提高生产力,最全 MyBatis Plus 讲解!
如果你每天还在重复写 CRUD 的 SQL,如果你对这些 SQL 已经不耐烦了,那么你何不花费一些时间来阅读这篇文章,然后对已有的老项目进行改造,必有收获!
一、MP 是什么
MP 全称 Mybatis-Plus ,套用官方的解释便是成为 MyBatis 最好的搭档,简称基友。它是在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
三大特性
-
润物无声
只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑。 -
效率至上
只需简单配置,即可快速进行单表 CRUD 操作,从而节省大量时间。 -
丰富功能
代码生成、物理分页、性能分析等功能一应俱全。
支持数据库
mysql 、mariadb 、oracle 、db2 、h2 、hsql 、sqlite 、postgresql 、sqlserver 、presto 、Gauss 、Firebird Phoenix 、clickhouse 、Sybase ASE 、 OceanBase 、达梦数据库 、虚谷数据库 、人大金仓数据库 、南大通用数据库
框架结构
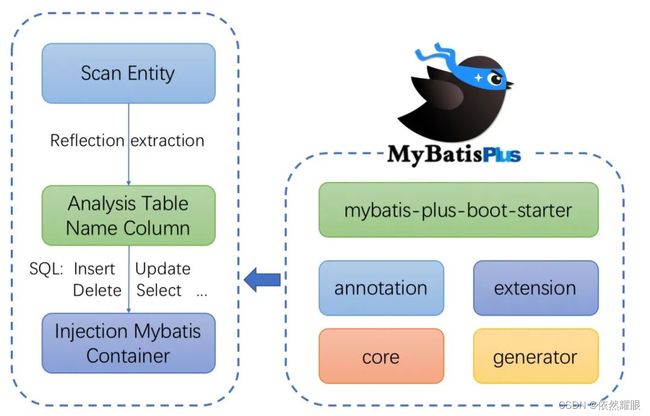
实话说,以上这些内容只要你打开官网也能看到,那么我们接下来就先来实际操作一番!
二、MP实战
手摸手式项目练习
1. 数据库及表准备
sql 语句:
use test;
CREATE TABLE `student` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`dept_id` int(0) NULL DEFAULT NULL,
`name` varchar(16) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL,
`remark` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, 1, '小A', '好好学习,天天向上!');
INSERT INTO `student` VALUES (2, 2, '小B', '好好学习,天天向上!');
2. pom 依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.16.16version>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.2.0version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.21version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.2.1version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13.1version>
dependency>
3. List item
配置文件
spring:
datasource:
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
4. 实体类
@Data
@Builder
@TableName("student")
public class User {
@TableId(type = IdType.AUTO)
private Integer id;
private Integer deptId;
private String name;
private String remark;
}
5. Mapper
public interface UserMapper extends BaseMapper<User> {}
6. 测试类
@RunWith(SpringRunner.class)
@SpringBootTest
public class MapperTest {
@Autowired
private UserMapper userMapper;
@Test
public void getAll() {
List<User> users = userMapper.selectList(null);
users.forEach(System.out::println);
}
}
/** OUTPUT:
User(id=1, deptId=1, name=小A, remark=好好学习,天天向上!)
User(id=2, deptId=1, name=小B, remark=好好学习,天天向上!)
**/
总结:
在以上的结果,我们可以看到已经打印出了数据库中的全部数据(两条)。而并没有看到平时我们需要写的 mapper.xml 文件,只是用到了 usermapper 中的 selectList() 方法,而 UserMapper 继承了 BaseMapper 这个接口,这个接口便是 MybatisPlus 提供给我们的,我们再来看下这个接口给我们提供了哪些方法。
CRUD 基操
1. insert
@Test
public void insert() {
//这里使用了 lombok 中的建造者模式构建对象
User user = User.builder().deptId(1).name("小华").remark("小华爱学习").build();
int insertFlag = userMapper.insert(user);
log.info("插入影响行数,{} | 小华的ID: {}", insertFlag, user.getId());
}
/** OUTPUT:
插入影响行数,1 | 小华的ID: 8
**/
可以看到我们不仅插入了数据,而且还获取到了插入数据的ID,但是值得注意的是这里的 ID 虽然是自增的,但并非是 MP 默认的 ID生成策略,而是我们在实体类中指定的:
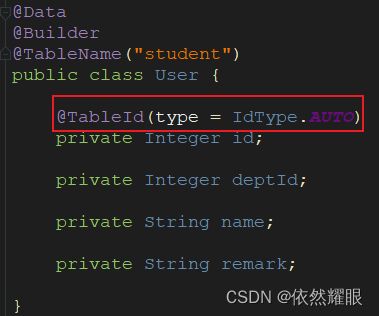
在 MP 中支持的主键生成策略有以下几种:
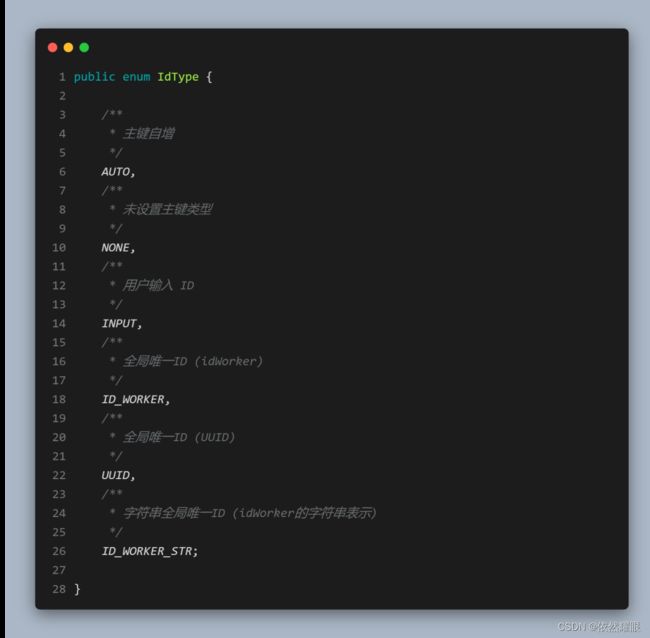
我们既然已经看到了 @TableId 这个注解,那我们再来关注一个常用注解 @TableField
从注解名上我们就可以看出,@TableId 是用来标记主键 ID 的,而 @TableField 是用来标记其他字段的。

可以看得出来这个注解中存在的值还是比较多的,下面介绍几个常用的值:
- value
用于解决字段名不一致问题和驼峰命名,比如实体类中属性名为 remark,但是表中的字段名为 describe ,这个时候就可以使用 @TableField(value=“describe”) 来进行转换。驼峰转换如果在全局中有配置驼峰命名,这个地方可不写。
- exist
用于在数据表中不存在的字段,我们可以使用 @TableField(exist = false) 来进行标记
- condition
用在预处理 WHERE 实体条件自定义运算规则,比如我配置了 @TableField(condition = SqlCondition.LIKE),输出 SQL 为:select 表 where name LIKE CONCAT(‘%’,值,‘%’),其中 SqlCondition 值如下:

- update
用在预处理 set 字段自定义注入,比如我配置了 @TableField(update = “%s+1”),其中 %s 会填充字段,输出 SQL 为:update 表名 set 字段 = 字段+1 where 条件
- select
用于是否查询时约束,如果我们有个字段 remark 是 text 类型的,查询的时候不想查询该字段,那么就可以使用 @TableField(select = false) 来约束查询的时候不查询该字段
2. update
MybatisPlus 的更新操作存在两种:
int updateById(Param("et") T entity);
int update(@Param("et") T entity, @Param("ew") Wrapper<T> updateWrapper);
根据 ID 更新
@Test
public void update() {
User user = User.builder().id(3).name("小华").remark("小华爱玩游戏").build();
userMapper.updateById(user);
}
/** 更新结果:
User(id=3, deptId=1, name=小华, remark=小华爱玩游戏)
**/
根据条件更新
@Test
public void update() {
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("name","小华").set("remark","小华爱下棋");
userMapper.update(null, updateWrapper);
}
/** 更新结果:
User(id=3, deptId=1, name=小华, remark=小华爱下棋)
**/
我们也可以将要更新的条件放进 user 对象 里面:
@Test
public void update() {
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("name","小华");
User user = User.builder().remark("小华爱游泳").build();
userMapper.update(user, updateWrapper);
}
/** 更新结果:
User(id=3, deptId=1, name=小华, remark=小华爱游泳)
**/
3. delete
在 MybatisPlus 中删除的方式相对于更新多,总共有四种:
int deleteById(Serializable id);
int deleteByMap(@Param("cm") Map<String, Object> columnMap);
int delete(@Param("ew") Wrapper<T> wrapper);
int deleteBatchIds(@Param("coll") Collection<? extends Serializable> idList);
根据 ID 删除
@Test
public void deleteById() {
userMapper.deleteById(3);
}
/** SQL语句:
DELETE FROM student WHERE id = 3;
**/
根据 Map 删除
@Test
public void deleteByMap() {
HashMap<String, Object> columnMap = new HashMap<>();
columnMap.put("name","小华");
columnMap.put("remark","小华爱游泳");
userMapper.deleteByMap(columnMap);
}
/** SQL语句:
DELETE FROM student WHRE name = '小华' AND remark = '小华爱游泳';
**/
根据 Wrapper 删除
@Test
public void delete() {
UpdateWrapper<User> wrapper = new UpdateWrapper<>();
wrapper.eq("remark","小华爱下棋");
userMapper.delete(wrapper);
}
/** SQL语句:
DELETE FROM student WHRE remark = '小华爱下棋';
**/
根据 Wrapper 删除还有另外一种方式,直接将实体类放入 Wrapper 中包装:
@Test
public void delete() {
User user = User.builder().remark("小华爱下棋").build();
UpdateWrapper<User> wrapper = new UpdateWrapper<>(user);
userMapper.delete(wrapper);
}
/** SQL语句:
DELETE FROM student WHRE remark = '小华爱下棋';
**/
根据 ID 批量删除
@Test
public void deleteBatchIds() {
List<Integer> idList = new ArrayList<>();
idList.add(4);
idList.add(7);
userMapper.deleteBatchIds(idList);
}
/** SQL语句:
DELETE FROM student WHERE id In (4,7)
**/
4. select
查询操作在我们开发中是最经常用到的,也是重中之重。MybatisPlus 中支持查询的方法也比较多,如下:
T selectById(Serializable id);
List<T> selectBatchIds(@Param("coll") Collection<? extends Serializable> idList);
List<T> selectByMap(@Param("cm") Map<String, Object> columnMap);
T selectOne(@Param("ew") Wrapper<T> queryWrapper);
Integer selectCount(@Param("ew") Wrapper<T> queryWrapper);
List<T> selectList(@Param("ew") Wrapper<T> queryWrapper);
List<Map<String, Object>> selectMaps(@Param("ew") Wrapper<T> queryWrapper);
List<Object> selectObjs(@aram("ew") Wrapper<T> queryWrapper);
IPage<T> selectPage(IPage<T> page, @Param("ew") Wrapper<T> queryWrapper);
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, @Param("ew") Wrapper<T> queryWrapper);
可以看到总共有 10 个方法,我们接下来一个一个测试
查询所有
@Test
public void selectList() {
List<User> users = userMapper.selectList(null);
users.forEach(System.out::println);
}
/**
OUTPUT:
User(id=1, deptId=1, name=小A, remark=好好学习,天天向上!)
User(id=2, deptId=1, name=小B, remark=好好学习,天天向上!)
SQL语句:
SELECT id, dept_id, name, remark FROM student;
**/
查询数量
@Test
public void selectCount() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.like("name","小");
System.out.println(userMapper.selectCount(queryWrapper));
}
/**
OUTPUT:
2
SQL语句:
SELECT COUNT( 1 ) FROM student WHERE (name LIKE '%小%');
**/
根据 ID 查询
@Test
public void selectById() {
User user = userMapper.selectById(1);
System.out.println(user);
}
/**
OUTPUT:
User(id=1, deptId=1, name=小A, remark=好好学习,天天向上!)
SQL语句:
SELECT id, dept_id, name, remark FROM student WHERE ID = 1;
**/
根据 ID 批量查询
@Test
public void selectBatchIds() {
List<User> users = userMapper.selectBatchIds(Arrays.asList(1, 2));
users.forEach(System.out::println);
}
/**
OUTPUT:
User(id=1, deptId=1, name=小A, remark=好好学习,天天向上!)
User(id=2, deptId=1, name=小B, remark=好好学习,天天向上!)
SQL语句:
SELECT id, dept_id, name, remark FROM student WHERE ID IN (1, 2);
**/
根据条件查询单条
@Test
public void selectOne() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("name","小A");
User user = userMapper.selectOne(queryWrapper);
System.out.println(user);
}
/**
OUTPUT:
User(id=1, deptId=1, name=小A, remark=好好学习,天天向上!)
SQL语句:
SELECT id, name, dept_id, remark FROM student WHERE (name = '小A');
**/
根据条件查询多条
通过 map 传递参数,不是通过 LIKE 查询,而是通过 = 查询
@Test
public void selectByMap() {
HashMap<String, Object> columnMap = new HashMap<>();
columnMap.put("name","小");
List<User> users = userMapper.selectByMap(columnMap);
users.forEach(System.out::println);
}
/**
OUTPUT:
null
SQL语句:
SELECT id, name, dept_id, remark FROM student WHERE name = '小';
**/
如果我们没有新建实体类进行结果封装,我们还可以用 Map 来接收结果集:
@Test
public void selectMaps() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.like("name","小");
List<Map<String, Object>> maps = userMapper.selectMaps(queryWrapper);
maps.forEach(System.out::println);
}
/**
OUTPUT:
{name=小A, remark=好好学习,天天向上!, id=1, dept_id=1}
{name=小B, remark=好好学习,天天向上!, id=2, dept_id=1}
SQL语句:
SELECT id, name, dept_id, remark FROM student WHERE (name LIKE '%小%');
**/
也可以用 Object 对象来接收结果集:
@Test
public void selectObjs() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.like("name", "小");
List<Object> objects = userMapper.selectObjs(queryWrapper);
}
/**
OUTPUT:
{name=小A, remark=好好学习,天天向上!, id=1, dept_id=1}
{name=小B, remark=好好学习,天天向上!, id=2, dept_id=1}
SQL语句:
SELECT id, name, dept_id, remark FROM student WHERE (name LIKE '%小%');
**/
分页查询
@Test
public void selectPage() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.like("name", "小");
Page<User> page = new Page<>(1, 1);
IPage<User> userIPage = userMapper.selectPage(page, queryWrapper);
System.out.println("数据总数:" + userIPage.getTotal());
System.out.println("总页数:" + userIPage.getPages());
System.out.println("当前页:" + userIPage.getCurrent());
System.out.println("页大小:" + userIPage.getSize());
userIPage.getRecords().forEach(System.out::println);
}
/**
OUTPUT:
数据总数:2
总页数:2
当前页:1
页大小:1
User(id=1, deptId=1, name=小明, remark=好好学习,天天向上!)
SQL语句:
SELECT id, name, dept_id, remark
FROM student
WHERE (name LIKE '%小%')
LIMIT 0,1;
**/
条件构造器

在 CRUD 的基本操作中,我们想要通过条件查询都是通过 Wrapper 类进行封装的,上面只是简单的用到 eq 和 like 操作。事实上这个类十分强大,我们在下面会详细进行介绍。
1. allEq
全部 eq 或个别 isNull
allEq(Map<R, V> params)
allEq(Map<R, V> params, boolean null2IsNull)
allEq(boolean condition, Map<R, V> params, boolean null2IsNull)
allEq(BiPredicate<R, V> filter, Map<R, V> params)
allEq(BiPredicate<R, V> filter, Map<R, V> params, boolean null2IsNull)
allEq(boolean condition, BiPredicate<R, V> filter, Map<R, V> params, boolean null2IsNull)
参数说明:
param: key 为数据库字段名,value 为字段值
**nullsIsNull:**为 true 则在 map 的 value 为 null 时调用 isNull 方法,为 false 时则忽略 value 为 null 时不调用 isNull 方法
filter: 过滤函数,判断是否允许字段传入比对条件中
使用示例:
- allEq(Map
@Test
public void testAllEq() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
Map<String,Object> params = new HashMap<>();
params.put("name","小明");
params.put("dept_id",1);
params.put("remark",null);
queryWrapper.allEq(params); //会调用 isNull 方法
userMapper.selectList(queryWrapper);
}
/**
结果:
{}
SQL语句:
SELECT id,name,dept_id,remark
FROM student
WHERE (name = '小明' AND dept_id = 1 AND remark IS NULL);
**/
- allEq(Map
@Test
public void testAllEq() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
Map<String,Object> params = new HashMap<>();
params.put("name","小明");
params.put("dept_id",1);
params.put("remark",null);
queryWrapper.allEq(params, false); //不会调用 isNull 方法
userMapper.selectList(queryWrapper);
}
/**
结果:
User(id=1, deptId=1, name=小明, remark=好好学习,天天向上!)
SQL语句:
SELECT id,name,dept_id,remark
FROM student
WHERE (name = '小明' AND dept_id = 1);
**/
- allEq(boolean condition, Map
@Test
public void testAllEq() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
Map<String,Object> params = new HashMap<>();
params.put("name","小明");
params.put("dept_id",1);
params.put("remark",null);
queryWrapper.allEq(false,params,false); //不会带入条件进行查询
userMapper.selectList(queryWrapper);
}
/**
结果:
{name=小A, remark=好好学习,天天向上!, id=1, dept_id=1}
{name=小B, remark=好好学习,天天向上!, id=2, dept_id=1}
SQL语句:
SELECT id,name,dept_id,remark
FROM student;
**/
- allEq(BiPredicate
@Test
public void testAllEq() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
Map<String, Object> params = new HashMap<>();
params.put("name", "小明");
params.put("dept_id", 1);
params.put("remark", null);
//只有 key 中含有 “m” 才会用作条件判断
queryWrapper.allEq((k, v) -> (k.contains("m")), params);
userMapper.selectList(queryWrapper);
}
/**
结果:
0
SQL语句:
SELECT id,name,dept_id,remark
FROM student
WHERE (name = '小明' AND remark IS NULL);
**/
2. 比较操作
- eq: 相当于 =
- ne: 相当于 !=
- gt: 相当于 >
- ge: 相当于 >=
- lt: 相当于 <
- le: 相当于 <=
- between: 相当于 between … and …
- notBetween: 相当于 not between … and …
- in: 相当于 in(…, …, …)
- notIn: 相当于 not in(…, …, …)
3. 模糊查询
- like: l
ike("name","小明") --> name like "%小明%" - notLike:
notLike("name","小明") --> name not like "%小菜小明" - likeLeft:
like("name","小明") --> name like "%小明" - likeRight:
like("name","小明") --> name like "小明%"
4. 排序
- orderBy:
orderBy(boolean condition, boolean isAsc, R... columns)
orderBy(true, true, "id", "name") --> order by id ASC, name ASC
- orderByAsc:
orderByAsc("id","name") --> order by id ASC, name ASC
- orderByDesc:
orderByDesc("id","name) --> order by id Desc, name Desc
5. 逻辑查询
- or:
拼接:主动调用 or 表示紧接着下一个方法不是用 and 连接!(不调用 or 则默认为使用 and 连接), eq("id",1).or().eq("name","老王")
嵌套:or(i -> i.eq("name", "李白").ne("status", "活着"))
- and:
嵌套:and(i -> i.eq("name", "李白").ne("status", "活着"))
6. select
在MP查询中,默认查询所有的字段,如果有需要也可以通过select方法进行指定字段,如select("id", "name")
配置讲解
1. 基本配置
- configLocation
用于指明 **MyBatis ** 配置文件的位置,如果我们有 MyBatis 的配置文件,需将配置文件的路径配置到 configLocation 中
SpringBoot:
mybatis-plus.config-location = classpath:mybatis-config.xml
SpringMvc:
<bean id="sqlSessionFactory"
class="com.baomidou.mybatisplus.extension.spring.MybatisSqlSessionFactoryBean">
<property name="configLocation" value="classpath:mybatis-config.xml"/>
- mapperLocations
用于指明 Mapper 所对应的 XML 的文件位置,我们在 通用 CRUD 中用到的 Mapper 是直接继承 MP 提供的 BaseMapper ,我们也可以自定义方法,然后在 XML 文件中自定义 SQL,而这时我们需要告诉 Mapper 所对应 XML 文件的位置
SpringBoot:
mybatis-plus.mapper-locations = classpath*:mybatis/*.xml
SpringMVC:
<bean id="sqlSessionFactory"
class="com.baomidou.mybatisplus.extension.spring.MybatisSqlSessionFactoryBean">
<property name="mapperLocations" value="classpath*:mybatis/*.xml"/>
bean>
- typeAliasesPackage
用于 MyBatis 别名包扫描路径,通过该属性可以给包中的类注册别名,注册后在 Mapper 对应的 XML 文件中可以直接使用类名,而不用使用全限定的类名
SpringBoot:
mybatis-plus.type-aliases-package = cbuc.life.bean
SpringMVC:
<bean id="sqlSessionFactory"
class="com.baomidou.mybatisplus.extension.spring.MybatisSqlSessionFactoryBean">
<property name="typeAliasesPackage"
value="com.baomidou.mybatisplus.samples.quickstart.entity"/>
bean>
2. 进阶配置
- mapUnderScoreToCamelCase
是否开启自动驼峰命名规则映射,这个配置的默认值是 true,但是这个属性在 MyBatis 中的默认值是 false,所以在我们平时的开发中都会将这个配置开启。
#关闭自动驼峰映射,该参数不能和mybatis-plus.config-location同时存在
mybatis-plus.configuration.map-underscore-to-camel-case = false
- cacheEnabled
全局地开启或关闭配置文件中的所有映射器已经配置的任何缓存,默认为 true。
mybatis-plus.configuration.cache-enabled = false
3. DB 策略配置
- idType
全局默认主键类型,设置后,即可省略实体对象中的@TableId(type = IdType.AUTO)配置。该配置的默认值为 ID_WORKER
SpringBoot:
mybatis-plus.global-config.db-config.id-type = auto
SpringMVC:
<bean id="sqlSessionFactory"
class="com.baomidou.mybatisplus.extension.spring.MybatisSqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="globalConfig">
<bean class="com.baomidou.mybatisplus.core.config.GlobalConfig">
<property name="dbConfig">
<bean class="com.baomidou.mybatisplus.core.config.GlobalConfig$DbConfig">
<property name="idType" value="AUTO"/>
bean>
property>
bean>
property>
bean>
- tablePrefix
表名前缀,全局配置后可省略@TableName()配置。该配置的默认值为 null
SpringBoot:
mybatis-plus.global-config.db-config.table-prefix = yq_
SpringMVC:
<bean id="sqlSessionFactory"
class="com.baomidou.mybatisplus.extension.spring.MybatisSqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="globalConfig">
<bean class="com.baomidou.mybatisplus.core.config.GlobalConfig">
<property name="dbConfig">
<bean class="com.baomidou.mybatisplus.core.config.GlobalConfig$DbConfig">
<property name="idType" value="AUTO"/>
<property name="tablePrefix" value="yq_"/>
bean>
property>
bean>
property>
bean>
其他扩展
1. 自动填充
有时候我们在插入或更新数据的时候,希望有些字段可以自动填充。比如我们平时数据表里面会有个 插入时间 或者 更新时间 这种字段,我们会默认以当前时间填充,在 MP 中我们也可以进行配置。
首先我们需要借助 @TableField(fill = FieldFill.INSERT) 这个注解,在插入时进行填充。
@TableField(fill = FieldFill.INSERT)
private String remark;
其中自动填充的模式如下:
public enum FieldFill {
/**
* 默认不处理
*/
DEFAULT,
/**
* 插入时填充字段
*/
INSERT,
/**
* 更新时填充字段
*/
UPDATE,
/**
* 插入和更新时填充字段
*/
INSERT_UPDATE
}
然后我们再编写自定义的填充处理模式:
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
Object remark = getFieldValByName("remark", metaObject);
if (null == remark) {
setFieldValByName("remark", "好好学习", metaObject);
}
}
@Override
public void updateFill(MetaObject metaObject) {
//自定义更新时填充
}
}
测试:
@Test
public void testObjectHandler() {
User user = User.builder().deptId(1).name("小明").build();
userMapper.insert(user);
}
/**
SQL语句:
INSERT INTO student ( name, dept_id, remark )
VALUES ( '小明', 1, '好好学习' );
**/
可以看到插入时,已经自动将我们填充的字段合并进去。
2. 逻辑删除
在开发中,很多时候我们删除数据并不需要真正意义上的物理删除,而是使用逻辑删除,这样子查询的时候需要状态条件,确保被标记的数据不被查询到。MP 当然也支持这样的功能。
我们需要先为 student 表添加一个字段 status 来声明数据是否被删除,0 表示被删除,1表示未删除,然后也需要在实体类上增加这个属性:
@TableLogic
private Integer status;
在 application.yaml 中配置:
mybatis-plus:
global-config:
db-config:
logic-delete-value: 0
logic-not-delete-value: 1
测试:
@Test
public void testLogicDelete() {
userMapper.deleteById(1);
}
/**
SQL语句:
UPDATE student SET status=0
WHERE id=1 AND status=1;
**/
可以看出这段 SQL 并没有真正删除,而是进行了逻辑删除,只是更新了删除标识
3. 通用枚举
如果有性别之类的字段,我们通常会用 0 和 1 来表示,但是查出来我们得进行值转换,这个时候我们就可以使用枚举来解决这个问题:
首先为 student 表添加一个 sex 字段来表示性别,0 表示女性,1 表示男性,然后定义一个枚举类:
public enum SexEnum implements IEnum<Integer> {
MAN(1, "男"),
WOMEN(0, "女");
private int code;
private String value;
SexEnum(int code, String value) {
this.code = code;
this.value = value;
}
@Override
public Integer getValue() {
return this.code;
}
//注意要重写此方法,不然会将值转换成 ‘MAN’,而不是 ‘男’
@Override
public String toString() {
return this.value;
}
}
然后在实体类中添加对应属性:
private SexEnum sex;
在 application.yaml 中配置:
mybatis-plus:
type-enums-package: cbuc.life.enums
测试:
@Test
public void selectOne() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("name", "小明");
User user = userMapper.selectOne(queryWrapper);
System.out.println(user);
}
/**
输出结果:
User(id=1, deptId=1, name=小明, remark=好好学习天天向上!, status=1, sex=男)
SQL语句:
SELECT id,sex,name,dept_id,remark,status
FROM student
WHERE status=1 AND (name = '小明');
**/
END
这篇文章写到这里就告一段落了哦,内容有点长,不过如果能完整看下来,我相信你肯定能够很好的使用 MybatisPlus 啦!