数据挖掘经典十大算法_KNN算法
数据挖掘经典十大算法_KNN算法
一、从案例入手
已知一组数据:
| 电影名称 | 亲热次数 | 打斗次数 | 电影类型 |
|---|---|---|---|
| California Man | 104 | 3 | 爱情电影 |
| He is Not Really into Dudes | 100 | 2 | 爱情电影 |
| Beautiful Woman | 81 | 1 | 爱情电影 |
| Kevin Longblade | 10 | 101 | 动作电影 |
| Robo Slayer 3000 | 5 | 99 | 动作电影 |
| Amped Ⅱ | 2 | 98 | 动作电影 |
| 未知 | 90 | 18 | ? |
(一)划分训练集与测试集
训练集
| 电影名称 | 亲热次数 | 打斗次数 | 电影类型 |
|---|---|---|---|
| California Man | 104 | 3 | 爱情电影 |
| He is Not Really into Dudes | 100 | 2 | 爱情电影 |
| Beautiful Woman | 81 | 1 | 爱情电影 |
| Kevin Longblade | 10 | 101 | 动作电影 |
| Robo Slayer 3000 | 5 | 99 | 动作电影 |
| Amped Ⅱ | 2 | 98 | 动作电影 |
测试集
| 电影名称 | 亲热次数 | 打斗次数 | 电影类型 |
|---|---|---|---|
| 未知 | 90 | 18 | ? |
(二)计算未知样本和每个训练集样本的距离(欧氏距离)
![]()
(三)设定参数,k值
设定K = 3
(四)将距离升序排列
1.Beautiful Woman
2.He is Not Really into Dudes
3.California Man
4.Kevin Longblade
5.Robo Slayer 3000
6.Amped Ⅱ
(五)选取距离最小的k个点
1.Beautiful Woman
2.He is Not Really into Dudes
3.California Man
(六)统计前k个最近邻样本点所在类别出现的次数
爱情电影 3次 动作电影 0 次
(七)选择出现频率最大的类别作为未知样本的类别
未知电影 为 爱情电影类型
二、从程序理解
(一)导入训练数据
import numpy as np
import matplotlib.pyplot as plt
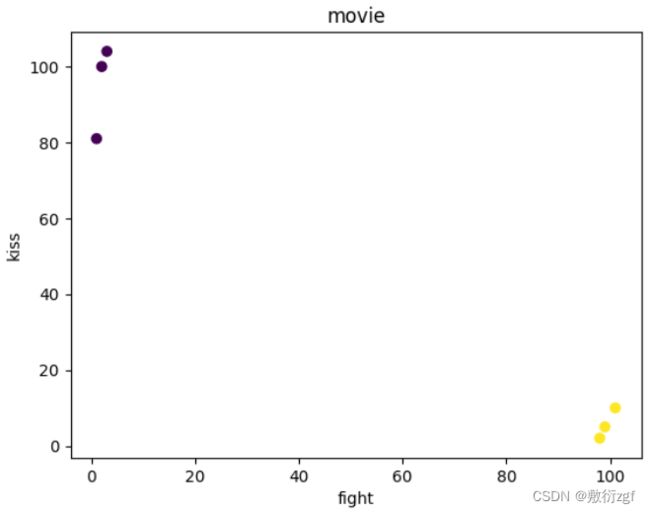
fight = [3,2,1,101,99,98]
kiss = [104,100,81,10,5,2]
filmtype = [1,1,1,2,2,2]
plt.scatter(fight,kiss,c=filmtype)
plt.xlabel('fight')
plt.ylabel('kiss')
plt.title('movie')
plt.show()
x = np.array([fight,kiss])
x = x.T # 转置
y = np.array(filmtype)
print(x)
print(y)
x 转置后的矩阵,每一行代表一条数据样本

y 矩阵
![]()
(二)计算测试数据与训练数据的欧氏距离
xx = np.array([18,90]) # 将测试数据转换为array
# 计算欧氏距离
# sum(0) 按列求和 sum(1)按行求和 由于前面将矩阵进行转置 所以每一行代表一条样本
dist = (((x-xx)**2).sum(1))**0.5
print(dist)

(三)将距离升序排序
sortedDist = dist.argsort()
print(sortedDist) # 输出的是排序索引
![]()
(四)设置K值,选取距离最小的k个点,统计前k个点所在类别出现的次数
k = 4
classCount = {} # 建立一个空的字典来统计每种类型出现的次数
for i in range(k):
voteLabel = y[sortedDist[i]] # 利用排序索引映射到y矩阵中,获得索引对应的电影类型
classCount[voteLabel] = classCount.get(voteLabel,0) + 1 # 利用get函数取键值 并在基础上加1达到计数效果 累加操作
print('class:count',classCount)
![]()
(五)多数表决,输出结果
maxType = 0 # 设置初始值
maxCount = -1 # 设置初始值
for key , value in classCount.items(): # items() 遍历字典
if value > maxCount:
maxType = key
maxCount = value
print('output:' , maxType)
![]()
三、封装KNN程序
import numpy as np
def knn(inX,dataSet,labels,k):
dist = (((dataSet-inX)**2).sum(1))**0.5
sortedDist = dist.argsort()
classCount = {}
for i in range(k):
voteLabel = labels[sortedDist[i]] # 利用排序索引映射到y矩阵中,获得索引对应的电影类型
classCount[voteLabel] = classCount.get(voteLabel,0) + 1 # 利用get函数取键值 并在基础上加1达到计数效果
maxType = 0 # 设置初始值
maxCount = -1 # 设置初始值
for key , value in classCount.items(): # items() 遍历字典
if value > maxCount:
maxType = key
maxCount = value
return maxType
import numpy as np
import matplotlib.pyplot as plt
import knn as K
fight = [3,2,1,101,99,98]
kiss = [104,100,81,10,5,2]
filmtype = [1,1,1,2,2,2]
x = np.array([fight,kiss])
x = x.T
y = np.array(filmtype)
xx = np.array([18,90]) # 将测试数据转换为array
result = k.knn(xx,x,y,4)
print(result)