深度学习基础:超分辨率网络整理之EDVR网络
目录
EDVR网络
1.简介
2.超分常见模块
2.1.特征提取-feature extraction
2.2.帧对齐-Alignment.
2.3.融合-Fusion
2.4.重建-reconstruction
3.EDVR模块
3.1整体架构
3.2PCD-帧对齐
3.3 TSA-时空融合
4.结论
5.EDVR模型代码
EDVR网络
1.简介
超分辨率(super-resolution)、去模糊(deblurring)等视频恢复任务越来越受到计算机视觉界的关注。在NTIRE19挑战赛中发布了一个名为REDS的具有挑战性的基准测试。这个新的基准测试从两个方面挑战了现有的方法:
(1)如何在给定大运动的情况下对齐多个帧
(2)如何有效地融合不同运动和模糊的不同帧。
在这项工作中,我们提出了一种新的视频恢复框架,增强可变形卷积,称为EDVR,以解决这些挑战。
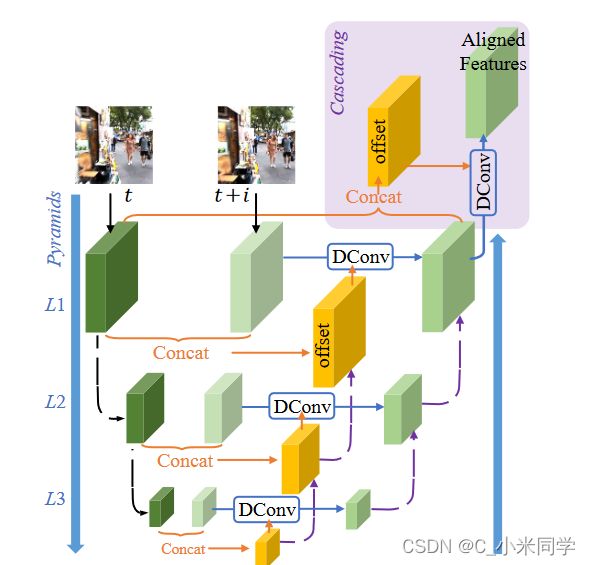
首先,为了处理大型运动,我们设计了一个金字塔、级联和可变形(PCD)对齐模块,在该模块中,帧对齐在特征级使用可变形卷积以从粗到细(coarse-to-fine)的方式完成。
其次,我们提出了一个时空注意(TSA)融合模块,将注意力同时应用于时间和空间上,以强调重要特征,为后续恢复提供依据。
多亏了这些模块,我们的EDVR在NTIRE19挑战赛中视频恢复和增强挑战的所有四个轨道中都获得了冠军,并以较大的优势超过了第二名。EDVR在视频超分辨率和去模糊方面的性能也优于最新发布的方法。
2.超分常见模块
2.1.特征提取-feature extraction
2.2.帧对齐-Alignment.
大多数现有的对准方法都是通过显式估计参考帧和相邻帧之间的光流场来实现的。根据估计的运动场对相邻帧进行变形处理。
另一个研究分支是通过动态滤波或可变形卷积实现隐式运动补偿。reds数据集对现有的对齐算法提出了巨大的挑战。特别是,对于基于流量的方法来说,精确的运动估计和精确的运动补偿是具有挑战性和耗时的。在大运动的情况下,很难在单一分辨率尺度内显式或隐式地进行运动补偿。
2.3.融合-Fusion
融合来自对齐帧的特征是视频恢复任务的另一个关键步骤。现有的大多数方法要么使用卷积对所有帧[进行早期融合,要么采用循环网络逐步融合多个帧。Liu等人提出了一种时间自适应网络,可以动态融合不同时间尺度。这些现有的方法都没有考虑到每个帧上潜在的视觉信息量——不同的帧和位置对重建的信息量并不相同或有益,因为一些帧或区域会受到不完全对齐和模糊的影响。(这里是不是读出了注意力机制的味道?)
2.4.重建-reconstruction
3.EDVR模块
3.1整体架构

上图是EDVR框架。它是一个统一的框架,适用于各种视频恢复任务,如超分辨率和去模糊。对高空间分辨率的输入先进行下采样,以减少计算成本。给定模糊输入,在PCD对齐模块之前插入预模糊模块以提高对齐精度。我们使用三个输入帧作为示例。
以视频SR为例,EDVR以2N+1个低分辨率帧作为输入,生成高分辨率输出。每个相邻帧由PCD对齐模块在特征级别上与参考帧对齐。TSA融合模块对不同帧的图像信息进行融合。然后,融合的特征通过一个重建模块,重建模块是EDVR中残留块的级联,可以很容易地被单幅图像SR中的任何其他高级模块替换。上采样操作在网络的末端执行,以增加空间大小。最后,将预测图像残差加入到直接上采样图像中,得到高分辨率帧Ot。对于其他具有高空间分辨率输入的任务,如视频去模糊,首先使用跨步卷积层对输入帧进行下采样。然后大部分的计算都是在低分辨率空间进行的,这大大节省了计算成本。在最后的上采样层将调整特征的大小回到原始的输入分辨率。在对准模块之前使用预模糊(PreDeblur)模块对模糊输入进行预处理,提高对准精度。虽然单一的EDVR模型可以达到最先进的性能,但我们采用两阶段策略来进一步提高NTIRE19比赛的性能。具体来说,我们用较浅的深度级联相同的EDVR网络,以细化第一阶段的输出帧。级联网络可以进一步消除之前模型无法处理的严重运动模糊。=
3.2PCD-帧对齐
3.3 TSA-时空融合
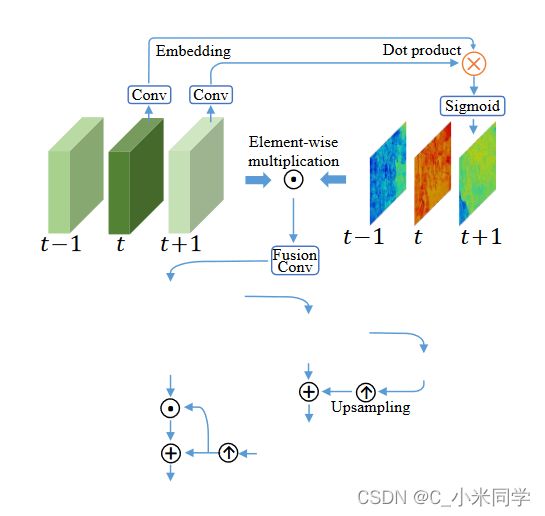
提出的TSA是一个融合模块,有助于跨多个对齐的特征聚合信息。为了更好地考虑每一帧的视觉信息量,我们通过计算参考帧和每一相邻帧特征之间的元素相关性引入时间注意力。然后,相关系数在每个位置上对每个相邻特征进行加权,表明它对重构参考图像的信息量有多大。然后将所有帧的加权特征进行卷积并融合在一起。在与时间注意融合后,我们进一步应用空间注意为每个通道中的每个位置分配权重,以更有效地利用跨通道和空间信息。
4.结论

5.EDVR模型代码
import torch
from torch import nn as nn
from torch.nn import functional as F
from basicsr.utils.registry import ARCH_REGISTRY
from .arch_util import DCNv2Pack, ResidualBlockNoBN, make_layer
#对齐模块
class PCDAlignment(nn.Module):
"""Alignment module using Pyramid, Cascading and Deformable convolution
(PCD). It is used in EDVR.
Ref:
EDVR: Video Restoration with Enhanced Deformable Convolutional Networks
Args:
num_feat (int): Channel number of middle features. Default: 64.
deformable_groups (int): Deformable groups. Defaults: 8.
"""
def __init__(self, num_feat=64, deformable_groups=8):
super(PCDAlignment, self).__init__()
# Pyramid has three levels:
# L3: level 3, 1/4 spatial size
# L2: level 2, 1/2 spatial size
# L1: level 1, original spatial size
self.offset_conv1 = nn.ModuleDict()
self.offset_conv2 = nn.ModuleDict()
self.offset_conv3 = nn.ModuleDict()
self.dcn_pack = nn.ModuleDict()
self.feat_conv = nn.ModuleDict()
# Pyramids
for i in range(3, 0, -1):
level = f'l{i}'
self.offset_conv1[level] = nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1)
if i == 3:
self.offset_conv2[level] = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
else:
self.offset_conv2[level] = nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1)
self.offset_conv3[level] = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.dcn_pack[level] = DCNv2Pack(num_feat, num_feat, 3, padding=1, deformable_groups=deformable_groups)
if i < 3:
self.feat_conv[level] = nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1)
# Cascading dcn
self.cas_offset_conv1 = nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1)
self.cas_offset_conv2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.cas_dcnpack = DCNv2Pack(num_feat, num_feat, 3, padding=1, deformable_groups=deformable_groups)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
def forward(self, nbr_feat_l, ref_feat_l):
"""Align neighboring frame features to the reference frame features.
Args:
nbr_feat_l (list[Tensor]): Neighboring feature list. It
contains three pyramid levels (L1, L2, L3),
each with shape (b, c, h, w).
ref_feat_l (list[Tensor]): Reference feature list. It
contains three pyramid levels (L1, L2, L3),
each with shape (b, c, h, w).
Returns:
Tensor: Aligned features.
"""
# Pyramids
upsampled_offset, upsampled_feat = None, None
for i in range(3, 0, -1):
level = f'l{i}'
offset = torch.cat([nbr_feat_l[i - 1], ref_feat_l[i - 1]], dim=1)
offset = self.lrelu(self.offset_conv1[level](offset))
if i == 3:
offset = self.lrelu(self.offset_conv2[level](offset))
else:
offset = self.lrelu(self.offset_conv2[level](torch.cat([offset, upsampled_offset], dim=1)))
offset = self.lrelu(self.offset_conv3[level](offset))
feat = self.dcn_pack[level](nbr_feat_l[i - 1], offset)
if i < 3:
feat = self.feat_conv[level](torch.cat([feat, upsampled_feat], dim=1))
if i > 1:
feat = self.lrelu(feat)
if i > 1: # upsample offset and features
# x2: when we upsample the offset, we should also enlarge
# the magnitude.
upsampled_offset = self.upsample(offset) * 2
upsampled_feat = self.upsample(feat)
# Cascading
offset = torch.cat([feat, ref_feat_l[0]], dim=1)
offset = self.lrelu(self.cas_offset_conv2(self.lrelu(self.cas_offset_conv1(offset))))
feat = self.lrelu(self.cas_dcnpack(feat, offset))
return feat
#融合模块
class TSAFusion(nn.Module):
"""Temporal Spatial Attention (TSA) fusion module.
Temporal: Calculate the correlation between center frame and
neighboring frames;
Spatial: It has 3 pyramid levels, the attention is similar to SFT.
(SFT: Recovering realistic texture in image super-resolution by deep
spatial feature transform.)
Args:
num_feat (int): Channel number of middle features. Default: 64.
num_frame (int): Number of frames. Default: 5.
center_frame_idx (int): The index of center frame. Default: 2.
"""
def __init__(self, num_feat=64, num_frame=5, center_frame_idx=2):
super(TSAFusion, self).__init__()
self.center_frame_idx = center_frame_idx
# temporal attention (before fusion conv)
self.temporal_attn1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.temporal_attn2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.feat_fusion = nn.Conv2d(num_frame * num_feat, num_feat, 1, 1)
# spatial attention (after fusion conv)
self.max_pool = nn.MaxPool2d(3, stride=2, padding=1)
self.avg_pool = nn.AvgPool2d(3, stride=2, padding=1)
self.spatial_attn1 = nn.Conv2d(num_frame * num_feat, num_feat, 1)
self.spatial_attn2 = nn.Conv2d(num_feat * 2, num_feat, 1)
self.spatial_attn3 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.spatial_attn4 = nn.Conv2d(num_feat, num_feat, 1)
self.spatial_attn5 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.spatial_attn_l1 = nn.Conv2d(num_feat, num_feat, 1)
self.spatial_attn_l2 = nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1)
self.spatial_attn_l3 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.spatial_attn_add1 = nn.Conv2d(num_feat, num_feat, 1)
self.spatial_attn_add2 = nn.Conv2d(num_feat, num_feat, 1)
self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
def forward(self, aligned_feat):
"""
Args:
aligned_feat (Tensor): Aligned features with shape (b, t, c, h, w).
Returns:
Tensor: Features after TSA with the shape (b, c, h, w).
"""
b, t, c, h, w = aligned_feat.size()
# temporal attention
embedding_ref = self.temporal_attn1(aligned_feat[:, self.center_frame_idx, :, :, :].clone())
embedding = self.temporal_attn2(aligned_feat.view(-1, c, h, w))
embedding = embedding.view(b, t, -1, h, w) # (b, t, c, h, w)
corr_l = [] # correlation list
for i in range(t):
emb_neighbor = embedding[:, i, :, :, :]
corr = torch.sum(emb_neighbor * embedding_ref, 1) # (b, h, w)
corr_l.append(corr.unsqueeze(1)) # (b, 1, h, w)
corr_prob = torch.sigmoid(torch.cat(corr_l, dim=1)) # (b, t, h, w)
corr_prob = corr_prob.unsqueeze(2).expand(b, t, c, h, w)
corr_prob = corr_prob.contiguous().view(b, -1, h, w) # (b, t*c, h, w)
aligned_feat = aligned_feat.view(b, -1, h, w) * corr_prob
# fusion
feat = self.lrelu(self.feat_fusion(aligned_feat))
# spatial attention
attn = self.lrelu(self.spatial_attn1(aligned_feat))
attn_max = self.max_pool(attn)
attn_avg = self.avg_pool(attn)
attn = self.lrelu(self.spatial_attn2(torch.cat([attn_max, attn_avg], dim=1)))
# pyramid levels
attn_level = self.lrelu(self.spatial_attn_l1(attn))
attn_max = self.max_pool(attn_level)
attn_avg = self.avg_pool(attn_level)
attn_level = self.lrelu(self.spatial_attn_l2(torch.cat([attn_max, attn_avg], dim=1)))
attn_level = self.lrelu(self.spatial_attn_l3(attn_level))
attn_level = self.upsample(attn_level)
attn = self.lrelu(self.spatial_attn3(attn)) + attn_level
attn = self.lrelu(self.spatial_attn4(attn))
attn = self.upsample(attn)
attn = self.spatial_attn5(attn)
attn_add = self.spatial_attn_add2(self.lrelu(self.spatial_attn_add1(attn)))
attn = torch.sigmoid(attn)
# after initialization, * 2 makes (attn * 2) to be close to 1.
feat = feat * attn * 2 + attn_add
return feat
class PredeblurModule(nn.Module):
"""Pre-dublur module.
Args:
num_in_ch (int): Channel number of input image. Default: 3.
num_feat (int): Channel number of intermediate features. Default: 64.
hr_in (bool): Whether the input has high resolution. Default: False.
"""
def __init__(self, num_in_ch=3, num_feat=64, hr_in=False):
super(PredeblurModule, self).__init__()
self.hr_in = hr_in
self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)
if self.hr_in:
# downsample x4 by stride conv
self.stride_conv_hr1 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
self.stride_conv_hr2 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
# generate feature pyramid
self.stride_conv_l2 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
self.stride_conv_l3 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
self.resblock_l3 = ResidualBlockNoBN(num_feat=num_feat)
self.resblock_l2_1 = ResidualBlockNoBN(num_feat=num_feat)
self.resblock_l2_2 = ResidualBlockNoBN(num_feat=num_feat)
self.resblock_l1 = nn.ModuleList([ResidualBlockNoBN(num_feat=num_feat) for i in range(5)])
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
def forward(self, x):
feat_l1 = self.lrelu(self.conv_first(x))
if self.hr_in:
feat_l1 = self.lrelu(self.stride_conv_hr1(feat_l1))
feat_l1 = self.lrelu(self.stride_conv_hr2(feat_l1))
# generate feature pyramid
feat_l2 = self.lrelu(self.stride_conv_l2(feat_l1))
feat_l3 = self.lrelu(self.stride_conv_l3(feat_l2))
feat_l3 = self.upsample(self.resblock_l3(feat_l3))
feat_l2 = self.resblock_l2_1(feat_l2) + feat_l3
feat_l2 = self.upsample(self.resblock_l2_2(feat_l2))
for i in range(2):
feat_l1 = self.resblock_l1[i](feat_l1)
feat_l1 = feat_l1 + feat_l2
for i in range(2, 5):
feat_l1 = self.resblock_l1[i](feat_l1)
return feat_l1
@ARCH_REGISTRY.register()
class EDVR(nn.Module):
"""EDVR network structure for video super-resolution.
Now only support X4 upsampling factor.
Paper:
EDVR: Video Restoration with Enhanced Deformable Convolutional Networks
Args:
num_in_ch (int): Channel number of input image. Default: 3.
num_out_ch (int): Channel number of output image. Default: 3.
num_feat (int): Channel number of intermediate features. Default: 64.
num_frame (int): Number of input frames. Default: 5.
deformable_groups (int): Deformable groups. Defaults: 8.
num_extract_block (int): Number of blocks for feature extraction.
Default: 5.
num_reconstruct_block (int): Number of blocks for reconstruction.
Default: 10.
center_frame_idx (int): The index of center frame. Frame counting from
0. Default: Middle of input frames.
hr_in (bool): Whether the input has high resolution. Default: False.
with_predeblur (bool): Whether has predeblur module.
Default: False.
with_tsa (bool): Whether has TSA module. Default: True.
"""
def __init__(self,
num_in_ch=3,
num_out_ch=3,
num_feat=64,
num_frame=5,
deformable_groups=8,
num_extract_block=5,
num_reconstruct_block=10,
center_frame_idx=None,
hr_in=False,
with_predeblur=False,
with_tsa=True):
super(EDVR, self).__init__()
if center_frame_idx is None:
self.center_frame_idx = num_frame // 2
else:
self.center_frame_idx = center_frame_idx
self.hr_in = hr_in
self.with_predeblur = with_predeblur
self.with_tsa = with_tsa
# extract features for each frame
if self.with_predeblur:
self.predeblur = PredeblurModule(num_feat=num_feat, hr_in=self.hr_in)
self.conv_1x1 = nn.Conv2d(num_feat, num_feat, 1, 1)
else:
self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)
# extract pyramid features
self.feature_extraction = make_layer(ResidualBlockNoBN, num_extract_block, num_feat=num_feat)
self.conv_l2_1 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
self.conv_l2_2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.conv_l3_1 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
self.conv_l3_2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
# pcd and tsa module
self.pcd_align = PCDAlignment(num_feat=num_feat, deformable_groups=deformable_groups)
if self.with_tsa:
self.fusion = TSAFusion(num_feat=num_feat, num_frame=num_frame, center_frame_idx=self.center_frame_idx)
else:
self.fusion = nn.Conv2d(num_frame * num_feat, num_feat, 1, 1)
# reconstruction
self.reconstruction = make_layer(ResidualBlockNoBN, num_reconstruct_block, num_feat=num_feat)
# upsample
self.upconv1 = nn.Conv2d(num_feat, num_feat * 4, 3, 1, 1)
self.upconv2 = nn.Conv2d(num_feat, 64 * 4, 3, 1, 1)
self.pixel_shuffle = nn.PixelShuffle(2)
self.conv_hr = nn.Conv2d(64, 64, 3, 1, 1)
self.conv_last = nn.Conv2d(64, 3, 3, 1, 1)
# activation function
self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
def forward(self, x):
b, t, c, h, w = x.size()
if self.hr_in:
assert h % 16 == 0 and w % 16 == 0, ('The height and width must be multiple of 16.')
else:
assert h % 4 == 0 and w % 4 == 0, ('The height and width must be multiple of 4.')
x_center = x[:, self.center_frame_idx, :, :, :].contiguous()
# extract features for each frame
# L1
if self.with_predeblur:
feat_l1 = self.conv_1x1(self.predeblur(x.view(-1, c, h, w)))
if self.hr_in:
h, w = h // 4, w // 4
else:
feat_l1 = self.lrelu(self.conv_first(x.view(-1, c, h, w)))
feat_l1 = self.feature_extraction(feat_l1)
# L2
feat_l2 = self.lrelu(self.conv_l2_1(feat_l1))
feat_l2 = self.lrelu(self.conv_l2_2(feat_l2))
# L3
feat_l3 = self.lrelu(self.conv_l3_1(feat_l2))
feat_l3 = self.lrelu(self.conv_l3_2(feat_l3))
feat_l1 = feat_l1.view(b, t, -1, h, w)
feat_l2 = feat_l2.view(b, t, -1, h // 2, w // 2)
feat_l3 = feat_l3.view(b, t, -1, h // 4, w // 4)
# PCD alignment
ref_feat_l = [ # reference feature list
feat_l1[:, self.center_frame_idx, :, :, :].clone(), feat_l2[:, self.center_frame_idx, :, :, :].clone(),
feat_l3[:, self.center_frame_idx, :, :, :].clone()
]
aligned_feat = []
for i in range(t):
nbr_feat_l = [ # neighboring feature list
feat_l1[:, i, :, :, :].clone(), feat_l2[:, i, :, :, :].clone(), feat_l3[:, i, :, :, :].clone()
]
aligned_feat.append(self.pcd_align(nbr_feat_l, ref_feat_l))
aligned_feat = torch.stack(aligned_feat, dim=1) # (b, t, c, h, w)
if not self.with_tsa:
aligned_feat = aligned_feat.view(b, -1, h, w)
feat = self.fusion(aligned_feat)
out = self.reconstruction(feat)
out = self.lrelu(self.pixel_shuffle(self.upconv1(out)))
out = self.lrelu(self.pixel_shuffle(self.upconv2(out)))
out = self.lrelu(self.conv_hr(out))
out = self.conv_last(out)
if self.hr_in:
base = x_center
else:
base = F.interpolate(x_center, scale_factor=4, mode='bilinear', align_corners=False)
out += base
return out