的变量。即保护类型只能允许其本身与子类进行访问。若内部变量标示,如: 当使用 “from M import” 时,不会将以一个下划线开头的对象引入 。
~~~~ 2. __xx 双下划线的表示的是私有类型的变量。只能允许这个类本身进行访问了,连子类也不可以用于命名一个类属性(类变量),调用时名字被改变(在类 FooBar 内部,__boo 变成 _FooBar__boo,如 self._FooBar__boo)
~~~~ 私有属性详解
63. 为什么使用装饰器?
~~~~ 可以给一个函数增加额外的方法而不用修改原来的代码。 装饰器的功能在于对函数或类功能的增强。
~~~~ 装饰器特点开放封闭原则,即对扩展是开放的,对修改时封闭的;
64. Python 如何实现单例模式?
~~~~ 单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
实现单例模式的几种方式:~~~~ 1.使用模块
~~~~ 2.使用装饰器
~~~~ 3.使用类
~~~~ 4.基于__new__方法实现(推荐使用,方便)
~~~~ 5.基于metaclass方式实现~~~~ 实现单例详解
65. Python 如何实现多线程?
~~~~ Python3 线程中常用的两个模块为:
~~~~ _thread
~~~~ threading (推荐使用)
~~~~ thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 “_thread”。
~~~~ 详细的创建方式
66. Python多线程的限制?多进程中如何传递参数?
~~~~ Python多线程中有 GIL(全局解释锁),意味着任何一个时间只能一个线程使用解释器;
~~~~ 多进程中共享数据,可以使用 multiprocessing.Value 和 multiprocessing.Array
~~~~ 进程共享数据的实现
67. 解释下继承?
~~~~ 1. 一个类继承自另外一个类,也可是说子类继承自父类;
~~~~ 2. 作用:可以使我们重用代码,还有更方便的创建和维护代码;
~~~~ 3. 单继承、多重继承、多级继承、分层继承、混合继承。
~~~~ 继承详解
68. Python 中 pass 语句的作用是什么?
~~~~ 空语句占位符,为了保持程序结构的完整性。
69. *arg 与 **kwarg 的作用?
~~~~ *args 用来将参数打包成 tuple (元组)给函数体调用,如果我们不确定要往函数中传入多少个参数,或者我们想往函数中以列表和元组的形式传参数时,那就使要用 *args.
~~~~ **kwargs 打包关键字参数成 dict (字典)给函数体调用,如果我们不知道要往函数中传入多少个关键词参数,或者想传入字典的值作为关键词参数时,那就要使用 **kwargs.
~~~~ 两者的详细讲解
70. Python 里面 match() 和 search() 的区别?
~~~~ 1. re 模块中 match(pattern,string[,flags]),检查 string 的开头是否与 pattern 匹配;
~~~~ 2. re 模块中 research(pattern,string[,flags]),在 string 搜索 pattern 的第一个匹配值。
~~~~ 函数使用详解
71. 单引号,双引号,三引号的区别?
~~~~ 单引号和双引号没有区别;
~~~~ 三引号则可以直接换行,并且可以包含注释。
72. Python 的局限性?
~~~~ 1. 速度
~~~~ 2. 移动开发
~~~~ 3. 内存消耗(与其他语言相比非常高)
~~~~ 4. 两个版本的不兼容(2,3)
~~~~ 5. 运行错误(需要更多测试,并且错误仅在运行时显示)
~~~~ 6. 简单性
72. Python 是否有 main 函数?
~~~~ 为什么有些编程语言必须编写 main 函数?
~~~~ 一些编程语言将 main 函数作为程序的执行入口,比如 C/C++、C#、Java、Go、Rust 等等,这个函数具有特定的含义:main 函数名是必须的,这意味着必须有一个主函数,且最多只能有一个 main 函数,这意味着程序的入口是唯一的。语法格式有特定要求,书写形式也相对固定。
~~~~ 为什么必须强制 main 函数作为入口?
~~~~ 这些语言都是编译语言,需要将代码编译成可执行的二进制文件。为了让操作系统/引导程序找到程序的开头,需要定义这样一个函数。简而言之,需要在大量可执行的代码中定义一个至关重要的的开头。
~~~~ 结论:
~~~~ Python 是一种解释语言,即脚本语言。运行过程是从上到下,逐行进行的,这意味着它的起点是已知的。每个 .py 文件都是一个可执行文件,可作为整个程序的入口文件,意味着该程序的入口很灵活,而且无需遵循任何约定。
73. iterables 和 iterators 之间的区别?
~~~~ iterable:可迭代是一个对象,可以对其进行迭代。在可迭代的情况下,整个数据一次存储在内存中。
~~~~ iterators:迭代器是用来在对象上迭代的对象。它只在被调用时被初始化或存储在内存中。迭代器使用 next 从对象中取出元素。
~~~~ 区别
# List is an iterable
lst = [1,2,3,4,5]
for i in lst:
print(i)
# iterator
lst1 = iter(lst)
next(lst1)
>1
next(lst1)
>2
for i in lst1:
print(i)
>3,4,5
74. Python中 OOPS 是什么?
~~~~ 面向对象编程,抽象(Abstraction)、封装(Encapsulation)、继承(Inheritance)、多态(Polymorphism)
75. 什么是抽象?
~~~~ 抽象(Abstraction)是将一个对象的本质或必要特征向外界展示,并隐藏所有其他无关信息的过程。
~~~~ 抽象类介绍
76. 什么是封装?
~~~~ 封装(Encapsulation)意味着将数据和成员函数包装在一起成为一个单元。它还实现了数据隐藏的概念。
~~~~ Python 封装详解
77. 什么是多态?
~~~~ 多态(Polymorphism)的意思是「许多形式」。子类可以定义自己的独特行为,并且仍然共享其父类/基类的相同功能或行为。
~~~~ 多态
78. Python 中使用的 zip 函数是什么?
~~~~ zip 函数获取可迭代对象,将它们聚合到一个元组中,然后返回结果。
~~~~ zip() 函数的语法是 zip(*iterables)
numbers = [1, 2, 3]
string = ['one', 'two', 'three']
result = zip(numbers,string)
print(set(result))
-------------------------------------
{(3, 'three'), (2, 'two'), (1, 'one')}
79. 装饰器的作用和功能?
~~~~ 引入日志
~~~~ 函数执行时间统计
~~~~ 执行函数前预备处理
~~~~ 执行函数后的清理功能
~~~~ 权限校验等场景
~~~~ 缓存
80. 简单谈下GIL?
~~~~ Global Interpreter Lock (全局解释器锁)
~~~~ Python 代码的执行由 Python 虚拟机(也叫解释器主循环,CPython版本)来控制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对 Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
~~~~ 在多线程环境中,Python 虚拟机按以下方式执行:
~~~~ 1.设置GIL
~~~~ 2.切换到一个线程去运行
~~~~ 3.运行:a. 指定数量的字节码指令,或者 ;b. 线程主动让出控制(可以调用time.sleep(0))
~~~~ 4.把线程设置为睡眠状态
~~~~ 5.解锁GIL
~~~~ 6.再次重复以上所有步骤~~~~ 在调用外部代码(如 C/C++ 扩展函数)的时候,GIL 将会被锁定,直到这个函数结束为止(由于在这期间没有Python
的字节码被运行,所以不会做线程切换)。
81. find 和 grep?
~~~~ grep命令是一种强大的文本搜索工具,grep搜索内容串可以是正则表达式,允许对文本文件进行模式查找。如果找到匹配模式,grep打印包含模式的所有行。
~~~~ find通常用来再特定的目录下搜索符合条件的文件,也可以用来搜索特定用户属主的文件。
82. python字符串格式化中,%s和.format的主要区别是什么?
~~~~ Python 用一个 tuple 将多个值传递给模板,每个值对应一个格式符 print(“ my name is %s ,im %d year old”%(“gaoxu”,19))
~~~~ 自 Python2.6 开始,新增了一种格式化字符串的函数 str.format(),通过 {} 和.来代替传统的 %
~~~~ 主要的区别是:不需要指定的字符串还是数字类型
print('ma name is {} ,age is {} year old'.format("小明",17))
print('my name is {1},age is {0}'.format(15,'小明'))
#:位置攒参的方式li=['hollo',18]print('may name is {0},my year old is {1}'.format(*li))
# 按照关键字传参hash={'name':'hoho','age':18}print ('my name is {name},age is {age}'.format(**hash))
83. 请描述Unicode,UTF-8,GBK之间的关系?
Unicode—>encode----->utf-8utf-------->decode------>unicode
84. eval 和 exce 的区别 ?
~~~~ eval有返回值
~~~~ exec没有返回值
print(eval('2+3'))
print(exec('2+1'))exec("print('1+1')")
~~~~ eval 还可以将字符串转化成对象
class obj(object):
passa = eval('obj()')
print(a,type(a)) #<__main__.obj object at 0x000001F1F6897550> 85. cookie 和 session 的区别?
~~~~ 1.session 在服务器,cooking在客户端(浏览器)
~~~~ 2.session默认存在服务器上的文件里面(也可以是内存,数据库)
~~~~ 3.session的运行依赖session_id,而session_id是存在cookie中,也就是说,若果浏览器禁用lcookie,同时session也会失效(但是可以通过其他方式实现,比如在url中传入session_id)
~~~~ 4.session可以放在文件,数据库,内存中都可以的 用户验证通常会用session
维持一个会话核心就是客户端的唯一标识,即session_id