(99+条未读通知) 牛客题霸_经典高频编程题库_面试备战无压力_牛客网 (nowcoder.com)
(99+条未读通知) yub4by的个人主页_牛客网 (nowcoder.com)
1、牛客OJ-SQL篇-非技术快速入门

# 方式1:使用distinct关键字去重
select distinct university from user_profile
# 方式2:借助分组实现去重
SELECT university FROM user_profile GROUP BY university

SELECT device_id FROM user_profile WHERE id IN(1,2);
SELECT device_id from user_profile where id='1' or id='2';
SELECT device_id from user_profile LIMIT 0,2;
SELECT device_id from user_profile LIMIT 2;

SELECT device_id user_infors_example from user_profile LIMIT 2;
SELECT device_id as user_infors_example from user_profile LIMIT 0,2;
# as可以省略,0可以省略,as关键字用于起别名
# 分页查询,limit 2等同于limit 0,2 表示从第0条记录后开始选取,限制选取2条(即第一第二条记录)
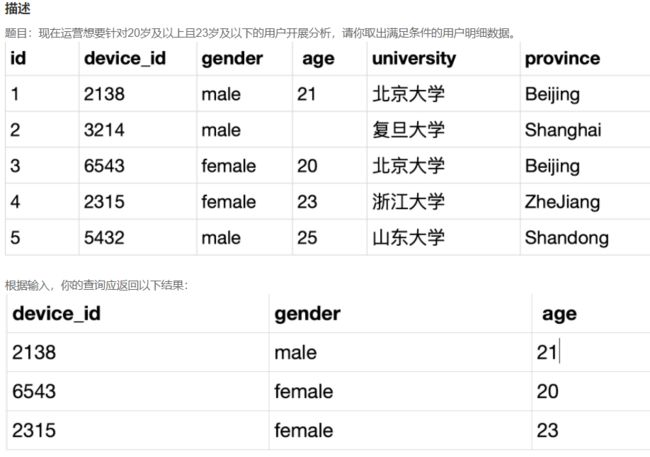
SELECT device_id,gender,age FROM user_profile WHERE age BETWEEN 20 and 23;
SELECT device_id,gender,age FROM user_profile WHERE age>=20 and age<=23;
SELECT device_id,gender,age FROM user_profile WHERE age IN(20,21,22,23);

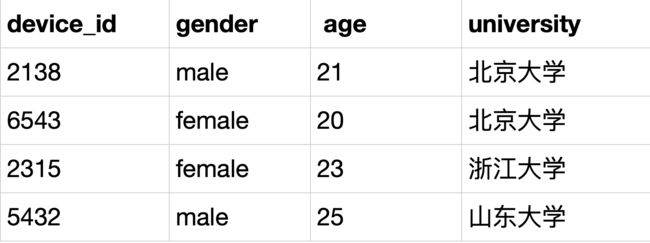
select device_id,gender,age,university FROM user_profile WHERE university!="复旦大学";
select device_id,gender,age,university FROM user_profile WHERE university not in("复旦大学");
# 延伸:子查询(实际此题没必要,直接用上述两个方法就行,在此只是讲一下子查询简单用法)
select device_id,gender,age,university
FROM user_profile
WHERE university not in(select university
from user_profile
WHERE university="复旦大学");
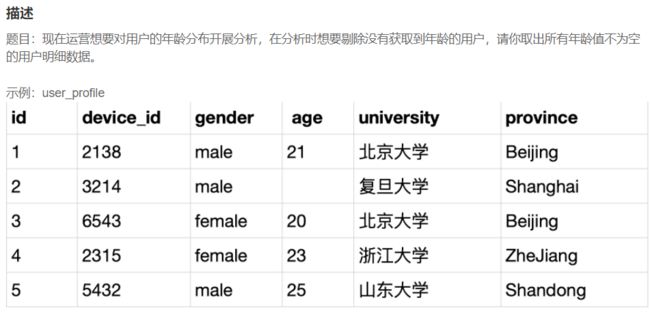
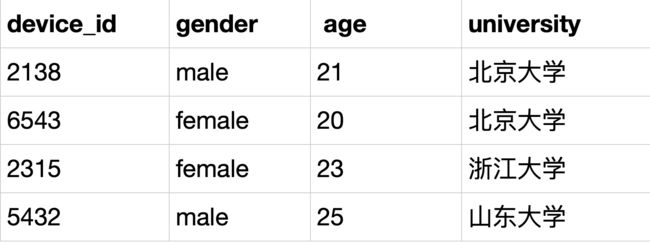
SELECT device_id,gender,age,university FROM user_profile WHERE age is not null;
SELECT device_id,gender,age,university FROM user_profile WHERE age!="";
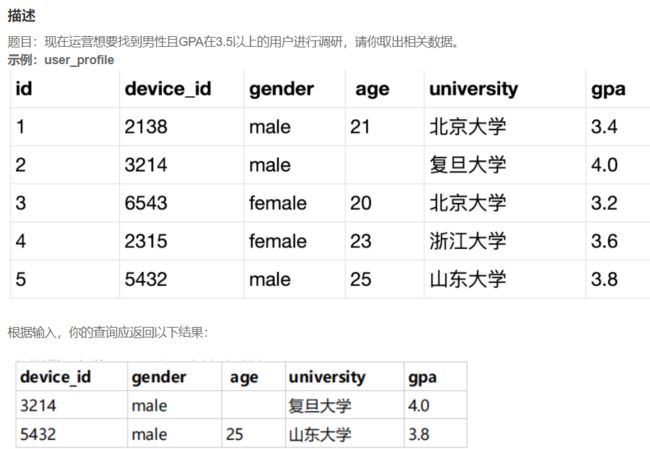
SELECT device_id,gender,age,university,gpa
FROM user_profile
WHERE gender='male' and gpa>3.5;
SELECT device_id,gender,age,university,gpa
FROM user_profile
WHERE gender in('male') and gpa>3.5;

SELECT device_id,gender,age,university,gpa
FROM user_profile
WHERE university in('北京大学','复旦大学','山东大学');
SELECT device_id,gender,age,university,gpa
FROM user_profile
WHERE university='北京大学' or university='复旦大学' or university='山东大学';

SELECT device_id,gender,age,university,gpa
FROM user_profile
WHERE
(gpa>3.5 and university='山东大学')
or
(gpa>3.8 and university='复旦大学')
;
# 实际上and的优先级大于or,可以省略(),但建议写上,可读性强
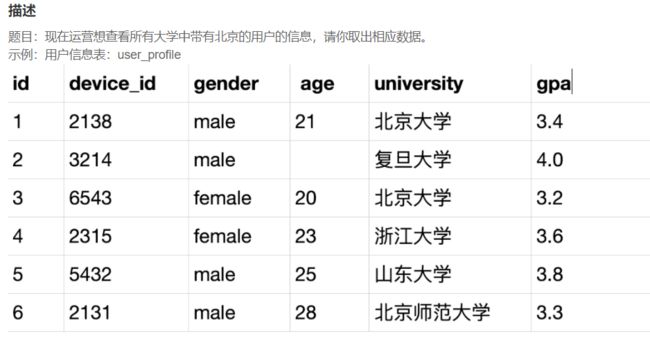
SELECT device_id,age,university
FROM user_profile
WHERE university LIKE "%北京%";
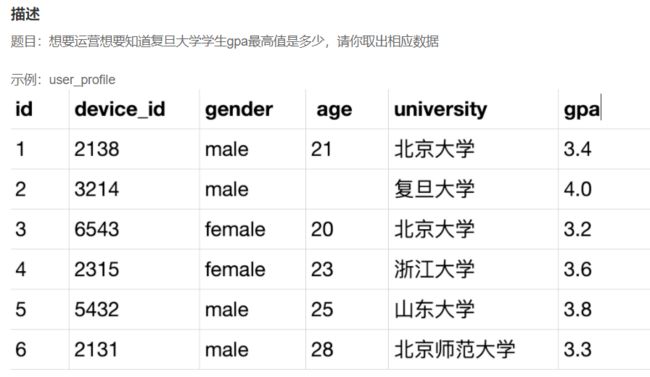
# 方法一
SELECT MAX(gpa)
FROM user_profile
WHERE university='复旦大学';
# 方法2
SELECT gpa
FROM user_profile
WHERE university='复旦大学'
ORDER BY gpa
LIMIT 1; -- 0,1


SELECT COUNT(gender) as male_num, ROUND(AVG(gpa),1) as avg_gpa
FROM user_profile
WHERE gender='male'GROUP BY gender;
# 此题要注意的是暗含条件,平均值保留一位小数
# 使用ROUND()函数,保留一位小数,四舍五入
# 使用COUNT()等聚合函数时必分组GROUP BY
# AVG()求平均值
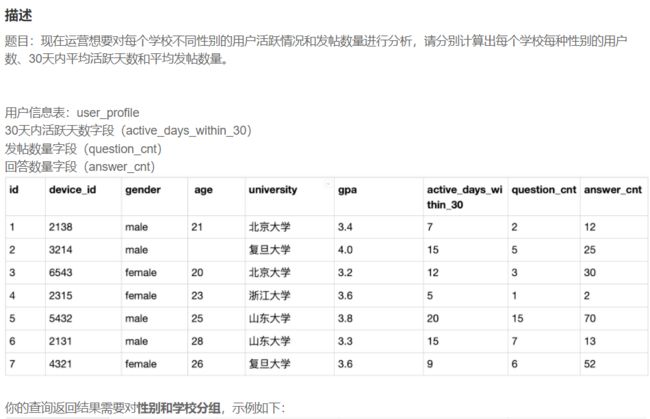

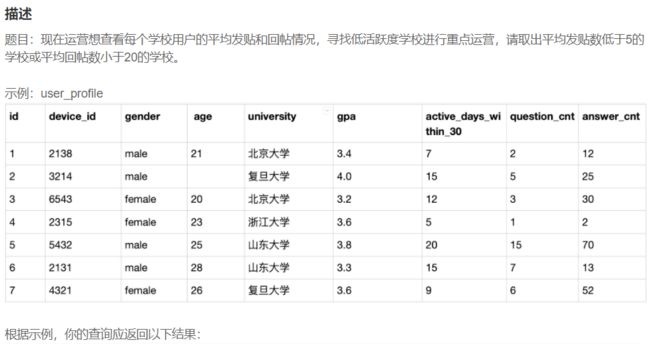
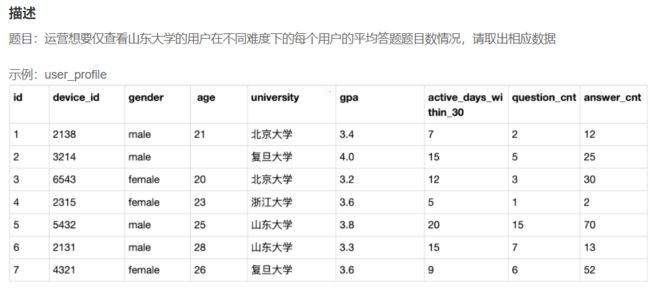
# 审题:请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量
# 1.找出分组条件每个学校的每种性别
# 2.确定要什么
# 2.1 用户数(id) count()
# 2.2 30天内平均活跃active_days_within_30 avg()
# 2.3 平均发帖数量question_cnt avg()
# group by 根据多个条件分组,如本题,University写在gender 之前即可,其他就是count函数和avg函数的用法
SELECT
gender,university,
COUNT(id) as user_num,
avg(active_days_within_30) as avg_active_day,
avg(question_cnt) as avg_question
FROM user_profile
GROUP BY university,gender;

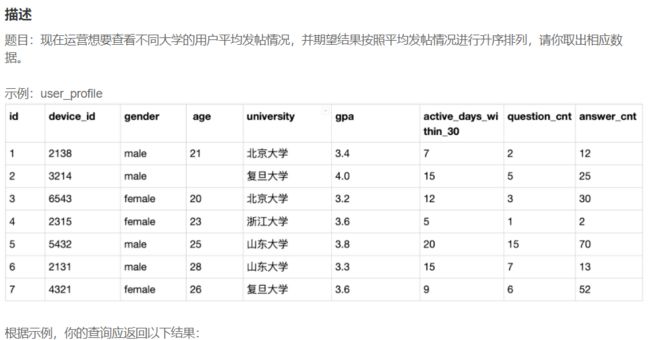
# 方式1(子查询-复杂方式)
SELECT sp.university,sp.avg_question_cnt,sp.avg_answer_cnt
FROM (
select university,avg(question_cnt) as avg_question_cnt,avg(answer_cnt) as avg_answer_cnt
from user_profile
GROUP BY university) sp
where sp.avg_question_cnt<5 or sp.avg_answer_cnt<20;
# 1.首先用到的是 avg()求平均值
# 2.起一个别名
# 3.做判断
# 3.1用having 比较
# 3.2用子查询在用where
# 方式2(较1,推荐方式2)
SELECT university,avg(question_cnt) as avg_question_cnt,avg(answer_cnt) as avg_answer_cnt
FROM user_profile
GROUP BY university
HAVING avg_question_cnt<5 or avg_answer_cnt<20;
# 按照大学进行分组 group by university; 条件having avg(question_cnt)<5 or avg(answer_cnt)<20
# 本题核心是掌握group by
# group by 代表分组查询(此时可以引用表的别名),having是分组后的筛选。avg()是聚合函数,依赖于group by。
# 执行循序为:from-》group by-》having-》select
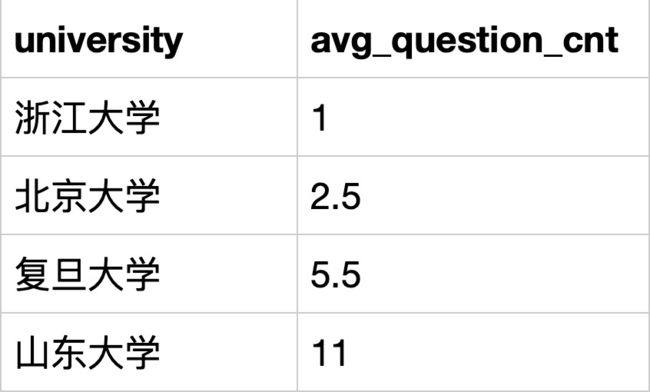
SELECT university,AVG(question_cnt) as avg_question_cnt
FROM user_profile
GROUP BY university
ORDER BY avg_question_cnt ASC;
# 运营想查看不同大学情况,就用大学分组 group by university
# 查看用户平均发帖情况,avg( question_cnt)
# 升序排列 group by university order by avg_question_cnt asc
# DESC降序 ASC升序
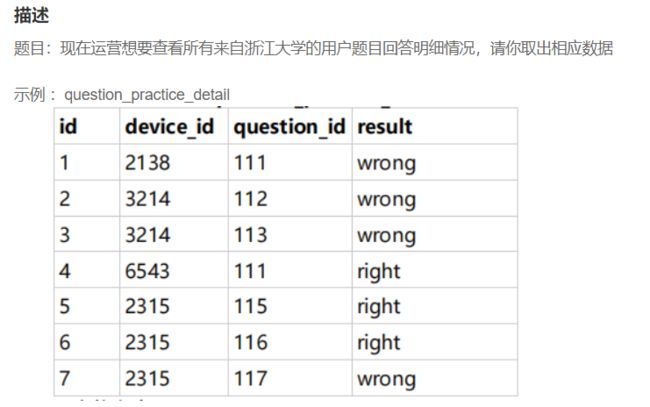
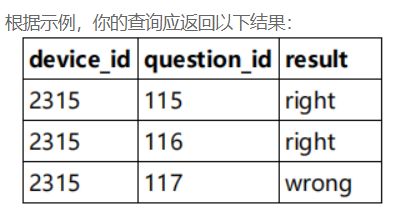
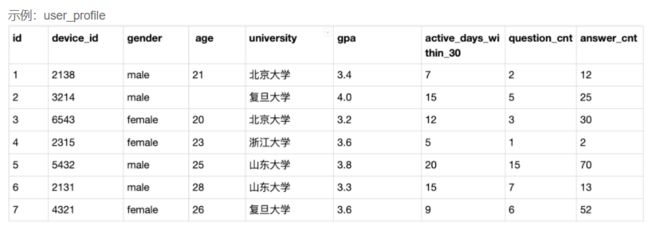
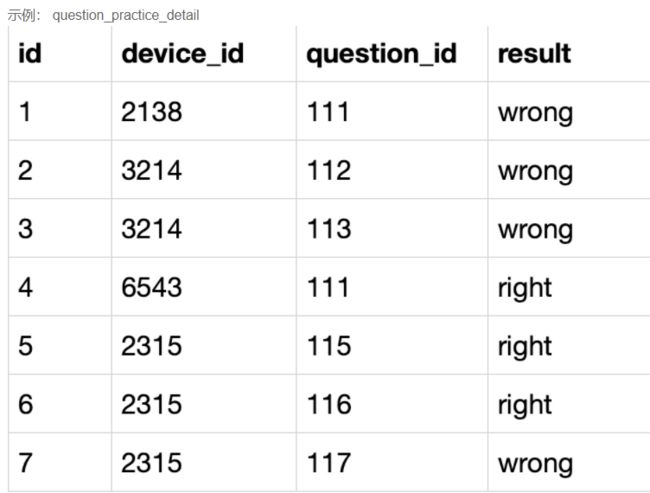
SELECT qpd.device_id,qpd.question_id,qpd.result
FROM question_practice_detail qpd,user_profile
WHERE
user_profile.university='浙江大学'
and
user_profile.device_id=qpd.device_id;
# 参考1(创建一张临时表用,获取浙江大学device_id对用户题目回答明细进行过滤)
SELECT device_id,question_id,result
from question_practice_detail
WHERE device_id=(SELECT device_id
FROM user_profile
WHERE university='浙江大学');
# 参考2(先将两张表关联在一起,然后再筛选出浙江大学的明细数据)
select t1.device_id,t1.question_id,t1.result
from question_practice_detail t1
left JOIN user_profile t2
on t1.device_id = t2.device_id
where university='浙江大学'
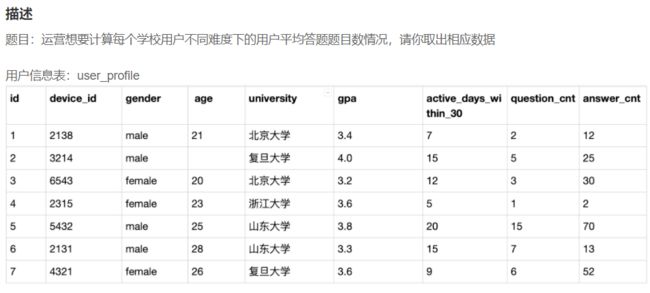


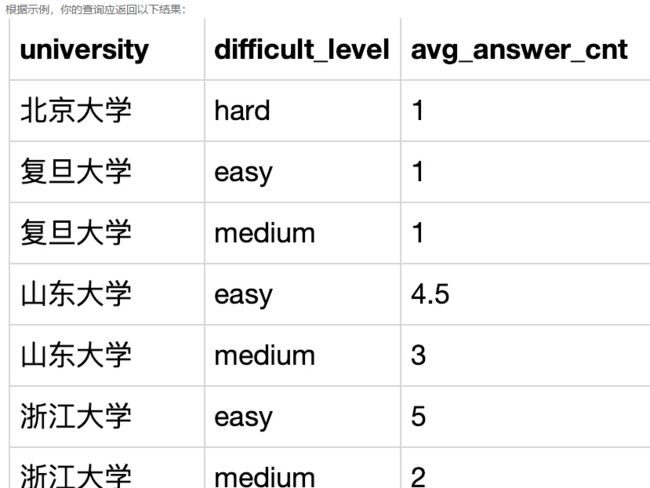
SELECT
t1.university,
t3.difficult_level,
# AVG(t1.answer_cnt) as avg_answer_cnt
COUNT(t2.question_id)/COUNT(distinct(t2.device_id)) as avg_answer_cnt
FROM
user_profile t1,
question_practice_detail t2,
question_detail t3
WHERE
t1.device_id = t2.device_id
and
t2.question_id = t3.question_id
GROUP BY
t1.university,t3.difficult_level;
# 参考SQL22题中的用户平均答题题目数求解方法,这道题自己做出来了
# 其他1:三表联,要求求出每个学校,每个难度的平均做题数 group by university,difficult_level,所以以学校,及难度进行分组,用题数/回答数求出,刷题率
select
u.university,
q1.difficult_level,
count(q.question_id)/count(distinct q.device_id)
from
user_profile u
inner join
question_practice_detail q
on
u.device_id=q.device_id
left join
question_detail q1
on
q1.question_id=q.question_id
group by u.university,q1.difficult_level
# 其他2:详细解析见https://blog.nowcoder.net/n/1b1530bcb5694ef382a837bda02d4f54
SELECT
u.university,
qd.difficult_level,
count(q.question_id)/count(distinct(q.device_id)) AS avg_answer_cnt
FROM
question_practice_detail AS q
LEFT JOIN
user_profile AS u
ON
u.device_id=q.device_id
LEFT JOIN
question_detail AS qd
ON
q.question_id=qd.question_id
GROUP BY u.university, qd.difficult_level;
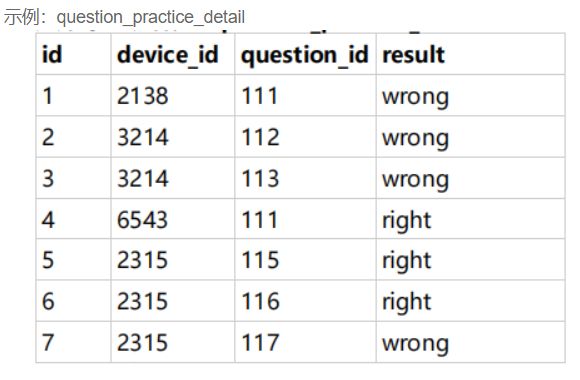


SELECT
t1.university,
t3.difficult_level,
COUNT(t2.question_id) / COUNT(DISTINCT(t2.device_id)) as avg_answer_cnt
from
user_profile as t1,
question_practice_detail as t2,
question_detail as t3
WHERE
t1.university = '山东大学'
and t1.device_id = t2.device_id
and t2.question_id = t3.question_id
GROUP BY
t3.difficult_level;
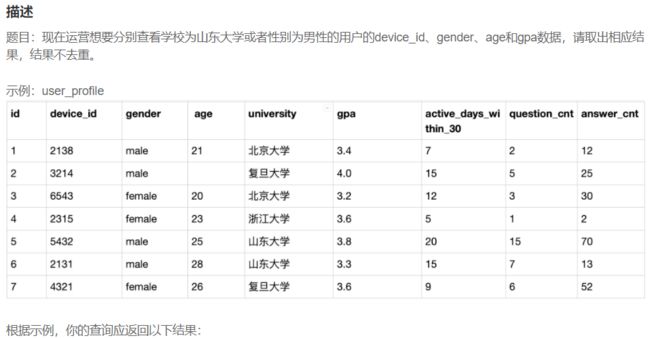

(SELECT device_id,gender,age,gpa
FROM user_profile
WHERE university='山东大学')
UNION ALL
(SELECT device_id,gender,age,gpa
FROM user_profile
WHERE gender="male");
# 结果不去重就用union all,去重就用 union。
# 直接where university='山东大学' or gender="male"的话,也是自动去重的。
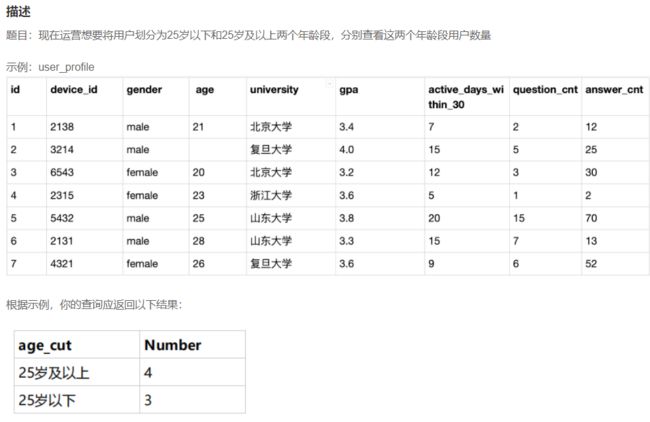
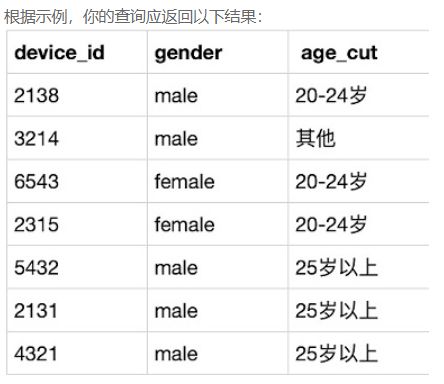
# 参考1:if判断
SELECT
IF(age<25 OR age IS NULL,'25岁以下','25岁及以上') as age_cut,
COUNT(device_id) as Number
FROM user_profile
GROUP BY age_cut;
# 参考2:联合查询
SELECT '25岁以下' as age_cut, COUNT(device_id) as Number
FROM user_profile WHERE age<25 OR age is NULL
UNION
SELECT '25岁及以上' as age_cut, COUNT(device_id) as Number
FROM user_profile WHERE age>=25;

# 参考1
# 考点 case when then
# 当年龄在20-24之间,显示20-24岁
# case when age between 20 and 24 then '20-24岁'
# 大于等于25,显示25岁以上
# when age>=25 then '25岁以上'
# 剩下的数据就是其他
# else '其他' end
# 重点:这里主要考察case when 的用法,勿忘end关键字
SELECT
device_id,gender,
(case when age<20 then '20岁以下'
when age between 20 and 24 then '20-24岁'
when age>=25 then '25岁以上'
else '其他'
end) as age_cut
from user_profile;
# 参考2:多重嵌套if
SELECT
device_id,gender,
if(age<20,'20岁以下',
if(age between 20 and 24,'20-24岁',
if(age>=25,'25岁以上','其他')
)
) as age_cut
from user_profile;


# 参考1
SELECT EXTRACT(DAY from date) as day, COUNT(question_id) as question_cnt
FROM question_practice_detail
WHERE EXTRACT(MONTH from date) = 08
GROUP BY day;
# 参考2
SELECT DAY(date) as day, COUNT(question_id) as question_cnt
FROM question_practice_detail
WHERE YEAR(date) = 2021 and MONTH(date) = 08
GROUP BY day;
# 参考3
select right(date,2) as day,count(question_id) as questionc_cnt
from question_practice_detail
where date like'2021-08%'
group by day

# 此题较难,详解见https://blog.nowcoder.net/n/6c04580282de402fb6d0a43a4cdb0a6d
# 参考1
SELECT
COUNT(res2.device_id) / COUNT(res1.device_id) as avg_ret
FROM
(select DISTINCT device_id,date
from question_practice_detail) as res1
left join
(select DISTINCT device_id, DATE_SUB(date,INTERVAL 1 DAY) as date
from question_practice_detail) as res2
USING(device_id, date);
# USING必须带括号不然报错;using()这一句可以替换为参考2中的on这一句
# 参考2
SELECT
COUNT(res2.device_id) / COUNT(res1.device_id) as avg_ret
FROM
(select DISTINCT device_id,date
from question_practice_detail) as res1
left join
(select DISTINCT device_id, DATE_SUB(date,INTERVAL 1 DAY) as date
from question_practice_detail) as res2
on res1.device_id = res2.device_id and res1.date = res2.date;

# 参考1
select 'male' as gender, COUNT(device_id) as number
FROM user_submit WHERE right(profile,6)<>"female"
UNION all
select 'female' as gender, COUNT(device_id) as number
FROM user_submit where right(profile,6)="female";
# 参考2
SELECT if(profile like '%female','female', 'male') as gender,COUNT(device_id) as number
FROM user_submit GROUP BY gender;
# 参考3(使用SUBSTRING_INDEX函数根据逗号将profile字段切分,性别位于最后一位,位置填写-1即可取出性别字段)
select substring_index(profile,',',-1) as gender,count(*) as number
from user_submit group by gender;
# 1、LOCATE(substr , str ):返回子串 substr 在字符串 str 中第一次出现的位置,如果字符substr在字符串str中不存在,则返回0;
# 2、POSITION(substr IN str ):返回子串 substr 在字符串 str 中第一次出现的位置,如果字符substr在字符串str中不存在,与LOCATE函数作用相同;
# 3、LEFT(str, length):从左边开始截取str,length是截取的长度;
# 4、RIGHT(str, length):从右边开始截取str,length是截取的长度;
# 5、SUBSTRING_INDEX(str ,substr ,n):返回字符substr在str中第n次出现位置之前的字符串;
# 6、SUBSTRING(str ,n ,m):返回字符串str从第n个字符截取到第m个字符;
# 7、REPLACE(str, n, m):将字符串str中的n字符替换成m字符;
# 8、LENGTH(str):计算字符串str的长度。


select
device_id,
substring_index(blog_url,'/',-1) as user_name
FROM user_submit;
# 其他1
select
device_id,
replace(blog_url,'http:/url/','') as user_name
from user_submit;
# 其他2
select
device_id,
SUBSTRING(blog_url,11) as user_name
FROM user_submit;
# 其他3
select
device_id,
SUBSTR(blog_url,11) as user_name
FROM user_submit;

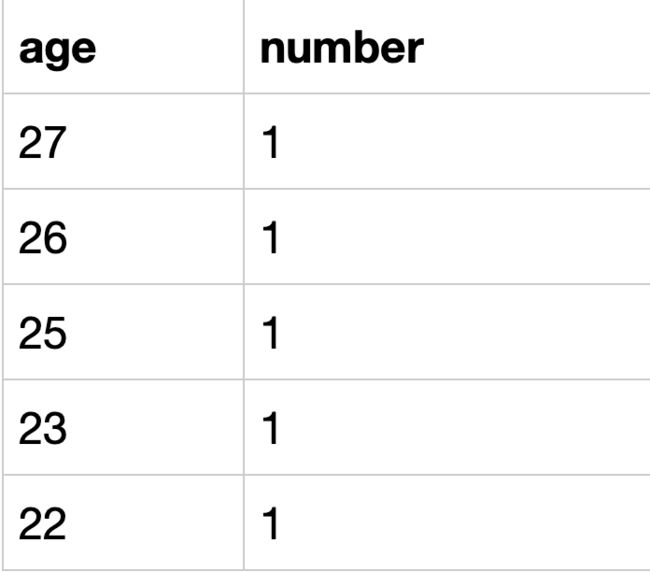
# 参考1:substring_index()
# 详解见https://blog.nowcoder.net/n/44a90eb9828d41d8800c7e160cbc37e8
select
substring_index(
substring_index(profile, ',' ,3),
',',
-1) as age,
count(device_id) as number
from user_submit a
group by age;
# 参考2:SUBSTRING()
SELECT
SUBSTRING(profile,12,2) as age,
COUNT(1) as number
FROM user_submit
GROUP BY age;
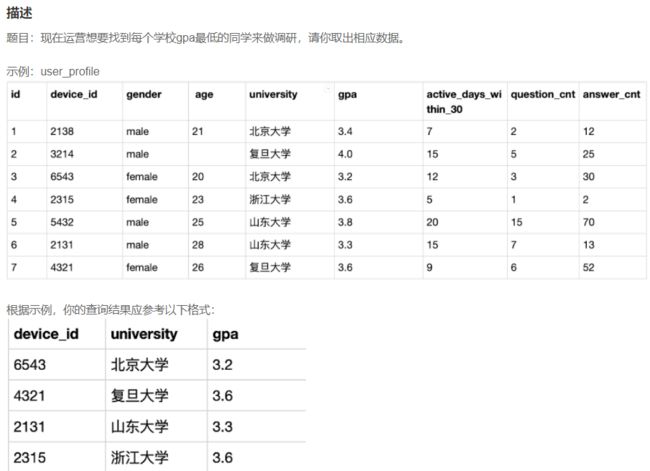
SELECT device_id,university,gpa
from user_profile
WHERE gpa in (select min(gpa)
from user_profile
GROUP BY university)
GROUP BY university # 结果要求每个大学出一个结果(最低GPA)
ORDER BY university; # 结果要求按照大学名称首字母排序
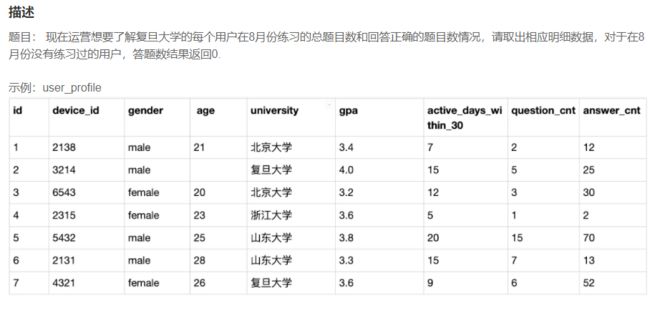

SELECT
t1.device_id,
t1.university,
COUNT(t1.question_cnt) as question_cnt,
SUM(
IF(t2.result='right',1,0)
) as right_question_cnt
from
user_profile as t1,
question_practice_detail as t2
WHERE
t1.university = '复旦大学'
and
t1.device_id = t2.device_id;
# 提交通过;自测结果却不对,可能示例数据不对(下面的参考也是如此)
# 参考1
SELECT
uu.device_id,
uu.university,
count(q.question_id) as question_cnt,
sum(if(q.result='right',1,0)) as right_question_cnt
from
question_practice_detail as q
left outer join
user_profile as uu
on q.device_id=uu.device_id and MONTH(q.date)=8
where
uu.university='复旦大学'
group by
q.device_id;
# 参考2
select
up.device_id,university,
count(upd.device_id) question_cnt,
count(case when result='right' then 1 else null end) right_question_cnt
from
user_profile as up
left join
question_practice_detail as upd
on upd.device_id=up.device_id
where
university='复旦大学' and month(date)='08'
group by
up.device_id;
# 参考3
SELECT
q.device_id, u.university,
COUNT(question_id) AS question_cnt,
COUNT(IF(result='right', 1, NULL)) AS right_question_cnt
FROM user_profile u
INNER JOIN question_practice_detail q
WHERE u.device_id=q.device_id AND university="复旦大学"
GROUP BY u.device_id;




SELECT
t3.difficult_level,
(
SUM(if(t2.result='right',1,0)) / COUNT(t2.result)
) as correct_rate
FROM
user_profile t1,
question_practice_detail t2,
question_detail t3
WHERE
t1.university = '浙江大学'
and t1.device_id = t2.device_id
and t2.question_id = t3.question_id
GROUP BY t3.difficult_level
ORDER BY correct_rate ASC;
# 其他1:https://blog.nowcoder.net/n/a61f6faea0f34fb4817bddcbcb76172d
SELECT qd.difficult_level,
sum(if(qpd.result='right',1,0))/count(qpd.device_id) AS correct_rate
FROM
(question_practice_detail AS qpd
LEFT JOIN user_profile AS u
ON qpd.device_id = u.device_id
LEFT JOIN question_detail AS qd
ON qpd.question_id = qd.question_id)
WHERE u.university = '浙江大学'
GROUP BY qd.difficult_level
ORDER BY correct_rate ASC;
# 其它2:1.要把三个表连起来;2.用前面提到的sum和if的结合来计算个数;3.记得排序
SELECT
q.difficult_level,
sum(if(q.result='right',1,0))/count(q.question_id) as correct_rate
from
(SELECT
q1.question_id,
q1.device_id,
q1.result,
qd1.difficult_level
from
question_practice_detail as q1
left outer JOIN
question_detail as qd1
on q1.question_id= qd1.question_id
) as q
left outer JOIN
user_profile as u
on q.device_id = u.device_id
where u.university='浙江大学'
group by q.difficult_level
order by correct_rate asc;
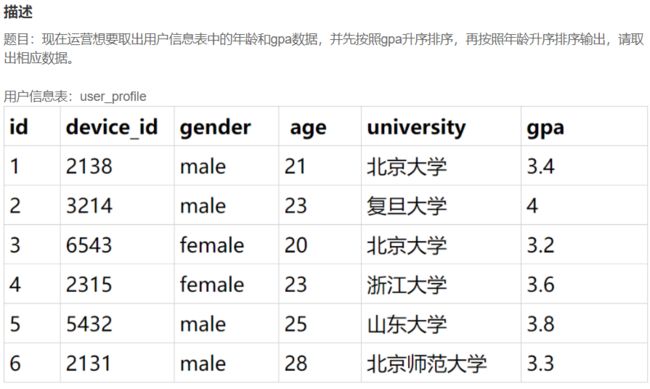
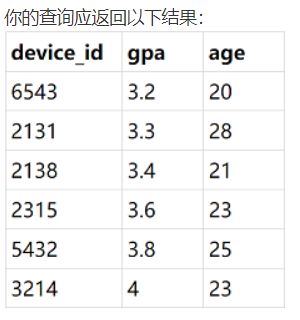
-- 查找后多列排序
select device_id, gpa, age
from user_profile
order by gpa ASC, age ASC;
# 默认以升序排列,以下撒种方式均可
# SELECT device_id,gpa,age from user_profile order by gpa,age;
# SELECT device_id,gpa,age from user_profile order by gpa,age asc;
# SELECT device_id,gpa,age from user_profile order by gpa asc,age asc;

select
COUNT( distinct device_id) as did_cnt,
COUNT( question_id) as qusetion_cnt
from question_practice_detail
where date like '2021-08%';
# 其他1
select
COUNT( distinct device_id) as did_cnt,
COUNT( question_id) as qusetion_cnt
from question_practice_detail
where
year(date)=2021 and MONTH(date)=8;
# 其他2:字符串匹配 LIKE '' ,其中_匹配单个字符,%匹配多个
SELECT
COUNT( DISTINCT device_id) as did_cnt,
count(question_id) as question_cnt
from question_practice_detail
where
date like '2021-08-__';
2、简单
SQL1 查找最晚入职员工的所有信息
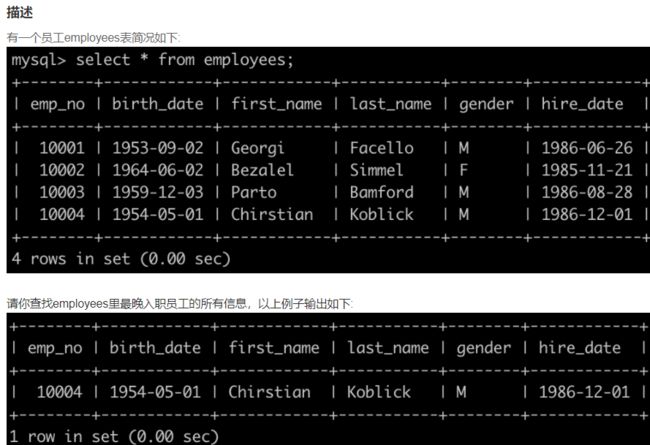
select * from employees
order by hire_date desc
limit 1;
select * from employees
order by hire_date desc
limit 0,1;
# 不建议用ORDER BY + LIMIT 1 的原因:最晚日期可能存在多个员工
select * from employees
where hire_date = (select max(hire_date) from employees);
select * from employees
where hire_date in (select max(hire_date) from employees);
3、入门
SQL2 查找入职员工时间排名倒数第三的员工所有信息
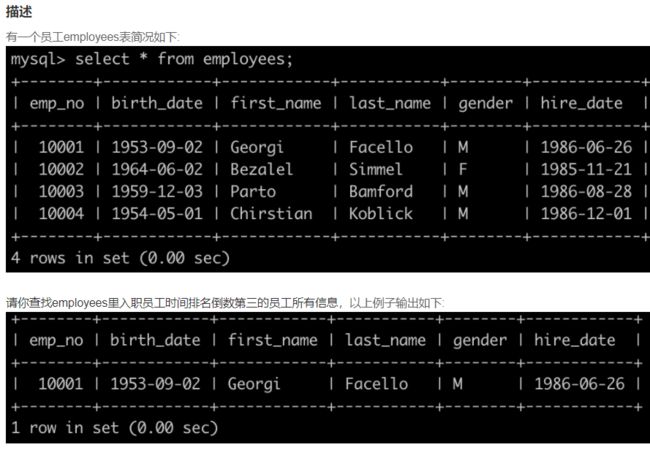
# limit n:表示从第0条数据开始,读取n条数据,是limt(0, n)的缩写
# limit m,n:表示从第m条数据开始,读取n条数据
# limit n offset m:表示从第m条数据开始,读取n条数据(mysql5以后支持这种写法)
select * from employees
order by hire_date DESC
limit 2,1;
select * from employees
order by hire_date DESC
limit 1 offset 2;
# 入职时间相同的员工可能不止一人,推荐这样写
SELECT * FROM employees
WHERE hire_date = ( # 此处不能用in,因为mysql不支持一条语句中in和limit一起用
SELECT DISTINCT hire_date
FROM employees
ORDER BY hire_date DESC
LIMIT 1 OFFSET 2
);
SQL4 查找所有已经分配部门的员工的last_name和first_name以及dept_no
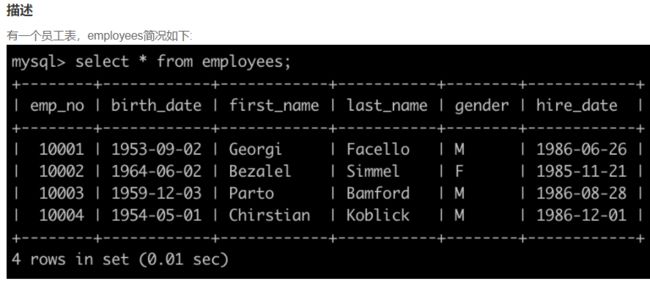


select last_name, first_name, dept_no
from employees as e, dept_emp as d
where e.emp_no = d.emp_no and d.dept_no is not null;
# 1、外部表联结
# 左外部联结(LEFT JOIN)- 包含左边表的所有列
# 右外部联结(RIGHT JOIN)- 包含右边表的所有列
SELECT e.last_name, e.first_name, de.dept_no
FROM dept_emp AS de
LEFT JOIN employees AS e
ON de.emp_no = e.emp_no;
# 2、内部联结
SELECT e.last_name, e.first_name, de.dept_no
FROM dept_emp AS de
JOIN employees AS e
ON de.emp_no = e.emp_no
WHERE de.dept_no IS NOT NULL;


SQL7 查找薪水记录超过15次的员工号emp_no以及其对应的记录次数t

SQL8 找出所有员工当前薪水salary情况

select distinct salary
from salaries
order by salary desc;
-- WHERE语句在GROUP BY语句之前,SQL会在分组之前计算WHERE语句。
-- HAVING语句在GROUP BY语句之后,SQL会在分组之后计算HAVING语句。
-- distinct可以去重,group by也可以
select salary
from salaries
group by salary
order by salary DESC;
SQL10 获取所有非manager的员工emp_no

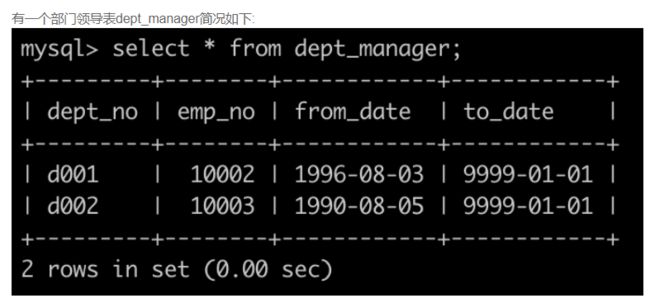

SELECT emp_no
from employees
where
emp_no in (select emp_no from employees) -- 这句没必要了
and emp_no not in (select emp_no from dept_manager);
# 1、NOT IN+子查询
SELECT emp_no
from employees
where emp_no not in (select emp_no from dept_manager);
# 2、左连接 + 去中
SELECT e.emp_no
from employees as e
left join dept_manager as d
on e.emp_no = d.emp_no
where d.emp_no is null;
SQL15 查找employees表emp_no与last_name的员工信息
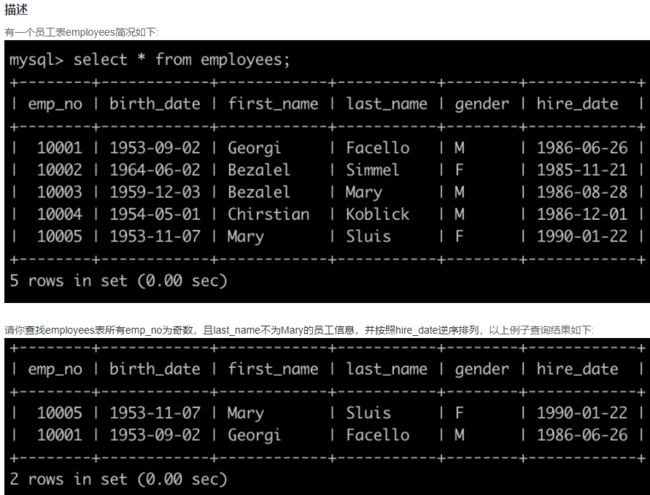
select * from employees
where emp_no%2!=0 and last_name!='Mary'
order by hire_date desc;
SELECT * FROM employees
WHERE emp_no%2=1 AND last_name NOT LIKE 'Mary'
ORDER BY hire_date DESC;
SQL17 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
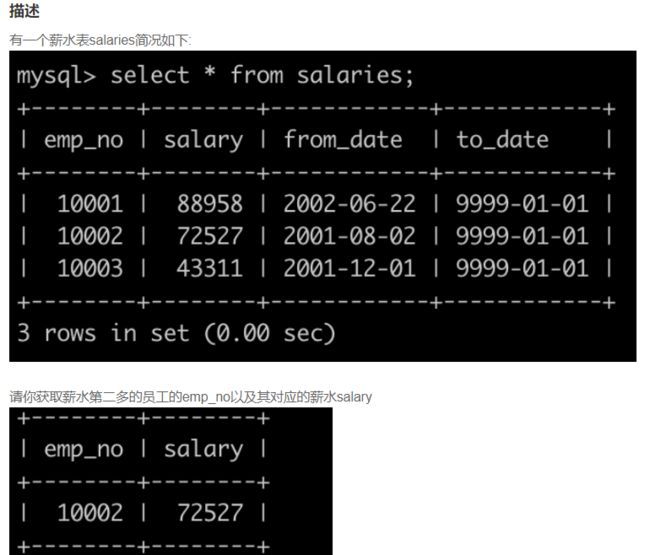
SELECT emp_no, salary from salaries
order by salary DESC
LIMIT 1,1; -- 第一个1表示从第1条记录后面开始取,第二个1表示取1条记录
select emp_no, salary from salaries
where salary = ( select salary from salaries
group by salary
order by salary desc
limit 1,1);
SQL32 将employees表的所有员工的last_name和first_name拼接起来作为Name

select concat_ws(' ', last_name, first_name) as Name from employees;
select CONCAT(last_name, ' ', first_name) as Name from employees;
SQL34 批量插入数据

insert into actor (actor_id,first_name,last_name,last_update)
values (1,'PENELOPE','GUINESS','2006-02-15 12:34:33'),
(2,'NICK','WAHLBERG','2006-02-15 12:34:33');
insert into actor
values (1,'PENELOPE','GUINESS','2006-02-15 12:34:33'),
(2,'NICK','WAHLBERG','2006-02-15 12:34:33');
SQL42 删除emp_no重复的记录,只保留最小的id对应的记录。
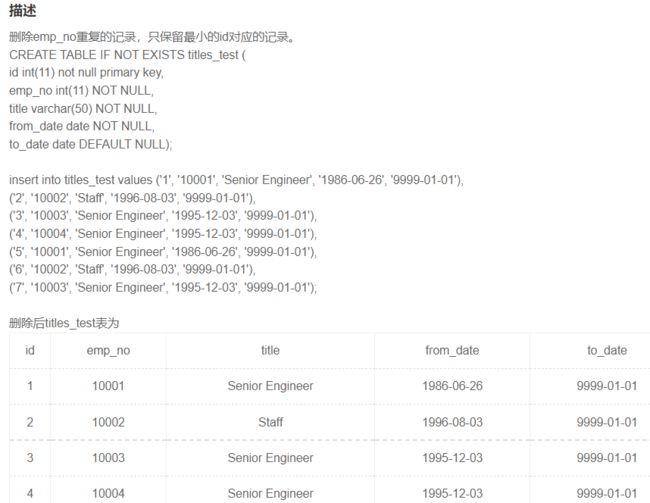
# 错误
# DELETE FROM titles_test
# WHERE id NOT IN(
# SELECT MIN(id)
# FROM titles_test
# GROUP BY emp_no);
# MySQL中不允许在子查询的同时删除表数据(不能一边查一边把查的表删了)
# 正确
DELETE FROM titles_test
WHERE id NOT IN(SELECT *
FROM (SELECT MIN(id)
FROM titles_test
GROUP BY emp_no)
as a); -- 把得出的表重命名为中间表a那就不是原表了
SQL43 将所有to_date为9999-01-01的全部更新为NULL


update titles_test
set to_date=null, from_date='2001-01-01'
where to_date='9999-01-01';
SQL44 将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005

# 1、使用replace
UPDATE titles_test
SET emp_no = REPLACE(emp_no, 10001, 10005)
WHERE id = 5;
# 2、使用insert(有遇到重复主键了就进行更新emp_no的值)
INSERT INTO titles_test
VALUES(5, 10001 ,'Senior Engineer', '1986-06-26', '9999-01-01')
ON DUPLICATE KEY UPDATE emp_no = 10005;
# 3、使用replace into(REPLACE INTO当遇到primary 或者 unique key 的时候,会首先进行update)
REPLACE INTO titles_test
VALUES(5, 10005 ,'Senior Engineer', '1986-06-26', '9999-01-01') ;
SQL45 将titles_test表名修改为titles_2017

ALTER TABLE titles_test
RENAME TO titles_2017;
# 更改表名语句结构: ALTER TABLE 原表名 RENAME TO/AS 新表名
SQL62 出现三次以上相同积分的情况
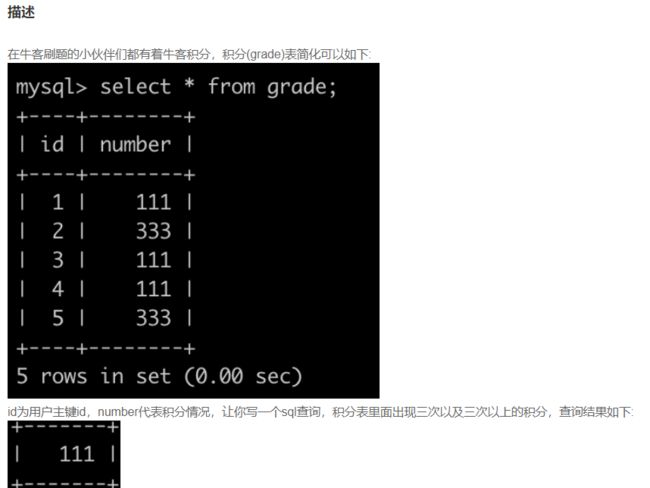
-- 分组、筛选组
select number from grade
group by number
having count(number)>=3;
SELECT
e.number
FROM
(
SELECT
number, count(number) as cnt
FROM
grade
GROUP BY
number
) as e
WHERE
e.cnt >= 3;
SQL64 找到每个人的任务

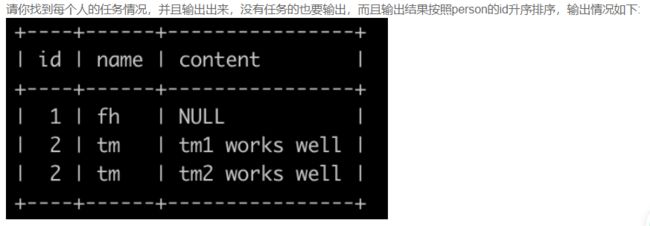
select person.id,person.name,task.content -- 这个题目挺简单的,首先肯定先写出,要输出的东西:
from person
left join task on person.id=task.person_id -- 但是有个坑注意就是,没有任务的也要输出,所以连接task表的时候要使用左连接:
order by person.id; -- 最后按照person的id升序输出

SQL66 牛客每个人最近的登录日期(一)


select user_id, max(date) as d
from login
group by user_id
order by user_id;
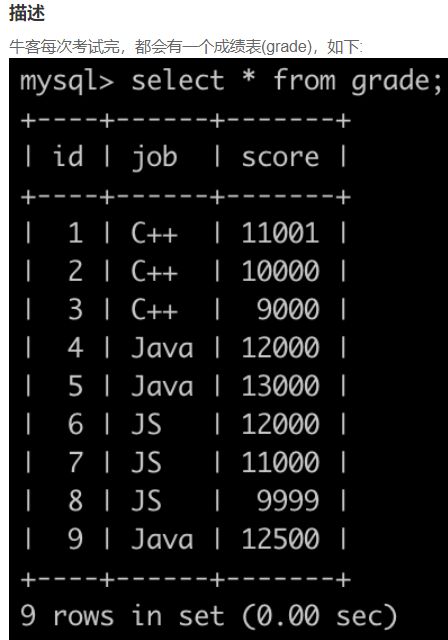
SQL72 考试分数(一)
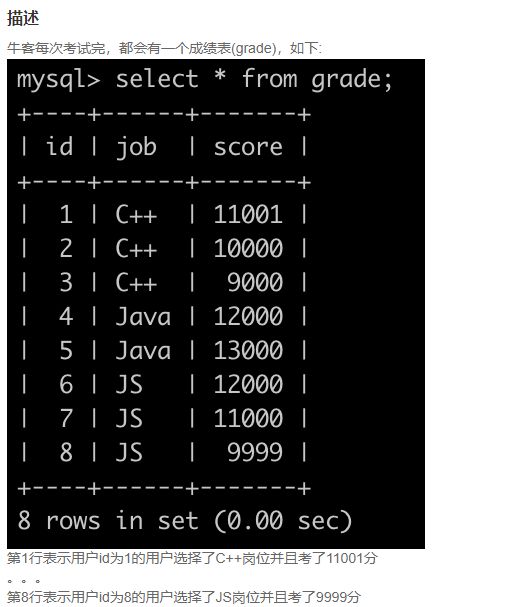
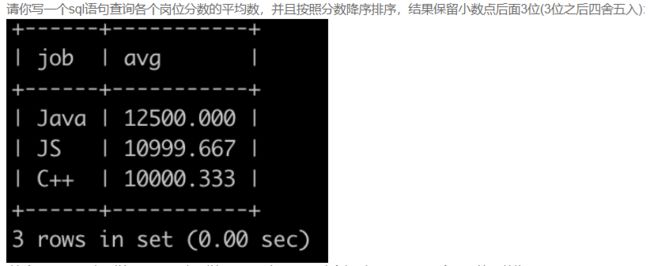
select job, round(avg(score), 3) as avg
from grade
group by job
order by avg desc;
-- 使用 ROUND(聚合函数,精确到小数点后几位)的方法来满足该需求
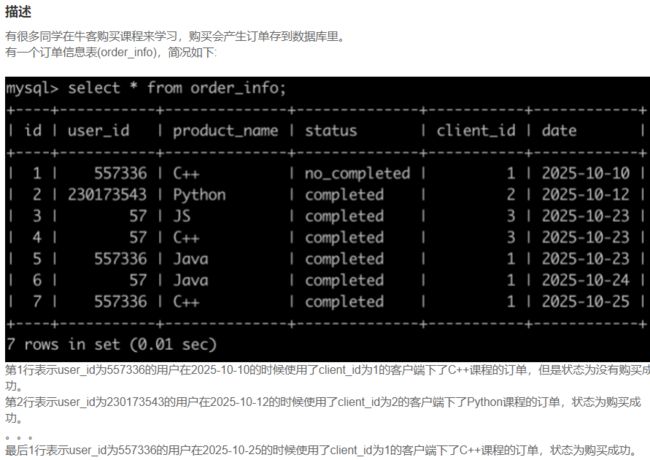
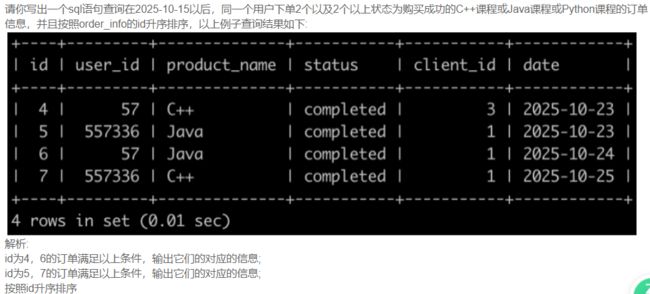
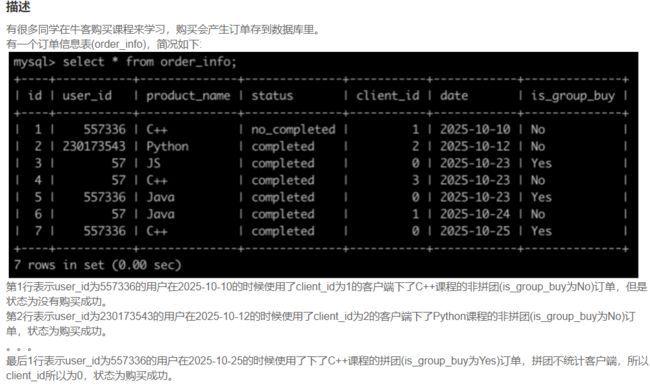
SQL77 牛客的课程订单分析(一)
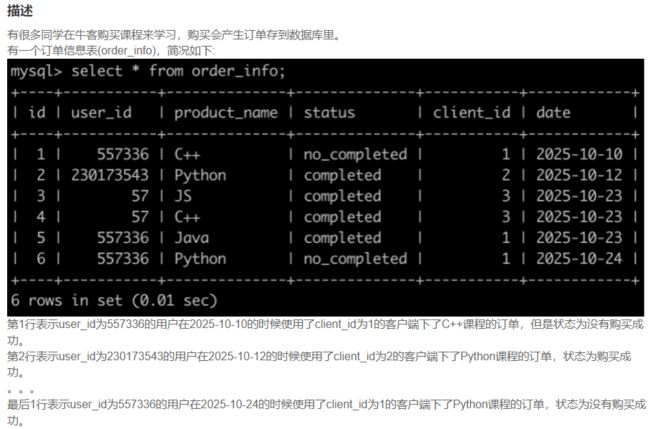
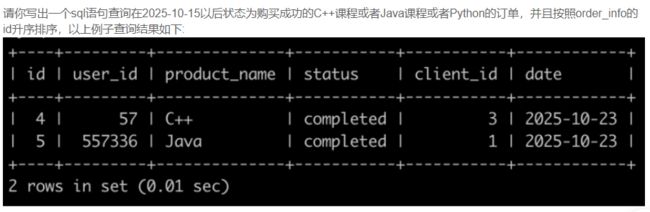
select *
from order_info
where
date>'2025-10-15'
and status='completed'
and (product_name='C++'
or product_name='Java'
or product_name='Python')
order by id asc;
select
id, user_id, product_name, status, client_id, date
from
order_info
where
date > '2025-10-15'
and product_name in ('C++','Java','Python')
and status = 'completed'
order by
id asc;
-- DATEDIFF(d1,d2) 语句,计算日期 d1到d2 之间相隔的天数
select *
from order_info
where
datediff(date,"2025-10-15")>0
and status = "completed"
and product_name in ("C++","Java","Python")
order by id;
SQL84 实习广场投递简历分析(一)
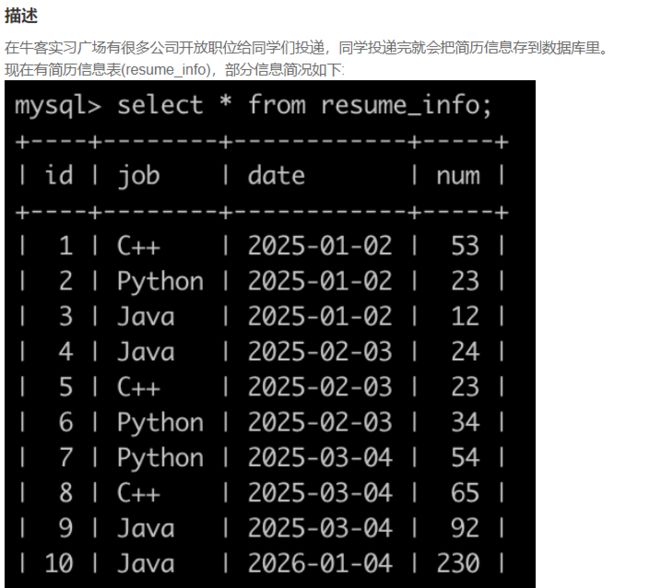
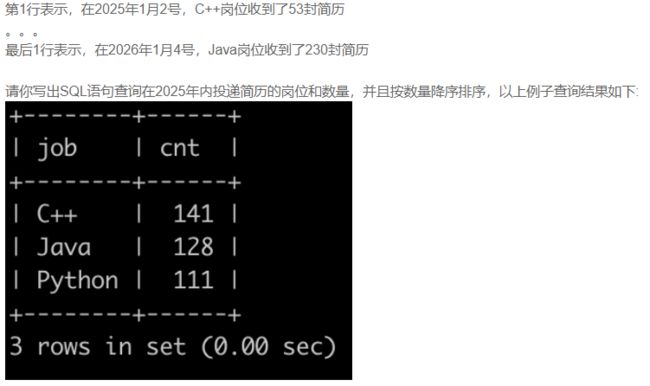
SELECT job, sum(num) as cnt
from resume_info
where YEAR(date)='2025'
GROUP by job
order by cnt desc;
4、中等
SQL92 商品交易(网易校招笔试真题)
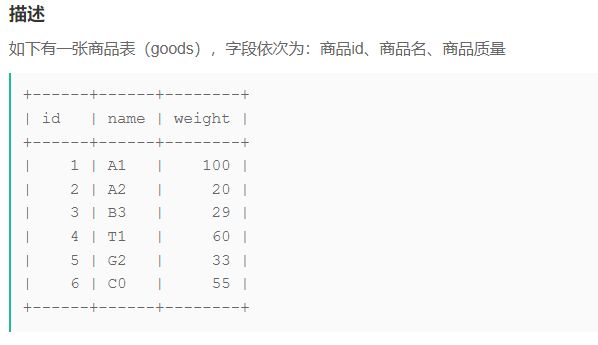


SELECT g.id, g.name, g.weight, sum(t.count) as total
from goods as g, trans as t
where g.weight < 50 and g.id = t.goods_id
group by t.goods_id
order by g.id asc;
-- 其他
select id,name,weight,total
from
goods,
(select t.goods_id , sum(t.count) as total from trans t group by t.goods_id) as ts
where
goods.id = ts.goods_id
and (goods.weight<50 and ts.total > 20);
-- 其他
SELECT a.id, a.name, a.weight, sum(b.count) as total
from goods a
left join trans b on a.id=b.goods_id
WHERE a.weight<50
group by a.name
having total>20;
SQL3 查找当前薪水详情以及部门编号dept_no

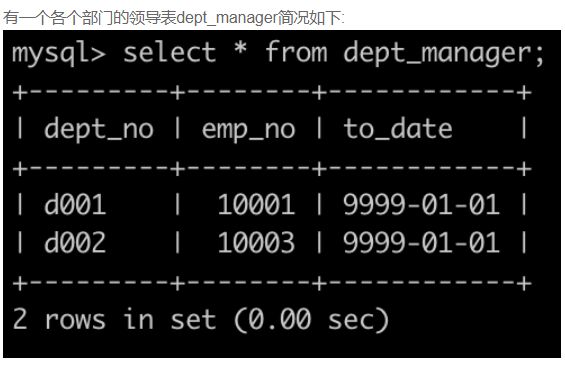
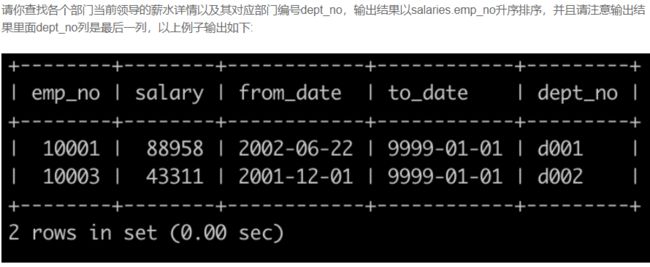
select salaries.emp_no, salary, from_date, salaries.to_date, dept_no
from salaries, dept_manager
where salaries.emp_no = dept_manager.emp_no
order by salaries.emp_no;
SELECT s.emp_no, s.salary, s.from_date, s.to_date, d.dept_no
FROM salaries s
JOIN dept_manager d -- 或者inner join
ON s.emp_no=d.emp_no
ORDER BY s.emp_no ASC;
SELECT s.emp_no, s.salary, s.from_date, s.to_date, d.dept_no
FROM salaries s
INNER JOIN dept_manager d
ON s.emp_no=d.emp_no
ORDER BY s.emp_no ASC;
SQL5 查找所有员工的last_name和first_name以及对应部门编号dept_no
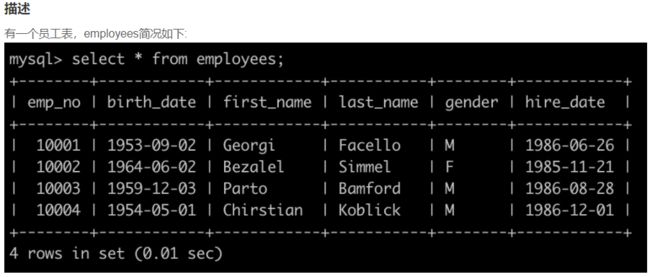
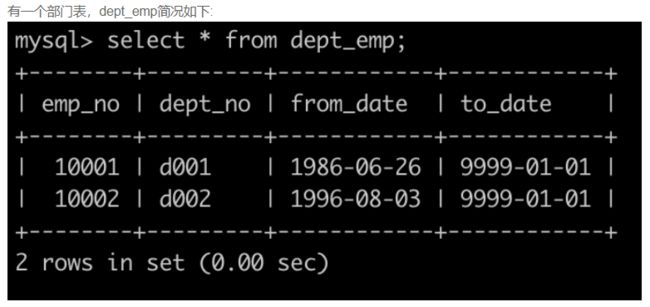
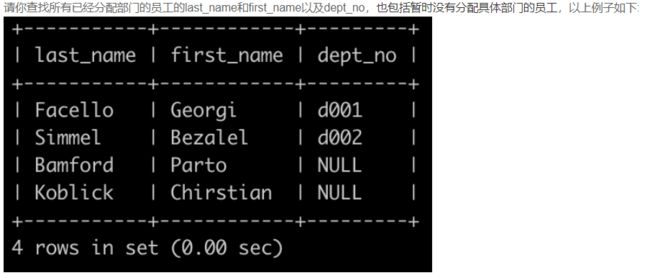
select e.last_name, e.first_name, d.dept_no
from employees as e
left join dept_emp as d
on e.emp_no=d.emp_no;
-- 左连接是以左表为基准匹配右表数据 ,匹配不上的填写null
-- 需要查找所有员工,包括没有分配部门的员工,因此在连接时需要以employees为主表
-- left join 左边的为主表,right join右边的为主表
SELECT e.last_name, e.first_name, d.dept_no
FROM dept_emp AS d
right JOIN employees AS e
ON d.emp_no = e.emp_no;
左连接 
右连接
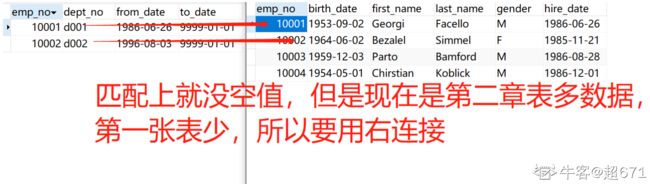
SQL11 获取所有员工当前的manager


-- 参考1:两表联结 且 员工不为manager
SELECT de.emp_no, dm.emp_no
FROM dept_emp AS de
LEFT JOIN dept_manager AS dm
ON de.dept_no = dm.dept_no
WHERE de.emp_no NOT IN (SELECT emp_no FROM dept_manager);
-- 参考2
SELECT de.emp_no, dm.emp_no
FROM dept_emp AS de
left JOIN dept_manager as dm
ON de.dept_no = dm.dept_no
WHERE de.emp_no != dm.emp_no
SQL16 统计出当前各个title类型对应的员工当前薪水对应的平均工资


select title, avg(salary) as avg_salary
from titles as t, salaries as s
where t.emp_no = s.emp_no
group by title
order by avg_salary;
# 通过group by对各个title类型进行分组
# 对这一题来说,用内连接、左连接和右连接都可以,因为两个表中的emp_no一样,不会出现null的情况
# order by 排序
# group by 进行数据分组
# having 过滤分组
# where 过滤行
SQL19 查找所有员工的last_name和first_name以及对应的dept_name
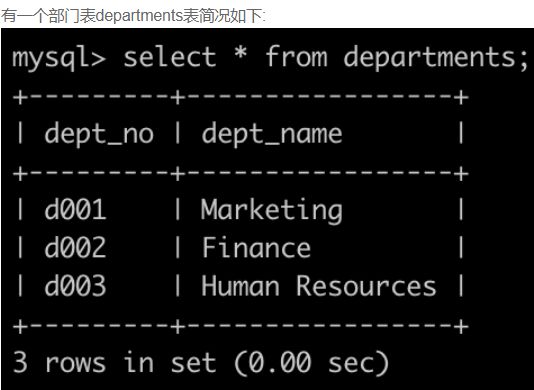
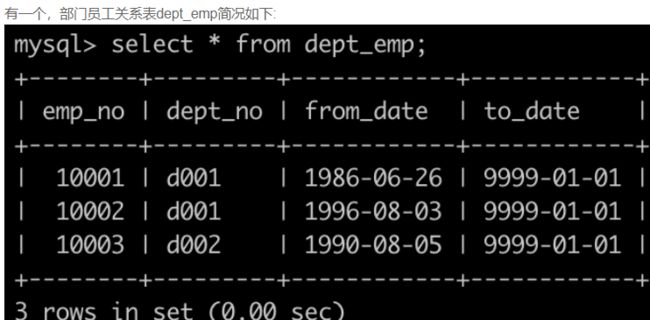

-- 参考1:要求连结employees表的全部行(包括暂时没有分配部门的员工)
select e.last_name, e.first_name, d.dept_name
from departments as d
join dept_emp as de on d.dept_no = de.dept_no
right join employees as e on e.emp_no = de.emp_no;
-- 参考2
SELECT a.last_name,a.first_name,b.dept_name
FROM (SELECT e.emp_no, e.last_name, e.first_name, de.dept_no
FROM employees AS e
LEFT JOIN dept_emp AS de
ON e.emp_no = de.emp_no) AS a
LEFT JOIN (SELECT de2.emp_no, de2.dept_no, d.dept_name
FROM dept_emp AS de2
INNER JOIN departments AS d
ON de2.dept_no = d.dept_no) AS b
ON a.dept_no=b.dept_no AND a.emp_no=b.emp_no;
-- 参考3
select last_name,first_name,dept_name
from employees e
left join (departments d, dept_emp de)
on e.emp_no=de.emp_no and d.dept_no=de.dept_no;
-- 参考4:https://blog.nowcoder.net/n/0a82d1626be44ab7943a62ed8c7772aa
select last_name, first_name, dept_name
from employees e
left join dept_emp de on de.emp_no = e.emp_no
left join departments d on de.dept_no = d.dept_no;
# 1、需要所有员工的last_name和first_name, 这两个信息都来自于employees,所以要把employees作为主表
# 2、先连接employees和dept_emp,将employees作为主表,把dept_no信息添加进来
# 3、再连接第2步中的表 和 departments,依然是将包含employees表内容的表作为主表,把dept_name信息添加进来
# 注意:两个join连着用,意味着先把employees和dept_emp连接,然后将连接后的表再与departments表连接,
# 而不是employees表分别与dept_emp、departments表连接
SQL22 统计各个部门的工资记录数
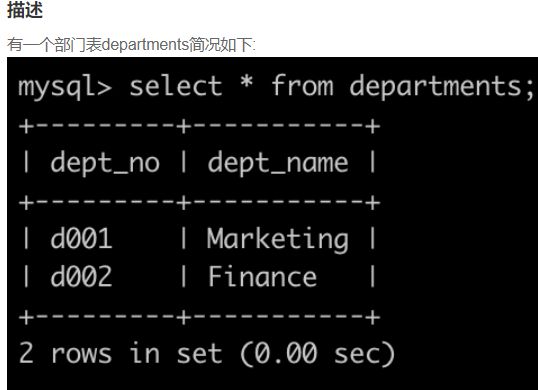
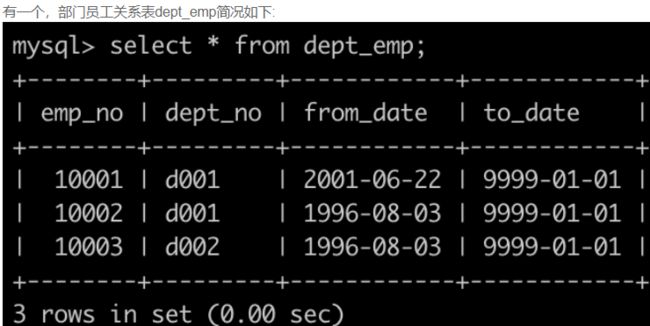
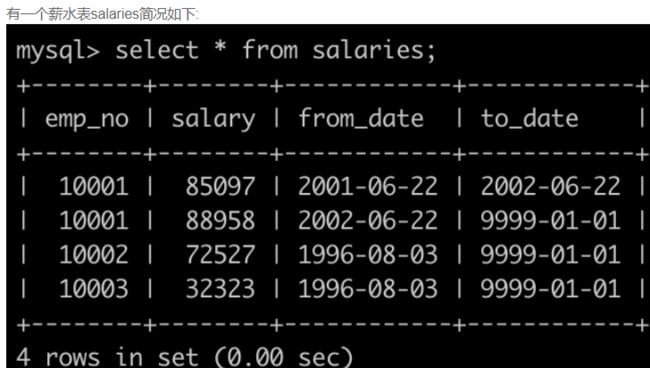
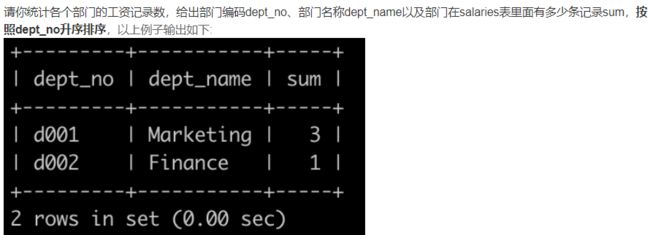
-- 思路:三表连结再分组再排序,使用聚合函数
select d.dept_no, d.dept_name, count(s.emp_no)
FROM departments d, dept_emp de, salaries s
where d.dept_no = de.dept_no and de.emp_no = s.emp_no
group by dept_no
order by dept_no;
-- 其他1
select d.dept_no, d.dept_name, count(*) as sum
from (departments d join dept_emp de on d.dept_no=de.dept_no)
join salaries s on de.emp_no=s.emp_no
group by d.dept_no
order by dept_no;



SQL29 使用join查询方式找出没有分类的电影id以及名称
-- 使用join
select f.film_id, f.title
from film as f left join film_category as fc on f.film_id = fc.film_id
where fc.category_id is null;
-- 使用子查询
select f.film_id, f.title
from film as f
where f.film_id not in (select film_id from film_category);
SQL30 使用子查询的方式找出属于Action分类的所有电影对应的title,description
-- 不用子查询,直接where
select f.title, f.description
from film as f, category as c, film_category as fc
where
f.film_id = fc.film_id
and c.category_id = fc.category_id
and c.name = 'Action';
-- 子查询
select f.title, f.description
from film as f
where
f.film_id in (select fc.film_id
from film_category as fc, category as c
where c.category_id = fc.category_id
and c.name = 'Action');
-- 参考1:join + 子查询
select f.title,f.description
from film f
left join film_category fc
on f.film_id = fc.film_id
where fc.category_id = (select category_id from category where name = 'Action');
# 1. 先分析题目“找出属于Action分类的所有电影”,按照 name 去找 分类,只能从 category 表去找;
# 2. 但是 category 和 film表没有直接关联,恰好film_category 表和 film有关联,最重要的是,film_category 表和 category 表也有关联(但是film_category 表中不能直接查询name,但是可以通过分类id去查);
# 3. 题目要求使用子查询,所以此时,我们可以先 在category表中查出 name为 Action的分类id,再通过分类id去查询。
-- 参考2:子查询
SELECT f.title, f.description
FROM film AS f, film_category AS fc
WHERE f.film_id = fc.film_id
AND fc.category_id IN (SELECT category_id
FROM category
WHERE name = 'Action');
SQL33 创建一个actor表,包含如下列信息

drop table if exists actor;
create TABLE actor(
actor_id smallint(5) not null primary key comment "主键id",
first_name varchar(45) not null comment "名字",
last_name varchar(45) not null comment "姓氏",
last_update date not null comment "日期"
);
SQL35 批量插入数据,不使用replace操作

insert ignore into actor VALUES('3','ED','CHASE','2006-02-15 12:34:33');
insert into actor(actor_id, first_name, last_name, last_update)
select 3, 'WD', 'GUINESS', '2006-02-15 12:34:33'
from DUAL
where not exists (select actor_id FROM actor WHERE actor_id = 3);
SQL36 创建一个actor_name表

drop table if exists actor_name;
create TABLE actor_name(
first_name varchar(45) not null comment "名字",
last_name varchar(45) not null comment "姓氏"
);
INSERT INTO actor_name
SELECT first_name,last_name
FROM actor;
-- https://blog.nowcoder.net/n/aa94945c76e6427482ef50d6c2b31ef6
SQL37 对first_name创建唯一索引uniq_idx_firstname

-- MySQL中四种方式给字段添加索引以及删除索引
-- https://blog.nowcoder.net/n/afd028af866a43a389ffdd161dadb0fc
-- 参考1
CREATE INDEX idx_lastname ON actor(last_name);
CREATE UNIQUE INDEX uniq_idx_firstname ON actor(first_name);
-- 参考2
alter table actor add unique uniq_idx_firstname(first_name);
alter table actor add index idx_lastname(last_name);
# 使用ALTER 命令添加索引,有四种方式来添加数据表的索引:
# ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
# ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
# ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。
# ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。
SQL38 针对actor表创建视图actor_name_view
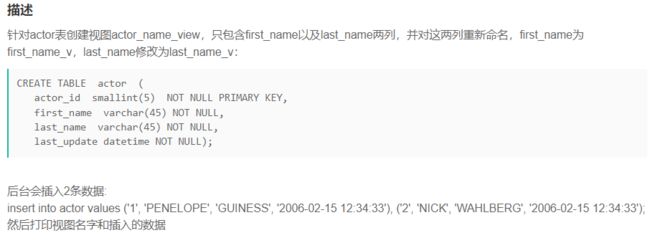
-- 1、直接在视图名的后面用小括号创建视图中的字段名
create view actor_name_view (first_name_v,last_name_v)
as
select first_name ,last_name from actor;
-- 2、在select后面对列重命名为视图的字段名
CREATE VIEW actor_name_view
AS
SELECT first_name AS first_name_v, last_name AS last_name_v FROM actor;
SQL39 针对上面的salaries表emp_no字段创建索引idx_emp_no

-- 题目创建表是已经创建索引idx_emp_no了。所以我们只需要按题意使用强索引进行查询
select * from salaries
force index (idx_emp_no)
where emp_no=10005
-- 强制索引的作用https://www.cnblogs.com/ll409546297/p/9060820.html
SQL40 在last_update后面新增加一列名字为create_date

alter table actor
add create_date datetime not null default '2020-10-01 00:00:00';
SQL41 构造一个触发器audit_log

-- https://blog.csdn.net/weixin_41177699/article/details/80302987
-- https://blog.nowcoder.net/n/7e02277e6ca04f6bb3168b2bad1f3c7c
# 在MySQL中,创建触发器语法如下:
# CREATE TRIGGER trigger_name
# trigger_time trigger_event ON tbl_name
# FOR EACH ROW
# trigger_stmt
# 其中:
# trigger_name:标识触发器名称,用户自行指定;
# trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
# trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
# tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
# trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句,每条语句结束要分号结尾。
create trigger audit_log
after insert on employees_test
for each row
begin
insert into audit values(new.id,new.name); -- 注意这里有一个分号,必须有且只能放在这
end
SQL46 在audit表上创建外键约束,其emp_no对应employees_test表的主键id
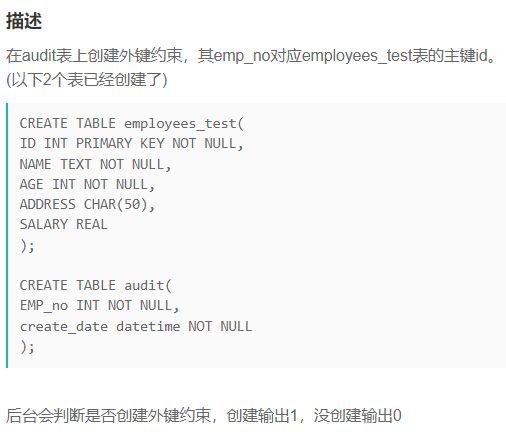
alter table audit
add constraint foreign key (emp_no)
references employees_test(id);
# 创建外键语句结构:
# ALTER TABLE <主表名>
# ADD CONSTRAINT FOREIGN KEY (<主表列名>)
# REFERENCES <关联表>(关联列)
SQL48 将所有获取奖金的员工当前的薪水增加10%
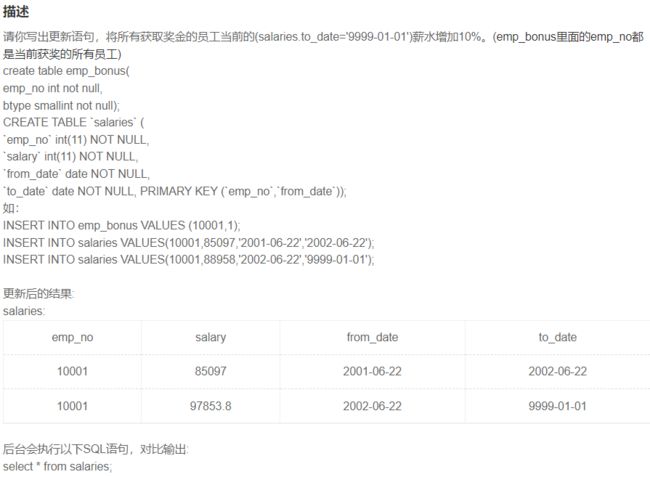
update salaries
set salary=salary+salary*0.1
where
to_date='9999-01-01'
and salaries.emp_no in (select emp_no from emp_bonus);
UPDATE salaries AS s
SET s.salary = 1.1 * s.salary
WHERE s.to_date = '9999-01-01'
AND s.emp_no IN(SELECT emp_no
FROM emp_bonus);
SQL50 将employees表中的所有员工的last_name和first_name通过引号连接起来

select concat(last_name, "'", first_name) as name from employees;
# concat()函数
# 1、功能:将多个字符串连接成一个字符串。
# 2、语法:concat(str1, str2,...)
# 返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
QL51 查找字符串“10,A,B”中逗号,出现的次数cnt
# select count(",") as cnt from '10,A,B'
-- 不对
-- 参考 https://blog.nowcoder.net/n/e3448a4cbd5c45d4abfe524db0b6f33e
select char_length("10,A,B")-char_length(replace("10,A,B", ",", ""));
# char_length('string')/char_length(column_name)
# 1、返回值为字符串string或者对应字段长度,长度的单位为字符,一个多字节字符(例如,汉字)算作一个单字符;
# 2、不管汉字还是数字或者是字母都算是一个字符;
# 3、任何编码下,多字节字符都算是一个字符;
# length('string')/length(column_name)
# 1、utf8字符集编码下,一个汉字是算三个字符,一个数字或字母算一个字符。
# 2、其他编码下,一个汉字算两个字符, 一个数字或字母算一个字符
# 字符串替换:REPLACE(s,s1,s2),将字符串 s2 替代字符串 s 中的字符串 s1
-- replace("10,A,B", ",", ""):将"10,A,B"中的所有逗号换为空字符,即删掉了两个逗号
-- 直接这句也行,QAQ
select 2;
SQL52 获取Employees中的first_name

-- 方法1:自己写的
-- substr(str,start,length)
# 1.字符串的第一个字符的索引是1。
# 2.值为正时从字符串开始位置开始计数,值为负时从字符串结尾位置开始计数。
# 3.长度不填时默认取到结尾。
select first_name
from employees
order by SUBSTR(first_name, -2, 2);
-- 方法2:参考
-- right(str,num) 函数
-- 从右边开始截取str字符串num长度.同理还有left函数
SELECT first_name FROM employees ORDER BY RIGHT(first_name,2);
SQL53 按照dept_no进行汇总
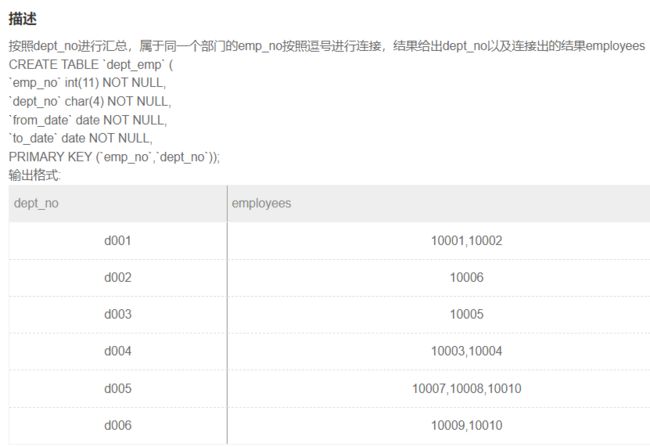
-- 参考
select dept_no, group_concat(emp_no) as employees
from dept_emp
group by dept_no;
# 知识点总结:group_concat()函数将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
# 语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
# 通过使用distinct可以排除重复值;
# 如果希望对结果中的值进行排序,可以使用order by子句;
# separator是一个字符串值,缺省为一个逗号。
SQL54 平均工资

-- 参考
SELECT AVG(salary) as avg_salary
FROM salaries
WHERE salary NOT IN(SELECT MAX(salary)
FROM salaries
WHERE to_date = '9999-01-01')
AND salary NOT IN (SELECT MIN(salary)
FROM salaries
WHERE to_date = '9999-01-01')
AND to_date = '9999-01-01';
SELECT AVG(salary) as avg_salary
FROM salaries
WHERE salary != (SELECT MAX(salary)
FROM salaries
WHERE to_date = '9999-01-01')
AND salary != (SELECT MIN(salary)
FROM salaries
WHERE to_date = '9999-01-01')
AND to_date = '9999-01-01';
# 关于为什么要用多个where子句判断to_date="9999-01-01".
# 题目描述查找排除最大、最小salary之后的当前(to_date = '9999-01-01' )员工的平均工资avg_salary。
# 个人思路先找出当前在职员工的最大、最小薪水。然后在当前在职员工薪水集合里扣除再求均值
SQL55 分页查询employees表,每5行一页,返回第2页的数据

-- 参考1
select *
from employees
limit 5,5
-- limit n,m 等于limit m offset n
-- n为偏移量,m为获取数据的个数
-- n=5说明数据取在5行之后(即首页之后,从第六条开始取)。
-- m=5即取五条数据(每5行为一页,所以取第二页数据)。
-- 参考2
select *
from employees
limit 5 offset 5
SQL57 使用含有关键字exists查找未分配具体部门的员工的所有信息。
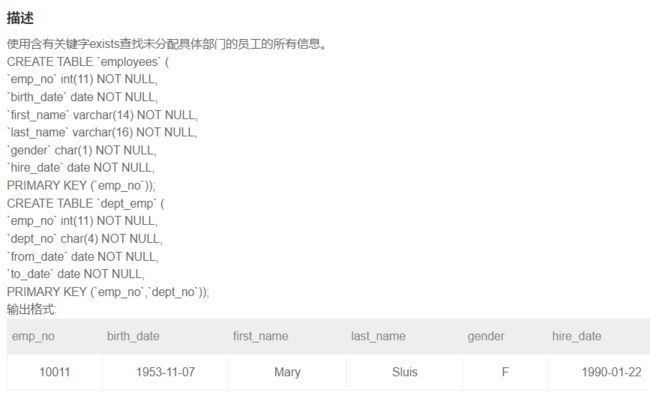
-- 自己实现;未使用exists关键字,虽能出结果但不符合要求
select *
from employees
where emp_no not in (select emp_no
from dept_emp);
# IN 语句:只执行一次
# 确定给定的值是否与子查询或列表中的值相匹配。in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。
# EXISTS语句:执行employees.length次
# 指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
-- 参考
select *
from employees
where not exists (select emp_no
from dept_emp
where employees.emp_no=dept_emp.emp_no);
SQL63 刷题通过的题目排名

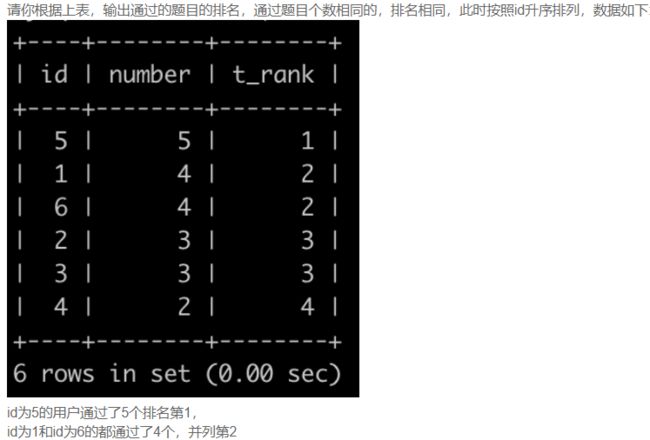
# select id, number, ROWS as t_rank
# from passing_number
# order by number, id asc;
-- ROWS不对,想找一个可以能对记录依次编号的变量
-- 参考:利用窗口函数计算排名
SELECT
id, number,
dense_rank() over(ORDER BY number DESC) AS t_rank
FROM passing_number;
-- 窗口函数详解:https://blog.nowcoder.net/n/bb8e0fcbe12a49ee9b83519b3e950d6f
-- 1. rank() over:查出指定条件后的进行排名。特点是相同排名虽然并列,但是下一排名会空出位置
-- 2. dense_rank() over:查出指定条件后的进行排名。特点是相同排名并列,并且下一排名不会空出位置
-- 3. row_number() over:不存在并列排名的情况,只会顺序排名
# mysql 排名函数(搭配窗口函数)
# 1、rank()over()//按照窗口分区,为每一行分配并列排名,通常不是连续的,若有并列的(1 1 3),会直接跳过2
# 2、dense_rank()//并列连续排序
# 3、row_number()//连续排名
SQL73 考试分数(二)

-- 参考
-- 1.先找出每个工作的平均分。
-- 2.用grade表与1进行比较,找出分数大于均分的数据并按id升序排序。
select t1.*
from grade as t1
join(select job, avg(score) as avg_score
from grade
group by job) as t2
on t1.job = t2.job
where t1.score > t2.avg_score
order by t1.id;
SQL78 牛客的课程订单分析(二)

-- 参考
select user_id
from order_info
where datediff(date,"2025-10-15") > 0
and status ="completed"
and product_name in ("C++","Java","Python")
group by user_id
having count(id) >= 2
order by user_id;
# 按题意一步一步写条件即可。
# 注意where子句常见错误之一:
# where子句中不能使用聚合函数,聚合函数可以在select,having,order by之后出现。
# where指定分组之前数据行的条件,having子句用来指定分组之后条件。
SQL79 牛客的课程订单分析(三)

-- 参考:https://blog.nowcoder.net/n/bd5dd0435ca346aa9d701b6b8428961a
-- 与SQL78(二)几乎一样。不过的是因为要显示的所有信息因此不能直接使用group by后的结果。
select *
from order_info
where datediff(date,"2025-10-15")>0
and product_name in ("C++","Java","Python")
and status="completed"
and user_id in (
select user_id
from order_info
where datediff(date,"2025-10-15")>0
and product_name in ("C++","Java","Python")
and status ="completed"
group by user_id
having count(id)>1
)
order by id;
SQL82 牛客的课程订单分析(六)

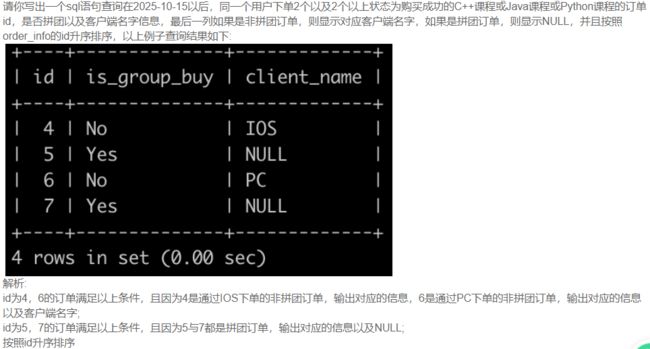
-- 参考:https://blog.nowcoder.net/n/0bb5b81646c84f7cbcda7e69c11450cd
-- 个人思路:以我的SQL79(三)为基础,右连接+窗口函数。
select t2.id, t2.is_group_buy, t1.name as client_name
from client AS t1 right join
(
select *, count(id) over(partition by user_id) as number
from order_info
where datediff(date,"2025-10-15")>0
and status="completed"
and product_name in ("C++","Java","Python")
) AS t2
on t1.id=t2.client_id
where t2.number > 1
order by t2.id;
SQL85 实习广场投递简历分析(二)


-- 参考1
-- 按月统计数量并排序
select job,date_format(date,'%Y-%m') as mon,sum(num) as cnt
from resume_info
where date like '2025%'
group by job,mon
order by mon desc,cnt desc;
# DATE_FORMAT(date或DATETIME,format)函数用于以不同的格式显示日期/时间数据
# date 参数是合法的日期。format 规定日期/时间的输出格式
# %Y 四位数字表示的年份
# %y 两位数字表示的年份
# %m 两位数字表示的月份( 01, 02, . . ., 12)
# %d 两位数字表示月中的天数( 00, 01, . . ., 31)
-- 参考2
select job, DATE_FORMAT(date, '%Y-%m') as mon, sum(num) as cnt
from resume_info
where date < '2026-01-01'and date > '2024-12-31'
group by job, mon
order by mon desc , cnt desc;
-- 参考3
select job, DATE_FORMAT(date, '%Y-%m') as mon, sum(num) as cnt
from resume_info
where YEAR(date) = 2025
group by job, mon
order by mon desc , cnt desc;
SQL87 最差是第几名(一)
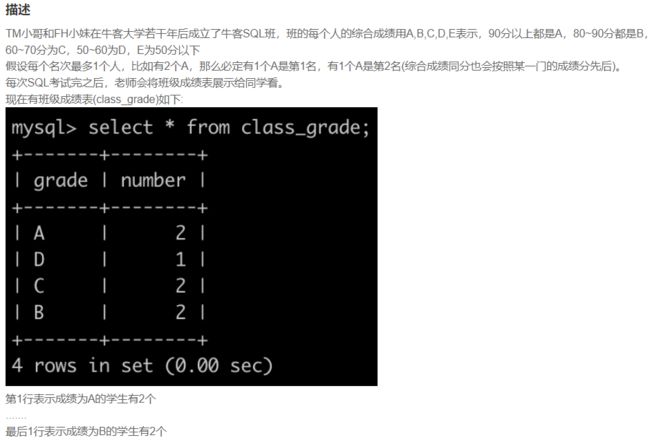

-- 参考1:用转置函数 case when 解决
select grade ,
case grade when 'A' then (select sum(number) from class_grade where grade <= 'A')
when 'B' then (select sum(number)from class_grade where grade <= 'B')
when 'C' then (select sum(number)from class_grade where grade <= 'C')
when 'D' then (select sum(number)from class_grade where grade <= 'D')
else (select sum(number) from class_grade)
end
from class_grade
order by grade
-- 参考2:用窗口函数sum()over()解决
select grade, sum(number)over(order by grade asc)t_rank
from class_grade
order by grade
-- case函数和窗口函数详解
-- https://blog.nowcoder.net/n/3872ffc328524ada842ead8843171aa7
SQL89 获得积分最多的人(一)



-- 参考1:使用窗口函数sum()over()
-- 总积分最高的 而不是 增加积分最高的
select u.name, g.grade
from (select user_id, sum(grade_num) over(partition by user_id) as grade
from grade_info
order by grade desc
limit 1) as g
join user as u on g.user_id = u.id;
-- 参考2
select b.name, sum(a.grade_num) as grade_sum
from grade_info as a
left join user as b on a.user_id = b.id
group by a.user_id
order by grade_sum desc
limit 1;