机器学习/深度学习开发框架
目录
命令式/符号式编程
TensorFlow
PyTorch
Theano
Caffe:Convolutional Architecture Forfast Feature Embedding
MXNET
CNTK:Microsoft cognitive toolkit,微软认知工具包
DL4J
PaddlePaddle
Keras
Fastai
Gluon
命令式/符号式编程
def add(a, b):
return a + b
def fancy_func(a, b, c, d):
e = add(a, b)
f = add(c, d)
g = add(e, f)
return g
fancy_func(1,2,3,4)# 10在运行语句e = add(a, b)时,Python会做加法运算并将结果存储在变量e中,从而令程序的状态发生改变。类似地,后面的两条语句f = add(c, d)和g = add(e, f)会依次做加法运算并存储变量。
虽然使用命令式编程很方便,但它的运行可能很慢。一方面,即使fancy_func函数中的add是被重复调用的函数,Python也会逐一执行这3条函数调用语句。另一方面,我们需要保存变量e和f的值直到fancy_func中所有语句执行结束。这是因为在执行e = add(a, b)和f = add(c, d)这2条语句之后我们并不知道变量e和f是否会被程序的其他部分使用。
与命令式编程不同,符号式编程通常在计算流程完全定义好后才被执行。多个深度学习框架,如Theano和TensorFlow,都使用了符号式编程。通常,符号式编程的程序需要下面3个步骤:
- 定义计算流程;
- 把计算流程编译成可执行的程序;
- 给定输入,调用编译好的程序执行。
下面我们用符号式编程重新实现本节开头给出的命令式编程代码。
def add_str():
return'''
def add(a, b):
return a + b
'''
def fancy_func_str():
return'''
def fancy_func(a, b, c, d):
e = add(a, b)
f = add(c, d)
g = add(e, f)
return g
'''
def evoke_str():
return add_str()+ fancy_func_str()+'''
print(fancy_func(1, 2, 3, 4))
'''
prog = evoke_str()
print(prog)
y = compile(prog,'','exec')
exec(y)输出
def add(a, b):
return a + b
def fancy_func(a, b, c, d):
e = add(a, b)
f = add(c, d)
g = add(e, f)
return g
print(fancy_func(1,2,3,4))
10以上定义的3个函数都仅以字符串的形式返回计算流程。最后,我们通过compile函数编译完整的计算流程并运行。由于在编译时系统能够完整地获取整个程序,因此有更多空间优化计算。例如,编译的时候可以将程序改写成print((1 + 2) + (3 + 4)),甚至直接改写成print(10)。这样不仅减少了函数调用,还节省了内存。
对比这两种编程方式,我们可以看到以下两点。
-
命令式编程更方便。当我们在Python里使用命令式编程时,大部分代码编写起来都很直观。同时,命令式编程更容易调试。这是因为我们可以很方便地获取并打印所有的中间变量值,或者使用Python的调试工具。
-
符号式编程更高效并更容易移植。一方面,在编译的时候系统容易做更多优化;另一方面,符号式编程可以将程序变成一个与Python无关的格式,从而可以使程序在非Python环境下运行,以避开Python解释器的性能问题。
TensorFlow
TensorFlow is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries, and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML-powered applications. TensorFlow was originally developed by researchers and engineers working on the Google Brain team within Google's Machine Intelligence Research organization to conduct machine learning and deep neural networks research. The system is general enough to be applicable in a wide variety of other domains, as well. TensorFlow provides stable Python and C++ APIs, as well as non-guaranteed backward compatible API for other languages.
PyTorch
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。 2017年1月,由Facebook人工智能研究院(FAIR)基于Torch推出了PyTorch。它是一个基于Python的可续计算包,提供两个高级功能:1、具有强大的GPU加速的张量计算(如NumPy)。2、包含自动求导系统的深度神经网络。
Theano
Theano 在深度学习框架中是祖师级的存在。它的开发始于 2007,早期开发者包括传奇人物 Yoshua Bengio 和 Ian Goodfellow。
Theano 基于 Python,是一个擅长处理多维数组的库(这方面它类似于 NumPy)。当与其他深度学习库结合起来,它十分适合数据探索。它为执行深度学习中大规模神经网络算法的运算所设计。其实,它可以被更好地理解为一个数学表达式的编译器:用符号式语言定义你想要的结果,该框架会对你的程序进行编译,来高效运行于 GPU 或 CPU。
Caffe:Convolutional Architecture Forfast Feature Embedding
Caffe是一个兼具表达性、速度和思维模块化的深度学习框架。由伯克利人工智能研究小组和伯克利视觉和学习中心开发。虽然其内核是用C++编写的,但Caffe有Python和Matlab 相关接口。Caffe支持多种类型的深度学习架构,面向图像分类和图像分割,还支持CNN、RCNN、LSTM和全连接神经网络设计。Caffe支持基于GPU和CPU的加速计算内核库,如NVIDIA cuDNN和Intel MKL。
MXNET
MXNet 是亚马逊(Amazon)选择的深度学习库。它拥有类似于 Theano 和 TensorFlow 的数据流图,为多 GPU 配置提供了良好的配置,有着类似于 Lasagne 和 Blocks 更高级别的模型构建块,并且可以在你可以想象的任何硬件上运行(包括手机)。对 Python 的支持只是其冰山一角—MXNet 同样提供了对 R、Julia、C++、Scala、Matlab,和 Javascript 的接口。
CNTK:Microsoft cognitive toolkit,微软认知工具包
The Microsoft Cognitive Toolkit is a unified deep learning toolkit that describes neural networks as a series of computational steps via a directed graph. In this directed graph, leaf nodes represent input values or network parameters, while other nodes represent matrix operations upon their inputs. CNTK allows users to easily realize and combine popular model types such as feed-forward DNNs, convolutional nets (CNNs), and recurrent networks (RNNs/LSTMs). It implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers. CNTK has been available under an open-source license since April 2015. It is our hope that the community will take advantage of CNTK to share ideas more quickly through the exchange of open source working code.
DL4J
Eclipse Deeplearning4J (DL4J) 是包含深度学习工具和库的框架,专为充分利用 Java™ 虚拟机 (JVM) 而编写。它具有为 Java 和 Scala 语言编写的分布式深度学习库,并且内置集成了 Apache Hadoop 和 Spark。Deeplearning4j 有助于弥合使用 Python 语言的数据科学家和使用 Java 语言的企业开发人员之间的鸿沟,从而简化了在企业大数据应用程序中部署深度学习的过程。 DL4J 是由来自旧金山和东京的一群开源贡献者协作开发的。2014 年末,他们将其发布为 Apache 2.0 许可证下的开源框架。主要是作为一种平台来使用,通过这种平台来部署商用深度学习算法。创立于 2014 年的 Skymind 是 DL4J 的商业支持机构。 2017 年 10 月,Skymind 加入了 Eclipse 基金会,并且将 DL4J 贡献给开源 Java Enterprise Edition 库生态系统。有了 Eclipse 基金会的支持,人们能够更加肯定 DL4J 项目必将得到妥善监管,同时也确保为商业开发提供合适的开源许可证。Java AI 开发人员已将 DL4J 视为成熟且安全的框架,因此,这些新建立的伙伴关系将吸引企业在商业领域使用 DL4J。
PaddlePaddle
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体。目前,飞桨累计开发者194万,服务企业8.4万家,基于飞桨开源深度学习平台产生了23.3万个模型。飞桨助力开发者快速实现AI想法,快速上线AI业务。帮助越来越多的行业完成AI赋能,实现产业智能化升级。
Keras
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。 Keras在代码结构上由面向对象方法编写,完全模块化并具有可扩展性,其运行机制和说明文档有将用户体验和使用难度纳入考虑,并试图简化复杂算法的实现难度。Keras支持现代人工智能领域的主流算法,包括前馈结构和递归结构的神经网络,也可以通过封装参与构建统计学习模型。在硬件和开发环境方面,Keras支持多操作系统下的多GPU并行计算,可以根据后台设置转化为Tensorflow、Microsoft-CNTK等系统下的组件。 Keras的主要开发者是谷歌工程师François Chollet,此外其GitHub项目页面包含6名主要维护者和超过800名直接贡献者。Keras在其正式版本公开后,除部分预编译模型外,按MIT许可证开放源代码。
Fastai
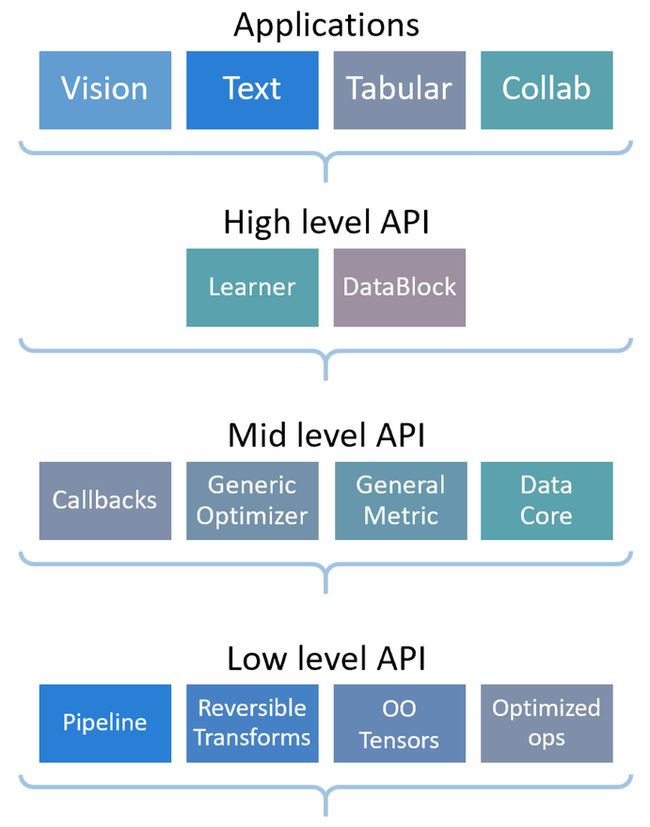
Fastai is a deep learning library which provides practitioners with high-level components that can quickly and easily provide state-of-the-art results in standard deep learning domains, and provides researchers with low-level components that can be mixed and matched to build new approaches. It aims to do both things without substantial compromises in ease of use, flexibility, or performance. This is possible thanks to a carefully layered architecture, which expresses common underlying patterns of many deep learning and data processing techniques in terms of decoupled abstractions. These abstractions can be expressed concisely and clearly by leveraging the dynamism of the underlying Python language and the flexibility of the PyTorch library. fastai includes:
- A new type dispatch system for Python along with a semantic type hierarchy for tensors
- A GPU-optimized computer vision library which can be extended in pure Python
- An optimizer which refactors out the common functionality of modern optimizers into two basic pieces, allowing optimization algorithms to be implemented in 4–5 lines of code
- A novel 2-way callback system that can access any part of the data, model, or optimizer and change it at any point during training
- A new data block API
Fastai is organized around two main design goals: to be approachable and rapidly productive, while also being deeply hackable and configurable. It is built on top of a hierarchy of lower-level APIs which provide composable building blocks. This way, a user wanting to rewrite part of the high-level API or add particular behavior to suit their needs does not have to learn how to use the lowest level.
Gluon
Gluon 是微软联合亚马逊推出的一个开源深度学习库,这是一个清晰、简洁、简单但功能强大的深度学习 API,该规范可以提升开发人员学习深度学习的速度,而无需关心所选择的深度学习框架。Gluon API 提供了灵活的接口来简化深度学习原型设计、创建、训练以及部署,而且不会牺牲数据训练的速度。
Gluon 规范已经在 Apache MXNet 中实现,只需要安装最新的 MXNet 即可使用。
主要优势包括:
-
代码简单,易于理解
-
灵活,命令式结构: 不需要严格定义神经网络模型,而是将训练算法和模型更紧密地结合起来,开发灵活
-
动态图: Gluon 可以让开发者动态的定义神经网络模型,这意味着他们可以在运行时创建模型、结构,以及使用任何 Python 原生的控制流
-
高性能: Gluon 所提供的这些优势对底层引擎的训练速度并没有任何影响