NLP-新闻主题分类任务
在看黑马的NLP的实践项目AI深度学习自然语言处理NLP零基础入门,可能由于版本的原因,完全按照课上的来无法运行,就参考实现了一遍,在这记录一下。
目录
1.用到的包
2.新闻主题分类数据
3.处理数据集
4.构建模型
5.训练
5.1.generate_batch
5.2.训练 & 验证函数
5.3.主流程
windows系统,jupyter notebook,torch:1.11.0+cu113
1.用到的包
import torch
import torchtext
import os
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
import string
import re
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data.dataset import random_split
import time
from torch.utils.data import DataLoader2.新闻主题分类数据
这边按课程的会报错,去网上查了torchtext.datasets.AG_NEWS,但是奇怪的是,看网上的资料会下载数据,我这边电脑里没有数据,不过代码能读到数据,也就没管数据下载不下来的问题了。
load_data_path = "../data"
if not os.path.isdir(load_data_path):
os.mkdir(load_data_path)
train_dataset, test_dataset = torchtext.datasets.AG_NEWS(
root='../data/', split=('train', 'test'))看一下数据:一个样本是一个元组,第一个元素是int类型,表示label,第二个是str类型
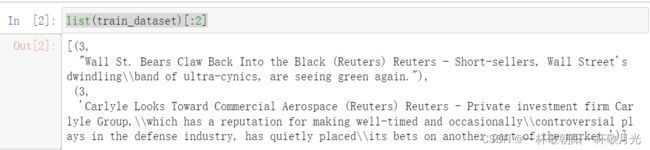
数据基本信息:
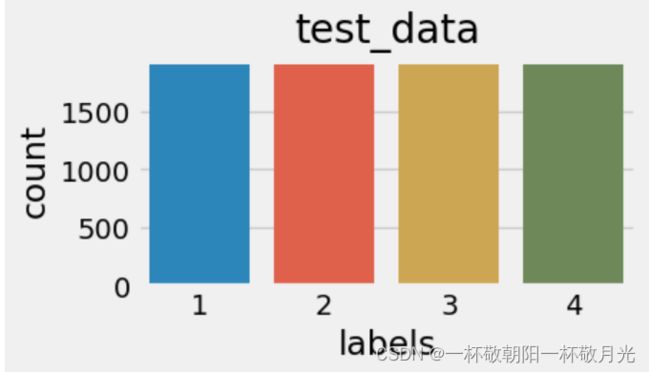
训练集有120000个样本,标签是共有4个取值:1,2,3,4。各类标签在训练集测试集分布比较均匀。

3.处理数据集
功能:1.将\替换成空格(即将其两边的单词拆分成两个单词),将所有字母转换成小写。2.将label转换成[0,3]。3.句子长度截取
punct = str.maketrans('','',string.punctuation)
def process_datasets_by_Tokenizer(train_dataset, test_dataset, seq_len=200):
"""
参数:
train_dataset: 训练样本列表list(tuple(int, str))
返回:
train_dataset: 训练集列表list(tuple(tensor, int))
"""
tokenizer = Tokenizer()
train_dataset_texts, train_dataset_labels = [], []
test_dataset_texts, test_dataset_labels = [], []
for label, text in train_dataset:
# 前面的打印可以看到,存在\\这种,这边替换成空格,并所有的均为小写字母
train_dataset_texts.append(text.replace('\\',' ').translate(punct).lower())
train_dataset_labels.append(label - 1) # 将标签映射到[0,3]
for label, text in test_dataset:
test_dataset_texts.append(text.replace('\\',' ').translate(punct).lower())
test_dataset_labels.append(label - 1)
# 这边图省事,把训练集测试集合在一起构建词表,这样就不存在未登录词了
all_dataset_texts = train_dataset_texts + train_dataset_texts
all_dataset_labels = train_dataset_labels + test_dataset_labels
tokenizer.fit_on_texts(all_dataset_texts)
# train_dataset_seqs 是一个列表,其中的每一个元素是 将句子由文本表示 变换成 词表中的索引表示的列表
train_dataset_seqs = tokenizer.texts_to_sequences(train_dataset_texts)
test_datase_seqs = tokenizer.texts_to_sequences(test_dataset_texts)
# print(type(train_dataset_seqs), type(train_dataset_seqs[0])) #
# print(train_dataset_seqs)
# 截取前seq_len个,不足后面补0
# train_dataset_seqs是一个tensor,size:(样本数目, seq_len)
train_dataset_seqs = torch.tensor(sequence.pad_sequences(
train_dataset_seqs, seq_len, padding='post'), dtype=torch.int32)
test_datase_seqs = torch.tensor(sequence.pad_sequences(
test_datase_seqs, seq_len, padding='post'), dtype=torch.int32)
# print(type(train_dataset_seqs), type(train_dataset_seqs[0])) #
# print(train_dataset_seqs)
train_dataset = list(zip(train_dataset_seqs, train_dataset_labels))
test_dataset = list(zip(test_datase_seqs, test_dataset_labels))
vocab_size = len(tokenizer.index_word.keys())
num_class = len(set(all_dataset_labels))
return train_dataset, test_dataset, vocab_size, num_class
embed_dim = 16 # 大概9w个词,这边embedding维度射为16
batch_size = 64
seq_len = 50 # 句子长度取50就能覆盖90%以上的样本
train_dataset, test_dataset, vocab_size, num_class = process_datasets_by_Tokenizer(
train_dataset, test_dataset, seq_len=seq_len)
print(train_dataset[:2])
print("vocab_size = {}, num_class = {}".format(vocab_size, num_class))
[(tensor([ 393, 395, 1571, 14750, 100, 54, 1, 838, 23, 23,
41233, 393, 1973, 10474, 3348, 4, 41234, 34, 3999, 763,
295, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
dtype=torch.int32), 2), (tensor([15798, 1041, 824, 1259, 4230, 23, 23, 898, 770, 305,
15798, 87, 90, 21, 3, 4444, 8, 537, 41235, 6,
15799, 1459, 2085, 5, 1, 490, 228, 21, 3877, 2345,
14, 6498, 7, 185, 333, 4, 1, 112, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
dtype=torch.int32), 2)]
vocab_size = 91629, num_class = 4
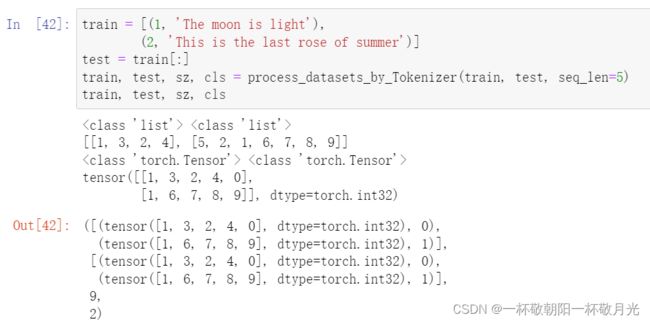
将注释掉的4条print语句打开,我们测试一下代码:
train = [(1, 'The moon is light'),
(2, 'This is the last rose of summer')]
test = train[:]
train, test, sz, cls = process_datasets_by_Tokenizer(train, test, seq_len=5)
train, test, sz, cls得到输出:
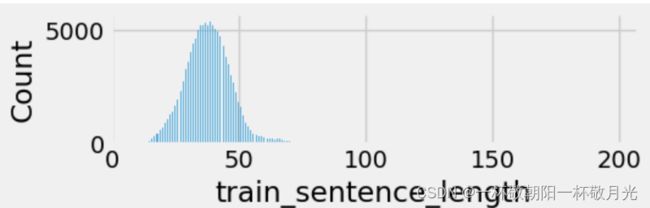
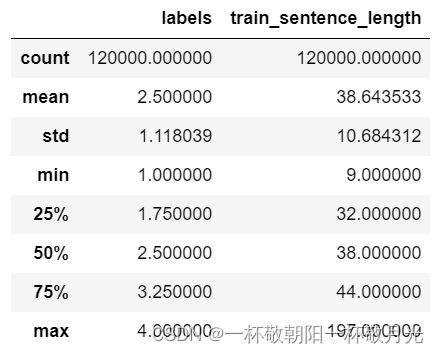
分析了一下样本中句子的长度:其中超过90%的句子长度都不超过50,故后续截取50个单词。

4.构建模型
模型结构简单:embedding层 + 平均池化层 + 全连接层
class TextSentiment(nn.Module):
"""文本分类模型"""
def __init__(self, vocab_size, embed_dim, num_class, seq_len):
"""
description: 类的初始化函数
:param vocab_size: 整个语料包含的不同词汇总数
:param embed_dim: 指定词嵌入的维度
:param num_class: 文本分类的类别总数
"""
super(TextSentiment, self).__init__()
self.seq_len = seq_len
self.embed_dim = embed_dim
# 实例化embedding层, sparse=True代表每次对该层求解梯度时, 只更新部分权重.
self.embedding = nn.Embedding(vocab_size, embed_dim, sparse=True)
# 实例化线性层, 参数分别是embed_dim和num_class.
self.fc = nn.Linear(embed_dim, num_class)
# 为各层初始化权重
self.init_weights()
def init_weights(self):
"""初始化权重函数"""
# 指定初始权重的取值范围数
initrange = 0.5
# 各层的权重参数都是初始化为均匀分布
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
# 偏置初始化为0
self.fc.bias.data.zero_()
def forward(self, text):
"""
:param text: 文本数值映射后的结果
:return: 与类别数尺寸相同的张量, 用以判断文本类别
"""
# [batch_size, seq_len, embed_dim]
embedded = self.embedding(text)
# [batch_size, embed_dim, seq_len],
# 后续将句子所在的维度做pooling,所以将句子所在维度放到最后面
embedded = embedded.transpose(2, 1) # 句子所在维度由原先的第二维变成第三维
# [batch_size, embed_dim, 1]
embedded = F.avg_pool1d(embedded, kernel_size=self.seq_len)
# [embed_dim, batch_size]
embedded = embedded.squeeze(-1)
# [batch_size, embed_dim]
# 看到torch.nn.CrossEntropyLoss()自带了softmax,所以这边不再套softmax
return self.fc(embedded)5.训练
5.1.generate_batch
generate_batch:构建一个批次内的数据,后续作为DataLoader函数的参数传入
def generate_batch(batch):
"""[summary]
Args:
batch ([type]): [description] 由样本张量和对应标签的元祖 组成的 batch_size 大小的列表
[(sample1, label1), (sample2, label2), ..., (samplen, labeln)]
:return 样本张量和标签各自的列表形式(Tensor)
"""
text = [entry[0].reshape(1, -1) for entry in batch]
# print(text)
label = torch.tensor([entry[1] for entry in batch])
text = torch.cat(text, dim=0)
return torch.tensor(text), torch.tensor(label)我们测试一下这段的效果:
batch = [(torch.tensor([3, 23, 2, 8]), 1), (torch.tensor([3, 45, 21, 6]), 0)]
res = generate_batch(batch)
print(res, res[0].size())输出:

5.2.训练 & 验证函数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def run(data, batch_size, model, criterion,
mode='train', optimizer=None, scheduler=None):
total_loss, total_acc = 0., 0.
shuffle = False
if mode == 'train':
shuffle = True
data = DataLoader(data, batch_size=batch_size, shuffle=shuffle,
collate_fn=generate_batch)
for i, (text, label) in enumerate(data):
# text = text.to(device) # gpu版本
# label = label.to(device)
sz = text.size(0)
if mode == 'train':
optimizer.zero_grad()
output = model(text)
loss = criterion(output, label)
# 累计批次平均,参照蓄水池抽样算法
total_loss = i / (i + 1) * total_loss + loss.item() / sz / (i + 1)
loss.backward()
optimizer.step()
# predict = F.softmax(output, dim=-1)
correct_cnt = (output.argmax(1) == label).sum().item()
total_acc = i / (i + 1) * total_acc + correct_cnt / sz / (i + 1)
else:
with torch.no_grad():
output = model(text)
loss = criterion(output, label)
total_loss = i / (i + 1) * total_loss + loss.item() / sz / (i + 1)
# predict = F.softmax(output, dim=-1)
correct_cnt = (output.argmax(1) == label).sum().item()
total_acc = i / (i + 1) * total_acc + correct_cnt / sz / (i + 1)
# if i % 10 == 0:
# print("i: {}, loss: {}".format(i, total_loss))
# 调整优化器学习率
if (scheduler):
scheduler.step()
# print(total_loss, total_acc, total_loss / count, total_acc / count, count)
return total_loss , total_acc5.3.主流程
model = TextSentiment(vocab_size + 1, embed_dim, num_class, seq_len)
# model = TextSentiment(vocab_size + 1, embed_dim, num_class, seq_len).to(device) # gpu版本
criterion = torch.nn.CrossEntropyLoss() # 自带了softmax
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.99)
train_len = int(len(train_dataset) * 0.95)
sub_train_, sub_valid_ = random_split(train_dataset,
[train_len, len(train_dataset) - train_len])
n_epochs = 10
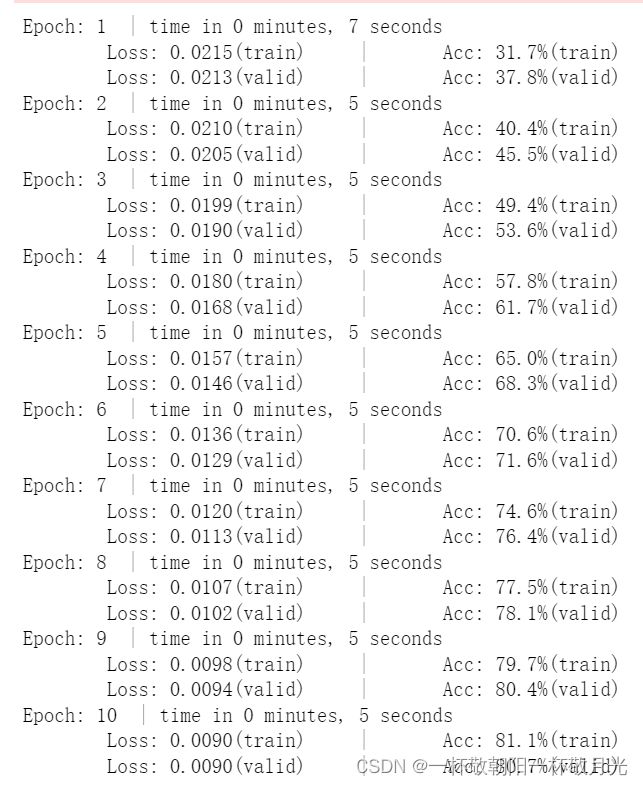
for epoch in range(n_epochs):
start_time = time.time()
train_loss, train_acc = run(sub_train_, batch_size, model, criterion,
mode='train', optimizer=optimizer, scheduler=scheduler)
valid_loss, valid_acc = run(sub_train_, batch_size, model, criterion, mode='validation')
secs = int(time.time() - start_time)
mins = secs / 60
secs = secs % 60
print("Epoch: %d" % (epoch + 1),
" | time in %d minutes, %d seconds" % (mins, secs))
print(
f"\tLoss: {train_loss:.4f}(train)\t|\tAcc: {train_acc * 100:.1f}%(train)"
)
print(
f"\tLoss: {valid_loss:.4f}(valid)\t|\tAcc: {valid_acc * 100:.1f}%(valid)"
)打印结果如下: