浅析MySQL死锁检测
MySQL发生死锁时,通过show engine innodb status;命令并不能看到事务中引起死锁的所有SQL语句。
死锁排查起来就比较麻烦,需要查询events_statements_%表,来获取SQL,同时需要对业务也比较熟悉,这样能分析出造成死锁的语句。
本着探究的目的,来看下MySQL死锁检测实现及为何无法打印出触发死锁的所有SQL语句。
Lock bitmap
截取show engine innodb status;命令查询锁信息时一段内容:
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 124 page no 4 n bits 80 index idx_id of table `dhy`.`t` trx id 45909 lock_mode X waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
0: len 4; hex 80000002; asc ;;
1: len 6; hex 000000000601; asc ;;
space id、page no、n bits(lock_rec_t结构体) 通过这三个可以定位到某一条记录,这里对应的就是heap_no = 2这条。n_bits是一个bitmap,用来记录行记录上是否持有Lock。
lock_t 结构用来描述锁信息的,通过n_bits可以将lock(lock_t类型的变量,下文中都将这样描述)与行记录的对应起来。lock_rec_t结构如下:
struct lock_rec_t {
ib_uint32_t space; /*!< space id */
ib_uint32_t page_no; /*!< page number */
ib_uint32_t n_bits; /*!< number of bits in the lock
bitmap; NOTE: the lock bitmap is
placed immediately after the
lock struct */
/** Print the record lock into the given output stream
@param[in,out] out the output stream
@return the given output stream. */
std::ostream& print(std::ostream& out) const;
};
n_bits 的大小分配为 : (1+ (记录锁+ 64) / 8) * 8
size大小:
static size_t lock_size(const page_t* page) {
ulint n_recs = page_dir_get_n_heap(page);
/* Make lock bitmap bigger by a safety margin */
return(1 + ((n_recs + LOCK_PAGE_BITMAP_MARGIN) / 8));
}
这么大的内存空间分配在lock内存之后的:
ulint n_bytes = size + sizeof(*lock);
mem_heap_t* heap = trx->lock.lock_heap;
lock = reinterpret_cast(mem_heap_alloc(heap, n_bytes));
在lock_rec_set_nth_bit中,设置bitmap位图信息:
lock_rec_set_nth_bit(
/*=================*/
lock_t* lock, /*!< in: record lock */
ulint i) /*!< in: index of the bit */
{
ulint byte_index;
ulint bit_index;
byte_index = i / 8; //标识第几个字节
bit_index = i % 8; //标识字节中的第几位
((byte*) &lock[1])[byte_index] |= 1 << bit_index; //将对应byte上相应的bit位设置为1
++lock->trx->lock.n_rec_locks;
}
创建好的lock都会被添加到HASH表中,space_no与page_no相同的lock会被分配到同一个HASH桶中
ulint key = m_rec_id.fold();
++lock->index->table->n_rec_locks;
HASH_INSERT(lock_t, hash, lock_hash_get(m_mode), key, lock);
/**
@return the "folded" value of {space, page_no} */
ulint fold() const
{
return(m_fold);
}
判断lock上bitmap对应的bit位是否存在锁:
UNIV_INLINE
ibool
lock_rec_get_nth_bit( /*=================*/
const lock_t* lock, /*!< in: record lock */
ulint i) /*!< in: index of the bit */ {
const byte* b;
if (i >= lock->un_member.rec_lock.n_bits) {
return(FALSE);
}
b = ((const byte*) &lock[1]) + (i / 8); //根据i(也就是heap_no)计算出是lock之后的第几个字节
return(1 & *b >> (i % 8)); //判断对应的bit位上是否为1
}
死锁检测
先介绍几个重要点:
-
变量:
const lock_t* m_wait_lock; // 想持有的锁
const trx_t* m_start // 直译过来是:正在以不兼容模式请求锁定的联接事务,举例说明下比较好理解:
| session1 | session2 |
|---|---|
| begin; | begin; |
| lock:a | |
| lock:b | |
| lock:b | |
| lock:a |
m_start 就是对应session2这个事务
ulint heap_no // 记录对应的物理位置号
-
函数get_first_lock // 获取m_wait_lock对应记录上的第一个lock, 例如上面例子中,就是获取session1中对a这条记录持有的lock信息。
-
精简后流程如下:
DeadlockChecker::get_first_lock(ulint* heap_no) const
{
const lock_t* lock = m_wait_lock;
if (lock_get_type_low(lock) == LOCK_REC) {
hash_table_t* lock_hash;
lock_hash = lock->type_mode & LOCK_PREDICATE
? lock_sys->prdt_hash
: lock_sys->rec_hash;
/* We are only interested in records that match the heap_no. */
*heap_no = lock_rec_find_set_bit(lock); // 查找lock对应的heap_no
/* Find the locks on the page. */
lock = lock_rec_get_first_on_page_addr(
lock_hash,
lock->un_member.rec_lock.space,
lock->un_member.rec_lock.page_no); //找出page上的第一个lock
/* Position on the first lock on the physical record.*/
if (!lock_rec_get_nth_bit(lock, *heap_no)) { //如果lock的bitmap对应bit位上存在锁,则返回lock,否则查找下一个lock,直到对应bit位上存在锁
lock = lock_rec_get_next_const(*heap_no, lock);
}
} else {
/* Table locks don't care about the heap_no. */
*heap_no = ULINT_UNDEFINED;
dict_table_t* table = lock->un_member.tab_lock.table;
lock = UT_LIST_GET_FIRST(table->locks);
}
return(lock);
}
死锁检测核心函数在DeadlockChecker::search()中,会做以下处理:
- 首先获取m_wait_lock对应记录上的第一个lock
const lock_t* lock = get_first_lock(&heap_no);
- 进入一个循环,这里代码比较多,直接贴代码不太直观,放一张流程图
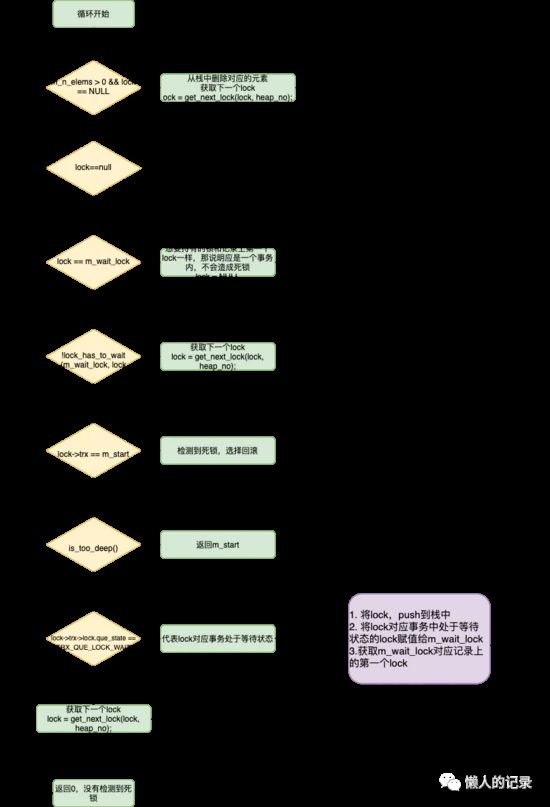
流程较长,举个例子对照上图看下:
| session1 | session2 |
|---|---|
| begin; | begin; |
| lock:a | |
| lock:b | |
| lock:b //blocking | |
| lock:a |
进入死锁检测时:
-
m_start:session2事务信息
-
lock:m_wait_lock对应记录上的第一个lock,对应session1对a记录持有的锁
-
m_wait_lock:session2中对a想要持有的锁
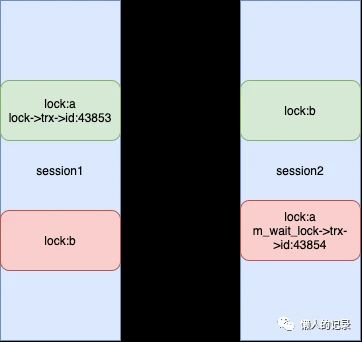
进入循环后,只满足lock->trx->lock.que_state == TRX_QUE_LOCK_WAIT这个条件(也代表m_wait_lock和lock是发生锁等待了),步骤7中将m_wait_lock被赋值后即为session2中对b想要持有的锁,lock变为session2对b持有的锁,再次进入循环。
这时lock->trx == m_start(都为session2),即检测出死锁。如下图所示:
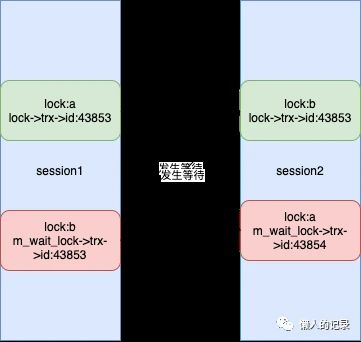
死锁日志
死锁日志只能看到事务中最后一个SQL语句,因为每次执行完语句后m_query_string变量都会被reset_query(),要实现就需要一个SQL语句和lock的对应关系,将每次执行的SQL保留起来。
这块还涉及到死锁日志的一个参数:
- innodb_print_all_deadlocks :会将死锁信息打印到errorlock中,最好将此参数设置下,能够保留死锁日志,方便查看因为show engine innodb status;只会保留最后一个死锁日志的信息,原因是mysql会在tmp目录下创建一个ib开头的临时文件,每次重启后都会重建。
结语
这里梳理了下死锁检测的流程,由于水平有限,文章可能存在不正确地方,望指正。