MYSQL基础知识归纳
目录
1.1 MYSQL数据库安装
1.2 MYSQL配置
1.2.1 添加环境变量
1.2.2 新建配置文件
1.2.3 初始化MYSQL
1.2.4 注册MYSQL服务
1.2.5 启动MYSQL服务
1.2.6 修改默认账户密码
1.3 mysql登录和退出
1.3.1 登陆
1.3.2 退出
2.2.1 建立和mysql服务的连接
2.2.2 操作
3.1 SQL分类
3.2 DDL操作数据库
3.2.1 查询数据库
3.2.2 创建数据库
3.2.3 删除数据库
3.2.4 使用数据库
3.3 DDL操作表
3.3.1 查询表
3.3.2 创建表
3.3.3 数据类型
3.3.4 删除表
3.4 DML操作数据
3.4.1 添加数据
3.4.2 修改数据
3.4.3 删除数据
3.5 DQL查询数据
3.5.1 基础查询
3.5.2 条件查询
3.5.3 排序查询
3.5.4 聚合函数
3.5.5 分组查询
3.5.6 分组查询
4.1 约束
4.1.1 非空约束
4.1.2 唯一约束
4.1.3 主键约束
4.1.4 默认约束
4.1.5 外键约束
4.2 数据库设计--表关系
4.2.1 一对一
4.2.2 一对多
4.2.3 多对多
4.3 多表查询
内连接查询
外连接查询
嵌套查询(子查询)
4.4 事务
4.4.1 语法
4.4.2 代码验证
4.4.3 事务的四大特征
1.1 MYSQL数据库安装
MySQL :: Download MySQL Community Server (Archived Versions)
选择和自己系统位数对应的版本Download,跳转后不用登录或注册,直接点击No thanks,just start my download,下载完成后是一个压缩包,解压,安装到你想安装的位置
1.2 MYSQL配置
1.2.1 添加环境变量
直接搜环境变量
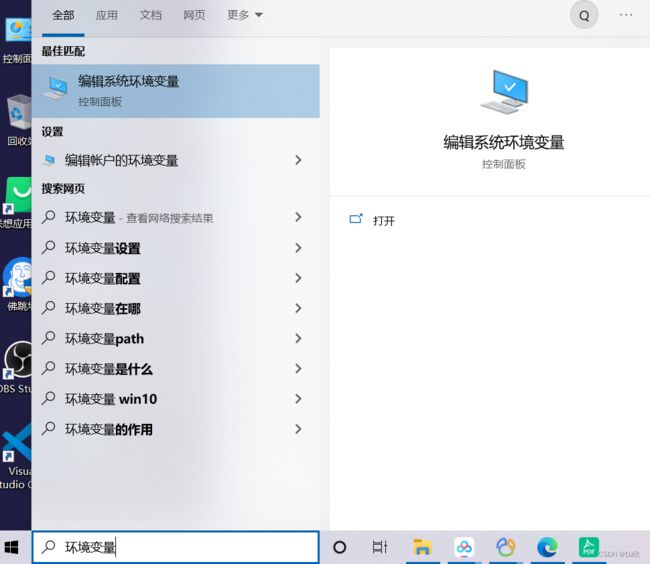
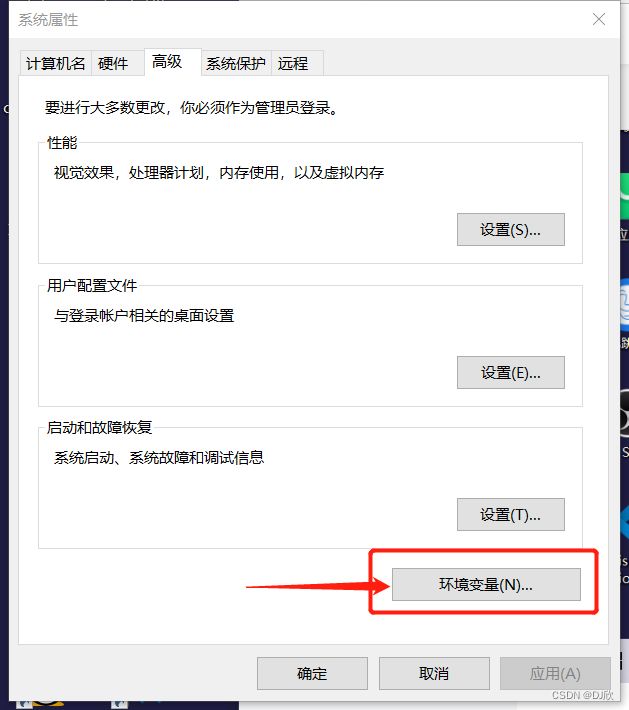
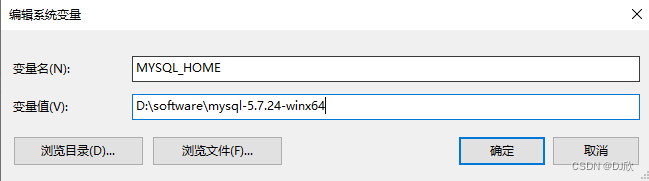
在系统变量中新建MYSQL_HOME
在系统变量中找到并双击Path
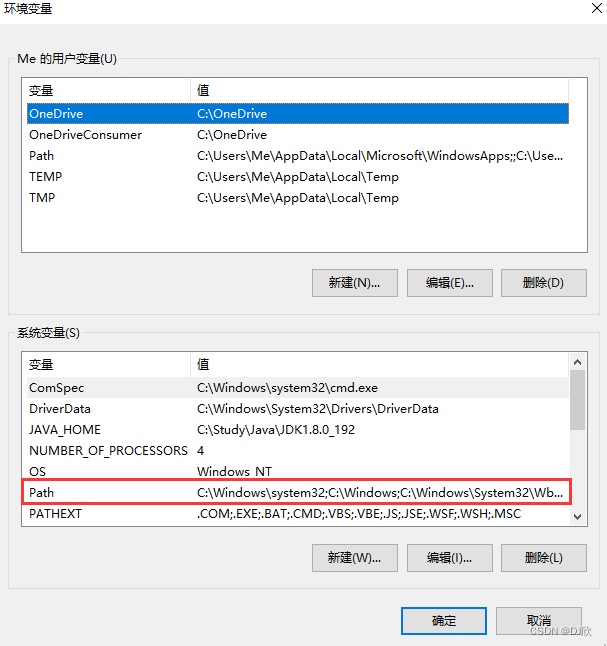
点击新建
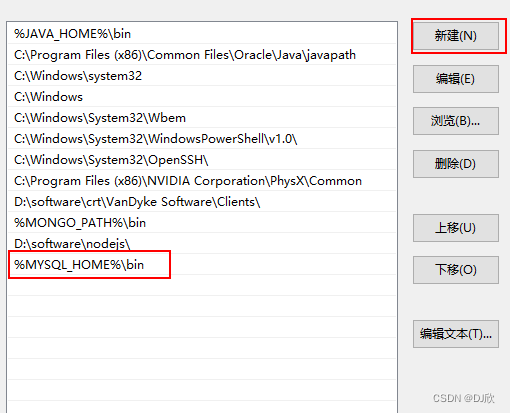
每个窗口都点击确定别直接关掉,不然保存不了更改
验证是否添加成功
cmd管理员打开黑框,输入mysql,回车。
如果提示Can't connect to MySQL server on 'localhost'则证明添加成功
如果提示mysql不是内部或外部命令,也不是可运行的程序或批处理文件则表示添加失败
1.2.2 新建配置文件
新建一个文本文件,复制一下内容
[mysql]
default-character-set=utf8
[mysqld]
character-set-server=utf8
default-storage-engine=INNODB
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CR
EATE_USER,NO_ENGINE_SUBSTITUTION更改文件名为my.ini,存放的路径为MYSQL的根目录
1.2.3 初始化MYSQL
在C盘Windows下system32路径下cmd,复制一下内容,回车
mysqld --initialize-insecure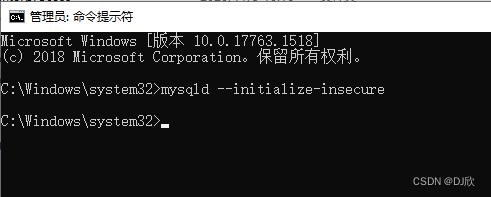
如果没有出现报错信息则证明data目录初始化没有问题,再查看MySQL目录下会有data目录
问题1:

解决方法:权限不足导致的,以管理员身份运行
其他问题:
很可能是my.ini文件不对或者什么
(17条消息) mysql学习笔记整理——my.ini配置文件_开发菜鸡的博客-CSDN博客_my.ini文件内容
可以参考这位兄弟的笔记
1.2.4 注册MYSQL服务
在黑框中复制一下内容,回车
mysqld -install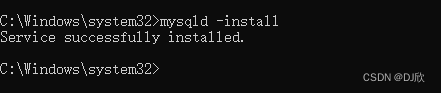
安装成功!!
1.2.5 启动MYSQL服务
复制一下内容,回车
net start mysql // 启动mysql服务
net stop mysql // 停止mysql服务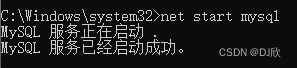
1.2.6 修改默认账户密码
复制一下内容,密码可以看自己
mysqladmin -u root password 1234
1.3 mysql登录和退出
1.3.1 登陆
cmd,复制一下内容,回车
mysql -uroot -p12341234是我的密码,自己设的是什么就换成什么,如果出现mysql>则登录成功
mysql -u用户名 -p密码 -h要连接的mysql服务器的ip地址(默认127.0.0.1) -P端口号(默认3306) 1.3.2 退出
exit
2.1 navicat安装
官网:Navicat | 支持 MySQL、MariaDB、MongoDB、SQL Server、SQLite、Oracle 和 PostgreSQL 的数据库管理
navicat15安装包+注册机
链接:https://pan.baidu.com/s/1Y3WVRtKnQCV8DBaTURJraQ
提取码:1234
Navicat15最新版本破解 亲测可用!!! - 学测试的小白白 - 博客园 (cnblogs.com)
2.2 navicat使用
2.2.1 建立和mysql服务的连接
点击连接,选择mysql
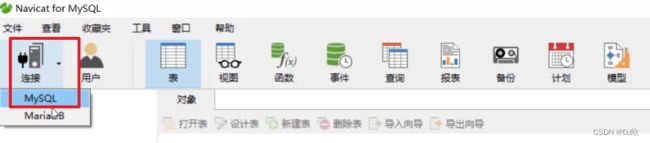
填写连接数据库必要的信息
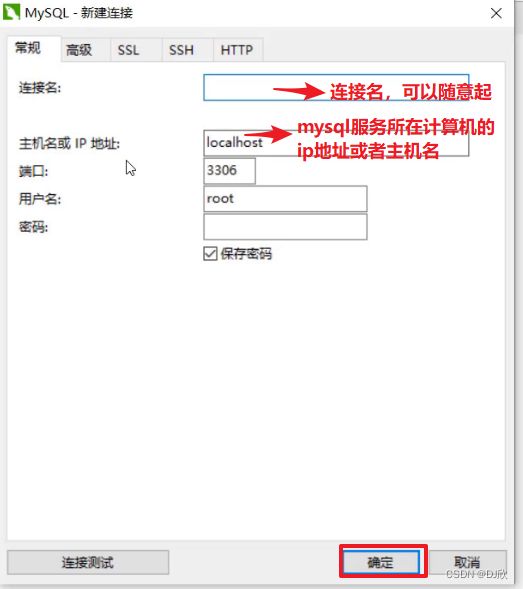
2.2.2 操作
修改表结构
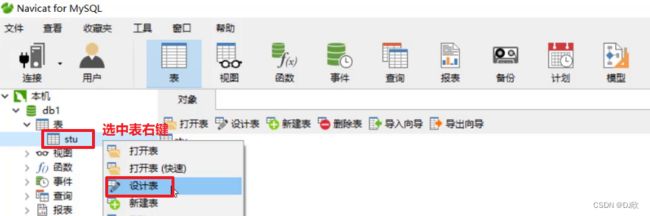
在图中红框中直接修改字段名,类型等信息
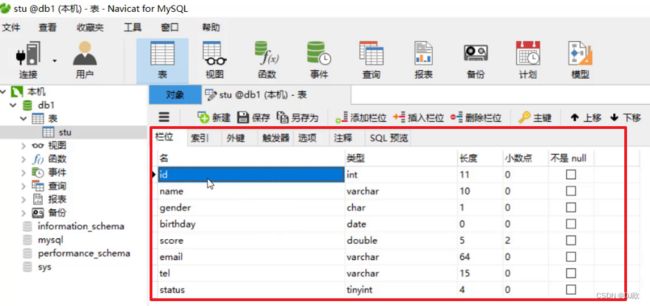
编写sql语句并执行
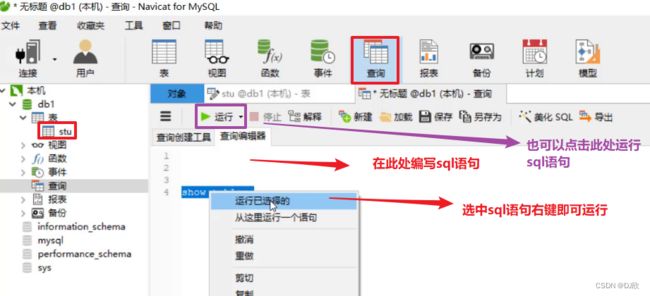
3.1 SQL分类
DDL数据定义语言,用来操作数据库、表等
DML数据操作语言,用来对数据库中表的数据进行增删改
DQL数据查询语言,用来查询数据库中表的记录(数据)
DCL数据控制语言,用来定于数据库的访问权限和安全级别,及创建用户
3.2 DDL操作数据库
操作数据库主要就是对数据库的增删查操作
3.2.1 查询数据库
SHOW DATABASES;3.2.2 创建数据库
CREATE DATABASE 数据库名称;有时候我们可能创建了同名的数据库,就会出现错误,为了避免这种错误,在创建数据库的时候先做判断,如果不存在再创建
CREATE DATABASE IF NOT EXISTS 数据库名称; 3.2.3 删除数据库
DROP DATABASE 数据库名称;
DROP DATABASE IF EXISTS 数据库名称; 3.2.4 使用数据库
使用数据库
USE 数据库名称; 查看当前使用的数据库
SELECT DATABASE();
3.3 DDL操作表
3.3.1 查询表
查看当前数据库下所有表名称
SHOW TABLES; 查询表结构
DESC 表名称;3.3.2 创建表
CREATE TABLE 表名 (
字段名1 数据类型1,
字段名2 数据类型2,
…
字段名n 数据类型n
);例:

create table tb_user (
id int,
username varchar(20),
password varchar(32)
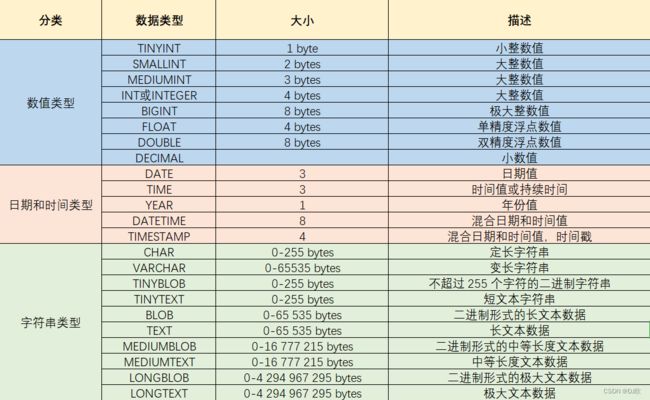
);3.3.3 数据类型
数值
tinyint : 小整数型,占一个字节
int : 大整数类型,占四个字节
eg : age int
double : 浮点类型
使用格式: 字段名 double(总长度,小数点后保留的位数)
eg : score double(5,2)
日期
date : 日期值。只包含年月日
eg :birthday date :
datetime : 混合日期和时间值。包含年月日时分秒
字符串
char : 定长字符串。
优点:存储性能高
缺点:浪费空间
eg : name char(10) 如果存储的数据字符个数不足10个,也会占10个的空间
varchar : 变长字符串。
优点:节约空间
缺点:存储性能底
eg : name varchar(10) 如果存储的数据字符个数不足10个,那就数据字符个数是几就占几个的空间
3.3.4 删除表
DROP TABLE 表名;
DROP TABLE IF EXISTS 表名;3.3.5 删除表
修改表名
ALTER TABLE 表名 RENAME TO 新的表名;
-- 将表名student修改为stu
alter table student rename to stu;添加一列
ALTER TABLE 表名 ADD 列名 数据类型;
-- 给stu表添加一列address,该字段类型是varchar(50)
alter table stu add address varchar(50);修改数据类型
ALTER TABLE 表名 MODIFY 列名 新数据类型;
-- 将stu表中的address字段的类型改为 char(50)
alter table stu modify address char(50);修改列名和数据类型
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型;
-- 将stu表中的address字段名改为 addr,类型改为varchar(50)
alter table stu change address addr varchar(50);删除列
ALTER TABLE 表名 DROP 列名;
-- 将stu表中的addr字段 删除
alter table stu drop addr;3.4 DML操作数据
3.4.1 添加数据
给指定列添加数据
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…); 给全部列添加数据
INSERT INTO 表名 VALUES(值1,值2,…); 批量添加数据
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
INSERT INTO 表名 VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;3.4.2 修改数据
UPDATE 表名 SET 列名1=值1,列名2=值2,… [WHERE 条件] ; 注意❗❗❗
1.修改语句中如果不加条件,则将所有数据都修改
2.中括号中内容在写SQL语句时可以省略这部分
3.4.3 删除数据
DELETE FROM 表名 [WHERE 条件] ;
-- 例:
-- 删除张三记录
delete from stu where name = '张三';
-- 删除stu表中所有的数据
delete from stu;3.5 DQL查询数据
3.5.1 基础查询
查询多个字段
SELECT 字段列表 FROM 表名;
SELECT * FROM 表名; -- 查询所有数据去除重复记录❗❗
SELECT DISTINCT 字段列表 FROM 表名; 起别名
AS: AS 也可以省略3.5.2 条件查询
SELECT 字段列表 FROM 表名 WHERE 条件列表;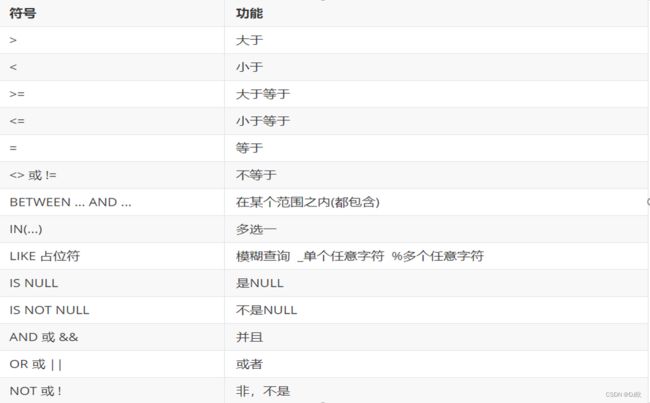
模糊查询like
模糊查询使用like关键字,可以使用通配符进行占位
(1)_ :代表单个任意字符
(2)% :代表任意个数字符
例:查询姓“马”学生信息
select * from stu where name like '马%';查询第二个字是“花”的学生信息
select * from stu where name like '_花%'; 查询名字中包含“德”的学生信息
select * from stu where name like '%德%';3.5.3 排序查询
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …; 排序方式有两种:升序和降序
- ASC:升序排列(默认)
- DESC:降序排列
如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
select * from stu order by math desc , english asc ; 3.5.4 聚合函数
| 函数名 | 功能 |
|---|---|
| count(列名) | 统计数量(一般选用不为null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
聚合函数语法
SELECT 聚合函数名(列名) FROM 表; null值不参与所有聚合函数计算
3.5.5 分组查询
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤]; ❗分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
例
select sex, avg(math),count(*) from stu where math > 70 group by sex having count(*) > 2; where和having的区别:
执行时机不一样:where是分组之前进行限定,不满足where条件则不参与分组,而having是分组之后对结果进行过滤
可判断的条件不一样:where不能对聚合函数进行判断,having可以
3.5.6 分组查询
分页查询是将数据一页一页的展示给用户看,用户也可以通过点击查看下一页的数据
SELECT 字段列表 FROM 表名 LIMIT 起始索引 , 查询条目数; ❗上述语句中的起始索引是从0开始的
❗起始索引=(当前页码-1)*每页显示的条数
例:每页显示3条数据,查询第3页数据
select * from stu limit 6 , 3;4.1 约束
| 约束 | 关键字 | 描述 |
|---|---|---|
| 非空约束 | NOT NULL | 保证列中所有的数据不能有null值 |
| 唯一约束 | UNIQUE | 保证列中的所有数据各不相同 |
| 主键约束 | PRIMARY KEY | 主键是一行数据的唯一标识,要求非空且唯一 |
| 检查约束 | CHECK | 保证列中的值满足某一条件(MYSQL不支持) |
| 默认约束 | DEFAULT | 保存数据时,未指定值则采用默认值 |
| 外键约束 | FOREIGN KEY | 外键用来让两个表的数据之间建立链接 |
4.1.1 非空约束
添加约束
-- 创建表时添加非空约束
CREATE TABLE 表名(
列名 数据类型 NOT NULL,
…
);
-- 建完表后添加非空约束
ALTER TABLE 表名 MODIFY 字段名 数据类型 NOT NULL;删除约束
ALTER TABLE 表名 MODIFY 字段名 数据类型;4.1.2 唯一约束
添加约束
-- 创建表时添加唯一约束
CREATE TABLE 表名(
列名 数据类型 UNIQUE [AUTO_INCREMENT],
-- AUTO_INCREMENT: 当不指定值时自动增长
…
);
CREATE TABLE 表名(
列名 数据类型,
…
[CONSTRAINT] [约束名称] UNIQUE(列名)
);
-- 建完表后添加唯一约束
ALTER TABLE 表名 MODIFY 字段名 数据类型 UNIQUE;删除约束
ALTER TABLE 表名 DROP INDEX 字段名;4.1.3 主键约束
添加约束
-- 创建表时添加主键约束
CREATE TABLE 表名(
列名 数据类型 PRIMARY KEY [AUTO_INCREMENT],
…
);
CREATE TABLE 表名(
列名 数据类型,
[CONSTRAINT] [约束名称] PRIMARY KEY(列名)
);
-- 建完表后添加主键约束
ALTER TABLE 表名 ADD PRIMARY KEY(字段名);删除约束
ALTER TABLE 表名 DROP PRIMARY KEY; 4.1.4 默认约束
添加约束
-- 创建表时添加默认约束
CREATE TABLE 表名(
列名 数据类型 DEFAULT 默认值,
…
);
-- 建完表后添加默认约束
ALTER TABLE 表名 ALTER 列名 SET DEFAULT 默认值;删除约束
ALTER TABLE 表名 ALTER 列名 DROP DEFAULT; 4.1.5 外键约束
添加约束
-- 创建表时添加外键约束
CREATE TABLE 表名(
列名 数据类型,
…
[CONSTRAINT] [外键名称] FOREIGN KEY(外键列名) REFERENCES 主表(主表列名)
);
-- 建完表后添加外键约束
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称);删除约束
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称; 4.2 数据库设计--表关系
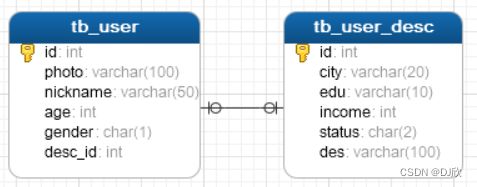
4.2.1 一对一
一对一关系多用于表拆分,将一个实体中经常使用的字段放一张表,不经常使用的字段放另一张表,用于提升查询性能
如:用户和用户详情
实现方式:在任意一方加入外键,关联另一方主键,并且设置外键为唯一(UNIQUE)

create table tb_user_desc (
id int primary key auto_increment,
city varchar(20),
edu varchar(10),
income int,
status char(2),
des varchar(100)
);
create table tb_user (
id int primary key auto_increment,
photo varchar(100),
nickname varchar(50),
age int,
gender char(1),
desc_id int unique,
-- 添加外键
CONSTRAINT fk_user_desc FOREIGN KEY(desc_id) REFERENCES tb_user_desc(id)
);表结构模型图
4.2.2 一对多
如:部门和员工,一个部门对应多个员工,一个员工只对应一个部门
实现方式:在多的一方建立外键,指向一的一方的主键
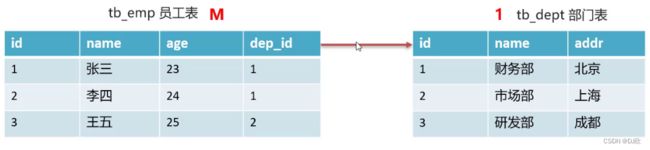
员工表 dep_id指向部门表的主键id
-- 删除表
DROP TABLE IF EXISTS tb_emp;
DROP TABLE IF EXISTS tb_dept;
-- 部门表
CREATE TABLE tb_dept(
id int primary key auto_increment,
dep_name varchar(20),
addr varchar(20)
);
-- 员工表
CREATE TABLE tb_emp(
id int primary key auto_increment,
name varchar(20),
age int,
dep_id int,
-- 添加外键 dep_id,关联 dept 表的id主键
CONSTRAINT fk_emp_dept FOREIGN KEY(dep_id) REFERENCES tb_dept(id)
);表结构模型图:
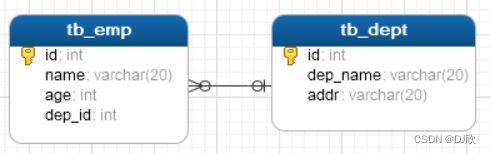
4.2.3 多对多
如:商品对订单,一个商品对应多个订单,一个订单也包含多个商品
实现方式:建立第三章中间表,中间表至少包含两个外键,分别关联两方主键
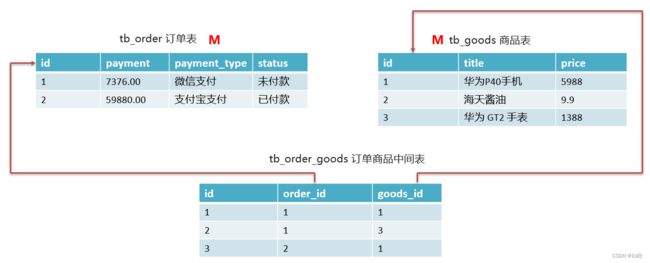
-- 删除表
DROP TABLE IF EXISTS tb_order_goods;
DROP TABLE IF EXISTS tb_order;
DROP TABLE IF EXISTS tb_goods;
-- 订单表
CREATE TABLE tb_order(
id int primary key auto_increment,
payment double(10,2),
payment_type TINYINT,
status TINYINT
);
-- 商品表
CREATE TABLE tb_goods(
id int primary key auto_increment,
title varchar(100),
price double(10,2)
);
-- 订单商品中间表
CREATE TABLE tb_order_goods(
id int primary key auto_increment,
order_id int,
goods_id int,
count int
);
-- 建完表后,添加外键
alter table tb_order_goods add CONSTRAINT fk_order_id FOREIGN key(order_id) REFERENCES
tb_order(id);
alter table tb_order_goods add CONSTRAINT fk_goods_id FOREIGN key(goods_id) REFERENCES
tb_goods(id);表结构模型图:
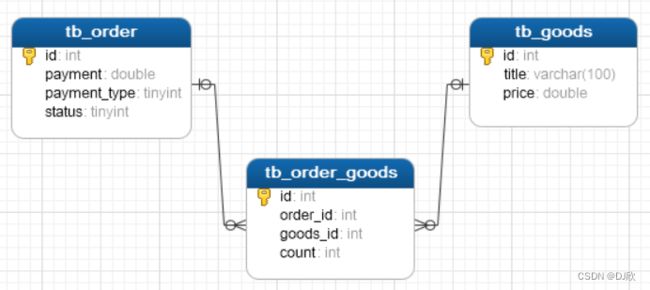
4.3 多表查询
select * from emp , dept; 这样会有很多无效数据,我们需要给一个限制条件
select * from emp , dept where emp.dep_id = dept.did; 内连接查询
-- 隐式内连接
SELECT 字段列表 FROM 表1,表2… WHERE 条件;
-- 显示内连接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 条件;外连接查询
-- 左外连接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件;
-- 右外连接
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件;嵌套查询(子查询)
select * from emp where salary > (select salary from emp where name = '猪八戒'); 子查询根据查询结果不同,作用也不同
- 子查询语句结果是单行单列,子查询语句作为条件值,使用= ! = > <等进行条件判断
- 子查询语句结果是多行单列,子查询语句作为条件值,使用in等关键字进行条件判断
- 子查询语句结果是多行多列,子查询语句作为虚拟表
子查询可以添加到SELECT、UPDATE和DELETE语句中,常用的操作符包括ANY、SOME、ALL、EXISTS、NOT EXISTS、IN和NOT IN等。
ANY子查询
ANY关键字表示如果与子查询返回的任何值相匹配,则返回TRUE,否则返回FALSE
例:查询t_goods数据表中t_category_id字段值大于t_goods_category数据表中任意一个id字段值的数据。
SELECT id, t_category_id, t_category, t_name, t_price
FROM t_goods
WHERE t_category_id > ANY (SELECT id FROM t_goods_category); SOME子查询的作用与ANY子查询的作用相同
ALL子查询
ALL关键字表示如果同时满足所有子查询的条件,则返回TRUE,否则返回FALSE
例:查询t_goods数据表中t_category_id字段值大于t_goods_category数据表中所有id字段值的数据。
SELECT id, t_category_id, t_category, t_name, t_price
FROM t_goods
WHERE t_category_id > ALL (SELECT id FROM t_goods_category);EXISTS子查询
EXISTS关键字表示如果存在某种条件,则返回TRUE,否则返回FALSE
例:查询t_goods_category数据表中是否存在id为1的数据,如果存在,则查询t_goods数据表中t_category_id为1的数据
SELECT id, t_category_id, t_category, t_name, t_price
FROM t_goods
WHERE EXISTS (
SELECT t_category
FROM t_goods_category
WHERE id = 1
)
AND t_category_id = 1;NOT EXISTS子查询
NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE
例:查询t_goods_category数据表中是否不存在id为5的数据,如果不存在,则查询t_goods数据表中t_category_id为2的数据
SELECT id, t_category_id, t_category, t_name, t_price
FROM t_goods
WHERE NOT EXISTS (
SELECT t_category
FROM t_goods_category
WHERE id = 5
)
AND t_category_id = 2;IN子查询
IN关键字表示如果比较的数据在IN列表中,则返回TRUE,否则返回FALSE
例:查询t_goods_category数据表中名称为“女装/女士精品”的id数据,并根据查询出的id数据查询t_goods数据表中的数据
SELECT id, t_category_id, t_category, t_name, t_price
FROM t_goods
WHERE t_category_id IN (
SELECT id
FROM t_goods_category
WHERE t_category = '女装/女士精品'
);NOT IN子查询
NOT IN关键字表示如果比较的数据不在IN列表中,则返回TRUE,否则返回FALSE
例:查询t_goods_category数据表中名称为“女装/女士精品”的id数据,并查询t_goods数据表中不在id列表中的数据
SELECT id, t_category_id, t_category, t_name, t_price
FROM t_goods
WHERE t_category_id NOT IN (
SELECT id
FROM t_goods_category
WHERE t_category = '女装/女士精品'
);4.4 事务
数据库的事务是一种机制、一个操作序列,包含了一组数据库操作命令
事务把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令要么同时成功,要么同时失败
事务是一个不可分割的工作逻辑单元
举例来说,如下图这张表:
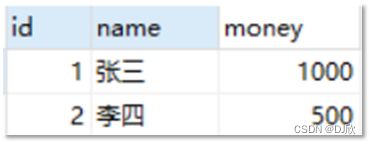
李四需要转账给张三500元,具体的操作步骤为:①查询李四的账户余额②李四账户金额-500③张三账户金额+500
如果顺利完成第二步,却在进行第三步时出现异常,就会造成李四账户少了500但张三并没有收到500元的转账。此时我们就需要使用事务来解决上述问题:
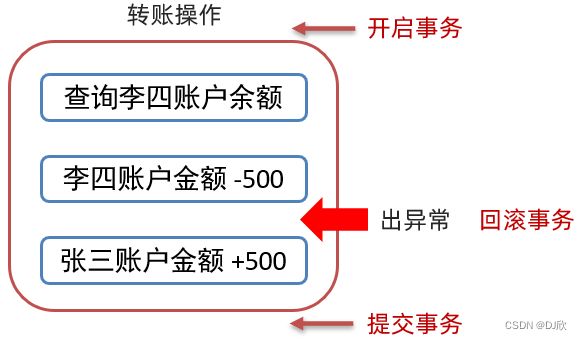
在转账前开启事务,如果中途出现异常,则回滚事务,也就是回到最初是开启事务前的状态。如果没有异常则提交事务。
4.4.1 语法
-- 开启事务
START TRANSACTION;
或者
BEGIN;
-- 提交事务
commit;
--回滚事务
rollback; 4.4.2 代码验证
创建表,添加数据
DROP TABLE IF EXISTS account;
-- 创建账户表
CREATE TABLE account(
id int PRIMARY KEY auto_increment,
name varchar(10),
money double(10,2)
);
-- 添加数据
INSERT INTO account(name,money) values('张三',1000),('李四',1000);无事务展示问题
-- 转账操作
-- 1. 查询李四账户金额是否大于500
-- 2. 李四账户 -500
UPDATE account set money = money - 500 where name = '李四';
出现异常了... -- 此处不是注释,在整体执行时会出问题,后面的sql则不执行
-- 3. 张三账户 +500
UPDATE account set money = money + 500 where name = '张三';-- 转账操作
添加事务,处理问题
-- 开启事务
BEGIN;
-- 转账操作
-- 1. 查询李四账户金额是否大于500
-- 2. 李四账户 -500
UPDATE account set money = money - 500 where name = '李四';
出现异常了... -- 此处不是注释,在整体执行时会出问题,后面的sql则不执行
-- 3. 张三账户 +500
UPDATE account set money = money + 500 where name = '张三';
-- 提交事务
COMMIT;
-- 回滚事务
ROLLBACK;4.4.3 事务的四大特征
原子性(Atomicity):事务是不可分割的最小操作单位,要么同时成功要么同时失败
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态
隔离性(Isolation):多个事务之间,操作的可见性
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
❗mysql中事务是自动提交的,也就是说我们不添加事务执行sql语句,语句执行完毕会自动的提交事务。