Kubernetes 进阶训练营 网络
网络
- Service
-
- 三种IP
- 定义 Service
- kube-proxy
- 服务类型
- 获取客户端 IP
- DNS
-
- 给 Pod 添加 DNS 记录
- Ingress
-
- 资源对象
- 定义
-
- rules
- Resource
- pathType
- IngressClass
- TLS
- Ingress-nginx
-
- 运行原理
- 安装
- 第一个示例❤
- Nginx配置
-
- Basic Auth
- URL Rewrite
- 灰度发布
- HTTPS
- 全局配置
- TCP与UDP
- Traefik
- Gateway API
- APISIX
Service
一些服务发现的工具,比如 Consul、ZooKeeper 还有我们熟悉的 etcd 等工具,有了这些工具过后我们就可以只需要把我们的服务注册到这些服务发现中心去就可以
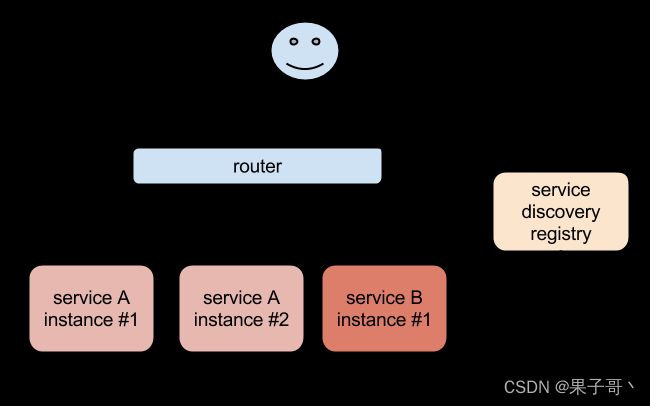
同样的,要解决我们上面遇到的问题是不是实现一个服务发现的工具也可以解决?没错的,当我们 Pod 被销毁或者新建过后,我们可以把这个 Pod 的地址注册到这个服务发现中心去就可以,但是这样的话我们的前端应用就不能直接去连接后台的 Pod 集合了,应该连接到一个能够做服务发现的中间件上面,对吧?
为解决这个问题 Kubernetes 就为我们提供了这样的一个对象 - Service,Service 是一种抽象的对象,它定义了一组 Pod 的逻辑集合和一个用于访问它们的策略,其实这个概念和微服务非常类似。一个 Serivce 下面包含的 Pod 集合是由 Label Selector 来决定的。
比如我们上面的例子,假如我们后端运行了3个副本,这些副本都是可以替代的,因为前端并不关心它们使用的是哪一个后端服务。尽管由于各种原因后端的 Pod 集合会发送变化,但是前端却不需要知道这些变化,也不需要自己用一个列表来记录这些后端的服务,Service 的这种抽象就可以帮我们达到这种解耦的目的。
三种IP
在继续往下学习 Service 之前,我们需要先弄明白 Kubernetes 系统中的三种IP,因为经常有同学混乱。
- Node IP:Node 节点的 IP 地址
- Pod IP: Pod 的 IP 地址
- Cluster IP: Service 的 IP 地址
首先,Node IP 是 Kubernetes 集群中节点的物理网卡 IP 地址(一般为内网),所有属于这个网络的服务器之间都可以直接通信,所以 Kubernetes 集群外要想访问 Kubernetes 集群内部的某个节点或者服务,肯定得通过 Node IP 进行通信(这个时候一般是通过外网 IP 了)
然后 Pod IP 是每个 Pod 的 IP 地址,它是网络插件进行分配的
最后 Cluster IP 是一个虚拟的 IP,仅仅作用于 Kubernetes Service 这个对象,由 Kubernetes 自己来进行管理和分配地址。
定义 Service
定义 Service 的方式和我们前面定义的各种资源对象的方式类型,例如,假定我们有一组 Pod 服务,它们对外暴露了 8080 端口,同时都被打上了 app=myapp 这样的标签,那么我们就可以像下面这样来定义一个 Service 对象:
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 8080
name: myapp-http
然后通过的使用 kubectl create -f myservice.yaml 就可以创建一个名为 myservice 的 Service 对象,它会将请求代理到使用 TCP 端口为 8080,具有标签 app=myapp 的 Pod 上,这个 Service 会被系统分配一个我们上面说的 Cluster IP,该 Service 还会持续的监听 selector 下面的 Pod,会把这些 Pod 信息更新到一个名为 myservice 的Endpoints 对象上去,这个对象就类似于我们上面说的 Pod 集合了。
另外 Service 能够支持 TCP 和 UDP 协议,默认是 TCP 协议。
kube-proxy
前面我们讲到过,在 Kubernetes 集群中,每个 Node 会运行一个 kube-proxy 进程, 负责为 Service 实现一种 VIP(虚拟 IP,就是我们上面说的 clusterIP)的代理形式,现在的 Kubernetes 中默认是使用的 iptables 这种模式来代理。
iptables
这种模式,kube-proxy 会 watch apiserver 对 Service 对象和 Endpoints 对象的添加和移除。对每个 Service,它会添加上 iptables 规则,从而捕获到达该 Service 的 clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某一个 Pod 上面。我们还可以使用 Pod readiness 探针 验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端,这样做意味着可以避免将流量通过 kube-proxy 发送到已知失败的 Pod 中,所以对于线上的应用来说一定要做 readiness 探针。
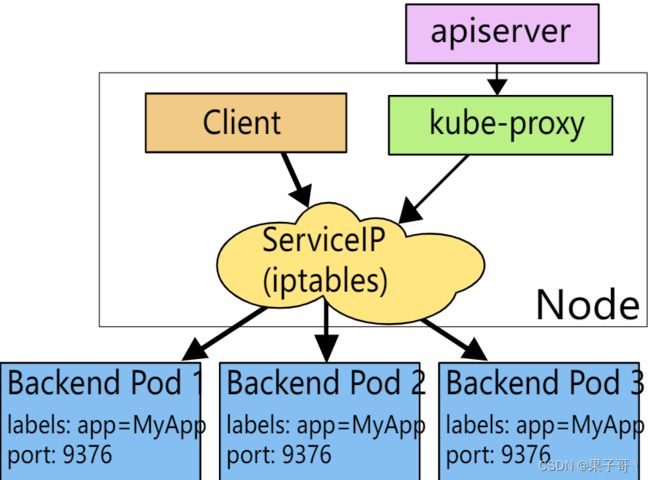
iptables 模式的 kube-proxy 默认的策略是,随机选择一个后端 Pod。
比如当创建 backend Service 时,Kubernetes 会给它指派一个虚拟 IP 地址,比如 10.0.0.1。假设 Service 的端口是 1234,该 Service 会被集群中所有的 kube-proxy 实例观察到。当 kube-proxy 看到一个新的 Service,它会安装一系列的 iptables 规则,从 VIP 重定向到 per-Service 规则。 该 per-Service 规则连接到 per-Endpoint 规则,该 per-Endpoint 规则会重定向(目标 NAT)到后端的 Pod。
ipvs
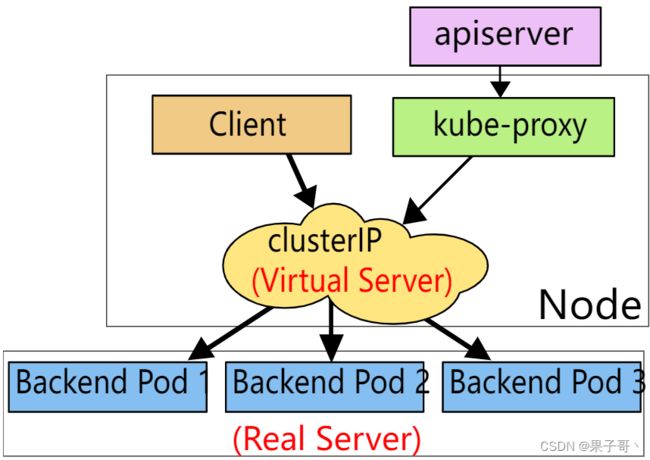
除了 iptables 模式之外,kubernetes 也支持 ipvs 模式,在 ipvs 模式下,kube-proxy watch Kubernetes 服务和端点,调用 netlink 接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。该控制循环可确保 IPVS 状态与所需状态匹配。访问服务时,IPVS 将流量定向到后端 Pod 之一。
IPVS 代理模式基于类似于 iptables 模式的 netfilter 钩子函数,但是使用哈希表作为基础数据结构,并且在内核空间中工作。 所以与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。所以对于较大规模的集群会使用 ipvs 模式的 kube-proxy,只需要满足节点上运行 ipvs 的条件,然后我们就可以直接将 kube-proxy 的模式修改为 ipvs,如果不满足运行条件会自动降级为 iptables 模式,现在都推荐使用 ipvs 模式,可以大幅度提高 Service 性能。
IPVS 提供了更多选项来平衡后端 Pod 的流量,默认是 rr,有如下一些策略:
- rr: round-robin
- lc: least connection (smallest number of open connections)
- dh: destination hashing
- sh: source hashing
- sed: shortest expected delay
- nq: never queue
不过现在只能整体修改策略,可以通过 kube-proxy 中配置 –ipvs-scheduler 参数来实现,暂时不支持特定的 Service 进行配置。
我们也可以实现基于客户端 IP 的会话亲和性,可以将 service.spec.sessionAffinity 的值设置为 “ClientIP” (默认值为 “None”)即可,此外还可以通过适当设置 service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 来设置最大会话停留时间(默认值为 10800 秒,即 3 小时):
apiVersion: v1
kind: Service
spec:
sessionAffinity: ClientIP
...
亲和性
Service 只支持两种形式的会话亲和性服务:None 和 ClientIP,不支持基于 cookie 的会话亲和性,这是因为 Service 不是在 HTTP 层面上工作的,处理的是 TCP 和 UDP 包,并不关心其中的载荷内容,因为 cookie 是 HTTP 协议的一部分,Service 并不知道它们,所有会话亲和性不能基于 Cookie。
服务类型
在定义 Service 的时候可以指定一个自己需要的类型的 Service,如果不指定的话默认是 ClusterIP类型。
我们可以使用的服务类型如下:
- ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的服务类型。
- NodePort:通过每个 Node 节点上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。通过请求 NodeIp:NodePort,可以从集群的外部访问一个 NodePort 服务。
- LoadBalancer:使用云提供商的负载局衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务,这个需要结合具体的云厂商进行操作。
- ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。
NodePort 类型
如果设置 type 的值为 “NodePort”,Kubernetes master 将从给定的配置范围内(默认:30000-32767)分配端口,每个 Node 将从该端口(每个 Node 上的同一端口)代理到 Service。该端口将通过 Service 的 spec.ports[*].nodePort 字段被指定,如果不指定的话会自动生成一个端口。
需要注意的是,Service 将能够通过 spec.ports[].nodePort 和 spec.clusterIp:spec.ports[].port 而对外可见。
接下来我们来给大家创建一个 NodePort 的服务来访问我们前面的 Nginx 服务:(service-nodeport-demo.yaml)
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
name: myapp-http
创建该 Service:
➜ ~ kubectl apply -f service-demo.yaml
然后我们可以查看 Service 对象信息:
➜ ~ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 27d
myservice NodePort 10.104.57.198 80:32560/TCP 14h
我们可以看到 myservice 的 TYPE 类型已经变成了 NodePort,后面的 PORT(S) 部分也多了一个 32560 的映射端口。
ExternalName
ExternalName 是 Service 的特例,它没有 selector,也没有定义任何的端口和 Endpoint。对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
当访问地址 my-service.prod.svc.cluster.local(后面服务发现的时候我们会再深入讲解)时,集群的 DNS 服务将返回一个值为 my.database.example.com 的 CNAME 记录。访问这个服务的工作方式与其它的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。如果后续决定要将数据库迁移到 Kubernetes 集群中,可以启动对应的 Pod,增加合适的 Selector 或 Endpoint,修改 Service 的 type,完全不需要修改调用的代码,这样就完全解耦了。
除了可以直接通过 externalName 指定外部服务的域名之外,我们还可以通过自定义 Endpoints 来创建 Service,前提是 clusterIP=None,名称要和 Service 保持一致,如下所示:
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: port
port: 2379
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s # 名称必须和 Service 一致
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 10.151.30.57 # Service 将连接重定向到 endpoint
ports:
- name: port
port: 2379 # endpoint 的目标端口
上面这个服务就是将外部的 etcd 服务引入到 Kubernetes 集群中来。
获取客户端 IP
通常,当集群内的客户端连接到服务的时候,是支持服务的 Pod 可以获取到客户端的 IP 地址的,但是,当通过节点端口接收到连接时,由于对数据包执行了源网络地址转换(SNAT),因此数据包的源 IP 地址会发生变化,后端的 Pod 无法看到实际的客户端 IP,对于某些应用来说是个问题,比如,nginx 的请求日志就无法获取准确的客户端访问 IP 了,比如下面我们的应用:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
直接创建后可以查看 nginx 服务被自动分配了一个 32761 的 NodePort 端口:
➜ ~ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 28d
nginx NodePort 10.106.190.194 80:32761/TCP 48m
➜ ~ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-54f57cf6bf-nwtjp 1/1 Running 0 3m 10.244.3.15 ydzs-node3
nginx-54f57cf6bf-ptvgs 1/1 Running 0 2m59s 10.244.2.13 ydzs-node2
nginx-54f57cf6bf-xhs8g 1/1 Running 0 2m59s 10.244.1.16 ydzs-node1
我们可以看到这个3个 Pod 被分配到了 3 个不同的节点,这个时候我们通过 master 节点的 NodePort 端口来访问下我们的服务,因为我这里只有 master 节点可以访问外网,这个时候我们查看 nginx 的 Pod 日志可以看到其中获取到的 clientIP 是 10.151.30.11,其实是 master 节点的内网 IP,并不是我们期望的真正的浏览器端访问的 IP 地址:
➜ ~ kubectl logs -f nginx-54f57cf6bf-xhs8g
10.151.30.11 - - [07/Dec/2019:16:44:38 +0800] "GET / HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36" "-"
这个是因为我们 master 节点上并没有对应的 Pod,所以通过 master 节点去访问应用的时候必然需要额外的网络跳转才能到达其他节点上 Pod,在跳转过程中由于对数据包进行了 SNAT,所以看到的是 master 节点的 IP。这个时候我们可以在 Service 设置 externalTrafficPolicy 来减少网络跳数:
spec:
externalTrafficPolicy: Local
如果 Service 中配置了 externalTrafficPolicy=Local,并且通过服务的节点端口来打开外部连接,则 Service 会代理到本地运行的 Pod,如果本地没有本地 Pod 存在,则连接将挂起,比如我们这里设置上该字段更新,这个时候我们去通过 master 节点的 NodePort 访问应用是访问不到的,因为 master 节点上并没有对应的 Pod 运行,所以需要确保负载均衡器将连接转发给至少具有一个 Pod 的节点。
但是需要注意的是使用这个参数有一个缺点,通常情况下,请求都是均匀分布在所有 Pod 上的,但是使用了这个配置的话,情况就有可能不一样了。比如我们有两个节点上运行了 3 个 Pod,假如节点 A 运行一个 Pod,节点 B 运行两个 Pod,如果负载均衡器在两个节点间均衡分布连接,则节点 A 上的 Pod 将接收到所有请求的 50%,但节点 B 上的两个 Pod 每个就只接收 25% 。
由于增加了externalTrafficPolicy: Local这个配置后,接收请求的节点和目标 Pod 都在一个节点上,所以没有额外的网络跳转(不执行 SNAT),所以就可以拿到正确的客户端 IP,如下所示我们把 Pod 都固定到 master 节点上:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
tolerations:
- operator: "Exists"
nodeSelector:
kubernetes.io/hostname: ydzs-master
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
externalTrafficPolicy: Local
selector:
app: nginx
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
更新服务后,然后再通过 NodePort 访问服务可以看到拿到的就是正确的客户端 IP 地址了:
➜ ~ kubectl logs -f nginx-ddc8f997b-ptb7b
182.149.166.11 - - [07/Dec/2019:17:03:43 +0800] "GET / HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36" "-"
DNS
DNS 服务不是一个独立的系统服务,而是作为一种 addon 插件而存在,现在比较推荐的两个插件:kube-dns 和 CoreDNS,实际上在比较新点的版本中已经默认是 CoreDNS 了,因为 kube-dns 默认一个 Pod 中需要3个容器配合使用,CoreDNS 只需要一个容器即可,我们在前面使用 kubeadm 搭建集群的时候直接安装的就是 CoreDNS 插件:
➜ ~ kubectl get pods -n kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
coredns-667f964f9b-sthqq 1/1 Running 0 32m
coredns-667f964f9b-zj4r4 1/1 Running 0 33m
CoreDns 是用 GO 写的高性能,高扩展性的 DNS 服务,基于 HTTP/2 Web 服务 Caddy 进行编写的。CoreDns 内部采用插件机制,所有功能都是插件形式编写,用户也可以扩展自己的插件,以下是 Kubernetes 部署 CoreDns 时的默认配置:
➜ ~ kubectl get cm coredns -n kube-system -o yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors # 启用错误记录
health # 启用健康检查检查端点,8080:health
ready
kubernetes cluster.local in-addr.arpa ip6.arpa { # 处理 k8s 域名解析
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153 # 启用 metrics 指标,9153:metrics
forward . /etc/resolv.conf # 通过 resolv.conf 内的 nameservers 解析
cache 30 # 启用缓存,所有内容限制为 30s 的TTL
loop # 检查简单的转发循环并停止服务
reload # 运行自动重新加载 corefile,热更新
loadbalance # 负载均衡,默认 round_robin
}
kind: ConfigMap
metadata:
creationTimestamp: "2019-11-08T11:59:49Z"
name: coredns
namespace: kube-system
resourceVersion: "188"
selfLink: /api/v1/namespaces/kube-system/configmaps/coredns
uid: 21966186-c2d9-467a-b87f-d061c5c9e4d7
- 每个 {} 代表一个 zone,格式是 “Zone:port{}”, 其中"."代表默认zone
- {} 内的每个名称代表插件的名称,只有配置的插件才会启用,当解析域名时,会先匹配 zone(都未匹配会执行默认 zone),然后 zone 内的插件从上到下依次执行(这个顺序并不是配置文件内谁在前面的顺序,而是core/dnsserver/zdirectives.go内的顺序),匹配后返回处理(执行过的插件从下到上依次处理返回逻辑),不再执行下一个插件
CoreDNS 的 Service 地址一般情况下是固定的,类似于 kubernetes 这个 Service 地址一般就是第一个 IP 地址 10.96.0.1,CoreDNS 的 Service 地址就是 10.96.0.10,该 IP 被分配后,kubelet 会将使用 --cluster-dns= 参数配置的 DNS 传递给每个容器。DNS 名称也需要域名,本地域可以使用参数--cluster-domain = 在 kubelet 中配置:
➜ ~ cat /var/lib/kubelet/config.yaml
......
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
......
我们前面说了如果我们建立的 Service 如果支持域名形式进行解析,就可以解决我们的服务发现的功能,那么利用 kubedns 可以将 Service 生成怎样的 DNS 记录
- 普通的 Service:会生成 servicename.namespace.svc.cluster.local 的域名,会解析到 Service 对应的 ClusterIP 上,在 Pod 之间的调用可以简写成 servicename.namespace,如果处于同一个命名空间下面,甚至可以只写成 servicename 即可访问
- Headless Service:无头服务,就是把 clusterIP 设置为 None 的,会被解析为指定 Pod 的 IP 列表,同样还可以通过 podname.servicename.namespace.svc.cluster.local 访问到具体的某一个 Pod。
接下来我们来使用一个简单 Pod 来测试下 Service 的域名访问:
➜ ~ kubectl run -it --image busybox:1.28.3 test-dns --restart=Never --rm /bin/sh
If you don't see a command prompt, try pressing enter.
/ # cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
/ #
我们进入到 Pod 中,查看 /etc/resolv.conf 中的内容,可以看到 nameserver 的地址 10.96.0.10,该 IP 地址即是在安装 CoreDNS 插件的时候集群分配的一个固定的静态 IP 地址,我们可以通过下面的命令进行查看:
➜ ~ kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 28d
也就是说我们这个 Pod 现在默认的 nameserver 就是 kube-dns 的地址,现在我们来访问下前面我们创建的 nginx-service 服务
wget -q -O- nginx-service.default.svc.cluster.local:5000
给 Pod 添加 DNS 记录
我们都知道 StatefulSet 中的 Pod 是拥有单独的 DNS 记录的,比如一个 StatefulSet 名称为 etcd,而它关联的 Headless SVC 名称为 etcd-headless,那么 CoreDNS 就会为它的每个 Pod 解析如下的记录:
etcd-0.etcd-headless.default.svc.cluster.local
etcd-1.etcd-headless.default.svc.cluster.local
......
首先我们来部署一个 Deployment 管理的普通应用,其定义如下:
# nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
然后定义如下的 Headless Service:
# service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
clusterIP: None
ports:
- name: http
port: 80
protocol: TCP
selector:
app: nginx
type: ClusterIP
创建该 service,并尝试解析 service DNS:
➜ ~ kubectl apply -f service.yaml
service/nginx created
➜ ~ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 > 443/TCP 38d
nginx ClusterIP None > 80/TCP 7s
➜ ~ dig @10.96.0.10 nginx.default.svc.cluster.local
; <<>> DiG 9.9.4-RedHat-9.9.4-73.el7_6 <<>> @10.96.0.10 nginx.default.svc.cluster.local
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 2573
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;nginx.default.svc.cluster.local. IN A
;; ANSWER SECTION:
nginx.default.svc.cluster.local. 30 IN A 10.244.2.209
nginx.default.svc.cluster.local. 30 IN A 10.244.1.68
;; Query time: 19 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Wed Nov 25 11:44:41 CST 2020
;; MSG SIZE rcvd: 154
然后我们对 nginx 的 FQDN 域名进行 dig 操作,可以看到返回了多条 A 记录,每一条对应一个 Pod。上面 dig 命令中使用的 10.96.0.10 就是 kube-dns 的 cluster IP,可以在 kube-system namespace 中查看:
➜ ~ kubectl -n kube-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 > 53/UDP,53/TCP 52m
接下来我们试试在 service 名字前面加上 Pod 名字交给 kube-dns 做解析
Ingress
资源对象
Ingress 资源对象是 Kubernetes 内置定义的一个对象,是从 Kuberenets 集群外部访问集群的一个入口,将外部的请求转发到集群内不同的 Service 上,其实就相当于 nginx、haproxy 等负载均衡代理服务器,可能你会觉得我们直接使用 nginx 就实现了,但是只使用 nginx 这种方式有很大缺陷,每次有新服务加入的时候怎么改 Nginx 配置?不可能让我们去手动更改或者滚动更新前端的 Nginx Pod 吧?那我们再加上一个服务发现的工具比如 consul 如何?貌似是可以,对吧?Ingress 实际上就是这样实现的,只是服务发现的功能自己实现了,不需要使用第三方的服务了,然后再加上一个域名规则定义,路由信息的刷新依靠 Ingress Controller 来提供。

Ingress Controller 可以理解为一个监听器,通过不断地监听 kube-apiserver,实时的感知后端 Service、Pod 的变化,当得到这些信息变化后,Ingress Controller 再结合 Ingress 的配置,更新反向代理负载均衡器,达到服务发现的作用。其实这点和服务发现工具 consul、 consul-template 非常类似。
定义
一个常见的 Ingress 资源清单如下所示:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: demo-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80
上面这个 Ingress 资源的定义,配置了一个路径为 /testpath 的路由,所有 /testpath/** 的入站请求,会被 Ingress 转发至名为 test 的服务的 80 端口的 / 路径下。可以将 Ingress 狭义的理解为Nginx 中的配置文件 nginx.conf。
此外 Ingress 经常使用注解 annotations 来配置一些选项,当然这具体取决于 Ingress 控制器的实现方式,不同的 Ingress 控制器支持不同的注解。
另外需要注意的是当前集群版本是 v1.22,这里使用的 apiVersion 是 networking.k8s.io/v1,所以如果是之前版本的 Ingress 资源对象需要进行迁移。 Ingress 资源清单的描述我们可以使用 kubectl explain 命令来了解:
➜ kubectl explain ingress.spec
KIND: Ingress
VERSION: networking.k8s.io/v1
RESOURCE: spec >
DESCRIPTION:
Spec is the desired state of the Ingress. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
IngressSpec describes the Ingress the user wishes to exist.
FIELDS:
defaultBackend >
DefaultBackend is the backend that should handle requests that don't match
any rule. If Rules are not specified, DefaultBackend must be specified. If
DefaultBackend is not set, the handling of requests that do not match any
of the rules will be up to the Ingress controller.
ingressClassName >
IngressClassName is the name of the IngressClass cluster resource. The
associated IngressClass defines which controller will implement the
resource. This replaces the deprecated `kubernetes.io/ingress.class`
annotation. For backwards compatibility, when that annotation is set, it
must be given precedence over this field. The controller may emit a warning
if the field and annotation have different values. Implementations of this
API should ignore Ingresses without a class specified. An IngressClass
resource may be marked as default, which can be used to set a default value
for this field. For more information, refer to the IngressClass
documentation.
rules <[]Object>
A list of host rules used to configure the Ingress. If unspecified, or no
rule matches, all traffic is sent to the default backend.
tls <[]Object>
TLS configuration. Currently the Ingress only supports a single TLS port,
443. If multiple members of this list specify different hosts, they will be
multiplexed on the same port according to the hostname specified through
the SNI TLS extension, if the ingress controller fulfilling the ingress
supports SNI.
从上面描述可以看出 Ingress 资源对象中有几个重要的属性:defaultBackend、ingressClassName、rules、tls。
rules
其中核心部分是 rules 属性的配置,每个路由规则都在下面进行配置:
- host:可选字段,上面我们没有指定 host 属性,所以该规则适用于通过指定 IP 地址的所有入站 HTTP 通信,如果提供了 host 域名,则 rules 则会匹配该域名的相关请求,此外 host 主机名可以是精确匹配(例如 foo.bar.com)或者使用通配符来匹配(例如 *.foo.com)。
- http.paths:定义访问的路径列表,比如上面定义的 /testpath,每个路径都有一个由 backend.service.name 和 backend.service.port.number 定义关联的 Service 后端,在控制器将流量路由到引用的服务之前,host 和 path 都必须匹配传入的请求才行。
- backend:该字段其实就是用来定义后端的 Service 服务的,与路由规则中 host 和 path 匹配的流量会将发送到对应的 backend 后端去。
此外一般情况下在 Ingress 控制器中会配置一个 defaultBackend 默认后端,当请求不匹配任何 Ingress 中的路由规则的时候会使用该后端。defaultBackend 通常是 Ingress 控制器的配置选项,而非在 Ingress 资源中指定。
Resource
backend 后端除了可以引用一个 Service 服务之外,还可以通过一个 resource 资源进行关联,Resource 是当前 Ingress 对象命名空间下引用的另外一个 Kubernetes 资源对象,但是需要注意的是 Resource 与 Service 配置是互斥的,只能配置一个,Resource 后端的一种常见用法是将所有入站数据导向带有静态资产的对象存储后端,如下所示:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-resource-backend
spec:
rules:
- http:
paths:
- path: /icons
pathType: ImplementationSpecific
backend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: icon-assets
该 Ingress 资源对象描述了所有的 /icons 请求会被路由到同命名空间下的名为 icon-assets 的 StorageBucket 资源中去进行处理。
pathType
上面的示例中在定义路径规则的时候都指定了一个 pathType 的字段,事实上每个路径都需要有对应的路径类型,当前支持的路径类型有三种:
- ImplementationSpecific:该路径类型的匹配方法取决于 IngressClass,具体实现可以将其作为单独的 pathType 处理或者与 Prefix 或 Exact 类型作相同处理。
- Exact:精确匹配 URL 路径,且区分大小写。
- Prefix:基于以 / 分隔的 URL 路径前缀匹配,匹配区分大小写,并且对路径中的元素逐个完成,路径元素指的是由 / 分隔符分隔的路径中的标签列表。 (结尾自带/)
Exact 比较简单,就是需要精确匹配 URL 路径,对于 Prefix 前缀匹配,需要注意如果路径的最后一个元素是请求路径中最后一个元素的子字符串,则不会匹配,例如 /foo/bar 可以匹配 /foo/bar/baz, 但不匹配 /foo/barbaz,可以查看下表了解更多的匹配场景(来自官网):
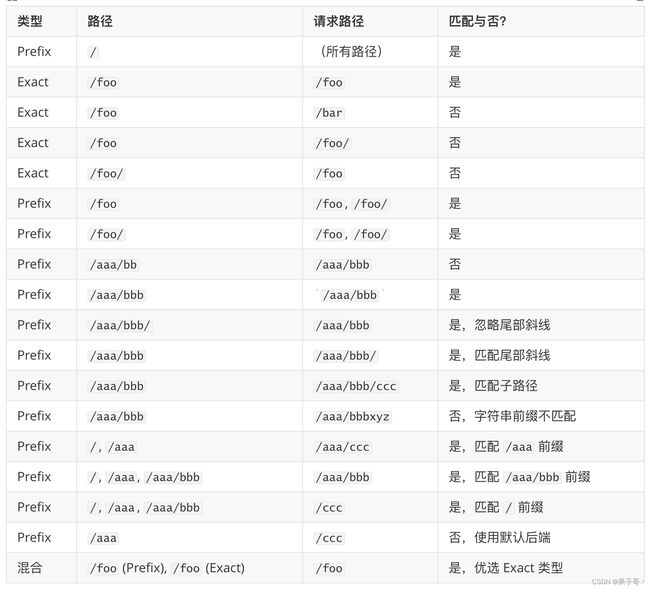
在某些情况下,Ingress 中的多条路径会匹配同一个请求,这种情况下最长的匹配路径优先,如果仍然有两条同等的匹配路径,则精确路径类型优先于前缀路径类型。
IngressClass
Kubernetes 1.18 起,正式提供了一个 IngressClass 资源,作用与 kubernetes.io/ingress.class 注解类似,因为可能在集群中有多个 Ingress 控制器,可以通过该对象来定义我们的控制器,例如:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: nginx-ingress-internal-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lb
其中重要的属性是 metadata.name 和 spec.controller,前者是这个 IngressClass 的名称,需要设置在 Ingress 中,后者是 Ingress 控制器的名称。
Ingress 中的 spec.ingressClassName 属性就可以用来指定对应的 IngressClass,并进而由 IngressClass 关联到对应的 Ingress 控制器,如:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp
spec:
ingressClassName: external-lb # 上面定义的 IngressClass 对象名称
defaultBackend:
service:
name: myapp
port:
number: 80
不过需要注意的是 spec.ingressClassName 与老版本的 kubernetes.io/ingress.class 注解的作用并不完全相同,因为 ingressClassName 字段引用的是 IngressClass 资源的名称,IngressClass 资源中除了指定了 Ingress 控制器的名称之外,还可能会通过 spec.parameters 属性定义一些额外的配置。
比如 parameters 字段有一个 scope 和 namespace 字段,可用来引用特定于命名空间的资源,对 Ingress 类进行配置。 scope 字段默认为 Cluster,表示默认是集群作用域的资源。将 scope 设置为 Namespace 并设置 namespace 字段就可以引用某特定命名空间中的参数资源,比如:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: nginx-ingress-internal-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lb
namespace: external-configuration
scope: Namespace
由于一个集群中可能有多个 Ingress 控制器,所以我们还可以将一个特定的 IngressClass 对象标记为集群默认是 Ingress 类。只需要将一个 IngressClass 资源的 ingressclass.kubernetes.io/is-default-class 注解设置为 true 即可,这样未指定 ingressClassName 字段的 Ingress 就会使用这个默认的 IngressClass。
如果集群中有多个 IngressClass 被标记为默认,准入控制器将阻止创建新的未指定 ingressClassName 的 Ingress 对象。最好的方式还是确保集群中最多只能有一个 IngressClass 被标记为默认。
TLS
Ingress 资源对象还可以用来配置 Https 的服务,可以通过设定包含 TLS 私钥和证书的 Secret 来保护 Ingress。 Ingress 只支持单个 TLS 端口 443,如果 Ingress 中的 TLS 配置部分指定了不同的主机,那么它们将根据通过 SNI TLS 扩展指定的主机名 (如果 Ingress 控制器支持 SNI)在同一端口上进行复用。需要注意 TLS Secret 必须包含名为 tls.crt 和 tls.key 的键名,例如:
apiVersion: v1
kind: Secret
metadata:
name: testsecret-tls
namespace: default
data:
tls.crt: base64 编码的 cert
tls.key: base64 编码的 key
type: kubernetes.io/tls
在 Ingress 中引用此 Secret 将会告诉 Ingress 控制器使用 TLS 加密从客户端到负载均衡器的通道,我们需要确保创建的 TLS Secret 创建自包含 https-example.foo.com 的公用名称的证书,如下所示:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: tls-example-ingress
spec:
tls:
- hosts:
- https-example.foo.com
secretName: testsecret-tls
rules:
- host: https-example.foo.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service1
port:
number: 80
现在我们了解了如何定义 Ingress 资源对象了,但是仅创建 Ingress 资源本身没有任何效果。还需要部署 Ingress 控制器,例如 ingress-nginx,现在可以供大家使用的 Ingress 控制器有很多,比如 traefik、nginx-controller、Kubernetes Ingress Controller for Kong、HAProxy Ingress controller,当然你也可以自己实现一个 Ingress Controller,现在普遍用得较多的是 traefik 和 ingress-nginx,traefik 的性能比 ingress-nginx 差,但是配置使用要简单许多,我们这里会重点给大家介绍 ingress-nginx、traefik 以及 apisix 的使用。
实际上社区目前还在开发一组高配置能力的 API,被称为 Service API,新 API 会提供一种 Ingress 的替代方案,它的存在目的不是替代 Ingress,而是提供一种更具配置能力的新方案。
Ingress-nginx
我们已经了解了 Ingress 资源对象只是一个路由请求描述配置文件,要让其真正生效还需要对应的 Ingress 控制器才行,Ingress 控制器有很多,这里我们先介绍使用最多的 ingress-nginx,它是基于 Nginx 的 Ingress 控制器。
运行原理
ingress-nginx 控制器主要是用来组装一个 nginx.conf 的配置文件,当配置文件发生任何变动的时候就需要重新加载 Nginx 来生效,但是并不会只在影响 upstream 配置的变更后就重新加载 Nginx,控制器内部会使用一个 lua-nginx-module 来实现该功能。
我们知道 Kubernetes 控制器使用控制循环模式来检查控制器中所需的状态是否已更新或是否需要变更,所以 ingress-nginx 需要使用集群中的不同对象来构建模型,比如 Ingress、Service、Endpoints、Secret、ConfigMap 等可以生成反映集群状态的配置文件的对象,控制器需要一直 Watch 这些资源对象的变化,但是并没有办法知道特定的更改是否会影响到最终生成的 nginx.conf 配置文件,所以一旦 Watch 到了任何变化控制器都必须根据集群的状态重建一个新的模型,并将其与当前的模型进行比较,如果模型相同则就可以避免生成新的 Nginx 配置并触发重新加载,否则还需要检查模型的差异是否只和端点有关,如果是这样,则然后需要使用 HTTP POST 请求将新的端点列表发送到在 Nginx 内运行的 Lua 处理程序,并再次避免生成新的 Nginx 配置并触发重新加载,如果运行和新模型之间的差异不仅仅是端点,那么就会基于新模型创建一个新的 Nginx 配置了,这样构建模型最大的一个好处就是在状态没有变化时避免不必要的重新加载,可以节省大量 Nginx 重新加载。
下面简单描述了需要重新加载的一些场景:
- 创建了新的 Ingress 资源
- TLS 添加到现有 Ingress
- 从 Ingress 中添加或删除 path 路径
- Ingress、Service、Secret 被删除了
- Ingress 的一些缺失引用对象变可用了,例如 Service 或 Secret
- 更新了一个 Secret
对于集群规模较大的场景下频繁的对 Nginx 进行重新加载显然会造成大量的性能消耗,所以要尽可能减少出现重新加载的场景。
安装
由于 ingress-nginx 所在的节点需要能够访问外网,这样域名可以解析到这些节点上直接使用,所以需要让 ingress-nginx 绑定节点的 80 和 443 端口,所以可以使用 hostPort 来进行访问,当然对于线上环境来说为了保证高可用,一般是需要运行多个 ·ingress-nginx 实例的,然后可以用一个 nginx/haproxy 作为入口,通过 keepalived 来访问边缘节点的 vip 地址。
边缘节点
所谓的边缘节点即集群内部用来向集群外暴露服务能力的节点,集群外部的服务通过该节点来调用集群内部的服务,边缘节点是集群内外交流的一个 Endpoint。
这里我们使用 Helm Chart(后面会详细讲解)的方式来进行安装:
# 如果你不喜欢使用 helm chart 进行安装也可以使用下面的命令一键安装
# kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.1.0/deploy/static/provider/cloud/deploy.yaml
➜ helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
➜ helm repo update
➜ helm fetch ingress-nginx/ingress-nginx
➜ tar -xvf ingress-nginx-4.0.13.tgz && cd ingress-nginx
➜ tree .
.
├── CHANGELOG.md
├── Chart.yaml
├── OWNERS
├── README.md
├── ci
│ ├── controller-custom-ingressclass-flags.yaml
│ ├── daemonset-customconfig-values.yaml
│ ├── daemonset-customnodeport-values.yaml
│ ├── daemonset-headers-values.yaml
│ ├── daemonset-internal-lb-values.yaml
│ ├── daemonset-nodeport-values.yaml
│ ├── daemonset-podannotations-values.yaml
│ ├── daemonset-tcp-udp-configMapNamespace-values.yaml
│ ├── daemonset-tcp-udp-values.yaml
│ ├── daemonset-tcp-values.yaml
│ ├── deamonset-default-values.yaml
│ ├── deamonset-metrics-values.yaml
│ ├── deamonset-psp-values.yaml
│ ├── deamonset-webhook-and-psp-values.yaml
│ ├── deamonset-webhook-values.yaml
│ ├── deployment-autoscaling-behavior-values.yaml
│ ├── deployment-autoscaling-values.yaml
│ ├── deployment-customconfig-values.yaml
│ ├── deployment-customnodeport-values.yaml
│ ├── deployment-default-values.yaml
│ ├── deployment-headers-values.yaml
│ ├── deployment-internal-lb-values.yaml
│ ├── deployment-metrics-values.yaml
│ ├── deployment-nodeport-values.yaml
│ ├── deployment-podannotations-values.yaml
│ ├── deployment-psp-values.yaml
│ ├── deployment-tcp-udp-configMapNamespace-values.yaml
│ ├── deployment-tcp-udp-values.yaml
│ ├── deployment-tcp-values.yaml
│ ├── deployment-webhook-and-psp-values.yaml
│ ├── deployment-webhook-resources-values.yaml
│ └── deployment-webhook-values.yaml
├── templates
│ ├── NOTES.txt
│ ├── _helpers.tpl
│ ├── _params.tpl
│ ├── admission-webhooks
│ │ ├── job-patch
│ │ │ ├── clusterrole.yaml
│ │ │ ├── clusterrolebinding.yaml
│ │ │ ├── job-createSecret.yaml
│ │ │ ├── job-patchWebhook.yaml
│ │ │ ├── psp.yaml
│ │ │ ├── role.yaml
│ │ │ ├── rolebinding.yaml
│ │ │ └── serviceaccount.yaml
│ │ └── validating-webhook.yaml
│ ├── clusterrole.yaml
│ ├── clusterrolebinding.yaml
│ ├── controller-configmap-addheaders.yaml
│ ├── controller-configmap-proxyheaders.yaml
│ ├── controller-configmap-tcp.yaml
│ ├── controller-configmap-udp.yaml
│ ├── controller-configmap.yaml
│ ├── controller-daemonset.yaml
│ ├── controller-deployment.yaml
│ ├── controller-hpa.yaml
│ ├── controller-ingressclass.yaml
│ ├── controller-keda.yaml
│ ├── controller-poddisruptionbudget.yaml
│ ├── controller-prometheusrules.yaml
│ ├── controller-psp.yaml
│ ├── controller-role.yaml
│ ├── controller-rolebinding.yaml
│ ├── controller-service-internal.yaml
│ ├── controller-service-metrics.yaml
│ ├── controller-service-webhook.yaml
│ ├── controller-service.yaml
│ ├── controller-serviceaccount.yaml
│ ├── controller-servicemonitor.yaml
│ ├── default-backend-deployment.yaml
│ ├── default-backend-hpa.yaml
│ ├── default-backend-poddisruptionbudget.yaml
│ ├── default-backend-psp.yaml
│ ├── default-backend-role.yaml
│ ├── default-backend-rolebinding.yaml
│ ├── default-backend-service.yaml
│ ├── default-backend-serviceaccount.yaml
│ └── dh-param-secret.yaml
└── values.yaml
4 directories, 81 files
Helm Chart 包下载下来后解压就可以看到里面包含的模板文件,其中的 ci 目录中就包含了各种场景下面安装的 Values 配置文件,values.yaml 文件中包含的是所有可配置的默认值 , 我们可以对这些默认值进行覆盖,我们这里测试环境就将 master1 节点看成边缘节点,所以我们就直接将 ingress-nginx 固定到 master1 节点上,采用 hostNetwork 模式(生产环境可以使用 LB + DaemonSet hostNetwork 模式),为了避免创建的错误 Ingress 等资源对象影响控制器重新加载,所以我们也强烈建议大家开启准入控制器,ingess-nginx 中会提供一个用于校验资源对象的 Admission Webhook,我们可以通过 Values 文件进行开启。然后新建一个名为 ci/daemonset-prod.yaml 的 Values 文件,用来覆盖 ingress-nginx 默认的 Values 值。
对应的 Values 配置文件如下所示:
# ci/daemonset-prod.yaml
controller:
name: controller
image:
repository: cnych/ingress-nginx
tag: "v1.1.0"
digest:
dnsPolicy: ClusterFirstWithHostNet
hostNetwork: true
publishService: # hostNetwork 模式下设置为false,通过节点IP地址上报ingress status数据
enabled: false
# 是否需要处理不带 ingressClass 注解或者 ingressClassName 属性的 Ingress 对象
# 设置为 true 会在控制器启动参数中新增一个 --watch-ingress-without-class 标注
watchIngressWithoutClass: false
kind: DaemonSet
tolerations: # kubeadm 安装的集群默认情况下master是有污点,需要容忍这个污点才可以部署
- key: "node-role.kubernetes.io/master"
operator: "Equal"
effect: "NoSchedule"
nodeSelector: # 固定到master1节点
kubernetes.io/hostname: master1
service: # HostNetwork 模式不需要创建service
enabled: false
admissionWebhooks: # 强烈建议开启 admission webhook
enabled: true
createSecretJob:
resources:
limits:
cpu: 10m
memory: 20Mi
requests:
cpu: 10m
memory: 20Mi
patchWebhookJob:
resources:
limits:
cpu: 10m
memory: 20Mi
requests:
cpu: 10m
memory: 20Mi
patch:
enabled: true
image:
repository: cnych/ingress-nginx-webhook-certgen
tag: v1.1.1
digest:
defaultBackend: # 配置默认后端
enabled: true
name: defaultbackend
image:
repository: cnych/ingress-nginx-defaultbackend
tag: "1.5"
然后使用如下命令安装 ingress-nginx 应用到 ingress-nginx 的命名空间中:
➜ kubectl create ns ingress-nginx
➜ helm upgrade --install ingress-nginx . -f ./ci/daemonset-prod.yaml --namespace ingress-nginx
Release "ingress-nginx" does not exist. Installing it now.
NAME: ingress-nginx
LAST DEPLOYED: Thu Dec 16 16:47:20 2021
NAMESPACE: ingress-nginx
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
The ingress-nginx controller has been installed.
It may take a few minutes for the LoadBalancer IP to be available.
You can watch the status by running 'kubectl --namespace ingress-nginx get services -o wide -w ingress-nginx-controller'
An example Ingress that makes use of the controller:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example
namespace: foo
spec:
ingressClassName: nginx
rules:
- host: www.example.com
http:
paths:
- backend:
service:
name: exampleService
port:
number: 80
path: /
# This section is only required if TLS is to be enabled for the Ingress
tls:
- hosts:
- www.example.com
secretName: example-tls
If TLS is enabled for the Ingress, a Secret containing the certificate and key must also be provided:
apiVersion: v1
kind: Secret
metadata:
name: example-tls
namespace: foo
data:
tls.crt: >
tls.key: >
type: kubernetes.io/tls
部署完成后查看 Pod 的运行状态:
➜ kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller-admission ClusterIP 10.96.15.99 > 443/TCP 11m
ingress-nginx-defaultbackend ClusterIP 10.97.250.253 > 80/TCP 11m
➜ kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-5dfdd4659c-9g7c2 1/1 Running 0 11m
ingress-nginx-defaultbackend-84854cd6cb-xb7rv 1/1 Running 0 11m
➜ POD_NAME=$(kubectl get pods -l app.kubernetes.io/name=ingress-nginx -n ingress-nginx -o jsonpath='{.items[0].metadata.name}')
➜ kubectl exec -it $POD_NAME -n ingress-nginx -- /nginx-ingress-controller --version
kubectl logs -f ingress-nginx-controller-5dfdd4659c-9g7c2 -n ingress-nginxW1216 08:51:22.179213 7 client_config.go:615] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
I1216 08:51:22.179525 7 main.go:223] "Creating API client" host="https://10.96.0.1:443"
-------------------------------------------------------------------------------
NGINX Ingress controller
Release: v1.1.0
Build: cacbee86b6ccc45bde8ffc184521bed3022e7dee
Repository: https://github.com/kubernetes/ingress-nginx
nginx version: nginx/1.19.9
-------------------------------------------------------------------------------
I1216 08:51:22.198221 7 main.go:267] "Running in Kubernetes cluster" major="1" minor="22" git="v1.22.2" state="clean" commit="8b5a19147530eaac9476b0ab82980b4088bbc1b2" platform="linux/amd64"
I1216 08:51:22.200478 7 main.go:86] "Valid default backend" service="ingress-nginx/ingress-nginx-defaultbackend"
I1216 08:51:22.611100 7 main.go:104] "SSL fake certificate created" file="/etc/ingress-controller/ssl/default-fake-certificate.pem"
I1216 08:51:22.627386 7 ssl.go:531] "loading tls certificate" path="/usr/local/certificates/cert" key="/usr/local/certificates/key"
I1216 08:51:22.651187 7 nginx.go:255] "Starting NGINX Ingress controller"
当看到上面的信息证明 ingress-nginx 部署成功了,这里我们安装的是最新版本的控制器,安装完成后会自动创建一个 名为 nginx 的 IngressClass 对象:
➜ kubectl get ingressclass
NAME CONTROLLER PARAMETERS AGE
nginx k8s.io/ingress-nginx > 18m
➜ kubectl get ingressclass nginx -o yaml
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
......
name: nginx
resourceVersion: "1513966"
uid: 70340e62-cab6-4a11-9982-2108f1db786b
spec:
controller: k8s.io/ingress-nginx
不过这里我们只提供了一个 controller 属性,如果还需要配置一些额外的参数,则可以在安装的 values 文件中进行配置。
第一个示例❤
安装成功后,现在我们来为一个 nginx 应用创建一个 Ingress 资源,如下所示:
# my-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
app: my-nginx
template:
metadata:
labels:
app: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
app: my-nginx
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
app: my-nginx
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-nginx
namespace: default
spec:
ingressClassName: nginx # 使用 nginx 的 IngressClass(关联的 ingress-nginx 控制器)
rules:
- host: ngdemo.qikqiak.com # 将域名映射到 my-nginx 服务
http:
paths:
- path: /
pathType: Prefix
backend:
service: # 将所有请求发送到 my-nginx 服务的 80 端口
name: my-nginx
port:
number: 80
# 不过需要注意大部分Ingress控制器都不是直接转发到Service
# 而是只是通过Service来获取后端的Endpoints列表,直接转发到Pod,这样可以减少网络跳转,提高性能
直接创建上面的资源对象:
➜ kubectl apply -f my-nginx.yaml
deployment.apps/my-nginx created
service/my-nginx created
ingress.networking.k8s.io/my-nginx created
➜ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
my-nginx nginx ngdemo.qikqiak.com 192.168.31.31 80 30m
在上面的 Ingress 资源对象中我们使用配置 ingressClassName: nginx 指定让我们安装的 ingress-nginx 这个控制器来处理我们的 Ingress 资源,配置的匹配路径类型为前缀的方式去匹配 /,将来自域名 ngdemo.qikqiak.com 的所有请求转发到 my-nginx 服务的后端 Endpoints 中去。
上面资源创建成功后,然后我们可以将域名 ngdemo.qikqiak.com 解析到 ingress-nginx 所在的边缘节点中的任意一个,当然也可以在本地 /etc/hosts 中添加对应的映射也可以,然后就可以通过域名进行访问了。
下图显示了客户端是如何通过 Ingress 控制器连接到其中一个 Pod 的流程,客户端首先对 ngdemo.qikqiak.com 执行 DNS 解析,得到 Ingress 控制器所在节点的 IP,然后客户端向 Ingress 控制器发送 HTTP 请求,然后根据 Ingress 对象里面的描述匹配域名,找到对应的 Service 对象,并获取关联的 Endpoints 列表,将客户端的请求转发给其中一个 Pod。
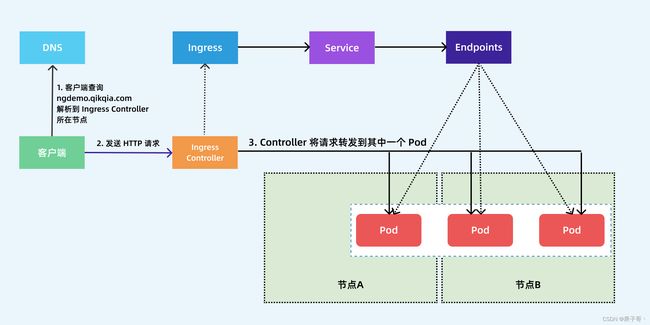
前面我们也提到了 ingress-nginx 控制器的核心原理就是将我们的 Ingress 这些资源对象映射翻译成 Nginx 配置文件 nginx.conf,我们可以通过查看控制器中的配置文件来验证这点:
➜ kubectl exec -it $POD_NAME -n ingress-nginx -- cat /etc/nginx/nginx.conf
......
upstream upstream_balancer {
server 0.0.0.1; # placeholder
balancer_by_lua_block {
balancer.balance()
}
keepalive 320;
keepalive_timeout 60s;
keepalive_requests 10000;
}
......
## start server ngdemo.qikqiak.com
server {
server_name ngdemo.qikqiak.com ;
listen 80 ;
listen [::]:80 ;
listen 443 ssl http2 ;
listen [::]:443 ssl http2 ;
set $proxy_upstream_name "-";
ssl_certificate_by_lua_block {
certificate.call()
}
location / {
set $namespace "default";
set $ingress_name "my-nginx";
set $service_name "my-nginx";
set $service_port "80";
set $location_path "/";
set $global_rate_limit_exceeding n;
......
proxy_next_upstream_timeout 0;
proxy_next_upstream_tries 3;
proxy_pass http://upstream_balancer;
proxy_redirect off;
}
}
## end server ngdemo.qikqiak.com
......
我们可以在 nginx.conf 配置文件中看到上面我们新增的 Ingress 资源对象的相关配置信息,不过需要注意的是现在并不会为每个 backend 后端都创建一个 upstream 配置块,现在是使用 Lua 程序进行动态处理的,所以我们没有直接看到后端的 Endpoints 相关配置数据。
Nginx配置
如果我们还想进行一些自定义配置,则有几种方式可以实现:使用 Configmap 在 Nginx 中设置全局配置、通过 Ingress 的 Annotations 设置特定 Ingress 的规则、自定义模板。接下来我们重点给大家介绍使用注解来对 Ingress 对象进行自定义。
Basic Auth
我们可以在 Ingress 对象上配置一些基本的 Auth 认证,比如 Basic Auth,可以用 htpasswd 生成一个密码文件来验证身份验证。
➜ htpasswd -c auth foo
New password:
Re-type new password:
Adding password for user foo
然后根据上面的 auth 文件创建一个 secret 对象:
➜ kubectl create secret generic basic-auth --from-file=auth
secret/basic-auth created
➜ kubectl get secret basic-auth -o yaml
apiVersion: v1
data:
auth: Zm9vOiRhcHIxJFUxYlFZTFVoJHdIZUZQQ1dyZTlGRFZONTQ0dXVQdC4K
kind: Secret
metadata:
name: basic-auth
namespace: default
type: Opaque
然后对上面的 my-nginx 应用创建一个具有 Basic Auth 的 Ingress 对象:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-with-auth
namespace: default
annotations:
nginx.ingress.kubernetes.io/auth-type: basic # 认证类型
nginx.ingress.kubernetes.io/auth-secret: basic-auth # 包含 user/password 定义的 secret 对象名
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - foo' # 要显示的带有适当上下文的消息,说明需要身份验证的原因
spec:
ingressClassName: nginx # 使用 nginx 的 IngressClass(关联的 ingress-nginx 控制器)
rules:
- host: bauth.qikqiak.com # 将域名映射到 my-nginx 服务
http:
paths:
- path: /
pathType: Prefix
backend:
service: # 将所有请求发送到 my-nginx 服务的 80 端口
name: my-nginx
port:
number: 80
直接创建上面的资源对象,然后通过下面的命令或者在浏览器中直接打开配置的域名:
➜ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-with-auth nginx bauth.qikqiak.com 192.168.31.31 80 6m55s
➜ curl -v http://192.168.31.31 -H 'Host: bauth.qikqiak.com'
* Trying 192.168.31.31...
* TCP_NODELAY set
* Connected to 192.168.31.31 (192.168.31.31) port 80 (#0)
> GET / HTTP/1.1
> Host: bauth.qikqiak.com
> User-Agent: curl/7.64.1
> Accept: */*
>
< HTTP/1.1 401 Unauthorized
< Date: Thu, 16 Dec 2021 10:49:03 GMT
< Content-Type: text/html
< Content-Length: 172
< Connection: keep-alive
< WWW-Authenticate: Basic realm="Authentication Required - foo"
<
401 Authorization Required
401 Authorization Required
nginx
* Connection #0 to host 192.168.31.31 left intact
* Closing connection 0
我们可以看到出现了 401 认证失败错误,然后带上我们配置的用户名和密码进行认证:
➜ curl -v http://192.168.31.31 -H 'Host: bauth.qikqiak.com' -u 'foo:foo'
当然除了 Basic Auth 这一种简单的认证方式之外,ingress-nginx 还支持一些其他高级的认证,比如我们可以使用 GitHub OAuth 来认证 Kubernetes 的 Dashboard。
URL Rewrite
ingress-nginx 很多高级的用法可以通过 Ingress 对象的 annotation 进行配置,比如常用的 URL Rewrite 功能。很多时候我们会将 ingress-nginx 当成网关使用,比如对访问的服务加上 /app 这样的前缀,在 nginx 的配置里面我们知道有一个 proxy_pass 指令可以实现:
location /app/ {
proxy_pass http://127.0.0.1/remote/;
}
proxy_pass 后面加了 /remote 这个路径,此时会将匹配到该规则路径中的 /app 用 /remote 替换掉,相当于截掉路径中的 /app 。 同样的在 Kubernetes 中使用 ingress-nginx 又该如何来实现呢?我们可以使用 rewrite-target 的注解来实现这个需求,比如现在我们想要通过 rewrite.qikqiak.com/gateway/ 来访问到 Nginx 服务,则我们需要对访问的 URL 路径做一个 Rewrite,在 PATH 中添加一个 gateway 的前缀
按照要求我们需要在 path 中匹配前缀 gateway,然后通过 rewrite-target 指定目标,Ingress 对象如下所示:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: rewrite
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
spec:
ingressClassName: nginx
rules:
- host: rewrite.qikqiak.com
http:
paths:
- path: /gateway(/|$)(.*)
pathType: Prefix
backend:
service:
name: my-nginx
port:
number: 80
更新后,我们可以预见到直接访问域名肯定是不行了,因为我们没有匹配 / 的 path 路径:
➜ curl rewrite.qikqiak.com
default backend - 404
➜ curl rewrite.qikqiak.com/gateway/
我们可以看到已经可以访问到了,这是因为我们在 path 中通过正则表达式 /gateway(/|$)(.*) 将匹配的路径设置成了 rewrite-target 的目标路径了,所以我们访问 rewite.qikqiak.com/gateway/ 的时候实际上相当于访问的就是后端服务的 / 路径 。
要解决我们访问主域名出现 404 的问题,我们可以给应用设置一个 app-root 的注解,这样当我们访问主域名的时候会自动跳转到我们指定的 app-root 目录下面,如下所示:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: rewrite
annotations:
nginx.ingress.kubernetes.io/app-root: /gateway/
nginx.ingress.kubernetes.io/rewrite-target: /$2
spec:
ingressClassName: nginx
rules:
- host: rewrite.qikqiak.com
http:
paths:
- path: /gateway(/|$)(.*)
pathType: Prefix
backend:
service:
name: my-nginx
port:
number: 80
这个时候我们更新应用后访问主域名 rewrite.qikqiak.com 就会自动跳转到 rewrite.qikqiak.com/gateway/ 路径下面去了。但是还有一个问题是我们的 path 路径其实也匹配了 /app 这样的路径,可能我们更加希望我们的应用在最后添加一个 / 这样的 slash,同样我们可以通过 configuration-snippet 配置来完成,如下 Ingress 对象:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: rewrite
annotations:
nginx.ingress.kubernetes.io/app-root: /gateway/
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/configuration-snippet: |
rewrite ^(/gateway)$ $1/ redirect;
spec:
ingressClassName: nginx
rules:
- host: rewrite.qikqiak.com
http:
paths:
- path: /gateway(/|$)(.*)
pathType: Prefix
backend:
service:
name: my-nginx
port:
number: 80
更新后我们的应用就都会以 / 这样的 slash 结尾了。这样就完成了我们的需求,如果你原本对 nginx 的配置就非常熟悉的话应该可以很快就能理解这种配置方式了。
灰度发布
在日常工作中我们经常需要对服务进行版本更新升级,所以我们经常会使用到滚动升级、蓝绿发布、灰度发布等不同的发布操作。而 ingress-nginx 支持通过 Annotations 配置来实现不同场景下的灰度发布和测试,可以满足金丝雀发布、蓝绿部署与 A/B 测试等业务场景。
ingress-nginx 的 Annotations 支持以下 4 种 Canary 规则:
- nginx.ingress.kubernetes.io/canary-by-header:基于 Request Header 的流量切分,适用于灰度发布以及 A/B 测试。当 Request Header 设置为 always 时,请求将会被一直发送到 Canary 版本;当 Request Header 设置为 never 时,请求不会被发送到 Canary 入口;对于任何其他 Header 值,将忽略 Header,并通过优先级将请求与其他金丝雀规则进行优先级的比较。
- nginx.ingress.kubernetes.io/canary-by-header-value:要匹配的 Request Header 的值,用于通知 Ingress 将请求路由到 Canary Ingress 中指定的服务。当 Request Header 设置为此值时,它将被路由到 Canary 入口。该规则允许用户自定义 Request Header 的值,必须与上一个 annotation (canary-by-header) 一起使用。
- nginx.ingress.kubernetes.io/canary-weight:基于服务权重的流量切分,适用于蓝绿部署,权重范围 0 - 100 按百分比将请求路由到 Canary Ingress 中指定的服务。权重为 0 意味着该金丝雀规则不会向 Canary 入口的服务发送任何请求,权重为 100 意味着所有请求都将被发送到 Canary 入口。
- nginx.ingress.kubernetes.io/canary-by-cookie:基于 cookie 的流量切分,适用于灰度发布与 A/B 测试。用于通知 Ingress 将请求路由到 Canary Ingress 中指定的服务的cookie。当 cookie 值设置为 always 时,它将被路由到 Canary 入口;当 cookie 值设置为 never 时,请求不会被发送到 Canary 入口;对于任何其他值,将忽略 cookie 并将请求与其他金丝雀规则进行优先级的比较。
需要注意的是金丝雀规则按优先顺序进行排序:canary-by-header - > canary-by-cookie - > canary-weight
总的来说可以把以上的四个 annotation 规则划分为以下两类:
-
基于权重的 Canary 规则

-
基于用户请求的 Canary 规则

下面我们通过一个示例应用来对灰度发布功能进行说明。 -
第一步. 部署 Production 应用
-
第二步. 创建 Canary 版本 参考将上述 Production 版本的 production.yaml 文件,再创建一个 Canary 版本的应用。
-
第三步. Annotation 规则配置
https://www.qikqiak.com/k3s/network/ingress-nginx/
HTTPS
如果我们需要用 HTTPS 来访问我们这个应用的话,就需要监听 443 端口了,同样用 HTTPS 访问应用必然就需要证书,这里我们用 openssl 来创建一个自签名的证书:
➜ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=foo.bar.com"
然后通过 Secret 对象来引用证书文件:
# 要注意证书文件名称必须是 tls.crt 和 tls.key
➜ kubectl create secret tls foo-tls --cert=tls.crt --key=tls.key
secret/who-tls created
这个时候我们就可以创建一个 HTTPS 访问应用的:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-with-auth
annotations:
# 认证类型
nginx.ingress.kubernetes.io/auth-type: basic
# 包含 user/password 定义的 secret 对象名
nginx.ingress.kubernetes.io/auth-secret: basic-auth
# 要显示的带有适当上下文的消息,说明需要身份验证的原因
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - foo'
spec:
ingressClassName: nginx
tls: # 配置 tls 证书
- hosts:
- foo.bar.com
secretName: foo-tls
rules:
- host: foo.bar.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: my-nginx
port:
number: 80
除了自签名证书或者购买正规机构的 CA 证书之外,我们还可以通过一些工具来自动生成合法的证书,cert-manager 是一个云原生证书管理开源项目,可以用于在 Kubernetes 集群中提供 HTTPS 证书并自动续期,支持 Let’s Encrypt/HashiCorp/Vault 这些免费证书的签发。在 Kubernetes 中,可以通过 Kubernetes Ingress 和 Let’s Encrypt 实现外部服务的自动化 HTTPS。
全局配置
除了可以通过 annotations 对指定的 Ingress 进行定制之外,我们还可以配置 ingress-nginx 的全局配置,在控制器启动参数中通过标志 --configmap 指定了一个全局的 ConfigMap 对象,我们可以将全局的一些配置直接定义在该对象中即可:
containers:
- args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/ingress-nginx-controller
......
比如这里我们用于全局配置的 ConfigMap 名为 ingress-nginx-controller:
➜ kubectl get configmap -n ingress-nginx
NAME DATA AGE
ingress-nginx-controller 1 5d2h
比如我们可以添加如下所示的一些常用配置:
➜ kubectl edit configmap ingress-nginx-controller -n ingress-nginx
apiVersion: v1
data:
allow-snippet-annotations: "true"
client-header-buffer-size: 32k # 注意不是下划线
client-max-body-size: 5m
use-gzip: "true"
gzip-level: "7"
large-client-header-buffers: 4 32k
proxy-connect-timeout: 11s
proxy-read-timeout: 12s
keep-alive: "75" # 启用keep-alive,连接复用,提高QPS
keep-alive-requests: "100"
upstream-keepalive-connections: "10000"
upstream-keepalive-requests: "100"
upstream-keepalive-timeout: "60"
disable-ipv6: "true"
disable-ipv6-dns: "true"
max-worker-connections: "65535"
max-worker-open-files: "10240"
kind: ConfigMap
......
修改完成后 Nginx 配置会自动重载生效,我们可以查看 nginx.conf 配置文件进行验证:
➜ kubectl exec -it ingress-nginx-controller-gc582 -n ingress-nginx -- cat /etc/nginx/nginx.conf |grep large_client_header_buffers
large_client_header_buffers 4 32k;
由于我们这里是 Helm Chart 安装的,为了保证重新部署后配置还在,我们同样需要通过 Values 进行全局配置:
# ci/daemonset-prod.yaml
controller:
config:
allow-snippet-annotations: "true"
client-header-buffer-size: 32k # 注意不是下划线
client-max-body-size: 5m
use-gzip: "true"
gzip-level: "7"
large-client-header-buffers: 4 32k
proxy-connect-timeout: 11s
proxy-read-timeout: 12s
keep-alive: "75" # 启用keep-alive,连接复用,提高QPS
keep-alive-requests: "100"
upstream-keepalive-connections: "10000"
upstream-keepalive-requests: "100"
upstream-keepalive-timeout: "60"
disable-ipv6: "true"
disable-ipv6-dns: "true"
max-worker-connections: "65535"
max-worker-open-files: "10240"
# 其他省略
此外往往我们还需要对 ingress-nginx 部署的节点进行性能优化,修改一些内核参数,使得适配 Nginx 的使用场景,一般我们是直接去修改节点上的内核参数,为了能够统一管理,我们==可以使用 initContainers 来进行配置== :
initContainers:
- command:
- /bin/sh
- -c
- |
mount -o remount rw /proc/sys
sysctl -w net.core.somaxconn=65535 # 具体的配置视具体情况而定
sysctl -w net.ipv4.tcp_tw_reuse=1
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -w fs.file-max=1048576
sysctl -w fs.inotify.max_user_instances=16384
sysctl -w fs.inotify.max_user_watches=524288
sysctl -w fs.inotify.max_queued_events=16384
image: busybox
imagePullPolicy: IfNotPresent
name: init-sysctl
securityContext:
capabilities:
add:
- SYS_ADMIN
drop:
- ALL
......
由于我们这里使用的是 Helm Chart 安装的 ingress-nginx,同样只需要去配置 Values 值即可,模板中提供了对 initContainers 的支持,配置如下所示:
controller:
# 其他省略,配置 initContainers
extraInitContainers:
- name: init-sysctl
image: busybox
securityContext:
capabilities:
add:
- SYS_ADMIN
drop:
- ALL
command:
- /bin/sh
- -c
- |
mount -o remount rw /proc/sys
sysctl -w net.core.somaxconn=65535 # socket监听的backlog上限
sysctl -w net.ipv4.tcp_tw_reuse=1 # 开启重用,允许将 TIME-WAIT sockets 重新用于新的TCP连接
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -w fs.file-max=1048576
sysctl -w fs.inotify.max_user_instances=16384
sysctl -w fs.inotify.max_user_watches=524288
sysctl -w fs.inotify.max_queued_events=16384
同样重新部署即可:
➜ helm upgrade --install ingress-nginx . -f ./ci/daemonset-prod.yaml --namespace ingress-nginx
部署完成后通过 initContainers 就可以修改节点内核参数了,生产环境建议对节点内核参数进行相应的优化。
TCP与UDP
由于在 Ingress 资源对象中没有直接对 TCP 或 UDP 服务的支持,要在 ingress-nginx 中提供支持,需要在控制器启动参数中添加 --tcp-services-configmap 和 --udp-services-configmap 标志指向一个 ConfigMap,其中的 key 是要使用的外部端口,value 值是使用格式
比如现在我们要通过 ingress-nginx 来暴露一个 MongoDB 服务,首先创建如下的应用:
# mongo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongo
labels:
app: mongo
spec:
selector:
matchLabels:
app: mongo
template:
metadata:
labels:
app: mongo
spec:
volumes:
- name: data
emptyDir: {}
containers:
- name: mongo
image: mongo:4.0
ports:
- containerPort: 27017
volumeMounts:
- name: data
mountPath: /data/db
---
apiVersion: v1
kind: Service
metadata:
name: mongo
spec:
selector:
app: mongo
ports:
- port: 27017
直接创建上面的资源对象:
➜ kubectl apply -f mongo.yaml
➜ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mongo ClusterIP 10.98.117.228 > 27017/TCP 2m26s
➜ kubectl get pods -l app=mongo
NAME READY STATUS RESTARTS AGE
mongo-84c587f547-gd7pv 1/1 Running 0 2m5s
现在我们要通过 ingress-nginx 来暴露上面的 MongoDB 服务,我们需要创建一个如下所示的 ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: tcp-services
namespace: ingress-nginx
data:
"27017": default/mongo:27017
然后在 ingress-nginx 的启动参数中添加 --tcp-services-configmap=$(POD_NAMESPACE)/ingress-nginx-tcp 这样的配置即可,由于我们这里使用的是 Helm Chart 进行安装的,我们只需要去覆盖 Values 值重新安装即可,修改 ci/daemonset-prod.yaml 文件:
# ci/daemonset-prod.yaml
# ...... 其他部分省略,和之前的保持一致
tcp: # 配置 tcp 服务
27017: "default/mongo:27017" # 使用 27017 端口去映射 mongo 服务
# 9000: "default/test:8080" # 如果还需要暴露其他 TCP 服务,继续添加即可
配置完成后重新更新当前的 ingress-nginx:
➜ helm upgrade --install ingress-nginx . -f ./ci/daemonset-prod.yaml --namespace ingress-nginx
重新部署完成后会自动生成一个名为 ingress-nginx-tcp 的 ConfigMap 对象,如下所示:
➜ kubectl get configmap -n ingress-nginx ingress-nginx-tcp -o yaml
apiVersion: v1
data:
"27017": default/mongo:27017
kind: ConfigMap
metadata:
......
name: ingress-nginx-tcp
namespace: ingress-nginx
在 ingress-nginx 的启动参数中也添加上 --tcp-services-configmap=$(POD_NAMESPACE)/ingress-nginx-tcp 这样的配置:
➜ kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-gc582 1/1 Running 0 5m17s
➜ kubectl get pod ingress-nginx-controller-gc582 -n ingress-nginx -o yaml
apiVersion: v1
kind: Pod
......
containers:
- args:
- /nginx-ingress-controller
- --default-backend-service=$(POD_NAMESPACE)/ingress-nginx-defaultbackend
- --election-id=ingress-controller-leader
- --controller-class=k8s.io/ingress-nginx
- --configmap=$(POD_NAMESPACE)/ingress-nginx-controller
- --tcp-services-configmap=$(POD_NAMESPACE)/ingress-nginx-tcp # tcp 配置参数
- --validating-webhook=:8443
- --validating-webhook-certificate=/usr/local/certificates/cert
- --validating-webhook-key=/usr/local/certificates/key
......
ports:
......
- containerPort: 27017
hostPort: 27017
name: 27017-tcp
protocol: TCP
......
同样的我们也可以去查看最终生成的 nginx.conf 配置文件:
➜ kubectl exec -it ingress-nginx-controller-gc582 -n ingress-nginx -- cat /etc/nginx/nginx.conf
......
stream {
......
# TCP services
server {
preread_by_lua_block {
ngx.var.proxy_upstream_name="tcp-default-mongo-27017";
}
listen 27017;
listen [::]:27017;
proxy_timeout 600s;
proxy_next_upstream on;
proxy_next_upstream_timeout 600s;
proxy_next_upstream_tries 3;
proxy_pass upstream_balancer;
}
# UDP services
}
TCP 相关的配置位于 stream 配置块下面。从 Nginx 1.9.13 版本开始提供 UDP 负载均衡,同样我们也可以在 ingress-nginx 中来代理 UDP 服务,比如我们可以去暴露 kube-dns 的服务,同样需要创建一个如下所示的 ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: udp-services
namespace: ingress-nginx
data:
53: "kube-system/kube-dns:53"
然后需要在 ingress-nginx 参数中添加一个 - --udp-services-configmap=$(POD_NAMESPACE)/udp-services 这样的配置,当然我们这里只需要去修改 Values 文件值即可,修改 ci/daemonset-prod.yaml 文件:
# ci/daemonset-prod.yaml
# ...... 其他部分省略,和之前的保持一致
tcp: # 配置 tcp 服务
27017: "default/mongo:27017" # 使用 27017 端口去映射 mongo 服务
# 9000: "default/test:8080" # 如果还需要暴露其他 TCP 服务,继续添加即可
udp: # 配置 udp 服务
53: "kube-system/kube-dns:53"
然后重新更新即可。
Traefik
Gateway API
APISIX
Apache APISIX 是一个基于 OpenResty 和 Etcd 实现的动态、实时、高性能的 API 网关,目前已经是 Apache 顶级项目。提供了丰富的流量管理功能,如负载均衡、动态路由、动态 upstream、A/B测试、金丝雀发布、限速、熔断、防御恶意攻击、认证、监控指标、服务可观测性、服务治理等。可以使用 APISIX 来处理传统的南北流量以及服务之间的东西向流量。
APISIX 基于 Nginx 和 etcd,与传统 API 网关相比,APISIX 具有动态路由和热加载插件功能,避免了配置之后的 reload 操作,同时 APISIX 支持 HTTP(S)、HTTP2、Dubbo、QUIC、MQTT、TCP/UDP 等更多的协议。而且还内置了 Dashboard,提供强大而灵活的界面。同样也提供了丰富的插件支持功能,而且还可以让用户自定义插件。
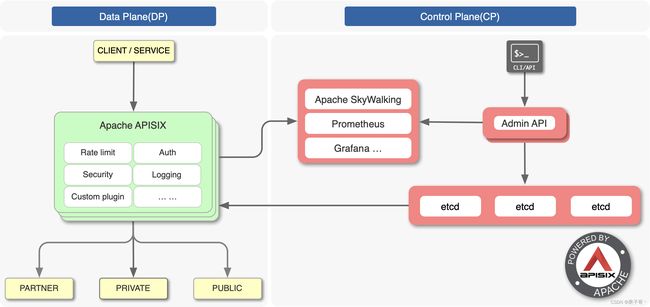
上图是 APISIX 的架构图,整体上分成数据面和控制面两个部分,控制面用来管理路由,主要通过 etcd 来实现配置中心,数据面用来处理客户端请求,通过 APISIX 自身来实现,会不断去 watch etcd 中的 route、upstream 等数据。
https://www.qikqiak.com/k3s/network/apisix/