饭店点餐系统的需求分析
Web scraping, Sentiment analysis, LDA topic modeling
网站抓取,情感分析,LDA主题建模
项目概况(Project Overview)
In this project, we are going to scrape hotel reviews of “Hotel Beresford” located in San Francisco, CA from the website bookings.com. Then, we are going to do some data exploration, generate WordClouds, perform sentiment analysis and create an LDA topic model.
在本项目中,我们将从bookings.com网站上删除位于加利福尼亚州旧金山的“ Hotel Beresford”酒店点评。 然后,我们将进行一些数据探索,生成WordCloud,执行情感分析并创建LDA主题模型。
问题陈述 (Problem Statement)
The project goal is to use text analytics and Natural Language Processing (NLP) to extract actionable insights from the reviews and help the hotel improve their guest satisfactions.
该项目的目标是使用文本分析和自然语言处理(NLP)从评论中提取可行的见解,并帮助酒店提高客人的满意度。
方法论 (Methodologies)
(1) Web Scraping
(1)网页抓取
The hotel reviews will be scraped from bookings.com by using requests with BeautifulSoup. The detailed steps are covered in the next section.
通过使用BeautifulSoup的请求,将从bookings.com删除酒店评论。 下一节将介绍详细步骤。
(2) Exploratory Data Analysis (EDA)
(2)探索性数据分析(EDA)
We will use pie chart, histogram, and seaborn violin plot to get a better understanding of the reviews and ratings data.
我们将使用饼图,直方图和seaborn小提琴图来更好地了解评论和评级数据。
(3) WordClouds
(3)字云
In order to generate more meaningful WordClouds, we will customize some extra stop words and use lemmatization to remove closely redundant words.
为了生成更有意义的词云,我们将自定义一些额外的停用词,并使用词形化技术来删除紧密冗余的词。
(4) Sentiment Analysis
(4)情感分析
The sentiment analysis helps to classify the polarity and subjectivity of the overall reviews and determine whether the expressed opinion in the reviews is mostly positive, negative, or neutral.
情绪分析有助于对总体评论的极性和主观性进行分类,并确定评论中表达的观点大部分是正面,负面或中立的。
(5) LDA Topic Model
(5)LDA主题模型
In natural language processing, the latent Dirichlet allocation is a generative statistical model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar. We will use GridSearch to find the best topic model. The two tuning parameters are: (1) n_components: number of topics and (2) learning_decay (which controls the learning rate)
在自然语言处理中,潜在的狄利克雷分配是一种生成的统计模型,该模型允许未观察到的组解释观察集,这些观察组解释了为什么数据的某些部分相似。 我们将使用GridSearch查找最佳主题模型。 这两个调整参数是:(1) n_components :主题数;(2) learning_decay (控制学习率)
指标 (Metrics)
To diagnose the model performance, we will take a look at the perplexity and log-likelihood scores of the LDA model.
为了诊断模型的性能,我们将研究LDA模型的困惑度和对数似然分数。
Perplexity captures how surprised a model is of new data it has not seen before, and is measured as the normalized log-likelihood of a held-out test set. Log-likelihood is a measure of how plausible model parameters are given the data.
困惑捕获了一个模型对从未见过的新数据感到惊讶的程度,并将其度量为保持测试集的标准化对数似然率。 对数似然性是对给定数据合理模型参数的一种度量。
A model with higher log-likelihood and lower perplexity is considered to be a good model. However, perplexity might not be the best measure to evaluate topic models because it doesn’t consider the context and semantic associations between words. (Read this article to learn more)
具有较高对数可能性和较低困惑度的模型被认为是一个很好的模型。 但是,困惑可能不是评估主题模型的最佳方法,因为它没有考虑单词之间的上下文和语义关联。 (阅读本文以了解更多信息)
如何取消评论? (How to Scrape the Reviews?)
In this project, we are going to scrape the reviews of “Hotel Beresford” located in San Francisco, CA . To scrape any websites, we need to first find the pattern of the URL and then inspect the web page. However, we see that this link is extremely long.
在此项目中,我们将刮除位于加利福尼亚州旧金山的“ Hotel Beresford”的评论。 要抓取任何网站,我们需要首先找到URL的模式,然后检查网页。 但是,我们看到此链接非常长。
https://www.booking.com/reviews/us/hotel/beresford.html?label=gen173nr-1FCA0o7AFCCWJlcmVzZm9yZEgzWARokQKIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4ArGo6_oFwAIB0gIkODFmNjUzODEtMWU5Ny00ZjIzLWI2MWEtYjBjZGU2NzI0ZWYz2AIF4AIB;sid=a1571564bf0a35365a839937489b2ef6;customer_type=total;hp_nav=0;old_page=0;order=featuredreviews;page=1;r_lang=en;rows=75&After several tries, you will realize that using the link below can also generate the same page. If you want to scrape other hotels, simply replace “beresford” with any other hotel names booking.com uses. Entering a page number at the end would bring you to the review page you want to see.
经过几次尝试,您将意识到使用下面的链接也可以生成相同的页面。 如果要刮擦其他酒店,只需将“ beresford”替换为booking.com使用的任何其他酒店名称。 在末尾输入页码将带您进入要查看的评论页面。
https://www.booking.com/reviews/us/hotel/beresford.html?page=Right click anywhere on the web page and select “Inspect” to view the HTML & CSS script of web elements. Here we find the html tags of the review section we want to scrape is “ul.review_list”.
右键单击网页上的任意位置,然后选择“检查”以查看Web元素HTML和CSS脚本。 在这里,我们发现要抓取的评论部分的html标签为“ ul.review_list”。
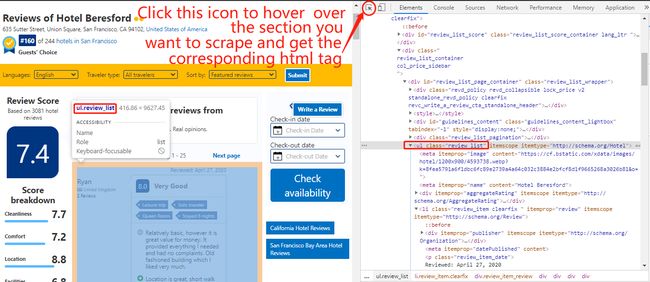
Under this tag, we want to scrape the following information:
在此标签下,我们要抓取以下信息:
1. Basic information of the reviewer and reviews:
1.审稿人和审稿的基本信息:
Rating Score
评分分数
Reviewer Name
审稿人姓名
Reviewer’s Nationality
审稿人的国籍
Overall Review (contains both positive & negative reviews)
总体评价(包含正面和负面评论)
Reviewer Reviewed Times
评论者评论时间
Review Date
审核日期
Review Tags (Trip type, such as business trip, leisure trip, etc.)
审核标签(旅行类型,例如商务旅行,休闲旅行等)
2. Positive reviews
2.正面评价
3. Negative Reviews
3.负面评价

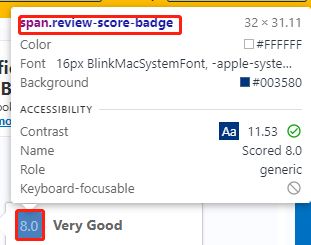
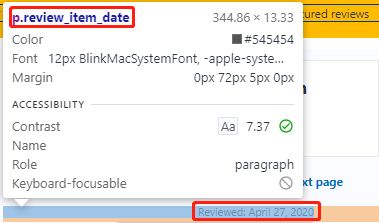
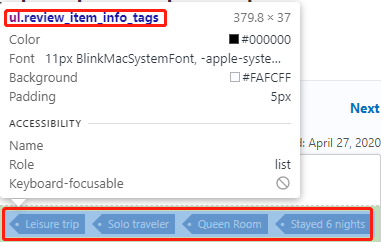

Now that we have found all of the html tags, let’s start coding! First, we need to import all the python packages we need.
现在我们已经找到了所有的html标记,让我们开始编码! 首先,我们需要导入所需的所有python软件包。
## importing packages ##
import numpy as np
import pandas as pd
import seaborn as sns
import plotly.express as px
import matplotlib.pyplot as plt
%matplotlib inline
import re
from bs4 import BeautifulSoup as bs
import requests
import string
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords,wordnet
from wordcloud import WordCloud
# nltk.download('averaged_perceptron_tagger')
# nltk.download('vader_lexicon')
# nltk.download('wordnet')
from textblob import TextBlob
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.model_selection import GridSearchCV
from sklearn.decomposition import LatentDirichletAllocation
import pyLDAvis
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
import warnings
warnings.filterwarnings("ignore")第一部分:来自Bookings.com的刮刮评论和干净的非结构化文本(Part I. Scrape Reviews from Bookings.com & Clean Unstructured Text)
The steps of scraping the reviews involves:
取消评论的步骤包括:
- Specify the URL of the reviews page 指定评论页面的URL
- Send an HTTP request to the URL and save the response from server in a response object. 将HTTP请求发送到URL,并将来自服务器的响应保存在响应对象中。
Create a BeautifulSoup object by passing the raw HTML content from step 2 and specifying the HTML parser we want to use, like
html.parserorhtml.5lib.通过传递第2步中的原始HTML内容并指定我们要使用HTML解析器(例如
html.parser或html.5lib来创建BeautifulSoup对象。Navigate and search the parse tree using BeautifulSoup’s tree-searching method
.find_all()使用BeautifulSoup的树搜索方法
.find_all()导航并搜索解析树Try to scrape one page first. Print out each scraped text to identify patterns and clean the text by using
.strip()and.replace()methods尝试先刮一页。 使用
.strip()和.replace()方法打印出每个刮擦的文本以识别模式并清理文本- Create for loops to store into the three lists创建for循环以存储到三个列表中
- Use a while loop to scrape all the pages使用while循环来抓取所有页面
- Convert the lists into dataframes将列表转换为数据框
- Put everything into a function called “scrape_reviews”将所有内容放入一个名为“ scrape_reviews”的函数中
The second function “show_data” will print out the length of a dataframe, total NAs, as well as the first five lines of a dataframe.
第二个函数“ show_data”将打印出数据帧的长度,总的NA以及数据帧的前五行。
def scrape_reviews(hotel_linkname,total_pages):
'''
Function to scrape hotel reviews from bookings.com
INPUTS:
hotel_linkname - hotel name in the bookings.com weblink
total_pages - the total number of reviews pages to scrape
OUTPUTS:
reviewer_info - a dataframe that includes reviewers' basic information
pos_reviews - a dataframe that includes all the positive reviews
neg_reviews - a dataframe that includes all the negative reviews
'''
#Create empty lists to put in reviewers' information as well as all of the positive & negative reviews
info = []
positive = []
negative = []
#bookings.com reviews link
url = 'https://www.booking.com/reviews/us/hotel/'+ hotel_linkname +'.html?page='
page_number = 1
#Use a while loop to scrape all the pages
while page_number <= total_pages:
page = requests.get(url + str(page_number)) #retrieve data from serve
soup = bs(page.text, "html.parser") # initiate a beautifulsoup object using the html source and Python’s html.parser
review_box = soup.find('ul',{'class':'review_list'})
#ratings
ratings = [i.text.strip() for i in review_box.find_all('span',{'class':'review-score-badge'})]
#reviewer_info
reviewer_info = [i.text.strip() for i in review_box.find_all('span',{'itemprop':'name'})]
reviewer_name = reviewer_info[0::3]
reviewer_country = reviewer_info[1::3]
general_review = reviewer_info[2::3]
# reviewer_review_times
review_times = [i.text.strip() for i in review_box.find_all('div',{'class':'review_item_user_review_count'})]
# review_date
review_date = [i.text.strip().strip('Reviewed: ') for i in review_box.find_all('p',{'class':'review_item_date'})]
# reviewer_tag
reviewer_tag = [i.text.strip().replace('\n\n\n','').replace('•',',').lstrip(', ') for i
in review_box.find_all('ul',{'class':'review_item_info_tags'})]
# positive_review
positive_review = [i.text.strip('눇').strip() for i in review_box.find_all('p',{'class':'review_pos'})]
# negative_review
negative_review = [i.text.strip('눉').strip() for i in review_box.find_all('p',{'class':'review_neg'})]
# append all reviewers' info into one list
for i in range(len(reviewer_name)):
info.append([ratings[i],reviewer_name[i],reviewer_country[i],general_review[i],
review_times[i],review_date[i],reviewer_tag[i]])
# build positive review list
for i in range(len(positive_review)):
positive.append(positive_review[i])
# build negative review list
for i in range(len(negative_review)):
negative.append(negative_review[i])
# page change
page_number +=1
#Reviewer_info df
reviewer_info = pd.DataFrame(info,
columns = ['Rating','Name','Country','Overall_review','Review_times','Review_date','Review_tags'])
reviewer_info['Rating'] = pd.to_numeric(reviewer_info['Rating'] )
reviewer_info['Review_times'] = pd.to_numeric(reviewer_info['Review_times'].apply(lambda x:re.findall("\d+", x)[0]))
reviewer_info['Review_date'] = pd.to_datetime(reviewer_info['Review_date'])
#positive & negative reviews dfs
pos_reviews = pd.DataFrame(positive,columns = ['positive_reviews'])
neg_reviews = pd.DataFrame(negative,columns = ['negative_reviews'])
return reviewer_info, pos_reviews, neg_reviews
def show_data(df):
print("The length of the dataframe is: {}".format(len(df)))
print("Total NAs: {}".format(reviewer_info.isnull().sum().sum()))
return df.head()There are 42 review pages for Hotel Beresford, adjust the hotel’s name and total number of reviews page when you scrape other hotels.
Hotel Beresford的共有42条评论页,刮其他酒店时,请调整酒店的名称和评论总数。
reviewer_info, pos_reviews, neg_reviews = scrape_reviews('beresford',total_pages = 42)Now, let’s check our scraped data by applying the “show_data” function we defined before.
现在,让我们通过应用我们之前定义的“ show_data”函数来检查抓取的数据。
#reviewers' basic information
show_data(reviewer_info)
#positive reviews
show_data(pos_reviews)
# positive review
show_data(neg_reviews)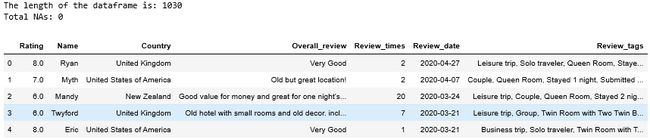


We have 1030 records for the dataframe that contains the basic information of the reviewers as well as rating scores, review dates, and review tags.
我们有1030个数据框记录,其中包含审阅者的基本信息以及评分,审阅日期和审阅标签。
For positive reviews, we have scraped 651 records and 614 for the negatives.
对于正面评价,我们已删除651条记录,而负面记录则为614条。
第二部分探索性数据分析(EDA) (Part II. Exploratory Data Analysis (EDA))
Before doing further analyses, let’s perform the exploratory data analysis (EDA) first to get a “feel” of the data we have!
在进行进一步分析之前,让我们先进行探索性数据分析(EDA),以“了解”我们拥有的数据!
1.正面和负面评论的比例 (1. Ratio of positive and negative reviews)
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
values = [len(pos_reviews), len(neg_reviews)]
ax.pie(values,
labels = ['Number of Positive Reviews', 'Number of Negative Reviews'],
colors=['gold', 'lightcoral'],
shadow=True,
startangle=90,
autopct='%1.2f%%')
ax.axis('equal')
plt.title('Positive Reviews Vs. Negative Reviews');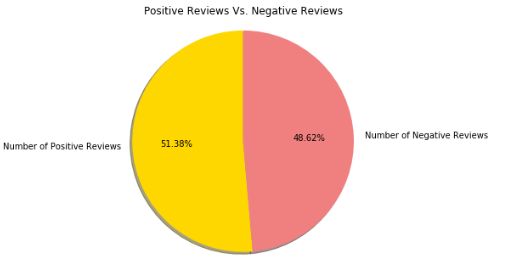
2. The Distribution of Ratings
2.评级的分布
# Histogram of Ratings
print(reviewer_info['Rating'].describe())
px.histogram(reviewer_info, x="Rating", nbins=30, title = 'Histogram of Ratings')
演示地址
print("For all of the reviewers, they came from {} different countries.".format(reviewer_info.Country.nunique()))
print("\n")
top10_df = reviewer_info.groupby('Country').size().reset_index().sort_values(0, ascending = False).head(10)
top10_df.columns = ['Country', 'Counts']
print("Top 10 countries ranked by review counts")
top10_df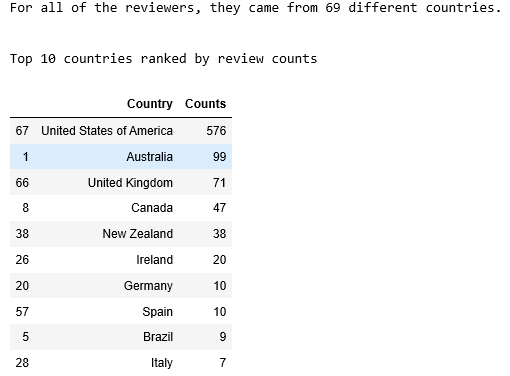
People from different countries may have different standards when it comes to rating hotels and their services. Among 1030 reviewers, they came from 69 different countries. Here, we are only visualizing the distributions of the top 10 countries ranked by the number of reviews.
在评价酒店及其服务时,来自不同国家的人们可能有不同的标准。 在1030名审稿人中,他们来自69个不同的国家。 在这里,我们仅显示按评论数排名的前10个国家/地区的分布。
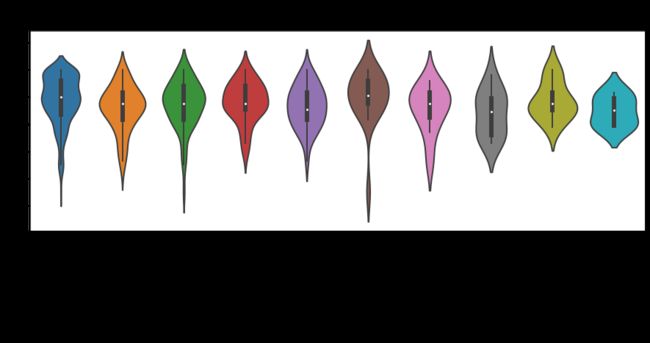
A Violin Plot is used to visualize the distribution of the data and its probability density. The plot shown below is displayed in the order of review counts of each country. It shows the relationship of ratings to the reviewers’ country of origins. From the box plot elements, we see that the median rating given by the U.S. and Ireland reviewers are a bit higher than the rest of the reviewers from other countries, while the median rating given by the reviewers from Italy is the lowest. Most of the shapes of the distributions (skinny on each end and wide in the middle) indicates the weights of ratings given by the reviewers are highly concentrated around the median, which is around 7 to 8. However, we probably need more data to get a better idea of the distributions.
小提琴图用于可视化数据的分布及其概率密度。 下面显示的图以每个国家的审查数量的顺序显示。 它显示了评分与审稿人的原籍国之间的关系。 从箱形图元素中,我们可以看到,美国和爱尔兰审稿人给出的中位评分略高于其他国家/地区的其他审稿人,而意大利审稿人给出的中位评分最低。 分布的大多数形状(两端呈细长形,中间呈宽形)表明审阅者给出的评分的权重高度集中在中位数(大约7到8)附近。但是,我们可能需要更多数据才能获得更好地了解分布。
3.查看每种行程类型的标签计数 (3. Review Tags Counts for each Trip Type)
#Define tag list
tag_list = ['Business','Leisure','Group','Couple','Family','friends','Solo']
#Count for each review tag
tag_counts = []
for tag in tag_list:
counts = reviewer_info['Review_tags'].str.count(tag).sum()
tag_counts.append(counts)
#Convert to a dataframe
trip_type = pd.DataFrame({'Trip Type':tag_list,'Counts':tag_counts}).sort_values('Counts',ascending = False)
#Visualize the trip type counts from Review_tags
fig = px.bar(trip_type, x='Trip Type', y='Counts', title='Review Tags Counts for each Trip Type')
fig.show()演示地址
A lot of the times, one review has multiple tags. The bar chart shows that most people came to San Francisco for leisure trips, either as couples or by themselves. Fewer people came with their family or with a group, and even fewer people came with friends. Out of 1030 reviews, there are only 164 reviews that were tagged “Business”, which means only 16% of the reviewers came for business trips. However, we should take into account of the fact that people who came for leisure trips are usually more likely to have time or more willing to write reviews, while those who came for business trips maybe too busy or simply do not want to write any reviews.
很多时候,一个评论有多个标签。 条形图显示,大多数人成对或单独来到旧金山休闲旅行。 与家人或同伴一起来的人减少了,与朋友一起来的人更少了。 在1030条评论中,只有164条被标记为“商务”的评论,这意味着只有16%的评论者来此出差。 但是,我们应该考虑到这样一个事实,来休闲旅行的人们通常更有时间或更愿意写评论,而那些出差旅行的人可能太忙或根本不想写任何评论。
第三部分文字分析 (Part III. Text Analytics)
Lemmatize Tokens
使令牌令牌化
Lemmatization links words with similar meaning to one word. Wordnet and treebank have different tagging systems, so we want to first define a mapping between wordnet tags and POS tags. Then, we lemmatize words using NLTK. After generating WordClouds, I added extra customized stop words in the lemmatization process below.
词法化将具有相似含义的词链接到一个词。 Wordnet和treebank具有不同的标签系统,因此我们首先要定义wordnet标签和POS标签之间的映射。 然后,我们使用NLTK对词进行词素化。 生成WordClouds之后,我在下面的词形化过程中添加了额外的自定义停用词。
# wordnet and treebank have different tagging systems
# Create a function to define a mapping between wordnet tags and POS tags
def get_wordnet_pos(pos_tag):
if pos_tag.startswith('J'):
return wordnet.ADJ
elif pos_tag.startswith('V'):
return wordnet.VERB
elif pos_tag.startswith('N'):
return wordnet.NOUN
elif pos_tag.startswith('R'):
return wordnet.ADV
else:
return wordnet.NOUN # default, return wordnet tag "NOUN"
#Create a function to lemmatize tokens in the reviews
def lemmatized_tokens(text):
text = text.lower()
pattern = r'\b[a-zA-Z]{3,}\b'
tokens = nltk.regexp_tokenize(text, pattern) # tokenize the text
tagged_tokens = nltk.pos_tag(tokens) # a list of tuples (word, pos_tag)
stop_words = stopwords.words('english')
new_stopwords = ["hotel","everything","anything","nothing","thing","need",
"good","great","excellent","perfect","much","even","really"] #customize extra stop_words
stop_words.extend(new_stopwords)
stop_words = set(stop_words)
wordnet_lemmatizer = WordNetLemmatizer()
# get lemmatized tokens #call function "get_wordnet_pos"
lemmatized_words=[wordnet_lemmatizer.lemmatize(word, get_wordnet_pos(tag))
# tagged_tokens is a list of tuples (word, tag)
for (word, tag) in tagged_tokens \
# remove stop words
if word not in stop_words and \
# remove punctuations
word not in string.punctuation]
return lemmatized_words2. Generate WordClouds
2.生成WordCloud
#Create a function to generate wordcloud
def wordcloud(review_df, review_colname, color, title):
'''
INPUTS:
reivew_df - dataframe, positive or negative reviews
review_colname - column name, positive or negative review
color - background color of worldcloud
title - title of the wordcloud
OUTPUT:
Wordcloud visuazliation
'''
text = review_df[review_colname].tolist()
text_str = ' '.join(lemmatized_tokens(' '.join(text))) #call function "lemmatized_tokens"
wordcloud = WordCloud(collocations = False,
background_color = color,
width=1600,
height=800,
margin=2,
min_font_size=20).generate(text_str)
plt.figure(figsize = (15, 10))
plt.imshow(wordcloud, interpolation = 'bilinear')
plt.axis("off")
plt.figtext(.5,.8,title,fontsize = 20, ha='center')
plt.show()
# Wordcoulds for Positive Reviews
wordcloud(pos_reviews,'positive_reviews', 'white','Positive Reviews: ')
# # WordCoulds for Negative Reviews
wordcloud(neg_reviews,'negative_reviews', 'black', 'Negative Reviews:')
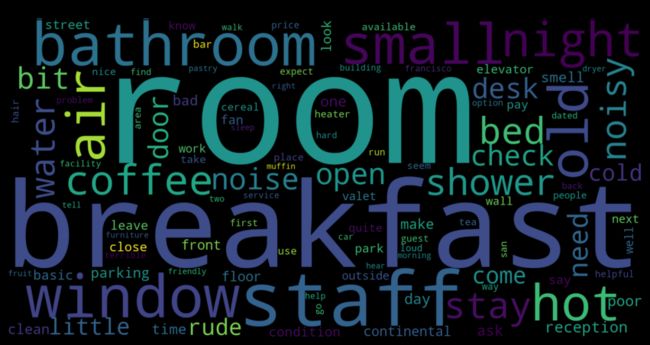
For positive reviews, most people are probably satisfied with the location, very convenient and close to Union Square or Chinatown and easy to find restaurants or pubs nearby, friendly and helpful staff, clean room, comfortable bed, and good price, etc.
对于正面评价,大多数人都对这里的位置感到满意,非常便利,靠近联合广场或唐人街,并且附近容易找到餐馆或酒吧,友善乐于助人的员工,干净的房间,舒适的床和价格优惠等。
The negative reviews also mentioned words like “breakfast”, “room” and “staff” quite often, but maybe people were complaining about the staffs who were being rude, small rooms, and coffee/ cereal/ muffin provided during breakfast. The air conditioning or the shower system may need improvements as we see words like “hot”, “cold”, “air”, “condition”, “bathroom” and “shower” in the WordCloud. The hotel may also need to solve issues related to soundproofing and parking.
负面评论还经常提到诸如“早餐”,“房间”和“员工”之类的词,但也许人们在抱怨那些粗鲁的员工,小房间以及早餐期间提供的咖啡/谷物/松饼。 当我们在WordCloud中看到诸如“热”,“冷”,“空气”,“状况”,“浴室”和“淋浴”之类的词时,空调或淋浴系统可能需要改进。 酒店可能还需要解决与隔音和停车有关的问题。
3. Sentiment Analysis
3.情绪分析
Here, we are using the Overall_review column in the reviewer_info dataframe to perform the sentiment analysis.
在这里,我们使用reviewer_info数据Overall_review列执行情感分析。
#Create a function to get the subjectivity
def subjectivity(text):
return TextBlob(text).sentiment.subjectivity
#Create a function to get the polarity
def polarity(text):
return TextBlob(text).sentiment.polarity
#Create two new columns
reviewer_info['Subjectivity'] = reviewer_info['Overall_review'].apply(subjectivity)
reviewer_info['Polarity'] = reviewer_info['Overall_review'].apply(polarity)
#################################################################################
#Create a function to compute the negative, neutral and positive analysis
def getAnalysis(score):
if score <0:
return 'Negative'
elif score == 0:
return 'Neutral'
else:
return 'Positive'
reviewer_info['Analysis'] = reviewer_info['Polarity'].apply(getAnalysis)
#################################################################################
# plot the polarity and subjectivity
fig = px.scatter(reviewer_info,
x='Polarity',
y='Subjectivity',
color = 'Analysis',
size='Subjectivity')
#add a vertical line at x=0 for Netural Reviews
fig.update_layout(title='Sentiment Analysis',
shapes=[dict(type= 'line',
yref= 'paper', y0= 0, y1= 1,
xref= 'x', x0= 0, x1= 0)])
fig.show()演示地址
The x-axis shows polarity, and y-axis shows subjectivity. Polarity tells how positive or negative the text is. The subjectivity tells how subjective or opinionated the text is. The green dots that lies on the vertical line are the “neutral” reviews, the red dots on the left are the “negative” reviews, and the blue dots on the right are the “positive” reviews. Bigger dots indicate more subjectivity. We see that positive reviews are more than the negatives.
x轴表示极性,y轴表示主观性。 极性表明文本的正面或负面。 主观性告诉文本是多么主观或自以为是。 垂直线上的绿点是“中性”评论,左侧的红点是“负”评论,右侧的蓝点是“正”评论。 点越大表示主观性越强。 我们看到正面的评价大于负面的评价。
4. LDA Topic Modelling
4. LDA主题建模
Now, let’s apply the LDA model to find each document topic distribution and the high probability of word in each topic. Here, we want to specifically look at the negative reviews to find out what aspects should the hotel be focusing on improving.
现在,让我们应用LDA模型来查找每个文档主题分布以及每个主题中单词的高概率。 在这里,我们要专门研究负面评论,以找出酒店应着重改善的方面。
Below are the steps to find the optimal LDA model:
以下是找到最佳LDA模型的步骤:
1. Convert the reviews to document-term matrix
1.将评论转换为文档术语矩阵
TFcomputes the classic number of times the word appears in the text, andIDFcomputes the relative importance of this word which depends on how many texts the word can be found.TF-DFis the inverse document frequency. It adjusts for the fact that some words appear more frequently in general, like "we", "the", etc. We discard words that appeared in > 90% of the reviews and words appeared in < 10 reviews since high appearing words are too common to be meaningful in topics and low appearing words won’t have a strong enough signal and might even introduce noise to our model.
TF计算该词在文本中出现的经典次数,而IDF计算该词的相对重要性,这取决于可以找到该词的文本数。TF-DF是反文档频率。 它会针对某些单词通常会更频繁地出现这一事实进行调整,例如“我们”,“该”等。我们会丢弃出现在90%以上评论中的单词和出现在<10条评论中的单词,因为出现次数也很高通常在主题上有意义,而露面的单词不会发出足够强烈的信号,甚至可能会给我们的模型带来噪音。
2. GridSearch and parameter tuning to find the optimal LDA model
2. GridSearch和参数调整以找到最佳的LDA模型
The process of grid search can consume a lot of time because it constructs multiple LDA models for all possible combinations of param values in the param_grid dict. So, here we are only tuning two parameters: (1)
n_components(number of topics) and (2)learning_decay(which controls the learning rate).网格搜索过程可能会花费大量时间,因为它会为param_grid dict中的所有可能的参数值组合构造多个LDA模型。 因此,这里我们仅调整两个参数:(1)
n_components(主题数)和(2)learning_decay(控制学习率)。
3. Output the optimal lda model and its parameters
3.输出最优的lda模型及其参数
A good model should have higher log-likelihood and lower perplexity (exp(-1. * log-likelihood per word)). However, perplexity might not be the best measure to evaluate topic models because it doesn’t consider the context and semantic associations between words.
一个好的模型应该具有较高的对数似然率和较低的困惑度(exp(-1。*每个单词的对数似然率))。 但是,困惑可能不是评估主题模型的最佳方法,因为它没有考虑单词之间的上下文和语义关联。
4. Compare LDA Model Performance Scores
4.比较LDA模型性能得分
The line plot shows the LDA model performance scores with different params
线图显示了具有不同参数的LDA模型性能得分
#Create a function to build the optimal LDA model
def optimal_lda_model(df_review, review_colname):
'''
INPUTS:
df_review - dataframe that contains the reviews
review_colname: name of column that contains reviews
OUTPUTS:
lda_tfidf - Latent Dirichlet Allocation (LDA) model
dtm_tfidf - document-term matrix in the tfidf format
tfidf_vectorizer - word frequency in the reviews
A graph comparing LDA Model Performance Scores with different params
'''
docs_raw = df_review[review_colname].tolist()
#************ Step 1: Convert to document-term matrix ************#
#Transform text to vector form using the vectorizer object
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
stop_words = 'english',
lowercase = True,
token_pattern = r'\b[a-zA-Z]{3,}\b', # num chars > 3 to avoid some meaningless words
max_df = 0.9, # discard words that appear in > 90% of the reviews
min_df = 10) # discard words that appear in < 10 reviews
#apply transformation
tfidf_vectorizer = TfidfVectorizer(**tf_vectorizer.get_params())
#convert to document-term matrix
dtm_tfidf = tfidf_vectorizer.fit_transform(docs_raw)
print("The shape of the tfidf is {}, meaning that there are {} {} and {} tokens made through the filtering process.".\
format(dtm_tfidf.shape,dtm_tfidf.shape[0], review_colname, dtm_tfidf.shape[1]))
#******* Step 2: GridSearch & parameter tuning to find the optimal LDA model *******#
# Define Search Param
search_params = {'n_components': [5, 10, 15, 20, 25, 30],
'learning_decay': [.5, .7, .9]}
# Init the Model
lda = LatentDirichletAllocation()
# Init Grid Search Class
model = GridSearchCV(lda, param_grid=search_params)
# Do the Grid Search
model.fit(dtm_tfidf)
#***** Step 3: Output the optimal lda model and its parameters *****#
# Best Model
best_lda_model = model.best_estimator_
# Model Parameters
print("Best Model's Params: ", model.best_params_)
# Log Likelihood Score: Higher the better
print("Model Log Likelihood Score: ", model.best_score_)
# Perplexity: Lower the better. Perplexity = exp(-1. * log-likelihood per word)
print("Model Perplexity: ", best_lda_model.perplexity(dtm_tfidf))
#*********** Step 4: Compare LDA Model Performance Scores ***********#
#Get Log Likelyhoods from Grid Search Output
gscore=model.fit(dtm_tfidf).cv_results_
n_topics = [5, 10, 15, 20, 25, 30]
log_likelyhoods_5 = [gscore['mean_test_score'][gscore['params'].index(v)] for v in gscore['params'] if v['learning_decay']==0.5]
log_likelyhoods_7 = [gscore['mean_test_score'][gscore['params'].index(v)] for v in gscore['params'] if v['learning_decay']==0.7]
log_likelyhoods_9 = [gscore['mean_test_score'][gscore['params'].index(v)] for v in gscore['params'] if v['learning_decay']==0.9]
# Show graph
plt.figure(figsize=(12, 8))
plt.plot(n_topics, log_likelyhoods_5, label='0.5')
plt.plot(n_topics, log_likelyhoods_7, label='0.7')
plt.plot(n_topics, log_likelyhoods_9, label='0.9')
plt.title("Choosing Optimal LDA Model")
plt.xlabel("Num Topics")
plt.ylabel("Log Likelyhood Scores")
plt.legend(title='Learning decay', loc='best')
plt.show()
return best_lda_model, dtm_tfidf, tfidf_vectorizer
best_lda_model, dtm_tfidf, tfidf_vectorizer = optimal_lda_model(neg_reviews, 'negative_reviews')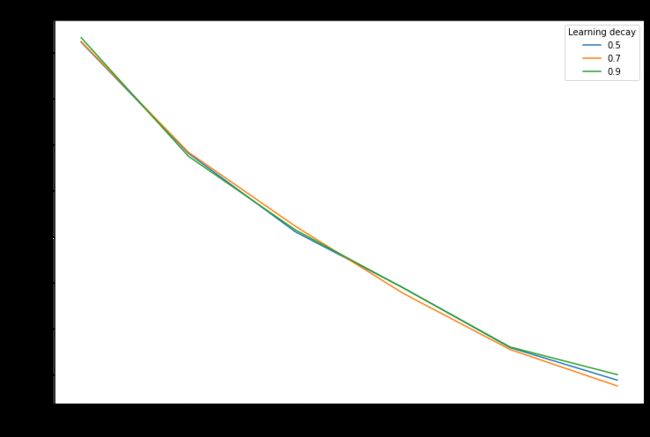
From the graph, we see that there is little impact to choose different learning decay, however, 5 topics would produce the best model.
从图中可以看出,选择不同的学习衰减几乎没有影响,但是5个主题将产生最佳模型。
Now, let’s output the words in the topics we just created.
现在,让我们输出刚刚创建的主题中的单词。
#Create a function to inspect the topics we created
def display_topics(model, feature_names, n_top_words):
'''
INPUTS:
model - the model we created
feature_names - tells us what word each column in the matric represents
n_top_words - number of top words to display
OUTPUTS:
a dataframe that contains the topics we created and the weights of each token
'''
topic_dict = {}
for topic_idx, topic in enumerate(model.components_):
topic_dict["Topic %d words" % (topic_idx+1)]= ['{}'.format(feature_names[i])
for i in topic.argsort()[:-n_top_words - 1:-1]]
topic_dict["Topic %d weights" % (topic_idx+1)]= ['{:.1f}'.format(topic[i])
for i in topic.argsort()[:-n_top_words - 1:-1]]
return pd.DataFrame(topic_dict)
display_topics(best_lda_model, tfidf_vectorizer.get_feature_names(), n_top_words = 20)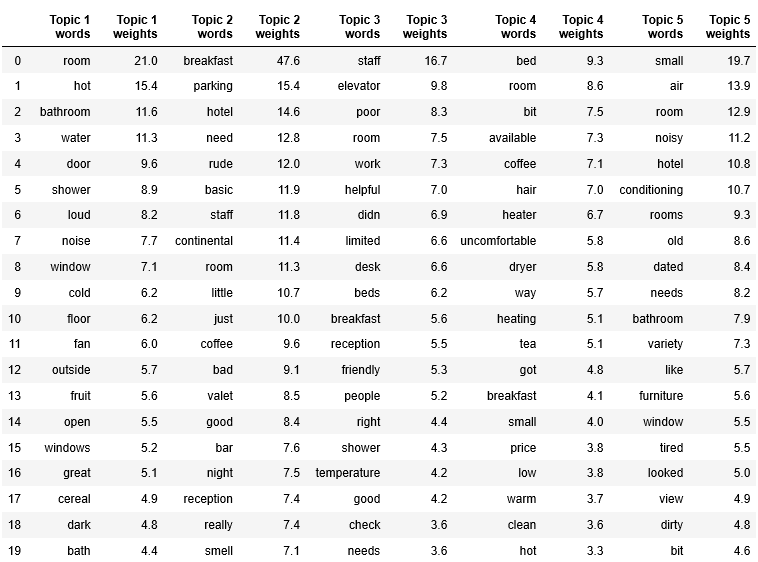
Now, let’s visualize the topics with pyLDAVis Visualization!
现在,让我们使用pyLDAVis Visualization可视化主题!
pyLDAVis is a great tool to interpret individual topics and the relationships between the topics. A good topic model will have fairly big, non-overlapping bubbles scattered throughout the chart instead of being clustered in one quadrant. On the left-hand side of the visualization, each topic is represented by a bubble. The larger the bubble, the more prevalent is that topic. The indices inside the circle indicates the sorted order by the area with the number 1 being the most popular topic, and number 5 being the least popular topic. The distance between two bubbles represents the topic similarity. However, this is just an approximation to the original topic similarity matrix because we are only using a two-dimensional scatter plots to best represent the spatial distribution of all 5 topics.
pyLDAVis是解释单个主题以及主题之间关系的好工具。 一个好的主题模型将有相当大的,不重叠的气泡分散在整个图表中,而不是聚集在一个象限中。 在可视化的左侧,每个主题都用一个气泡表示。 气泡越大,该话题越普遍。 圆圈内的索引指示按区域排序的顺序,数字1是最受欢迎的主题,数字5是最受欢迎的主题。 两个气泡之间的距离代表主题相似度。 但是,这只是原始主题相似度矩阵的近似值,因为我们仅使用二维散点图来最好地表示所有5个主题的空间分布。
The right-hand side shows the top-30 most relevant terms for the topic you select on the left. The blue bar represents the overall term frequency, and the red bar indicates the estimated term frequency within the selected topic. So, if you see a bar with both red and blue, it means the term also appears at other topics. You can hover over the term to see in which topic(s) is the term also included.
右侧显示了与您在左侧选择的主题相关的前30个最相关术语。 蓝色条形表示总的词频,红色条形表示所选主题内的估计词频。 因此,如果您看到红色和蓝色的条形,则表示该术语也出现在其他主题上。 您可以将鼠标悬停在该术语上,以查看该术语还包括在哪些主题中。
You can adjust the relevance metric (λ) by sliding the bar on the top right corner. It helps to strike a balance between the terms that are exclusively popular for the topic you selected when λ=0 and the terms that also appear more in other topics if you slide the λ to the right.
您可以通过滑动右上角的条来调整相关性指标(λ)。 如果您将λ滑动到右侧,则有助于在λ= 0时专门为您选择的主题所用的术语与在其他主题中也会出现的术语之间取得平衡。
# Topic Modelling Visualization for the Negative Reviews
pyLDAvis.sklearn.prepare(best_lda_model, dtm_tfidf, tfidf_vectorizer)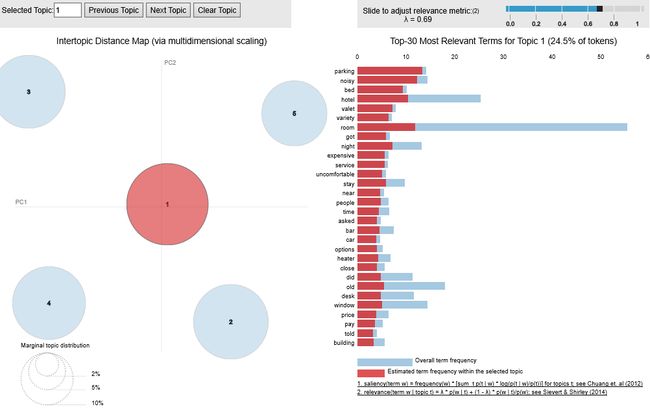
çonclusion(Conclusion)
From the Sentiment Analysis scatter plot, we see that positive reviews are slightly more than the negatives, Hotel Beresford definitely needs to improve hotel guest satisfaction.
从情绪分析散点图中,我们可以看到,正面评价比负面评价稍多,伯雷斯福德酒店绝对需要提高酒店住客满意度。
The WordCloud reveals some problems for the hotel manager to look into, like their breakfast. However, it is probably necessary to read detail reviews about their breakfast to figure out what exactly needs to be improved, maybe coffee or pastries as appeared in the WordCloud. Also, the hotel manager should train staff well to provide friendlier and better services. The hotel may also need to work with issues related to soundproofing, air conditioning, shower system and parking.
WordCloud揭示了酒店经理需要研究的一些问题,例如早餐。 但是,可能有必要阅读有关他们早餐的详细评论,以找出需要改进的地方,例如WordCloud中出现的咖啡或糕点。 此外,酒店经理还应培训员工,以提供更友好,更好的服务。 酒店可能还需要处理有关隔音,空调,淋浴系统和停车的问题。
The EDA section could give the hotel manager a general idea of the reviews as well as the rating distribution. The pyLDAvis interactive visualization would help the hotel manager to further understand what most popular topics within the negative reviews are and make improvements accordingly.
EDA部分可以使酒店经理对评论以及评级分布有一个总体了解。 pyLDAvis交互式可视化将帮助酒店经理进一步了解负面评论中最受欢迎的主题,并做出相应的改进。
未来的工作 (Future Work)
A lot of the analyses are limited due to the size of the scraped data. Here, we are only scraping reviews written in “English.” According to San Francisco Travel Reports, there were 2.9 million international visitors visiting San Francisco in 2019. Visitors from non-English speaking countries are most likely going to leave reviews in their native language. Maybe trying to scrape reviews in other languages and translate the scraped reviews or scrape after translation would help to increase the data volume.
由于抓取数据的大小,许多分析受到限制。 在这里,我们只抓取以“英语”撰写的评论。 根据《旧金山旅行报告》 ,2019年有290万国际游客访问旧金山。来自非英语国家的游客很可能会以其母语发表评论。 也许尝试以其他语言刮取评论并翻译所刮取的评论,或者在翻译后进行刮擦将有助于增加数据量。
To provide more useful suggestions to Hotel Beresford, we may also conduct analysis of its competitors to gain insights of guest preferences as well as valuable information that Hotel Beresford may not get from its own reviews.
为了给贝雷斯福德酒店提供更多有用的建议,我们还可能对其竞争对手进行分析,以了解客人的喜好以及贝雷斯福德酒店可能无法从其自身评论中获得的宝贵信息。
Hope that this analysis could also benefit people who are interested in text analytics. Please check out my GitHub link for the full code and analysis. Thank you!
希望这种分析也可以使对文本分析感兴趣的人受益。 请查看我的GitHub链接以获取完整的代码和分析。 谢谢!
翻译自: https://medium.com/swlh/sentiment-analysis-topic-modeling-for-hotel-reviews-6b83653f5b08
饭店点餐系统的需求分析