【目标检测】Object Detection in 20 Years: A Survey
目录
- 概述
- 细节
-
- 20年来的目标检测技术
- 目标检测的加速方法
- 目标检测的最新进展
概述
这是一篇19年的综述,介绍了目标检测领域20年来各个方面的内容,非常全面!
细节
20年来的目标检测技术
目标检测的里程碑(传统检测器):Viola Jones Detectors、HOG Detector、Deformable Part-based Model (DPM)
目标检测的里程碑(两阶段检测器:由粗到细):RCNN、SPPNet、Fast RCNN、Faster RCNN、Feature Pyramid Networks(FPN)
目标检测的里程碑(单阶段检测器:一步到位):YOLO系列、Single Shot MultiBox Detector (SSD)、RetinaNet(focal loss)
数据集:通用数据集如Pascal VOC(2007、2012;20个类别)、The ImageNet Large Scale Visual Recognition Challenge (ILSVRC;200个类别)、MS-COCO(很难)、Open Images Detection等,还有很多很多特定领域的数据集(文中给出了,但是太多了)。其中,数据量大小排名:voc
评价指标:Average Precision (AP,最常用,voc数据集中国引入的):不同召回率下的平均检测精度,通常在特定类别下进行评估;MAP:所有类别的AP的平均值;IOU:用于检测目标定位的精度,预测框和gt box的IOU大于阈值,则说明检测成功;过去经常将前两个指标结合,如0.5IOU基础上的MAP作为最终的指标;现在 MS-COCO AP是0.5~0.95的IOU门限下的平均。
多尺度检测技术的演进: 特征+滑窗(14年之前):多个模型用于多尺度检测;object proposals (10-15年):指的是一组可能包含任何对象的、与类别无关候选框,从而避免了滑窗带来的巨大开销;深度回归(13-16):直接回归bbox的坐标,简单但是对于小目标处理不佳;多参考/多分辨率检测(15之后):前者就是anchor机制,预先定义一组参考框,他们具有不同的尺寸和横纵比,根据这些参考,来预测bbox(常见的损失函数形式如下),后者就是网络的不同层检测不同尺度物体。

bbox回归的演进:从没有使用bbox回归到使用bbox回归作为后处理流程,再到15年Faster RCNN之后,将bbox回归作为模型的一部分,和检测器一起训练,也就是使用模型的特征预测进行bbox的回归(为了更具有鲁棒性的定位,常用损失函数如下)。

Context priming(上下文获取?)的演进:首先是局部信息有助于目标检测,并且基于CNN的结构,很容易调整感受野控制局部的大小;其次全局的上下文信息更加有助于目标检测,现在主要是两种方式实现,一种是大感受野,甚至是超过原图尺寸的感受野,另一种是全局池化操作,将上下文信息视为序列信息,用RNN来学习(貌似自注意力机制也可以?);最后是上下文交互,就是探索元素之间的关系帮助目标检测能力的提高,如探索对象之间的关系,再如探索对象与背景之间的关系。
Non-maximum suppression (NMS) 的演进:NMS指的是模型最后可能会产生多个重叠的(相邻的)检测框,他们很有可能是对同一个物体的重复检测,NMS要做的就是去除掉冗余的检测,得到最终的检测结果。基于贪心的NMS(最经典最常用):核心就是每次选择检测得分最高的bbox,并使用它去和其余的bbox做IOU计算,若是结果大于指定阈值,则删除较小的bbox,迭代上述策略,直到bbox遍历完毕。尽管存在一些问题,但是他仍然是最流行的NMS算法。bbox聚合:将重叠的bbox汇聚成一个bbox。自学习的NMS:就是将NMS作为一个bbox的过滤器,放到网络中,对原始检测结果再评分,让网络自己学习。(这个过滤器有点注意力机制的感觉了)
Hard Negative Mining(困难负样本挖掘)的演进:主要是为了解决样本的不平衡问题。目标检测的样本不平衡体现在,前景(目标)和背景数量的极度不平衡。Bootstrap:指的是从训练从一小部分的背景样本开始,在训练过程中迭代添加错误分类背景。最开始用于经典的目标检测算法中,但是随着深度学习技术的发展,主流的深度学习算法采用正负样本加权的方式处理样本不平衡问题,但是后来的研究又将Bootstrap重新引入。
目标检测的加速方法
核优化:非线性分类器如SVM分类效果好,但是计算复杂度不一定,可以采取核优化的方式加速。
级联检测:由粗到细的检测方案,前面的流程过滤掉一大部分候选框,后面的流程专注于重要的候选框。
模型剪枝:删除部分网络结构或者权重。近年来的方式是迭代循环和剪枝,就是每个训练阶段去除一部分不重要的权重,但是这种方式不适用于CNN的结构,一种改进就是直接去掉该权重对应的卷积核。
模型量化:减少激活或者权重的代码长度。主要工作集中在网络二值化,就是将网络的激活或权重量化为二进制变量(例如,0/1)来加速网络,从而将浮点运算转换为 AND、OR、NOT 逻辑操作。
网络蒸馏:就是老师-学生网络,使用提前训练好的老师网络来指导学生网络的训练。
轻量级网络设计: 分解卷积,两种思路,一种是将大卷积核从空间上分解为若干个小卷积,如VGG中提出来的,一个7*7的卷积可以使用两个3*3的卷积替代,再如将一个K*K的卷积使用K*1和1*K的卷积替代;另一种思路就是先用一个卷积核将特征图的维度降低,然后再用一个卷积核将特征图的维度恢复到需要的维度;分组卷积:就是从通道维度将原来的特征图分成若干个组,然后分别做卷积,将各个组的结果再从通道维度上堆起来就好了;深度可分离卷积:分组卷积的一个特例,组数是通道数,就是对每个通道单独做卷积,做完之后的结果concat起来,然后使用1x1卷积调整通道数;Bottle-neck设计;神经架构搜索NAS。

数值加速技术:积分图像加速、频域加速、矢量量化和降阶逼近
目标检测的最新进展
经典骨干网络:AlexNet、VGG、GoogLeNet、ResNet、DenseNet、SENet、ResNeXt、MobileNet
特征融合:主要是两种方式,一种是bottom-top的,就是将浅层的特征送到深层,另一种就是top-bottom的,将深层的特征送到浅层,当然还有很多更为复杂的融合方式。另外,各个层的尺寸、通道数可能都不太相同,需要进行调整。另外,融合的方式主要有三种,包括逐元素相加,逐元素点积(可以对特征进行抑制或者强调,利于小目标检测)还有concat(可以整合不同区域的上下文信息,但是带来了更多的显存占用)。
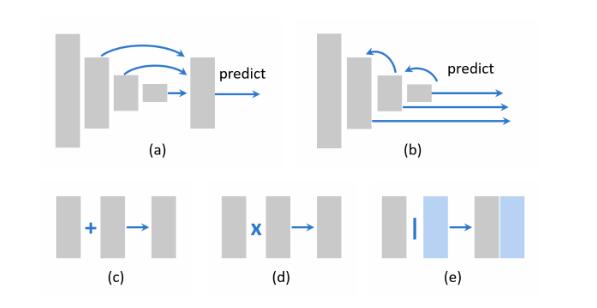
学习具有大感受野的高分辨率特征: 感受野指的是对输出的单个像素有贡献的输入像素的空间范围,具有大感受野的网络能够捕获更大范围的上下文信息,较小的感受野能够更多的关注局部信息。特征分辨率指的是输入和特征图之间的下采样率,因此特征分辨率越小,越难检测到小物体(因为特征图小),直观的做法就是增大特征图,如去掉池化或者卷积保持尺寸不变,但是这又会带来感受野的下降,使得大物体检测能力的下降。一个合理的解决方案就是空洞卷积。
新的检测思路:目标检测而很多时候还是遵循一种特征图上滑动窗口的范式,一些新的思路比如,将目标检测问题作为子区域搜索的问题、关键点定位的问题
定位方面的提高技术: bbox细化:一个后处理环节,将模型预测得到的bbox输入一个bbox回归器中,得到一个更加正确的位置与大小;设计loss函数:现在都是将目标检测作为回归问题解决的,我们可以在回归的损失函数中添加IOU作为定位的损失函数
和语义分割网络一起训练: 优点:语义分割能够帮助类别识别、精确定位、能够作为上下文嵌入;怎么做: 可以将分割网络视为特征提取器,将提取到的特征作为额外特征集成到检测网络中;也可以将分割作为原来检测网络的一个分支,并使用多类别的损失函数训练,在推理的时候将这个分支去掉就好了,但是需要分割的标注,或者使用弱监督学习不增加额外的标注。
对旋转的检测更具有鲁棒性:传统的做法是数据增广或者为每个方向都训练一个模型,一些新的方法比如:旋转不变的损失函数、旋转矫正、Rotation RoI Pooling
对比例变化的检测更具有鲁棒性: 尺度自适应训练:一般的做法就是将图片resize之后投入网络,会带来一些问题,而Scale Normalization for Image Pyramids (SNIP)以及后续的一些研究可以解决这个问题;尺度自适应检测: 一般的做法就是一套模型配置(如anchor)适用于检测不同尺寸的图片,一些技术如adaptive zoom-in等尝试解决这个问题。
从零开始训练:作者认为是否需要将目标检测模型在imageNet上做预训练,需要考虑清楚,一个是损失函数、类别分布、图像比例等,另一个是域是否匹配,如检测的图片是RGB-D的或者3D的,这个就不适合了吧。
GAN:GAN与目标检测
Weakly Supervised Object Detection (WSOD):仅仅使用图片级别的标注实现目标检测网络的训练,包括多实例学习和类激活映射技术等。
应用:行人检测、文本检测、人脸检测、交通指示灯和交通信号检测、遥感目标检测、
未来展望: 轻量级目标检测:能够在移动端或者其他边缘设备上流畅使用,并且对于小目标的检测能够得到较好的性能、网络结构搜索:、领域自适应:在与源数据分布不同的数据集上或者现实场景中,能够得到一个近似源数据集上的表现、弱监督检测:使得模型能够在图像级标注或者少量bbox标注下训练、大场景下的小目标检测、视频中的目标检测:传统的目标检测做的事图像的,缺少对视频帧之间的关系或者其他视频专有信息的考察、多信息融合的目标检测:使用多种模态或者多种数据源的数据进行目标检测模型的设计,如RGB-D 图像、3d 点云、LIDAR 等数据和图像数据如何融合等;或者是如何将当前数据源下训练的模型迁移到另一个数据源中。