猿创征文|Text to image论文精读SD-GAN:文本到图像生成的语义分解Semantics Disentangling for Text-to-Image Generation
目录
- 一、原文摘要
- 二、为什么提出SD-GAN?
- 三、条件批量归一化(CBN)
- 四、基于语义分解的生成对抗网络SD-GAN
- 4.1、网络结构
- 4.2、具有对比损失的孪生结构
- 4.3、语义条件批量归一化(SCBN)
- 4.3.1、批量归一化(BN)
- 4.3.2、条件批量归一化(CBN)
- 4.3.3、语义条件批量归一化(SCBN)
- 五、实验
- 5.1、实验设置
- 5.2、实验结果
- 六、总结
- 最后
SD-GAN是中科大、香港中文大学、北航等学者2019年提出的一个文本生成图像模型。其通过在鉴别器当中增加孪生机制,并通过语义条件批量归一化来发现不同低级语义的视觉嵌入策略。
论文地址:https://ieeexplore.ieee.org/document/8953563
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、原文摘要
从文本描述合成照片真实感图像是一个具有挑战性的问题。先前的研究表明,在生成图像的视觉质量方面取得了显著进展。在本文中,我们考虑了输入文本描述的语义,以帮助渲染照片真实感图像。然而,不同的语言表达在提取一致的语义方面提出了挑战,即使它们描述了相同的东西。为此,我们提出了一种新的照片真实感文本到图像生成模型,该模型隐式地分解语义,以实现高级语义一致性和低级语义多样性。具体而言,我们设计了(1)鉴别器中的连体机制来学习一致的高级语义,以及(2)通过语义条件化批量归一化来发现不同的低级语义的视觉语义嵌入策略。对CUB和MS-COCO数据集进行的大量实验和消融研究表明,与现有方法相比,该方法具有优越性。
二、为什么提出SD-GAN?
与随机噪声、标签图或草图等条件相比,从文本生成图像是一种更自然但更具挑战性的方法,因为(1)语言描述是人类描述图像的自然和方便的媒介,但(2)跨模态文本到图像生成仍然具有挑战性。
以往的方法忽略了一个重要现象:即对同一图像的人类描述在表达上具有高度的主观性和多样性,比如一张图像有多种句式表达方式:this yellow bird’s crown is black and it has speckled wings和a yellow bird has speckled wings and a black crown 意思相同,他们理应形容同一张图像,但大多数模型生成的两张图像如下,其实相差甚远:
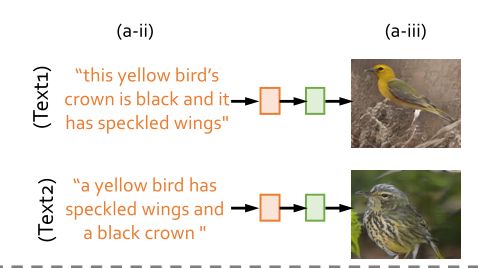
这表明语言表达变体的生成偏差给文本语义图像生成带来了巨大挑战。描述的变化可能导致图像生成的偏差,即使它们用非常相似的语义表达描述同一只鸟。
语义分解生成对抗网络(SD-GAN)提出了一种新方法有效地利用了生成过程中输入文本的语义。SDGAN从文本中提取语义公域以实现图像生成的一致性,同时保留语义多样性和细节以用于细粒度图像生成。通过SD-GAN,具有相似语言语义的类内对应该生成在鉴别器的特征空间中具有较小距离的一致图像,而类间对必须承受更大的距离。
三、条件批量归一化(CBN)
批量归一化(BN)是一种广泛使用的技术,通过针对每个小批量归一化整个网络的激活来改进神经网络训练。通过减少整个网络中的协变量移位,BN已被证明可以加速训练并提高泛化,并在控制图像样式化、视觉推理、视频分割、问答等任务的主网络行为运用。而SD-GAN首先将条件批量归一化运用到图像生成当中。
四、基于语义分解的生成对抗网络SD-GAN
4.1、网络结构

如上图所示,受到多阶段生成对抗网络(如StackGAN++、AttnGAN、DMGAN)的启发,其同样使用了采用了从低分辨率到高分辨率的分层阶段,下一阶段使用前一阶段的输出以及句子特征生成具有高分辨率的图像。
4.2、具有对比损失的孪生结构
对比损失用于最小化由同一真实图像的两个描述生成的假图像的距离,同时最大化不同真实图像的距离。
分别向孪生结构的两个分支输入两个不同的文本描述。如果从两个分支生成的视觉特征是同一语义的,则两个生成的图像应该相似(即,距离很小)。否则,两个生成的图像应该不同(即,距离较大)。为此,我们采用对比损失从输入描述对中提取语义信息。[12]中首次引入了对比损耗,损失函数公式为: L c = 1 2 N ∑ n = 1 N y ⋅ d 2 + ( 1 − y ) max ( ε − d , 0 ) 2 L_{c}=\frac{1}{2 N} \sum_{n=1}^{N} y \cdot d^{2}+(1-y) \max (\varepsilon-d, 0)^{2} Lc=2N1∑n=1Ny⋅d2+(1−y)max(ε−d,0)2,其中 d = ∥ v 1 − v 2 ∥ 2 d=\left\|v_{1}-v_{2}\right\|_{2} d=∥v1−v2∥2是来自两个孪生分支的视觉特征向量之间的距离。由于存在噪声,故作者设分支之间最低距离为α(α=0.1),公式转换为: L c = 1 2 N ∑ n = 1 N y max ( d , α ) 2 + ( 1 − y ) max ( ε − d , 0 ) 2 L_{c}=\frac{1}{2 N} \sum_{n=1}^{N} y \max (d, \alpha)^{2}+(1-y) \max (\varepsilon-d, 0)^{2} Lc=2N1∑n=1Nymax(d,α)2+(1−y)max(ε−d,0)2
在对比损失的情况下,通过最小化从同一图像的描述生成的图像之间的距离,并最大化从不同图像的描述产生的图像的距离,来优化此孪生结构。
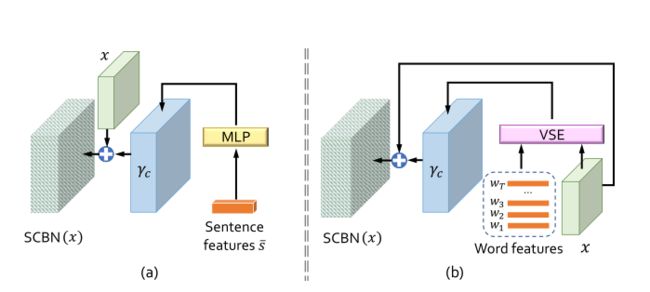
4.3、语义条件批量归一化(SCBN)
SCBN的目的是增强生成网络特征图中的视觉语义嵌入。它使语言嵌入能够通过放大或缩小、否定或关闭视觉特征图等操作视觉特征图
4.3.1、批量归一化(BN)
给定 x ∈ R N × C × H × W x \in \mathbb{R}^{N \times C \times H \times W} x∈RN×C×H×W,BatchNorm将每个单独特征通道的平均值和标准差进行归一化: B N ( x ) = γ ⋅ x − μ ( x ) σ ( x ) + β \mathrm{BN}(x)=\gamma \cdot \frac{x-\mu(x)}{\sigma(x)}+\beta BN(x)=γ⋅σ(x)x−μ(x)+β,其中, γ \gamma γ和 β \beta β是从数据中学习的仿射参数,u表示均值, σ \sigma σ表示标准差。
4.3.2、条件批量归一化(CBN)
条件批量归一化利用条件线索c学习调制参数 γ c \gamma_c γc和 β c \beta_c βc,根据条件信息(如文本、类别等监督信息)进行批量归一化: BN ( x ∣ c ) = ( γ + γ c ) ⋅ x − μ ( x ) σ ( x ) + ( β + β c ) \operatorname{BN}(x \mid c)=\left(\gamma+\gamma_{c}\right) \cdot \frac{x-\mu(x)}{\sigma(x)}+\left(\beta+\beta_{c}\right) BN(x∣c)=(γ+γc)⋅σ(x)x−μ(x)+(β+βc)
4.3.3、语义条件批量归一化(SCBN)
作者将语义条件批量归一化分成了两个方面:Sentence-level和Word-level
- Sentence-level Cues:采用单隐层多层感知器(MLP)分别从输入描述的句子特征向量中提取调制参数: γ c = f γ ( s ˉ ) , β c = f β ( s ˉ ) \gamma_{c}=f_{\gamma}(\bar{s}), \beta_{c}=f_{\beta}(\bar{s}) γc=fγ(sˉ),βc=fβ(sˉ), f γ ( . ) f_γ(.) fγ(.)和 f β ( . ) f_β(.) fβ(.)分别表示 γ c γ_c γc和 β c β_c βc的一个隐层MLP,学习到调制参数后将其代入4.3.2的 BN ( x ∣ c ) = ( γ + γ c ) ⋅ x − μ ( x ) σ ( x ) + ( β + β c ) \operatorname{BN}(x \mid c)=\left(\gamma+\gamma_{c}\right) \cdot \frac{x-\mu(x)}{\sigma(x)}+\left(\beta+\beta_{c}\right) BN(x∣c)=(γ+γc)⋅σ(x)x−μ(x)+(β+βc)中,从而使用语句特征通过通道的方式调节生成的视觉特征。
- Word-level Cues:单词嵌入为 W = { w t } t = 1 T ∈ R D × T \mathcal{W}=\left\{w_{t}\right\}_{t=1}^{T} \in \mathbb{R}^{D \times T} W={wt}t=1T∈RD×T,其中wt是第t个单词的特征。图像特征为 X ∈ R C × L \mathcal{X} \in \mathbb{R}^{C \times L} X∈RC×L,其中C表示通道数,L=W×H。使用一种视觉语义嵌入(VSE)模块融合词特征和视觉特征。VSE首先使用感知层(即 f ( w t ) f(w_t) f(wt))来匹配文本特征和视觉特征的维度,基于图像的每个子区域j的嵌入特征 v j v_j vj来计算VSE向量 v s e j v_{sej} vsej, v s e j v_{sej} vsej计算方法与AttnGAN类似,其计算每个单词与图像子区域的相关度: v s e j = ∑ t = 0 T − 1 σ ( v j ⊤ ⋅ f ( w t ) ) f ( w t ) \mathrm{vse}_{j}=\sum_{t=0}^{T-1} \sigma\left(v_{j}^{\top} \cdot f\left(w_{t}\right)\right) f\left(w_{t}\right) vsej=∑t=0T−1σ(vj⊤⋅f(wt))f(wt)
五、实验
5.1、实验设置
数据集:CUB、COCO
训练细节:损失函数与AttnGAN相同,文本编码器预训练好后固定参数,随机初始化生成器和鉴别器的网络参数
5.2、实验结果
在CUB上和COCO上进行了实验,实验基于同一真实图像的两个随机选择的文本描述生成图像,图像效果如下所示:

定量指标实验测得IS如下:

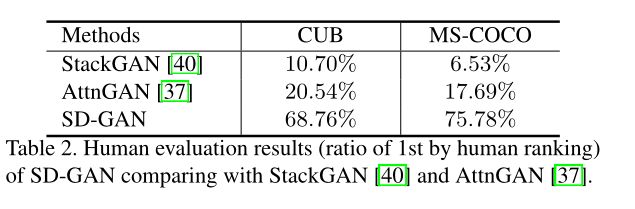
此外,作者额外设计了用户调研实验,问卷调查人类主观最好的图像,结果如下:
消融实验结果:


模型捕捉细微变化的能力实验

另外作者还设计了大量的消融研究,包括对比损失的α取值、对比损失的阶段数,SCBN的有效性等,详细请看原文。
六、总结
SDGAN主要有以下贡献:
- 第一次将孪生结构引入文本生成图像模型,引入对比损失,从文本中提取语义公域以实现图像生成的一致性,同时保留语义多样性和细节以用于细粒度图像生成。
- 设计了一种增强的视觉语义嵌入方法,通过使用实例语言线索重新格式化批量规范化层,语义条件批量归一化是一种很好用的文本监督和约束图像生成的方法,这个在DF-GAN中也使用。基于此,语言嵌入可以进一步指导用于细粒度图像生成的视觉模式合成。
- 比较丰富的实验和消融研究。
最后
个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
关注我:中杯可乐多加冰
限时免费订阅:文本生成图像T2I专栏
支持我:点赞+收藏⭐️+留言