【自然语言处理】【文本生成】UniLM:用于自然语言理解和生成的统一语言模型预训练
论文地址:https://arxiv.org/pdf/1905.03197.pdf
相关博客
【自然语言处理】【文本生成】Transformers中用于语言生成的不同解码方法
【自然语言处理】【文本生成】BART:用于自然语言生成、翻译和理解的降噪Sequence-to-Sequence预训练
【自然语言处理】【文本生成】UniLM:用于自然语言理解和生成的统一语言模型预训练
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
一、简介
预训练语言模型提高了各种自然语言处理任务的表现。预训练语言模型通过使用大量文本进行基于上下文的预测来学习上下文表示,并通过微调来适应下游任务。
不同类型的预训练语言模型具有不同的预测任务和训练目标函数。 ELMo \text{ELMo} ELMo学习两个单向 LMs \text{LMs} LMs:一个前向 LM \text{LM} LM从左到右读取文本,一个后向 LM \text{LM} LM则从右到左编码文本。 GPT \text{GPT} GPT使用一个left-to-right的 Transformer \text{Transformer} Transformer来逐个词的预测文本序列。作为对比, BERT \text{BERT} BERT利用双向 Transformer \text{Transformer} Transformer编码器来融合左和右两个方向上下文来预测遮蔽单词。虽然 BERT \text{BERT} BERT显著改善了各种自然语言处理任务,但是双向的本质使得其应用在自然语言生成任务上比较困难。
在本文中,作者提出了一个新的统一预训练语言模型 (Unified pre-trained Language Model,UniLM) \text{(Unified pre-trained Language Model,UniLM)} (Unified pre-trained Language Model,UniLM),其能够被同时应用在自然语言理解和自然语言生成。 UniLM \text{UniLM} UniLM是多层 Transformer \text{Transformer} Transformer网络,在大规模文本上进行预训练并使用三种无监督目标函数进行优化。特别地,作者设计了一组完型填空任务来基于上下文预测遮蔽单词。这些完型填空任务的不同在于如何定义上下文。对于一个从左到右的单向 LM \text{LM} LM,需要被预测遮蔽词的上下文由其左侧的所有词组成。对于一个从右到左的单向 LM \text{LM} LM,上下文是由右边的单词组成。对于双向 LM \text{LM} LM,上下文是由左和右两边的单词组成。对于sequence-to-sequence LM \text{LM} LM,目标序列中将要被预测单词的上下是由源序列中的所有单词和目标序列中右侧单词组成。
类似于 BERT \text{BERT} BERT,预训练 UniLM \text{UniLM} UniLM可以被微调来适应各种下游任务。不同于 BERT \text{BERT} BERT主要用于 NLU \text{NLU} NLU任务, UniLM \text{UniLM} UniLM可以配置不同类型的自注意力机制来聚合不同类型的上下文,其可以同时用于 NLU \text{NLU} NLU和 NLG \text{NLG} NLG任务。
提出了 UniLM \text{UniLM} UniLM有三个优点。首先,统一的预训练过程带来了用于共享参数和不同类型 LM \text{LM} LM架构的单一 Transformer LM \text{Transformer LM} Transformer LM,缓解了独立训练和托管多个 LM \text{LM} LM的需求。第二,共享参数使得学习到的文本表示更具通用性,因为它们联合优化了不同的语言模型目标函数。第三,除了应用于 NLU \text{NLU} NLU任务, UniLM \text{UniLM} UniLM可以用作sequence-to-sequence LM任务,使其天然适合 NLG \text{NLG} NLG,例如摘要和问题生成。
二、统一语言模型预训练
给定一个输入序列 x = x 1 … x ∣ x ∣ x=x_1\dots x_{|x|} x=x1…x∣x∣, UniLM \text{UniLM} UniLM为每个token获得上下文向量表示。如上图所示,使用若干个无监督语言建模目标函数来预训练优化共享 Transformer \text{Transformer} Transformer网络,即单向 LM \text{LM} LM、双向 LM \text{LM} LM和sequence-to-sequence LM \text{LM} LM。为了控制将要被预测单词的上下文,利用了不同的自注意力mask策略。

1. 输入表示
输入 x x x是一个单词序列,其是用于单向 LMs \text{LMs} LMs的一个文本片段,或者是用于双向 LM \text{LM} LM和sequence-to-sequence LM \text{LM} LM的一对文本片段。在输入的开始处添加特殊的序列开始符 [SOS] \text{[SOS]} [SOS],并在每个片段的结尾添加特定的序列结束符 [EOS] \text{[EOS]} [EOS]。 [EOS] \text{[EOS]} [EOS]不仅能够用于标记 NLU \text{NLU} NLU任务中的句子边界,还可以用于 NLG \text{NLG} NLG任务中模型学习何时结束解码过程。遵循 BERT \text{BERT} BERT的输入表示。文本通过 WordPiece \text{WordPiece} WordPiece被切分为子词单元。对于每个输入的token,其向量表示是通过将对于的token嵌入、位置嵌入和segment嵌入相加求得。因为 UniLM \text{UniLM} UniLM使用多个 LM \text{LM} LM任务训练,segment嵌入扮演着 LM \text{LM} LM标识符的作用,即使用不同的segment嵌入使用不同的 LM \text{LM} LM目标函数。
2. 主干网络:多层 Transformer \text{Transformer} Transformer
输入向量 { x i } i = 1 ∣ x ∣ \{\textbf{x}_i\}_{i=1}^{|x|} {xi}i=1∣x∣被合并为 H 0 = [ x 1 , … , x ∣ x ∣ ] \textbf{H}^0=[\textbf{x}_1,\dots,\textbf{x}_{|x|}] H0=[x1,…,x∣x∣],然后使用 L L L层的 Transformer \text{Transformer} Transformer H l = Transformer l ( H l − 1 ) , l ∈ [ 1 , L ] \textbf{H}^l=\text{Transformer}_l(\textbf{H}^{l-1}),l\in[1,L] Hl=Transformerl(Hl−1),l∈[1,L]将其编码为不同抽象等级的上下文表示 H l = [ h 1 l , … , h ∣ x ∣ l ] \textbf{H}^l=[\textbf{h}_1^l,\dots,\textbf{h}_{|x|}^l] Hl=[h1l,…,h∣x∣l]。在每个 Transformer \text{Transformer} Transformer块,多自注意力头被用于聚合前一层的输出向量。对于第 l l l层 Transformer \text{Transformer} Transformer,自注意力头 A l \text{A}_l Al的输出计算如下:
Q = H l − 1 W l Q , K = H l − 1 W l K , V = H l − 1 W l V (1) \textbf{Q}=\textbf{H}^{l-1}\textbf{W}_l^Q,\quad \textbf{K}=\textbf{H}^{l-1}\textbf{W}_l^K,\quad\textbf{V}=\textbf{H}^{l-1}\textbf{W}_l^V \tag{1} Q=Hl−1WlQ,K=Hl−1WlK,V=Hl−1WlV(1)
M i j = { 0 , allow to attend − ∞ , prevent from attending (2) \textbf{M}_{ij}= \begin{cases} 0,\quad \text{allow to attend} \tag{2}\\ -\infty,\quad \text{prevent from attending} \end{cases} Mij={0,allow to attend−∞,prevent from attending(2)
A l = softmax ( QK ⊤ d k + M ) V l (3) \textbf{A}_l=\text{softmax}(\frac{\textbf{QK}^\top}{\sqrt{d_k}}+\textbf{M})\textbf{V}_l \tag{3} Al=softmax(dkQK⊤+M)Vl(3)
其中,前一层的输出 H l − 1 ∈ R ∣ x ∣ × d h \textbf{H}^{l-1}\in\mathbb{R}^{|x|\times d_h} Hl−1∈R∣x∣×dh使用参数矩阵 W l Q , W l K , W l V ∈ R d h × d k \textbf{W}_l^Q,\textbf{W}_l^K,\textbf{W}_l^V\in\mathbb{R}^{d_h\times d_k} WlQ,WlK,WlV∈Rdh×dk来线性投影为queries、keys、values,掩码矩阵 M ∈ R ∣ x ∣ × ∣ x ∣ \textbf{M}\in\mathbb{R}^{|x|\times|x|} M∈R∣x∣×∣x∣来决定一对tokens是由能相关影响。
使用不同的掩码矩阵 M \textbf{M} M来控制一个token能够见到的上下文。采用双向 LM \text{LM} LM作为例子。掩码矩阵的所有元素为0,表示所有的tokens都能够相关访问。
3. 预训练目标函数
使用4中不同的完型填空任务来预训练 UniLM \text{UniLM} UniLM。在完型填空任务中,随机选择输入中的一些 WordPiece \text{WordPiece} WordPiece tokens,并使用[MASK]进行替换。然后,通过 Transformer \text{Transformer} Transformer计算其对应的输出向量并将其送入 softmax \text{softmax} softmax来预测遮蔽的token。 UniLM \text{UniLM} UniLM的参数是通过最小化预测token和原始token的交叉熵损失函数进行学习。值得注意的是,完型填空任务使得所有的 LMs \text{LMs} LMs使用相同的训练程序成为可能。
3.1 单向 LM \text{LM} LM
使用left-to-right和right-to-left两个 LM \text{LM} LM目标函数。以left-to-right LM \text{LM} LM为例。每个token的表示都仅编码其本身和左边的上下文。举例来说,为了预测 x 1 x 2 [MASK] x 4 x_1x_2\text{[MASK]}x_4 x1x2[MASK]x4的遮蔽token,仅会考虑 x 1 , x 2 x_1,x_2 x1,x2和其本身。这是通过对自注意力掩码 M \textbf{M} M使用三角来完成的,其中自注意力掩码的上三角部分被设置为 − ∞ -\infty −∞,其他的元素为0。
3.2 双向 LM \text{LM} LM
双向 LM \text{LM} LM允许所有的token相关访问。其从两个方向编码上下文信息,并能比单向生成更好的上下文表示。正如等式(2)描述,自注意力掩码 M \textbf{M} M是一个0矩阵,允许每个token能够访问输入序列的所有位置。
3.3 序列到序列 LM \text{LM} LM
对于预测,在源片段中的token能够在片段内访问双向token,而目标片段中的token只能访问左边的上下文和源片段的所有tokens。举例来说,给定一个源片段 t 1 t 2 t_1t_2 t1t2和目标片段 t 3 t 4 t 5 t_3t_4t_5 t3t4t5,将 [SOS] t 1 t 2 [EOS] t 3 t 4 t 5 [EOS] \text{[SOS]}t_1t_2\text{[EOS]}t_3t_4t_5\text{[EOS]} [SOS]t1t2[EOS]t3t4t5[EOS]输入模型。 t 1 t_1 t1和 t 2 t_2 t2可以访问前4个tokens,包括 [SOS] \text{[SOS]} [SOS]和 [EOS] \text{[EOS]} [EOS], t 4 t_4 t4则仅能访问前六个tokens。
上图展示了sequence-to-sequence LM \text{LM} LM目标函数使用的自注意力掩码 M \textbf{M} M。 M \textbf{M} M的左半部分设置为0,所有的token都可以访问第一个片段。右上部分被设置为 − ∞ -\infty −∞来阻塞源片段自目标片段的注意力。此外,对于右下部分,设置右上三角部分为 − ∞ -\infty −∞且其他元素为0。
在训练过程中,随机选择两个文本片段中的tokens,并使用特殊的[MASK]进行替换。模型学习来恢复遮蔽的tokens。因为在训练过程中源片段和目标片段被打包成连续的文本序列,然后鼓励模型来学习两个片段的关系。为了更好的预测目标片段的tokens, UniLM \text{UniLM} UniLM学习对源片段进行高效编码。因此,用于sequence-to-sequence LM \text{LM} LM的完型填空任务,也称为encoder-decoder模型,同时预训练双向encoder和一个单向decoder。用作encoder-decoder模型预训练模型能够轻易应用于广泛的文本生成任务。
4. 在下游 NLU \text{NLU} NLU和 NLG \text{NLG} NLG任务上微调
对于 NLU \text{NLU} NLU任务,微调 UniLM \text{UniLM} UniLM作为双向 Transformer \text{Transformer} Transformer编码器,类似于 BERT \text{BERT} BERT。以文本分类为例。使用[SOS]的编码向量作为输入的表示,记为 h 1 L \textbf{h}_1^L h1L,并将其送入随机初始化的softmax分类器。类别概率计算为 softmax ( h 1 L W C ) \text{softmax}(\textbf{h}_1^L\textbf{W}^C) softmax(h1LWC),其中 W C ∈ R d h × C \textbf{W}^C\in\mathbb{R}^{d_h\times C} WC∈Rdh×C是参数矩阵, C C C是类别数量。
对于 NLG \text{NLG} NLG任务,使用sequence-to-sequence任务为例。微调过程类似于使用注意力掩码的预训练。令 S 1 S1 S1和 S 2 S2 S2表示源序列和目标序列。使用特殊的token将其连在一起,形成输入 [SOS]S1[EOS]S2[EOS] \text{[SOS]S1[EOS]S2[EOS]} [SOS]S1[EOS]S2[EOS]。通过随机遮蔽目标序列中的tokens来微调模型,并学习恢复遮蔽的tokens。值得注意的是, [EOS] \text{[EOS]} [EOS]标记这目标序列的结束,其也可以在微调过程中被遮蔽,因为当这种情况发生时,模型学习何时产生 [EOS] \text{[EOS]} [EOS]来终止目标序列的生成过程。
三、实验
1. 摘要

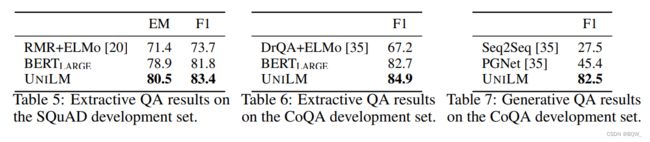
2. 问答
3. 问题生成

4. 响应生成
