从DDPM到GLIDE:基于扩散模型的图像生成算法进展
前几天,OpenAI在Arxiv上挂出来了他们最新最强的文本-图像生成GLIDE [1],如头图所示,GLIDE能生成非常真实的结果。GLIDE并非基于对抗生成网络或是VQ-VAE类模型所设计,而是采用了一种新的图像生成范式 - 扩散模型(Diffusion Model)。
作为一种新的生成模型范式,扩散模型有着和GAN不同且有趣的很多特质。这篇笔记梳理了过去一年多在扩散模型方向的一些主要工作,希望可以帮助读者更好的理解扩散模型以及GLIDE。在扩散模型相关论文中普遍有很多公式推导,笔记中基本省略了推导,读者若感兴趣的话还是推荐阅读原文,有助于增进理解。笔记中若有写错的地方,烦请指正。
01扩散模型与DDPM

如图所示,扩散模型通常包括两个过程,从信号逐步到噪声的正向过程/扩散过程(forward/diffusion process)和从噪声逐步到信号的逆向过程(reverse process)。这里主要介绍Google 的DDPM [2] (Denoising Diffusion Probabilistic Model),这两年后续的扩散模型大都是基于DDPM的框架所设计。
逆向过程
逆向过程从一张随机高斯噪声图片
![]()
开始,通过逐步去噪生成最终的结果
![]()
。这个过程是一个Markov Chain,可以被定义为:

这个过程可以理解为,我们根据
![]()
作为输入,预测高斯分布的均值和方差,再基于预测的分布进行随机采样得到
![]()
。通过不断的预测和采样过程,最终生成一张真实的图片。
正向/扩散过程
正向过程或者说是扩散过程,采用的是一个固定的Markov chain形式,即逐步地向图片添加高斯噪声:

在DDPM中,
![]()
是预先设置的定值参数。扩散过程有一个重要的特性,我们可以直接采样任意时刻t下的加噪结果 ![]() 。将
。将

,则我们可以得到:![]()
这个closed form公式使得我们可以直接获得任意程度的加噪图片,方便后续的训练。
训练模型
为了实现基于扩散模型的生成,DDPM采用了一个U-Net 结构的Autoencoder来对t时刻的噪声进行预测,即
![]()
。网络训练时采用的训练目标非常简单:

此处
![]()
是高斯噪声。这里,噪声预测网络以加噪图片作为输入,目标是预测所添加的噪声。此训练目标即希望预测的噪声和真实的噪声一致。最终在DDPM中,均值
![]()
的定义为:
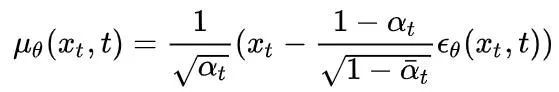
在DDPM中,逆向过程中高斯分布的方差项
![]()
采用的是一个常数项,后续也有工作[3] 用另外的网络分支去单独预测方差项,来获得更好的生成效果。
02Guided Diffusion - 基于类别引导的扩散模型
通常而言,对于通用图像生成任务,加入类别条件能够比无类别条件生成获得更好的效果,这是因为加入类别条件的时候,实际上是大大减小了生成时的多样性。OpenAI的Guided Diffusion [4]就提出了一种简单有效的类别引导的扩散模型生成方式。Guided Diffusion的核心思路是在逆向过程的每一步,用一个分类网络对生成的图片进行分类,再基于分类分数和目标类别之间的交叉熵损失计算梯度,用梯度引导下一步的生成采样。这个方法一个很大的优点是,不需要重新训练扩散模型,只需要在前馈时加入引导既能实现相应的生成效果。
基于条件的逆向过程
在DDPM中,无条件的逆向过程可以用
![]()
来描述,在加入类别条件
![]()
后,逆向过程可以表示为
![]()
这里
![]()
是常量。这个公式表示的意思是,基于类别条件的逆向过程,可以由无条件的逆向过程结合生成结果的分类损失来度量,此处
![]()
表明的即是一个单独训练的分类模型。这里省略具体的推导,最终在guided diffusion 中采用的每一步逆向过程可以用以下式子描述:
![]()
这里 ![]() 也是一个常量。即在每一步过程中,在计算高斯分布的均值时加上方差和分类梯度项的乘积。基于这样的改进,不需要重新训练扩散模型,只需要额外训练一个分类器,就能够有效地在添加类别引导。当然,这样的结构也存在一点小问题,就是会引入比较多的额外计算时间(每一步都要过分类模型并求梯度)。这个问题在本文第四节介绍的no-classifier guidence 中有所改进。但总的来说,扩散模型由于每一次逆向过程都要过至少一遍网络,所以总体生成速度通常还是比较慢的。
也是一个常量。即在每一步过程中,在计算高斯分布的均值时加上方差和分类梯度项的乘积。基于这样的改进,不需要重新训练扩散模型,只需要额外训练一个分类器,就能够有效地在添加类别引导。当然,这样的结构也存在一点小问题,就是会引入比较多的额外计算时间(每一步都要过分类模型并求梯度)。这个问题在本文第四节介绍的no-classifier guidence 中有所改进。但总的来说,扩散模型由于每一次逆向过程都要过至少一遍网络,所以总体生成速度通常还是比较慢的。
扩散模型结构改进
guided diffusion 中,还对DDPM中采用的U-Net 结构的Autoencoder进行了一些结构上的改进。包括加深网络、增加attention head数量、增加添加attention layer的尺度数量、采用BigGAN的残差模块结构。此外,在这篇工作中还采用了一种称为Adaptive Group Normalization (AdaGN)的归一化模块。
03Semantic Guidence Diffusion - 更多的扩散引导形式(图片/文本)
在Guided Diffusion 中,每一步逆向过程里通过引入朝向目标类别的梯度信息,来实现针对性的生成。这个过程其实和基于优化(Optimization)的图像生成算法(即固定网络,直接对图片本身进行优化)有很大的相似之处。这就意味着之前很多基于优化的图像生成算法都可以迁移到扩散模型上。
换一句话说,我们可以轻易地通过修改Guided Diffusion中的条件类型,来实现更加丰富、有趣的扩散生成效果。在Semantic Guidence Diffusion (SGD)[5] 中,作者就将类别引导改成了基于参考图引导以及基于文本引导两种形式,通过设计对应的梯度项,实现对应的引导效果,实现了不错的效果。

首先,在SGD中,作者将guided diffusion 的过程写作:
![]()
此处
![]()
为引导函数(Guidence Function),接下来简单介绍一下本文提出的几种不同的引导函数。
文本引导
基于文本条件的图像生成,即希望生成的图像符合文本的描述。而如何度量一张图片是否和文本描述符合呢?自然的想法当然是采用今年很火爆的CLIP模型,CLIP 模型包含一个图像编码网络
![]()
和文本编码网络
![]()
,两个编码网络能够各自将文本和图片编码为1*512 大小的向量,然后我们可以通过余弦距离来度量两者之间的相似度。要将CLIP模型用于扩散模型的逆向过程,作者注意到了一个问题,即CLIP的图像编码网络是没有见过加噪图像的,这会使得度量效果不理想,从而不能提供有效的梯度。因此,作者将
![]()
在加噪图像上进行了一定的finetune,得到了适应加噪图像的
![]()
。从而,文本引导函数可以定义为:
![]()
即每一步中都基于生成图像与文本之间的相似度来计算梯度。基于这个策略,SGD能生成有效的结果。
图片引导
图片引导是指希望生成的图片与一张参考图片相似。我们将参考图记为
![]()
,根据前述DDPM中的
![]()
公式,我们可以根据当前逆向过程的
![]()
获得对应程度的加噪图片
![]()
。通过对比
![]()
与
![]()
引导生成。此处作者提出了三种不同的图片引导函数。

-
图片内容引导:希望图片的内容内容与参考图相似

-
图片结构引导:进一步的,我们希望加入更强的引导,即在空间结构上的相似性。这里对比的是encoder 的spatial feature map

-
图片风格引导:基于Gram 矩阵,希望生成图片的风格符合参考图片

第j层特征的gram matrix。
混合引导
将上述的引导函数以一定的比例加起来,就能够同时基于多种引导条件进行生成,得到丰富的编辑效果。比如上图中结合文本引导和图像引导的生成。总的来说,这篇工作将Guided Diffusion 进行了很有趣的拓展,使得我们可以通过调整引导的方式生成不同的结果。
04Classifier-Free Diffusion Guidence - 无分类器的扩散引导
上述的各种引导函数,基本都是额外的网络前向 + 梯度计算的形式,这种形式虽然有着成本低,见效快的优点。也存在着一些问题:(1)额外的计算量比较多;(2)引导函数和扩散模型分别进行训练,不利于进一步扩增模型规模,不能够通过联合训练获得更好的效果。DDPM的作者,谷歌的Jonathan Ho等人在今年NIPS 的workshop 上对Guided Diffusion 进行了一波改进,提出了无需额外分类器的扩散引导方法。
如前面DDPM介绍部分所述,DDPM模型主要通过噪声估计模型
![]()
的结果来计算高斯分布的均值。在这个工作中,作者额外给噪声估计模型加入了额外的条件输入
![]()
。训练扩散模型时,结合有条件和无条件两种训练方式,无条件时,将条件
![]()
设置为
![]()
。从而得到一个同时支持有条件和无条件噪声估计的模型。在逆行过程中,该方法通过以下方式,结合有条件和无条件噪声估计得到结果(相当于时模拟了梯度):
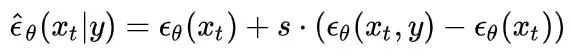
这个式子,主要收到implicit classifier 隐式分类器的启发

,其梯度可以表示为
![]()
基于这个式子,在逆向生成过程的每一步,只需要过两次噪声估计网络,即可进行扩散引导。当然,如果采用这种形式,对于每一种不同的引导类型,都需要重新训练扩散模型,成本+++
05GLIDE - 基于扩散模型的文本图像生成大模型
上一节说到no-classifer guidence 可以更好的将条件信息加入到扩散模型的训练中去以得到更好的训练效果,但同时也会增加训练成本。财大气粗的OpenAI 就基于no-classifier guidence 的思想,整了一个超大规模的基于扩散模型的文本图像生成模型GLIDE。其中算法的核心即将前面的类别条件更新为了文本条件:
![]()
其余部分在方法上并没有什么特别新的东西,说的上是大力出奇迹了。这里简单介绍一些重要的点:
-
更大的模型:算法采用了Guided Diffusion方法中相同的Autoencoder结构,但是进一步扩大了通道数量,使得最终的网络参数数量达到了3.5 billion;
-
更多的数据:采用了和DALLE [7]相同的大规模文本-图像对数据集
-
很高的训练成本:这里作者没有细说,只说了采用2048batch size,训练了250万轮,总体成本接近Dalle。
在2020年Google 发表DDPM后,这两年扩散模型有成为一个新的研究热点的趋势,除了上面介绍的几篇论文之外,还有不少基于扩散模型所设计的优秀的生成模型,应用于多种不同的任务,比如超分、inpainting等。除了在视觉任务上的应用,也有工作针对DDPM的速度进行优化[8],加速生成时的采样过程。
此外,也有将扩散模型与VQ-VAE结合起来实现文本图像生成的算法[9]。其实在七八月份的时候,就已经看了一些DDPM的相关工作,不过因为种种原因当时没有follow下去,还是比较可惜。大家若对扩散模型感兴趣,也欢迎私信我讨论交流~
参考文献
[1] GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
[2] Denoising Diffusion Probabilistic Models
[3] Improved denoising diffusion probabilistic models
[4] Diffusion Models Beat GANs on Image Synthesis
[5] More Control for Free! Image Synthesis with Semantic Diffusion Guidance
[6] Classifier-Free Diffusion Guidance
[7] Zero-Shot Text-to-Image Generation
[8] On Fast Sampling of Diffusion Probabilistic Models
[9] Vector Quantized Diffusion Model for Text-to-Image Synthesis
作者:林天威
|关于深延科技|
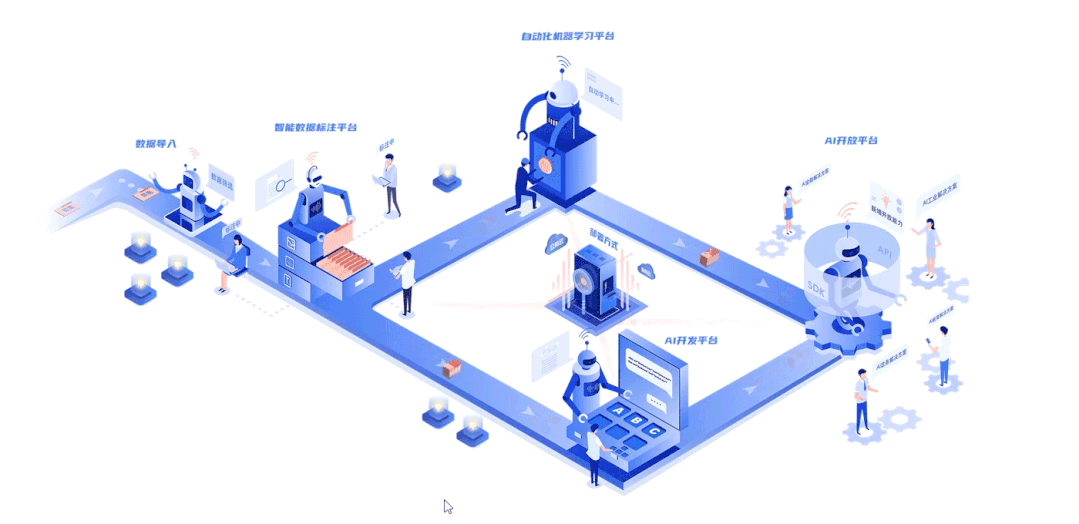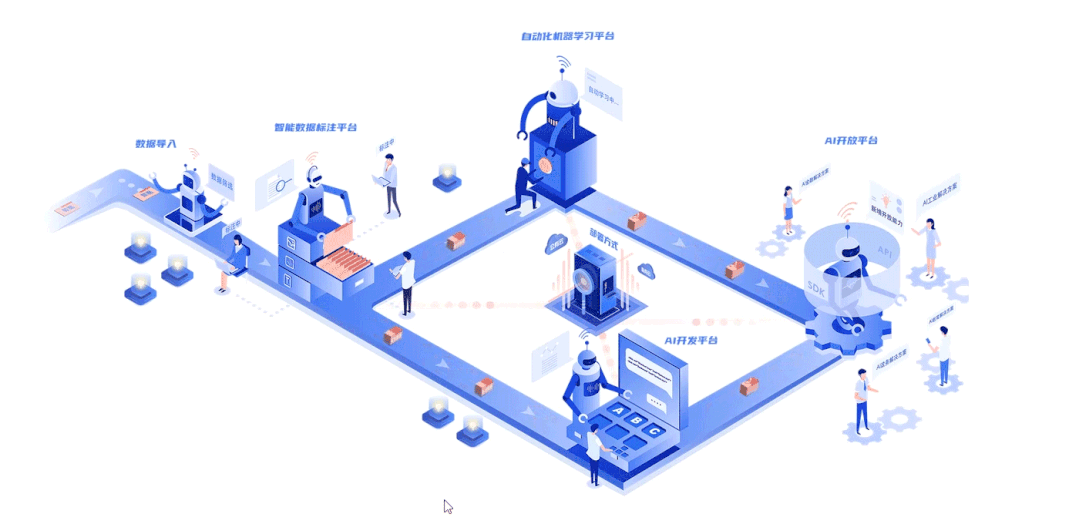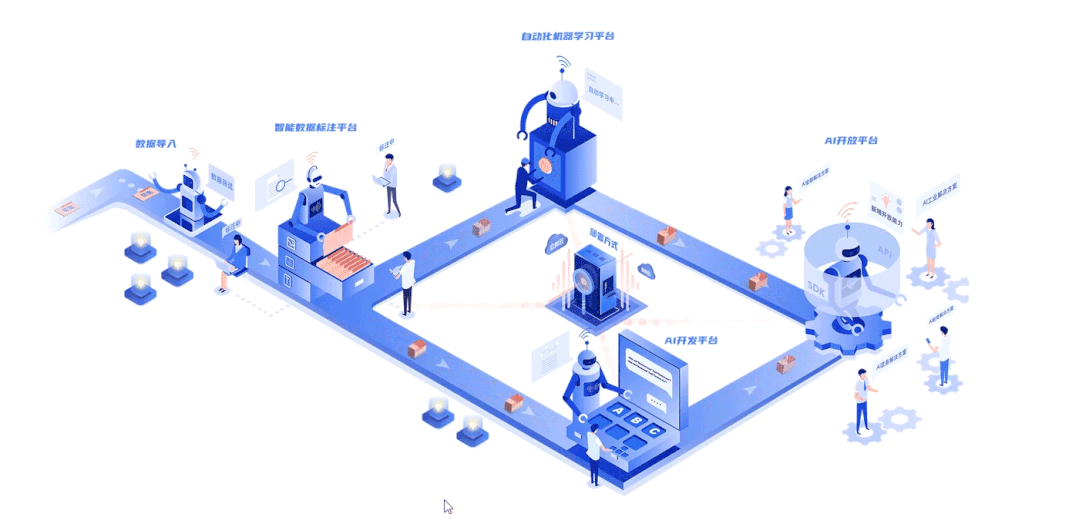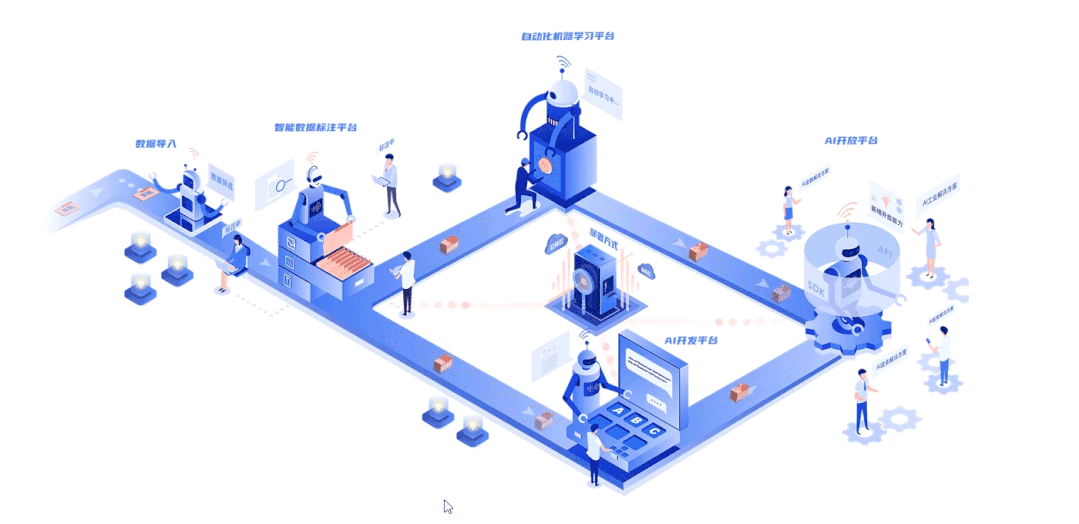
深延科技成立于2018年,是深兰科技(DeepBlue)旗下的子公司,以“人工智能赋能企业与行业”为使命,助力合作伙伴降低成本、提升效率并挖掘更多商业机会,进一步开拓市场,服务民生。公司推出四款平台产品——深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,涵盖从数据标注及处理,到模型构建,再到行业应用和解决方案的全流程服务,一站式助力企业“AI”化。