Pandas数据分析:快速图表可视化各类操作详解+实例代码(三)
目录
前言
一、六边形箱图
二、饼图
三、缺失数据绘制处理
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
前言
一般我们做数据挖掘或者是数据分析,再或者是大数据开发提取数据库里面的数据时候,难免只能拿着表格数据左看右看,内心总是希望能够根据自己所想立马生成一张数据可视化的图表来更直观的呈现数据。而当我们想要进行数据可视化的时候,往往需要调用很多的库与函数,还需要数据转换以及大量的代码处理编写。这都是十分繁琐的工作,确实只为了数据可视化我们不需要实现数据可视化的工程编程,这都是数据分析师以及拥有专业的报表工具来做的事情,日常分析的话我们根据自己的需求直接进行快速出图即可,而Pandas正好就带有这个功能,当然还是依赖matplotlib库的,只不过将代码压缩更容易实现。下面就让我们来了解一下如何快速出图。
Pandas数据分析:快速图表可视化各类操作详解+实例代码(一)
Pandas数据分析:快速图表可视化各类操作详解+实例代码(二)
Pandas数据分析系列专栏已经更新了很久了,基本覆盖到使用pandas处理日常业务以及常规的数据分析方方面面的问题。从基础的数据结构逐步入门到处理各类数据以及专业的pandas常用函数讲解都花费了大量时间和心思创作,如果大家有需要从事数据分析或者大数据开发的朋友推荐订阅专栏,将在第一时间学习到Pandas数据分析最实用常用的知识。此篇博客篇幅较长,涉及到数据可视化等各类操作,值得细读实践一番,我会将Pandas的精华部分挑出细讲实践。博主会长期维护博文,有错误或者疑惑可以在评论区指出,感谢大家的支持。
一、六边形箱图
可以通过DataFrame.plot.hexbin()来创建一个六边形箱图。如果数据过于密集,无法单独绘制每个点,则Hexbin图可以作为散点图的有用替代方案。
这里我们不用上一个数据集,换用一个数据集,就用这次2022国赛E题的数据来展示:
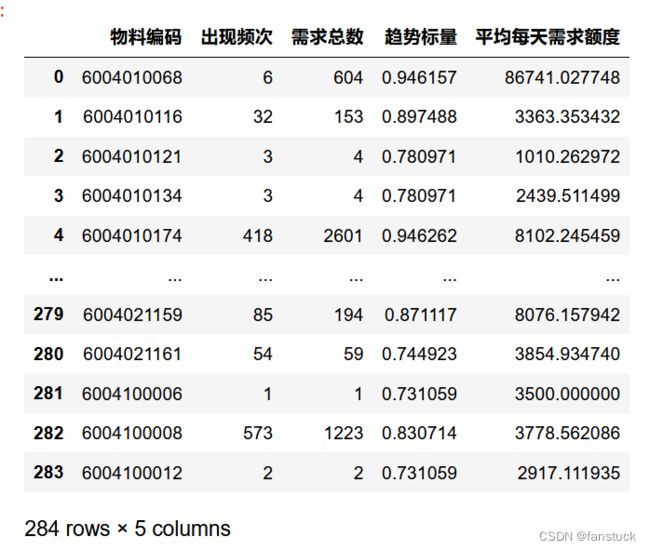
df_example[['出现频次','需求总数']].plot.hexbin(x='出现频次',y='需求总数',gridsize=25) 
效果不是很好,因为上限和下限都差的很多,用集中的数据集更好展现效果。
df = pd.DataFrame(np.random.randn(1000, 2), columns=["a", "b"])
df["b"] = df["b"] + np.arange(1000)
df.plot.hexbin(x="a", y="b", gridsize=25);
关键字参数gridsize:它控制x方向六边形的数量,默认值为100。网格越大,箱子越小。
df.plot.hexbin(x="a", y="b", gridsize=10); 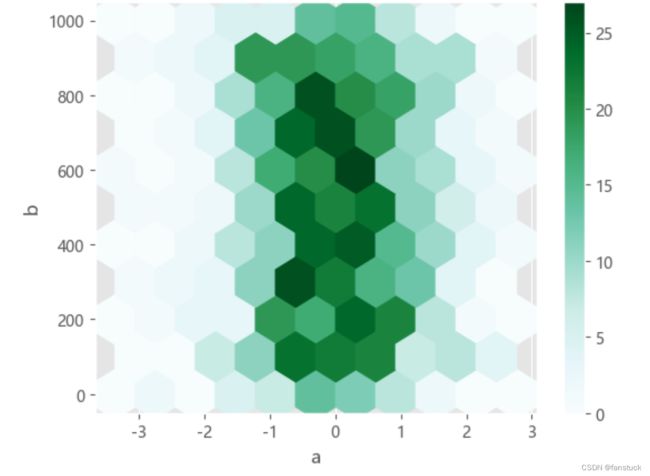
默认情况下,计算每个(x,y)点周围计数的直方图。您可以通过向C和reduce_C_function参数传递值来指定替代聚合。C指定每个(x,y)点的值,reduce_C_function是一个参数的函数,它将bin中的所有值聚合为一个数字(例如mean、max、sum、std)。在本例中,位置由a列和b列给出,而值由z列给出。这些箱子通过NumPy的max函数进行聚合。
df = pd.DataFrame(np.random.randn(1000, 2), columns=["a", "b"])
df["b"] = df["b"] + np.arange(1000)
df["z"] = np.random.uniform(0, 3, 1000)
df.plot.hexbin(x="a", y="b", C="z", reduce_C_function=np.max, gridsize=25); 
二、饼图
使用DataFrame.plot.pie()或者是Series.plot.pie()可以创建饼图。如果数据包含任何NaN,则它们将自动填充为0。如果数据中有任何负值,则会引发ValueError。
series = pd.Series(3 * np.random.rand(4), index=["a", "b", "c", "d"], name="series")
series.plot.pie(figsize=(6, 6)); 
对于饼图,最好使用正方形图形,即图形纵横比1。可以创建宽度和高度相等的图形,或者在绘图后通过调用ax强制使纵横比相等。返回的axes对象上的ax.set_aspect('equal')。
带有DataFrame的饼图需要通过y参数或subplots=True指定目标列。当指定y时,将绘制所选列的饼图。如果指定subplots=True,则每个列的饼图都将绘制为subplots。默认情况下,将在每个饼图中绘制图例;指定legend=False将其隐藏。
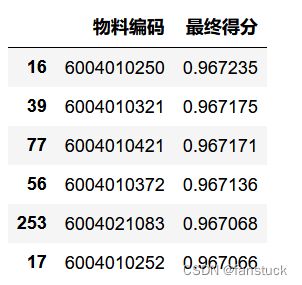
q1_1_result['最终得分'].plot.pie(labels=q1_1_result['物料编码'].values,figsize=(6, 6),autopct="%.2f") 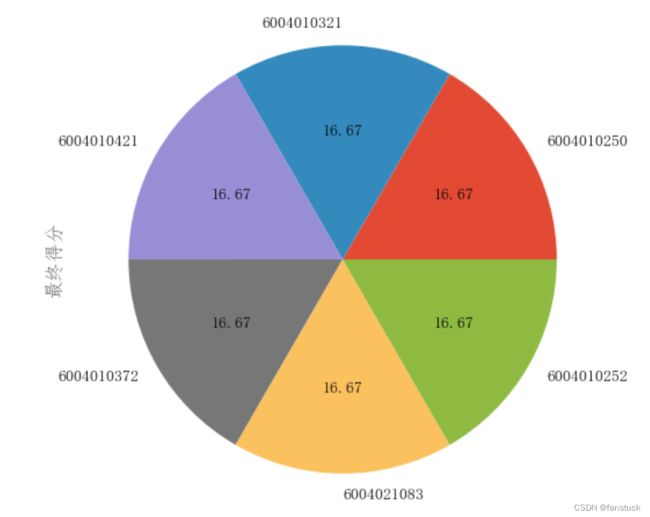
df_flow_mark[['湿度','体感温度']].plot.pie(subplots=True, figsize=(8, 4)); 
可以使用标签和颜色关键字指定每个按钮的标签和颜色。
大多数Pandas图都使用标签和颜色参数(注意这些参数上没有“s”)。与matplotlib.pyplot一致。pie()必须使用标签和颜色。
如果要隐藏楔体标签,指定labels=None。如果指定了fontsize,则该值将应用于楔形标签。此外,matplotlib.pyplot支持的其他关键字,可以使用pie()。
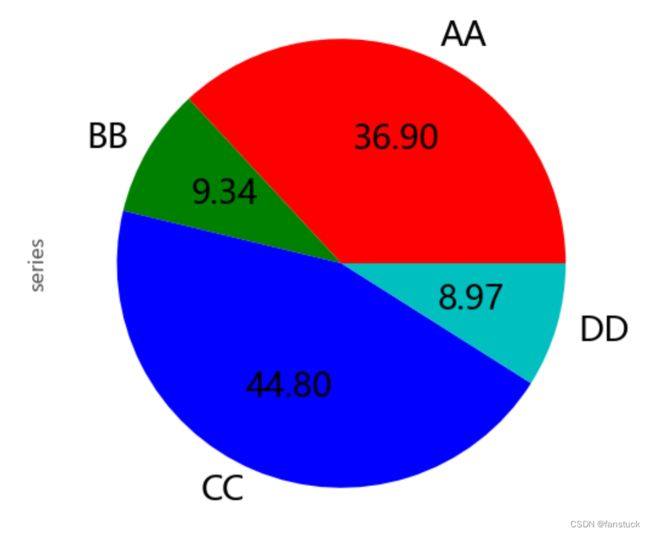
series.plot.pie(
labels=["AA", "BB", "CC", "DD"],
colors=["r", "g", "b", "c"],
autopct="%.2f",
fontsize=20,
figsize=(6, 6),
); 
如果传递的值的总和小于1.0,则会重新缩放这些值,使其总和为1。
series = pd.Series([0.1] * 4, index=["a", "b", "c", "d"], name="series2")
series.plot.pie(figsize=(6, 6)); 
三、缺失数据绘制处理
Pandas在绘制包含缺失数据的DataFrame或Series时尽可能完全填充。根据打印类型,删除、省略或填充缺少的值。

如果这些默认值中有任何一个不是您想要的,或者如果您想明确说明如何处理缺少的值,请考虑在绘制之前使用fillna()或dropna()。
那么到目前为止所有常用的绘图形式都讲完了。接下来会对plot的多样性组合表和特殊形式表进行补充,以及一些其他类数据的绘图进行总结:




点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见