Pytorch基本操作(10)——完整的模型训练、验证套路
前言
在学习李沐在B站发布的《动手学深度学习》PyTorch版本教学视频中发现在操作使用PyTorch方面有许多地方看不懂,往往只是“动手”了,没有动脑。所以打算趁着寒假的时间好好恶补、整理一下PyTorch的操作,以便跟上课程。
学习资源:
- B站up主:我是土堆的视频:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
- PyTorch中文手册:(pytorch handbook)
- Datawhale开源内容:深入浅出PyTorch(thorough-pytorch)
import torchvision
import torch
from torch.utils.data import DataLoader
from torch import nn
from torch.utils.tensorboard import SummaryWriter
完整的模型训练套路
搭建网络模型
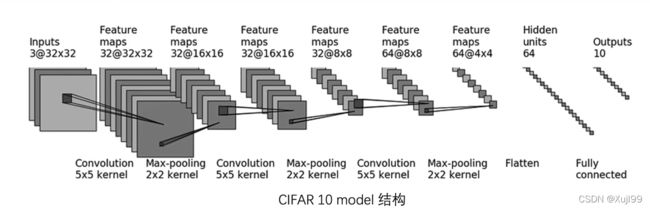
# 习惯上把模型单独存一个py文件里面,这里也把这个代码块存在"model.py"下
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding = 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding = 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == 'main':
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
关于__name__
准备数据集
train_data = torchvision.datasets.CIFAR10(root = "dataset", train=True, transform=torchvision.transforms.ToTensor(),
download = True)
test_data = torchvision.datasets.CIFAR10(root = "dataset", train=False, transform=torchvision.transforms.ToTensor(),
download = True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度为:50000
测试数据集的长度为:10000
利用Dataloader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
创建网络
注意model里面的Sequential引用了,外部就不要再import了,否则会报错
from model import * # 如果直接import model 的话使用model需要model.Tudui()
Tudui()
Tudui(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
tudui = Tudui()
损失函数
loss_fn = nn.CrossEntropyLoss()
优化器
# learning_rate = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
设置训练网络的一些参数
"""记录训练的次数"""
total_train_step = 0
"""记录测试的次数"""
total_test_step = 0
"""训练的轮数"""
epoch = 10
开始训练
# 添加tensorboard
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("-------第{}轮训练开始-------".format(i+1))
# 训练步骤开始
# tudui.train()#仅对dropout层和BatchNorm层有作用
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
# 减少显示量
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item())) # 这里的loss.item()可以返回非tensor的正常数字,方便可视化
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
# tudui.eval() #仅对dropout层和BatchNorm层有作用
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
# 这部分用于测试不用于训练所以不计算梯度
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum() #(1)是指对每一行搜索最大
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
writer.add_scalar("test_loss", total_test_loss, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
# torch.save(tuidui.state_dict(), "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
-------第1轮训练开始-------
训练次数:100, Loss:2.29325008392334
训练次数:200, Loss:2.283909559249878
训练次数:300, Loss:2.2683935165405273
训练次数:400, Loss:2.208040237426758
训练次数:500, Loss:2.077479362487793
训练次数:600, Loss:2.076197385787964
训练次数:700, Loss:2.0125396251678467
整体测试集上的Loss:311.0042494535446
整体测试集上的正确率:0.28690001368522644
模型已保存
-------第2轮训练开始-------
训练次数:800, Loss:1.8943209648132324
训练次数:900, Loss:1.8497763872146606
训练次数:1000, Loss:1.9259988069534302
训练次数:1100, Loss:1.9223729372024536
训练次数:1200, Loss:1.70912504196167
训练次数:1300, Loss:1.6560978889465332
训练次数:1400, Loss:1.7395917177200317
训练次数:1500, Loss:1.8148372173309326
整体测试集上的Loss:299.8941307067871
整体测试集上的正确率:0.31310001015663147
模型已保存
-------第3轮训练开始-------
训练次数:1600, Loss:1.7610538005828857
训练次数:1700, Loss:1.6932322978973389
训练次数:1800, Loss:1.9729604721069336
训练次数:1900, Loss:1.7057372331619263
训练次数:2000, Loss:1.9103789329528809
训练次数:2100, Loss:1.5418747663497925
训练次数:2200, Loss:1.5031366348266602
训练次数:2300, Loss:1.8073830604553223
整体测试集上的Loss:259.2040170431137
整体测试集上的正确率:0.4016000032424927
模型已保存
-------第4轮训练开始-------
训练次数:2400, Loss:1.7602804899215698
训练次数:2500, Loss:1.3938450813293457
训练次数:2600, Loss:1.5612308979034424
训练次数:2700, Loss:1.6809883117675781
训练次数:2800, Loss:1.4944334030151367
训练次数:2900, Loss:1.5898441076278687
训练次数:3000, Loss:1.34271240234375
训练次数:3100, Loss:1.511343002319336
整体测试集上的Loss:247.7659454345703
整体测试集上的正确率:0.4260999858379364
模型已保存
-------第5轮训练开始-------
训练次数:3200, Loss:1.303970217704773
训练次数:3300, Loss:1.4783345460891724
训练次数:3400, Loss:1.4903525114059448
训练次数:3500, Loss:1.5542851686477661
训练次数:3600, Loss:1.5686604976654053
训练次数:3700, Loss:1.2872371673583984
训练次数:3800, Loss:1.284749150276184
训练次数:3900, Loss:1.4711768627166748
整体测试集上的Loss:242.27887797355652
整体测试集上的正确率:0.4399999976158142
模型已保存
-------第6轮训练开始-------
训练次数:4000, Loss:1.3726962804794312
训练次数:4100, Loss:1.4828013181686401
训练次数:4200, Loss:1.5091488361358643
训练次数:4300, Loss:1.2292431592941284
训练次数:4400, Loss:1.163584589958191
训练次数:4500, Loss:1.3460476398468018
训练次数:4600, Loss:1.4269042015075684
整体测试集上的Loss:234.99573576450348
整体测试集上的正确率:0.4560000002384186
模型已保存
-------第7轮训练开始-------
训练次数:4700, Loss:1.3523941040039062
训练次数:4800, Loss:1.5344129800796509
训练次数:4900, Loss:1.3567960262298584
训练次数:5000, Loss:1.3714420795440674
训练次数:5100, Loss:0.9842540621757507
训练次数:5200, Loss:1.2979055643081665
训练次数:5300, Loss:1.2400109767913818
训练次数:5400, Loss:1.393009901046753
整体测试集上的Loss:226.84071695804596
整体测试集上的正确率:0.4796000123023987
模型已保存
-------第8轮训练开始-------
训练次数:5500, Loss:1.1929703950881958
训练次数:5600, Loss:1.2454817295074463
训练次数:5700, Loss:1.2415851354599
训练次数:5800, Loss:1.2181754112243652
训练次数:5900, Loss:1.3696681261062622
训练次数:6000, Loss:1.577223539352417
训练次数:6100, Loss:1.0177942514419556
训练次数:6200, Loss:1.0912299156188965
整体测试集上的Loss:215.75732743740082
整体测试集上的正确率:0.5087000131607056
模型已保存
-------第9轮训练开始-------
训练次数:6300, Loss:1.443060278892517
训练次数:6400, Loss:1.1173267364501953
训练次数:6500, Loss:1.5345420837402344
训练次数:6600, Loss:1.1260135173797607
训练次数:6700, Loss:1.0809710025787354
训练次数:6800, Loss:1.1551690101623535
训练次数:6900, Loss:1.0953528881072998
训练次数:7000, Loss:0.9307641983032227
整体测试集上的Loss:204.84118616580963
整体测试集上的正确率:0.5357999801635742
模型已保存
-------第10轮训练开始-------
训练次数:7100, Loss:1.2746365070343018
训练次数:7200, Loss:0.9630709290504456
训练次数:7300, Loss:1.0464202165603638
训练次数:7400, Loss:0.8529015183448792
训练次数:7500, Loss:1.1859822273254395
训练次数:7600, Loss:1.3062114715576172
训练次数:7700, Loss:0.8813175559043884
训练次数:7800, Loss:1.226499080657959
整体测试集上的Loss:196.155792593956
整体测试集上的正确率:0.5586000084877014
模型已保存
用时12m25s
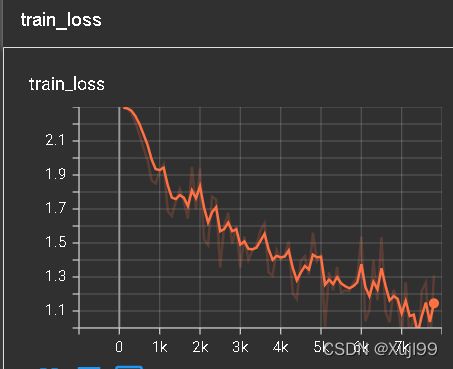
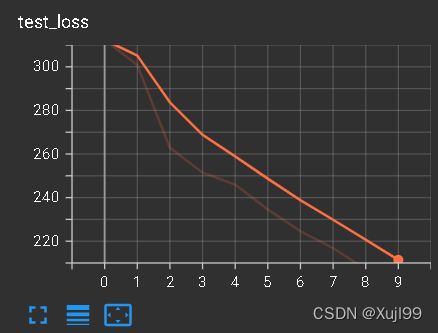

利用GPU训练
模型,损失函数,数据
第一种方式.cuda()
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda()
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
第二种方式.to(device)
device = torch.device("cpu")
device = torch.device("cuda")
device = torch.device("cuda:0")
device = torch.device("cuda:1")
tudui.to(device)
loss_fn.to(devce)
imgs = imgs.to(device)
device(type='cuda', index=1)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')
from model import * # 如果直接import model 的话使用model需要model.Tudui()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_data = torchvision.datasets.CIFAR10(root = "dataset", train=True, transform=torchvision.transforms.ToTensor(),
download = True)
test_data = torchvision.datasets.CIFAR10(root = "dataset", train=False, transform=torchvision.transforms.ToTensor(),
download = True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
tudui = Tudui()
tudui.to(device)
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# learning_rate = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
"""记录训练的次数"""
total_train_step = 0
"""记录测试的次数"""
total_test_step = 0
"""训练的轮数"""
epoch = 10
# 添加tensorboard
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("-------第{}轮训练开始-------".format(i+1))
# 训练步骤开始
# tudui.train()#仅对dropout层和BatchNorm层有作用
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
# 减少显示量
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item())) # 这里的loss.item()可以返回非tensor的正常数字,方便可视化
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
# tudui.eval() #仅对dropout层和BatchNorm层有作用
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
# 这部分用于测试不用于训练所以不计算梯度
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum() #(1)是指对每一行搜索最大
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
writer.add_scalar("test_loss", total_test_loss, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
# torch.save(tuidui.state_dict(), "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度为:50000
测试数据集的长度为:10000
-------第1轮训练开始-------
训练次数:100, Loss:2.2956652641296387
训练次数:200, Loss:2.289777994155884
训练次数:300, Loss:2.2651607990264893
训练次数:400, Loss:2.2075891494750977
训练次数:500, Loss:2.1386234760284424
训练次数:600, Loss:2.055907726287842
训练次数:700, Loss:1.988847255706787
整体测试集上的Loss:312.381210565567
整体测试集上的正确率:0.2849999964237213
模型已保存
-------第2轮训练开始-------
训练次数:800, Loss:1.8688374757766724
训练次数:900, Loss:1.8500841856002808
训练次数:1000, Loss:1.9199410676956177
训练次数:1100, Loss:1.9640048742294312
训练次数:1200, Loss:1.6866363286972046
训练次数:1300, Loss:1.6587870121002197
训练次数:1400, Loss:1.7443153858184814
训练次数:1500, Loss:1.8170870542526245
整体测试集上的Loss:300.8343594074249
整体测试集上的正确率:0.3174999952316284
模型已保存
-------第3轮训练开始-------
训练次数:1600, Loss:1.7429736852645874
训练次数:1700, Loss:1.643491268157959
训练次数:1800, Loss:1.947422742843628
训练次数:1900, Loss:1.6957898139953613
训练次数:2000, Loss:1.9376251697540283
训练次数:2100, Loss:1.5219039916992188
训练次数:2200, Loss:1.4877138137817383
训练次数:2300, Loss:1.7730400562286377
整体测试集上的Loss:262.9073522090912
整体测试集上的正确率:0.39489999413490295
模型已保存
-------第4轮训练开始-------
训练次数:2400, Loss:1.7554453611373901
训练次数:2500, Loss:1.3557775020599365
训练次数:2600, Loss:1.601438283920288
训练次数:2700, Loss:1.6769195795059204
训练次数:2800, Loss:1.4934691190719604
训练次数:2900, Loss:1.5987865924835205
训练次数:3000, Loss:1.3547706604003906
训练次数:3100, Loss:1.5375285148620605
整体测试集上的Loss:251.40372455120087
整体测试集上的正确率:0.42309999465942383
模型已保存
-------第5轮训练开始-------
训练次数:3200, Loss:1.4001057147979736
训练次数:3300, Loss:1.4579328298568726
训练次数:3400, Loss:1.4868910312652588
训练次数:3500, Loss:1.5736465454101562
训练次数:3600, Loss:1.6154143810272217
训练次数:3700, Loss:1.327691912651062
训练次数:3800, Loss:1.3083850145339966
训练次数:3900, Loss:1.4584790468215942
整体测试集上的Loss:246.00046956539154
整体测试集上的正确率:0.43309998512268066
模型已保存
-------第6轮训练开始-------
训练次数:4000, Loss:1.4018315076828003
训练次数:4100, Loss:1.4277464151382446
训练次数:4200, Loss:1.5089188814163208
训练次数:4300, Loss:1.2022169828414917
训练次数:4400, Loss:1.1702873706817627
训练次数:4500, Loss:1.395234227180481
训练次数:4600, Loss:1.422357201576233
整体测试集上的Loss:234.6010730266571
整体测试集上的正确率:0.4512999951839447
模型已保存
-------第7轮训练开始-------
训练次数:4700, Loss:1.313550591468811
训练次数:4800, Loss:1.561052918434143
训练次数:4900, Loss:1.392410397529602
训练次数:5000, Loss:1.4247487783432007
训练次数:5100, Loss:1.0075993537902832
训练次数:5200, Loss:1.328966498374939
训练次数:5300, Loss:1.220709204673767
训练次数:5400, Loss:1.358386516571045
整体测试集上的Loss:224.60081231594086
整体测试集上的正确率:0.47859999537467957
模型已保存
-------第8轮训练开始-------
训练次数:5500, Loss:1.2082645893096924
训练次数:5600, Loss:1.2206870317459106
训练次数:5700, Loss:1.2155909538269043
训练次数:5800, Loss:1.264174222946167
训练次数:5900, Loss:1.3011680841445923
训练次数:6000, Loss:1.536810278892517
训练次数:6100, Loss:1.0403668880462646
训练次数:6200, Loss:1.1068507432937622
整体测试集上的Loss:216.78163981437683
整体测试集上的正确率:0.5008999705314636
模型已保存
-------第9轮训练开始-------
训练次数:6300, Loss:1.397782802581787
训练次数:6400, Loss:1.1621772050857544
训练次数:6500, Loss:1.5353243350982666
训练次数:6600, Loss:1.0948131084442139
训练次数:6700, Loss:1.0332701206207275
训练次数:6800, Loss:1.224757194519043
训练次数:6900, Loss:1.1486912965774536
训练次数:7000, Loss:0.9570747017860413
整体测试集上的Loss:207.18361151218414
整体测试集上的正确率:0.5292999744415283
模型已保存
-------第10轮训练开始-------
训练次数:7100, Loss:1.2685602903366089
训练次数:7200, Loss:0.9366878271102905
训练次数:7300, Loss:1.0904749631881714
训练次数:7400, Loss:0.8180400133132935
训练次数:7500, Loss:1.2180923223495483
训练次数:7600, Loss:1.2670235633850098
训练次数:7700, Loss:0.8642953634262085
训练次数:7800, Loss:1.3094435930252075
整体测试集上的Loss:197.68658405542374
整体测试集上的正确率:0.5529999732971191
模型已保存
gpu上的训练仅用时2m8s,快了10m
完整的模型验证套路
from PIL import Image
image_path = "dog.png"
image = Image.open(image_path)
image = image.convert('RGB')
print(image)
transform = torchvision.transforms.Compose(
[ torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()]
)
image = transform(image)
print(image.shape)
torch.Size([3, 32, 32])
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding = 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding = 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
model = torch.load('tudui_9.pth')
model
Tudui(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
image = torch.reshape(image, (1,3,32,32))
image = image.to(device)
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
tensor([[-0.0771, -4.0209, 1.8172, 3.0104, 0.3398, 3.0585, 1.0830, -0.0867,
-1.0371, -3.0783]], device='cuda:0')
tensor([5], device='cuda:0')
test_data.class_to_idx
{'airplane': 0,
'automobile': 1,
'bird': 2,
'cat': 3,
'deer': 4,
'dog': 5,
'frog': 6,
'horse': 7,
'ship': 8,
'truck': 9}
[5]对应狗