Docker安装MySQL,配置主从,读写分离
MySQL主从复制
为什么要使用主从复制
主从复制读写分离一般都是一起使用的,目的简单,为了提高数据库的并发。
如果是单机库,读写都在一台MySQL中完成,I/O频率过高,采用多机部署,读写分离,可以提高数据库的可用性
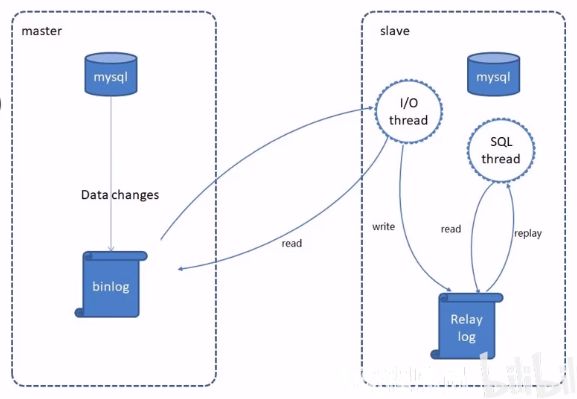
MySQL主从复制是一个异步的过程,底层是基于MySQL数据库自带的二进制日志功能,将一台或者多台MySQL数据库(即slave,从库)从另一台MySQL数据库(Master,即主库)进行日志的复制然后解析日志并应用到本身,最后实现从库数据与主库的数据保持一致。
MySQL复制过程分为三步
- master将改变以二进制数据的形式存储到二进制(binary log)
- slave 将master的binary log拷贝到他的中继日志 (relay log)
- slave重做中继日志中的事件 将改变应用到自己的数据库中
安装Docker和MySQL
准备两台机器,分别安装MySQL
使用docker快速安装MySQL
妈的 之前搞的虚拟机的静态id 突然访问不了外网 搞一下午又 giao,顺便复习一下Docker
1.首先需要大家虚拟机联网,安装yum工具
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2 --skip-broken
2.设置镜像源
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum makecache fast
3.安装Docker
yum install -y docker-ce
4.启动Docker
确保防火墙关闭
关闭
systemctl stop firewalld
禁止开机启动防火墙
systemctl disable firewalld
查看防火墙状态
systemctl status fi
systemctl start dokcer
5.拉取MySQL镜像
docker pull mysql:5.7.25
查看容器中的镜像
docker images
在本地创建mysql的映射目录
mkdir -p /root/mysql/data /root/mysql/logs /root/mysql/conf
在/root/mysql/conf中创建 *.cnf 文件(叫什么都行)
touch my.cnf
创建容器,将数据,日志,配置文件映射到本机
docker run -p 3306:3306 --name mysql -v /root/mysql/conf:/etc/mysql/conf.d -v /root/mysql/logs:/logs -v /root/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
-d: 后台运行容器
-p 将容器的端口映射到本机的端口
-v 将主机目录挂载到容器的目录
-e 设置参数
启动MySQL容器
docker start mysql
进入到MySQL容器
docker exec -it mysql bash
- docker exec :进入容器内部,执行一个命令
- -it : 给当前进入的容器创建一个标准输入、输出终端,允许我们与容器交互
- mn :要进入的容器的名称
- bash:进入容器后执行的命令,bash是一个linux终端交互命令
切换至 cd /etc/mysql/mysql.conf.d:/目录 修改其配置文件
安装vim
apt-get update
apt-get install vim
主库添加以下配置
[mysqld]
## 同一局域网内注意要唯一
server-id=100
## 开启二进制日志功能,可以随便取(关键)
log-bin=mysql-bin
从库添加以下配置
[mysqld]
## 同一局域网内注意要唯一
server-id=101
添加完重新启动MySQL
exit //退出
docker stop mysql
docker start mysql
主库执行
GRANT REPLICATION SLAVE ON *.* to'xiaoming'@'%' identified by '123456'
从库执行SQL
change master to master_host=‘192.168.37.129’, master_port=3306, master_user=‘xiaoming’, master_password=‘123456’,master_log_file=‘mysql-bin.000001’, master_log_pos=154;
start salve;
查看从库状态
show slave status
Slave_IO_State 为 Waiting for master to send event 代表配置成功
通过远程连接 测试
在主库中添加一个数据库,数据表,表记录 从库也会成功执行;
操作实战
使用sharding-jdbc我们可以通过配置主库从库,从而实现读写分离
ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
导入依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
修改配置文件
spring:
application:
#应用的名称,可选
name: reggie_take_out
shardingsphere:
datasource:
names:
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.37.129:3306/reggie?characterEncoding=utf-8
username: root
password:
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.37.128:3306/reggie?characterEncoding=utf-8
username: root
password:
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false
main:
allow-bean-definition-overriding: true #运行Bean定义覆盖 后初始化的bean覆盖先初始化的
来自瑞吉外卖优化篇,学会了主从复制读写分离,感觉自己又行了!!!
项目地址:https://gitee.com/xing-da-cute/reggie_take_out
l:
show: true #开启SQL显示,默认false
main:
allow-bean-definition-overriding: true #运行Bean定义覆盖 后初始化的bean覆盖先初始化的
> 来自瑞吉外卖优化篇,学会了主从复制读写分离,感觉自己又行了!!!
项目地址:https://gitee.com/xing-da-cute/reggie_take_out