flume flume采集目录到HDFS
flume采集目录到HDFS
- 采集新增文件到HDFS
-
- flume配置文件
- 定义agent内组件
- 定义source
- 定义channel
- 定义sink
-
- round相关参数示例说明
- 整合上 面全部内容到spooldir.conf中
- 采集指定文件新增内容到HDFS
-
- flume的配置文件
- agent
- source
- channel
- sink
- 整合后
- 官网地址
采集新增文件到HDFS
此案例为了方便观察采集结果,设置的采集频率都比较高,实际应用中频率不应该这么高
同时通过大小和实际控制临时文件滚动生成目标文件
- 结构示意图
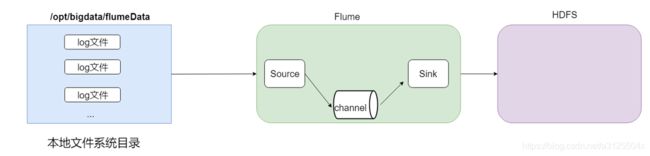
- 采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去
- 需求分析:
根据需求,首先定义以下3大要素 - 数据源组件,即source ——监控文件目录 : spooldir
spooldir特性:
1.监视一个目录,只要目录中出现新文件,就会采集文件中的内容
2.采集完成的文件,会被agent自动添加一个后缀:COMPLETED
3.所监视的目录中不允许重复出现相同文件名的文件 - 下沉组件,即sink——HDFS文件系统 : hdfs sink
- 通道组件,即channel——可用file channel 也可以用内存channel
flume配置文件
cd /bg/apache-flume-1.6.0-cdh5.14.2-bin/conf
mkdir -p /bg/dirfile
vim spooldir.conf
定义agent内组件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
定义source
# Describe/configure the source
##注意:不能往监控目中重复丢同名文件
a1.sources.r1.type = spooldir
## source类型为spooldir
a1.sources.r1.spoolDir = /test/dirfile
## 是否添加文件的绝对路径到event的header中,默认是false
a1.sources.r1.fileHeader = true
注意:flume中重复添加相同名称的文件,flume会崩溃无法继续运行。
定义channel
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
## channel的容量:1000条数据
a1.channels.c1.capacity = 1000
## 一次从source拿去或者输出到sink的最大容量
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意:
- 使用memory channel当数据宕机时,channel中未传送至sink端的数据会丢失。
- 可以使用file channel代替。当flume重启启动后,会读取file channel内的数据
- 也可以不定义sink 直接将数据输出到kafka的topic中
定义sink
# Describe the sink
## 定义输出类型
a1.sinks.k1.type = hdfs
## channel需要和agent设置中的名称保持一致
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://node01:8020/spooldir/files/%y-%m-%d/%H%M/
## 生成的文件名前缀,默认是FlumeData
a1.sinks.k1.hdfs.filePrefix = events-
## 以下3个round相关参数设置用来控制多久生成一个文件
## 时间戳是否四舍五入,默认false
a1.sinks.k1.hdfs.round = true
## 时间上进行舍弃的值
a1.sinks.k1.hdfs.roundValue = 10
## 时间上进行舍弃的单位
a1.sinks.k1.hdfs.roundUnit = minute
## 设置true则使用本地时间生成文件 而不是event中的header的时间戳生成文件
a1.sinks.k1.hdfs.useLocalTimeStamp = true
## hdfs sink间隔多长将临时文件滚动成最终目标文件,单位秒
a1.sinks.k1.hdfs.rollInterval = 3
## 当临时文件大小达到指定大小时生成文件,单位bytes。 设置为0 则不关闭大小限制
a1.sinks.k1.hdfs.rollSize = 20
## 写入多少个event后,将临时文件滚动生成目标文件
a1.sinks.k1.hdfs.rollCount = 5
## 每次刷到HDFS处理的event的个数
a1.sinks.k1.hdfs.batchSize = 1
注意:
- 滚动(roll)指的是,hdfs sink将临时文件重命名成最终目标文件,并新打开一个临时文件来写入数据
round相关参数示例说明
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
当时间为2015-10-16 17:38:59时候,hdfs.path依然会被解析为:
/flume/events/20151016/17:30/00
因为设置的是舍弃10分钟内的时间,因此,该目录每10分钟新生成一个。
整合上 面全部内容到spooldir.conf中
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
##注意:不能往监控目中重复丢同名文件
a1.sources.r1.type = spooldir
## source类型为spooldir
a1.sources.r1.spoolDir = /test/dirfile
## 是否添加文件的绝对路径到event的header中,默认是false
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://node01:8020/spooldir/files/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
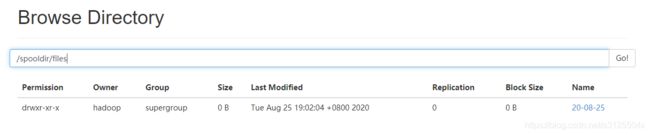
输出结果

- 在HDFS上指定目录下,采集到目标文件,并以指定前缀开头

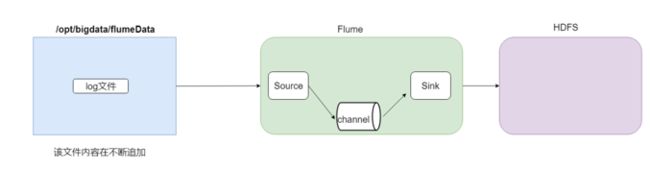
采集指定文件新增内容到HDFS
此案例为了方便观察采集结果,设置的采集频率都比较高,实际应用中频率不应该这么高
需求分析:
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs
根据需求,首先定义以下3大要素
- 采集源,即source——监控文件内容更新 : exec ‘tail -F file’
- 下沉目标,即sink——HDFS文件系统 : hdfs sink
- Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
flume的配置文件
cd /test/apache-flume-1.6.0-cdh5.14.2-bin/conf
vim tail-file.conf
agent
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
source
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F /test/taillogs/access_log
agent1.sources.source1.channels = channel1
注意:
- 使用exec + tail -F 会在flume宕机时才生脏数据问题。
- 脏数据:会在flume重启之后,将之前采集过的数据再采集一遍
- 一般使用
tailDirSource断点续传采集数据
channel
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
## 添加或删除一个event的等待超时时间
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
- keep-alive
- 这个参数用来控制channel满时影响source的发送,channel空时影响sink的消费,就是等待时间,默认是3s,超过这个时间就甩异常,一般不需配置,但是有些情况很有用,比如你得场景是每分钟开头集中发一次数据,这时每分钟的开头量可能比较大,后面会越来越小,这时你可以调大这个参数,不至于出现channel满了得情况
sink
# Describe sink1
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
agent1.sinks.sink1.hdfs.path = hdfs://node01:8020/weblog/flume-collection/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
## 同时允许最大打开文件的数量,超出指定数量会关闭最老的打开的文件
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
agent1.sinks.sink1.hdfs.round = true
agent1.sinks.sink1.hdfs.roundValue = 10
agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
整合后
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure tail -F source1
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F /test/taillogs/access_log
agent1.sources.source1.channels = channel1
#configure host for source
#agent1.sources.source1.interceptors = i1
#agent1.sources.source1.interceptors.i1.type = host
#agent1.sources.source1.interceptors.i1.hostHeader = hostname
# Describe sink1
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
agent1.sinks.sink1.hdfs.path = hdfs://node01:8020/weblog/flume-collection/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
agent1.sinks.sink1.hdfs.round = true
agent1.sinks.sink1.hdfs.roundValue = 10
agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
官网地址
官网地址