DeepExploit——当Metasploit遇上机器学习
Metasploit Meets Machine Learning
文章目录
-
- Metasploit Meets Machine Learning
- 1. Metasploit准备
-
- 1.1 与外部项目的合作
-
- 1.1.1 启用RPC API
- 1.1.2 使用RPC API操作Metasploit
- 2. 创建机器学习模型
-
- 2.1 DQN
- 2.2 A3C
-
- 2.2.1 CartPole
- 2.2.2 分布式学习机制
- 3. 深度利用
-
- 3.1 代理任务
- 3.2 当前状态
-
- 3.2.1 OS类型的获取
- 3.2.2 “端口号”、“协议”、“产品名称”和“版本”的获取
- 3.2.3 “漏洞利用模块类型”的获取
- 3.2.4 获取“利用目标”
- 3.3 行为
- 3.4 补偿
-
- 3.4.1 确定开发的成功或失败
- 3.5 神经网络模型
- 4. 示范
-
- 4.1 学习模式
- 4.2 生产模式
- 4.3 验证环境
- 5. 结论
简要介绍
Metasploit Framework(MSF)是用于渗透测试和漏洞判断的审计攻击,包含功能端口扫描、漏洞利用执行和漏洞调查,是命令行工具。
Deep Exploit通过Metasploit与机器学习相结合,自动执行从搜索到入侵目标主机的所有操作。
主要操作
- 通过Nmap端口扫描收集用于情报收集的主机信息
- 建模威胁:识别目标主机中的已知漏洞
- 漏洞分析:确定高效有效的检查方法
- Exploitation:使用确定的检查方法执行漏洞利用
运行模式两种:学习模式+生产模式
- 学习模式:参考目标主机的状态(OS类型。可用端口号。正在运行的产品名称),进行训练,每个Exploit模块根据其状态进行加权
- 生产模式:根据所学结果对目标主机的状态进行利用
1. Metasploit准备
命令
msfconsole
1.1 与外部项目的合作
MSF一般用法是用户进行输入命令,蛋本工具目的是使用机器学习来自动化开发,因此输入主体由人变成机器学习模型。
具体操作:使用MSF中的RPC API来执行来自机器学习模型的命令,并通过RPC API获取执行结果
1.1.1 启用RPC API
msf> load msgrpc ServerHost=192.168.220.144 ServerPort=55553 User=test Pass=NsSJMEI3
[*] MSGRPC Service: 192.168.220.144:55553
[*] MSGRPC Username: test
[*] MSGRPC Password: NsSJMEI3
[*] Successfully loaded plugin: msgrpc
显示Successfully loaded plugin: msgrpc说明已经启用RPC API
1.1.2 使用RPC API操作Metasploit
Meatsploit中实现了很多API, 通过从客户端向RPC服务器发送一个以MessagePack格式化的HTTP POST请求来执行API。
# 导入MessagePack和HTTP通信包
In[2]: import msgpack
In[3]: import http.client
# 定义etasploit连接信息
In[4]: host = '192.168.220.144'
In[5]: port = 55553
In[6]: uri = '/api/'
In[7]: headers = {'Content-type' : 'binary/message-pack'}
# 连接到Metasploit
In[8]: client = http.client.HTTPConnection(host, port)
# 使用 auth.login API 登录 Metasploit
# 要发送的HTTP请求以MessagePack格式序列化(msgpack.packb)
# 收到的 HTTP 响应是从 MessagePack 格式反序列化的 (msgpack.unpackb)
In[9]: user = 'test'
In[10]: password = 'NsSJMEI3'
In[11]: option = [user, password]
In[12]: option.insert(0, 'auth.login')
In[13]: option
Out[13]: ['auth.login', 'test', 'NsSJMEI3']
In[14]: params = msgpack.packb(option)
In[15]: client.request('POST', uri, params, headers)
In[16]: ret = client.getresponse()
In[17]: response = msgpack.unpackb(ret.read())
# 如果登录成功,则返回用于认证的Token
In[18]: response
Out[18]: {b'result': b'success', b'token': b'TEMPEfC9t8y1YXyR5j0jgDnX9M07bk2d'}
# 使用 console.create API 创建 MSFconsole
In[19]: token = response.get(b'token')
In[20]: option = [token]
In[21]: option.insert(0, 'console.create')
In[22]: option
Out[22]: ['console.create', b'TEMPEfC9t8y1YXyR5j0jgDnX9M07bk2d']
In[23]: params = msgpack.packb(option)
In[24]: client.request('POST', uri, params, headers)
In[25]: ret = client.getresponse()
In[26]: response = msgpack.unpackb(ret.read())
# 如果 MSFconsole 创建成功,则返回控制台 ID
In[27]: response
Out[27]: {b'busy': False, b'id': b'0', b'prompt': b'msf > '}
# 使用 console.write API 执行任何命令(需要在命令末尾换行)
In[28]: console_id = response.get(b'id')
In[29]: command = 'version\n'
In[30]: option = [token, console_id, command]
In[31]: option.insert(0, 'console.write')
In[32]: option
Out[32]: ['console.write', b'TEMPEfC9t8y1YXyR5j0jgDnX9M07bk2d', b'0', 'version\n']
In[33]: params = msgpack.packb(option)
In[34]: client.request('POST', uri, params, headers)
In[35]: ret = client.getresponse()
In[36]: response = msgpack.unpackb(ret.read())
In[37]: response
Out[37]: {b'wrote': 8}
# 使用 console.read API 获取命令执行结果输出到 MSFconsole
In[38]: option = [token, console_id]
In[39]: option.insert(0, 'console.read')
In[40]: option
Out[40]: ['console.read', b'TEMPEfC9t8y1YXyR5j0jgDnX9M07bk2d', b'0']
In[41]: params = msgpack.packb(option)
In[42]: client.request('POST', uri, params, headers)
In[43]: ret = client.getresponse()
In[44]: response = msgpack.unpackb(ret.read())
# 如果命令执行成功,则返回执行结果
In[45]: response
Out[45]:
{b'busy': False,
b'data': b'\n ___ ...snip... Framework: 4.16.15-dev\nConsole : 4.16.15-dev\n',
b'prompt': b'msf > '}
2. 创建机器学习模型
作为强化学习的模型,我们决定采用一种名为**Asynchronous Advantage Actor-Critic (A3C)**的模型,该模型是在DeepMind 于 2016 年发表的论文《 Asynchronous Methods for Deep Reinforcement Learning 》中提出的。
A3C 也被称为 DQN 的改进模型,故先简要解释一下 DQN 的轮廓。
2.1 DQN
DQN 是基于强化学习的模型,是参照人和动物的奖励系统制作的。
DQN 在学习开始时,不知道合适的行为模式,所以它的行为是随机的。有时你会丢球,有时你会不小心把它弹起来。弹跳球会导致块崩溃,因此认为这是一个好的动作并奖励DQN 。获得奖励后,未来采取相同行动的概率会略有增加。通过在各种情况下重复这一点,可以根据各种情况学习可以很好地发挥的动作。
此外,在学习 DQN 的过程中,人类不需要展示示例或教授游戏规则(不需要教授数据)。如果你提前定义了“状态”、“行为模式”和“给予奖励的规则”,它会根据奖励制度的原理自行**学习。**换句话说,要想成功地学习 DQN,**根据任务适当地设计“状态”、“动作”和“奖励”**是非常重要 的。
2.2 A3C
A3C学习方式和DQN类似,只是增加了以下三个改进:
- 优势
- 表现-评价
- 异步
由于 1 和 2 需要 DQN 的先决知识,我们将在本博客中省略它们,重点介绍第三个特性“异步”。
强化学习基于奖励系统的原理进行学习,因此需要在各种状态下尝试许多不同的动作,学习需要很多时间。
因此,A3C通过异步的多代理分布式学习实现了学习时间的显着加快。DeepMind 的验证表明,在 16 个 CPU 内核上进行分布式训练的 A3C 的训练速度比在 Nvidia K40 GPU 上训练的 DQN 更快。
下面展示了基于学习时间和分数在“Beamrider”、“Breakout”、“Pong”、“Q*bert”和“Space Invaders”五款游戏中比较包括 A3C 和 DQN 在内的各种模型的结果。 .
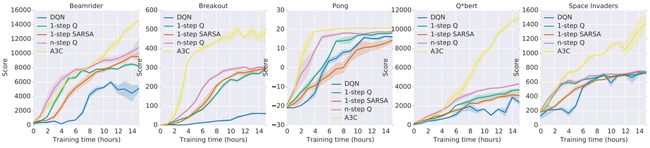
来源:
https /arxiv.org/pdf/1602.01783.pdf
从这个结果可以看出,有一些模型在学习的早期阶段就超过了 A3C,但是随着学习的进行,A3C 在所有游戏中都取得了高分。尤其是BreakOut,可以看出它从一开始学习就压倒其他模型。
2.2.1 CartPole
CartPole 是一种游戏,通过根据杆的倾斜度左右移动推车以使放置在黑匣子上的杆不掉落来保持平衡。

A3C 可以通过 Gym了解当前状态。CartPole 定义状态为:
- 推车位置
- 推车速度
- 极角
- 极角速度
并根据当前状态选择一些**动作。**CartPole 将行为定义为:
- 向右移
- 向左移动
最后,根据行为结果获得奖励。CartPole 将奖励定义为:
- 正奖励(+1): Pole 是平衡的
- 负奖励(-1): Pole不平衡
通过如上所述设计“状态”、“行为”和“奖励”,我们将逐渐学习根据状态给予奖励的动作,即Pole不倒下来的动作。
2.2.2 分布式学习机制
A3C分为两个区域,称为“ Worker Thread ”,代理(动作主体)操作的地方,和“Parameter Server”,分享代理经验的地方。他们 具有相同的神经网络结构。

每个工作线程中的每个代理都会播放 CartPole 并将获得的经验存储在内存中。然后,当它积累一定数量的经验时,它会计算自己的梯度(⊿w = grad:用于更新权重(w)的参数)并将其推送到参数服务器。Parameter Server 使用从每个工作线程推送的 grad 来更新自己的网络权重 (w),并将更新后的权重 (w) 复制到每个工作线程。然后每个代理再次播放 CartPole。重复此过程,直到满足学习的结束条件。
上述过程按时间顺序排列如下。
- [PS] 将网络权重 (w) 初始化为随机值。
- [PS] 将网络权重 (w) 复制到工作线程。
- [WT]将当前状态动作输入网络并选择一些动作
- [WT] 为您的行为获得**奖励。**由于采取行动时状态会发生变化,因此这称为“下一个状态”。
- [WT] 将“当前状态、动作、奖励、下一个状态”(=体验)存储在内存中。
- [WT] 重复上述步骤 3 至 5。
- [WT] 积累一定的经验后,利用记忆中的经验(当前状态、动作、奖励、下一个状态)计算网络的梯度(grad)。
- [WT] 将 grad 推送到参数服务器。
- [PS] 使用从每个工作线程推送的 grad 更新网络权重 (w)。
- 回到上面的2。
通过这种方式,多个代理异步处理任务并分享他们的经验以加快学习速度。
3. 深度利用
在这里,我们将解释使用Python 实现的连接 Metasploit 和 A3C的Deep Exploit逻辑,并自动执行从搜索到入侵目标主机的一系列操作。
下面是这次创建的 Deep Exploit 的概念图。
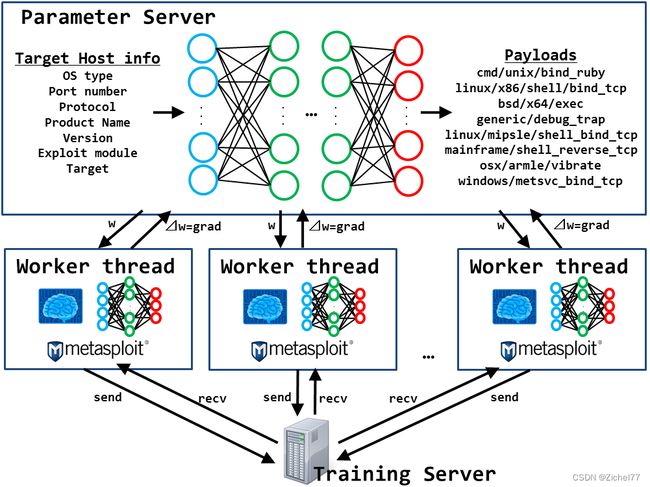
如上图所示,基本结构与 CartPole 相同,但有以下五个不同之处。
- 代理任务
- 神经网络的输入信息(=当前状态)
- 神经网络的输出(=动作)
- 奖励规则
- 神经网络模型
下面将解释每个差异。
3.1 代理任务
CartPole目标:在左右移动手推车时保持平衡,而不会倾斜杆。
DeepExploit 目标:通过 Metasploit 将漏洞利用模块发送到目标主机,并使漏洞利用成功。
3.2 当前状态
Deep Exploit 将以下七类信息定义为“当前状态”。
- 操作系统类型
- 端口号
- 协议类型(tcp/udp)
- 产品名称
- 版本
- Metasploit 中利用模块的类型
- Exploit 模块中的可选目标
以下板块是这些信息的获取
3.2.1 OS类型的获取
使用RPC API " console.write" 通过命令对目标主机执行端口扫描db_nmap。然后在端口扫描后使用相同的 APIhosts执行命令。
下面是对目标主机“ ”192.168.220.145进行端口扫描后执行命令的结果hosts(实际上输出在MSFconsole缓冲区中)。
Hosts
=====
address mac name os_name os_flavor os_sp purpose info comments
------- --- ---- ------- --------- ----- ------- ---- --------
192.168.220.145 00:0c:29:16:3a:ce Linux 2.6.X server
hosts执行命令时,输出端口扫描主机的IP和MAC地址,以及扫描猜到的操作系统类型。由于 OS 类型在“os_name”列中输出,因此使用 RPC API“ ”console.read从缓冲区hosts中获取命令的执行结果Linux,解析相应部分( )并将其设置为 OS 类型。
3.2.2 “端口号”、“协议”、“产品名称”和“版本”的获取
使用RPC API " console.write" 并services执行命令来获取。
下面services -c port,proto,info -R 192.168.220.145显示运行结果
Services
========
host port proto info
---- ---- ----- ----
192.168.220.145 21 tcp vsftpd 2.3.4
192.168.220.145 22 tcp OpenSSH 4.7p1 Debian 8ubuntu1 protocol 2.0
192.168.220.145 23 tcp Linux telnetd
192.168.220.145 25 tcp Postfix smtpd
192.168.220.145 53 tcp ISC BIND 9.4.2
...snip...
192.168.220.145 5900 tcp VNC protocol 3.3
192.168.220.145 6000 tcp access denied
192.168.220.145 6667 tcp UnrealIRCd
192.168.220.145 8009 tcp Apache Jserv Protocol v1.3
192.168.220.145 8180 tcp Apache Tomcat/Coyote JSP engine 1.1
RHOSTS => 192.168.220.145
services执行该命令,输出端口扫描检测到的空闲端口号、协议、产品名称和版本等详细信息。由于“port”列输出空闲端口号,“proto”列输出协议类型,“info”列输出产品名称和版本,console.read命令的执行结果是从缓冲区中获取的RPC API“”并解析相应部分。
3.2.3 “漏洞利用模块类型”的获取
使用RPC API "module.exploit”获取。
通过使用此 API,可以获得以下格式的所有漏洞利用模块名称。
{b'modules': [b'windows/wins/ms04_045_wins',
b'windows/winrm/winrm_script_exec',
b'windows//safenet_ike_11',
b'windows/vnc/winvnc_http_get',
b'windows/vnc/ultravnc_viewer_bof',
...snip...
b'android/meterpreter/reverse_tcp',
b'android/shell/reverse_https',
b'android/meterpreter/reverse_https',
b'android/shell/reverse_http',
b'android/meterpreter/reverse_http']}
此外,由于在Metasploit中确定了与产品名称关联的漏洞利用模块,因此要设置为“当前状态”的漏洞利用模块是从与产品关联的漏洞模块中随机选择的。
3.2.4 获取“利用目标”
使用RPC API“ ”,选择console.write设置为“当前状态”的exploit模块,执行命令获取。useshow targets
下面显示了运行 use exploit/linux/http/linksys_apply_cgi后的结果show targets
Exploit targets:
Id Name
-- ----
0 Generic
1 Version 1.42.2
2 Version 2.02.6beta1
3 Version 2.02.7_ETSI
4 Version 3.03.6
5 Version 4.00.7
6 Version 4.20.06
show targets运行该命令将输出可用于所选漏洞利用模块的目标列表。 由于标识目标的数字在“Id”列中输出,console.read因此命令的执行结果是通过RPC API“”从缓冲区中获取的,对应的部分(Target ID)被解析为“Exploit target” ”。另外,由于可能有多个Target,这种情况下,随机选择一个Target,设置为当前状态。
3.3 行为
在DeepExploit中,当前状态下选择的exploit模块可以引用的payload被定义为“行为”。
可以从 Exploit 模块引用的有效负载列表可以module.compatible_payloads通过 RPC API “” 获得。下面exploit/linux/http/linksys_apply_cgi显示了一个获取可以从模块引用的 Payload 名称列表的示例。
{b'payloads': [b'generic/custom',
b'generic/shell_bind_tcp',
b'generic/shell_reverse_tcp',
b'linux/mipsle/exec',
b'linux/mipsle/meterpreter/reverse_tcp',
b'linux/mipsle/reboot',
b'linux/mipsle/shell/reverse_tcp',
b'linux/mipsle/shell_bind_tcp',
b'linux/mipsle/shell_reverse_tcp']}
3.4 补偿
Deep Exploit 对“奖励”的定义如下:
- 成功利用的积极奖励(+1)
- 如果利用失败,则为负奖励 (-1)
- 否则什么都没有 (0)
3.4.1 确定开发的成功或失败
结合RPC API " module.execute" 和 " session.list"可以很容易地确定利用的成功或失败。
Deep Exploit 使用 " module.execute" 来执行漏洞利用,但是这个 API 返回job_id和作为返回值uuid。其中uuid是与执行的漏洞利用模块相关联的唯一值。
接下来,当您执行“ session.list”时,将返回当前活动会话信息列表(成功利用打开的会话列表)。每个会话信息都包含一个元素“ exploit_uuid”,即被成功利用的漏洞利用模块uuid。换句话说,通过比较获得的module.execute结果可以很容易地确定利用的成功或失败 。uuidexploit_uuid
如上所述,通过 RPC API 操作 Metasploit 中提供的功能,可以获得学习 A3C 所需的“状态”、“行为”和“奖励”。
3.5 神经网络模型
CartPole 中使用的神经网络是一个 3 层的多层感知器,由以下数量的节点组成。
- 输入层:4个节点
- 中间层:16 个节点
- 输出层:2个节点
如上所述,“输入节点数=状态数”,“输出节点数=动作数”。
另一方面,Deep Exploit 将 7 个状态作为输入,将 504 个动作(有效负载)作为输出。因此,神经网络具有以下结构。
- 输入层:7个节点
- 中间层 1:50 个节点
- 中间层 2:100 个节点
- 中间层 3:200 个节点
- 输出层:504个节点
隐藏层的激活函数是ReLU(Rectified Linear Unit,Rectifier),输出层的激活函数是Softmax。* 详情请参考 Github 上发布的源代码。
- 神经网络配置(参考)
# NUM_STATES=7, NUM_ACTIONS=504
l_input = Input(batch_shape=(None, NUM_STATES))
l_dense1 = Dense(50, activation='relu')(l_input)
l_dense2 = Dense(100, activation='relu')(l_dense1)
l_dense3 = Dense(200, activation='relu')(l_dense2)
out_actions = Dense(NUM_ACTIONS, activation='softmax')(l_dense3)
4. 示范
展示Deep Exploit的实际操作,并解释学习和测试的过程
4.1 学习模式
首先,对训练主机进行端口扫描,根据从目标主机获取的信息定义“当前状态”。在学习模式下,利用各种**有效负载执行漏洞利用,同时随机重新排列状态(端口号、产品名称、漏洞利用模块和目标等) 。**我们正在为每个状态和行动积累奖励。
如果利用成功,将显示“BINGO!!!”。同时,屏幕右侧显示的 MSFconsole 上会显示会话已打开的消息。
上面的学习例子展示了5000 个漏洞是如何被 10 个线程划分和执行的。本次培训大约需要 30 分钟。
通过 5000 次试验,它根据当前状态逐渐学习成功和不成功利用的行为模式,并最终对每个行为进行加权。
4.2 生产模式
在生产模式下,对目标主机执行端口扫描并获取状态后,根据学习结果,针对获取的状态,利用成功率最高的“exploit module/payload/target”组合来运行exploit . 此外,如果利用失败,将尝试下一个概率最高的组合(最大尝试次数为 5 次)。
如果利用成功,将显示“BINGO!!!”。同时,屏幕右侧显示的 MSFconsole 上会显示会话已打开的消息。
- 23/tcp,选择“Exploit: /solaris/telnet/fuser, Payload: cmd/unix/bind_perl, Target: 0”的组合为telnet Exploit module/Payload/Target的全部455个组合,在试验中利用成功
从视频中的 0:22 开始
-
445/tcp,选择“Exploit: /multi/samba/usermap_script, Payload: cmd/unix/bind_perl, Target: 0”组合为所有991个模式的samba Exploit module/Payload/Target组合**,试验利用成功**。
从视频中的 1:07
- 80/tcp, apacheExploit module/Payload/Target 5922模式的所有组合,选择“Exploit: multi/http/struts2_rest_xstream, Payload: cmd/unix/bind_perl, Target: 0”的组合,第4次尝试利用成功.
从视频中的 0:56 开始
通过学习,我们了解到可以从 991 模式和 5922 模式等无数可能的“漏洞利用模块/有效负载/目标组合”中随机选择最优组合,并精确执行漏洞利用。
4.3 验证环境
- Kali Linux 2017.3 (Guest OS on VMWare)
- Memory: 8.0GB
- Metasploit Framework 4.16.15-dev
- Windows 10 Home 64-bit (Host OS)
- CPU: Intel® Core™ i7-6500U 2.50GHz
- Memory: 16.0GB
- Python 3.6.1(Anaconda3)
- tensorflow 1.4.0
- Keras 2.1.2
- msgpack 0.4.8
- docopt 0.6.2
5. 结论
这一次,我们尝试使用强化学习实现 Metasploit 自动利用。虽然开发的工具是测试版,但发现可以自学利用方法(无需训练数据)并在生产中精确定位成功利用。
未来,希望添加和改进如下所示的功能,并突破测试版(升级到可以在实战中使用的级别)。
- 提高利用的准确性
- “状态”的细化(辅助模块的利用)
- 漏洞利用模块选项的优化
- 模型超参数优化
- 添加新功能
- 应对利用后
- 资产评估
- 报告
- 提高安全性
- 目标主机异常检测
- 终止开关实现