机器学习基础概念
机器学习
一般包括监督学习、无监督学习、强化学习
监督学习
- 既有输入,又有输出
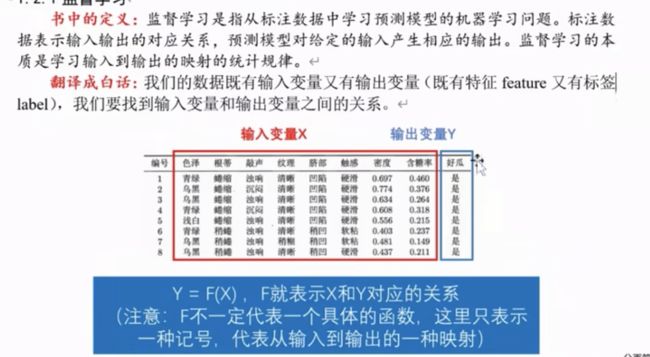
- 根据输出变量Y的数据类型,分为
- 分类问题:Y取有限个离散值
- Y只有两类:二分类问题
- Y有多类:多分类问题
- 回归问题:输出变量Y为连续型变量
- 此回归非回归分析
- 分类问题:Y取有限个离散值
无监督学习
- 聚类
- 降维
强化学习
做对了奖励,做错了惩罚
模型评估指标
这里只介绍有监督学习
回归问题评估指标
- 第一个指标体系


SSE 残差平方和:其量纲是原来数据量纲的平方
MSE均方误差:SSE/样本数n
RMSE均方根误差:MSE开根号
第一个指标体系中RMSE用的比较多
- 第二个指标体系
- 不是平方,而是去了绝对值

分类问题评估指标
混淆矩阵

在机器学习中通常将更关注的事件定义为正类事件
(往往是生活中不好的结果,并不完全绝对)
必须要先定义好,不然后记结果都反了
比如我们这里更关注坏瓜,我们就将坏瓜定义为正类事件。正类为1,负类为0
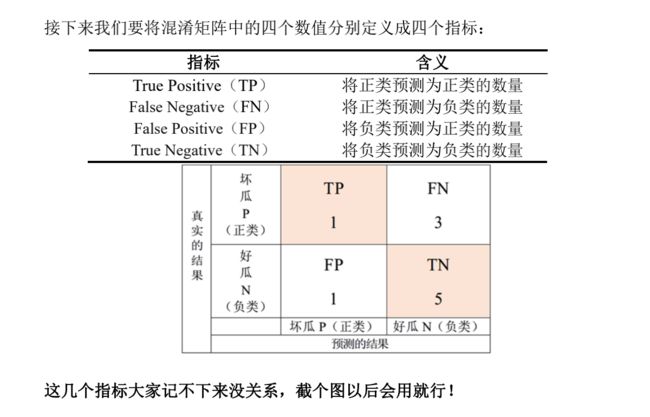
下面开始定义一系列的评估指标
- 分类准确率

这个指标存在局限性,比如一个不平衡样本,分类中一个占比特别多一个特别少,把少的全预测错了,而分类准确率依然很高
- 查全率和查全率


- F1分数

查全率和查准率的调和平均数
单纯看其中哪一个都不是很全面
- ROC曲线和
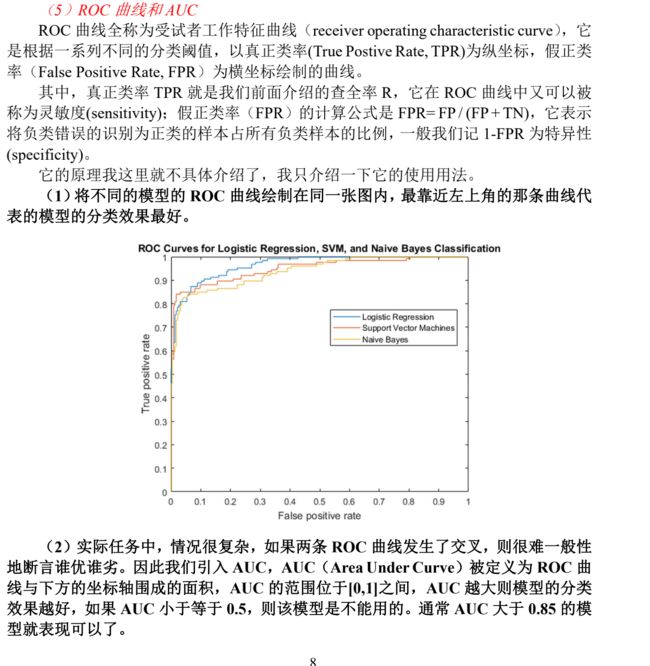
- 纵坐标:真正类率TPR,即查全率R,实际为正类被预测正确的比例
- 横坐标:假正类率FPR,表示负类被错误识别为正类的样本所占所有负类样本的比例
- 比如说用了三个模型做了同一个问题,越靠近左上角的分类效果一般越好
- 如果两条线交叉了,我们可以引入AUC,就是曲线下半部分的面积,AUC越大说明分类效果越好
- AUC小于0.5说明完全错了
- AUC大于0.85说明还不错
模型的泛化能力
模型的泛化能力(generalization ability)是指由该模型对未知数据的预测能力。
还是举西瓜分类的例子,我们利用 100 个西瓜的数据建立了一个模型,不妨称其为“西瓜分类器”,它能帮助我们区分好瓜和坏瓜。
那么我们怎样去评价这个“西瓜分类器”好不好用呢?
有同学会想,前面我们学了那么多用来评价分类结果好坏的评估指标,比如分类准确率、F1 分数、AUC 等。如果这些指标都很大的话不就说明我们的模型很好吗?
事实上这是不够的,我们更加关心的是这个“西瓜分类器”在面对一组新的数据的时候,它的分类能力还是不是足够好。
打个比方,准备期末考试的时候,大家都做课后作业题复习,可能你每道课后题都会做,但上了考场还是啥都不会。
回到我们西瓜分类的例子上,怎么去衡量这个“西瓜分类器”的泛化能力是否强呢?我们可以再去买 20 个西瓜,把这些西瓜的特征数据(输入数据 X)输入到我们的“西瓜分类器”中,然后看它的预测结果(输出结果为 Y);另一方面,我们可以人工去判断这 20 个西瓜是好瓜还是坏瓜,这样就可以得到真实的结果。接下来只需要将预测结果和真实结果进行对比,看看“西瓜分类器”的分类准确率是不是很高。如果“西瓜分类器”表现的很好,那就说它的泛化能力很强;如果“西瓜分类器”表现的很糟糕,那么它的泛化能力就很弱,这时候你就要怀疑我们的“西瓜分类器”的模型是否存在问题。
留出法:划分训练集与测试集
前面我们为了衡量“西瓜分类器”的泛化能力,我们又买了 20 个西瓜用于测试。
但大多少时候我们获取新的测试样本的成本较高,例如银行判断申请贷款的客户是否会违约时,需要等到客户还钱的时候才知道结果。因此,我们需要想一个办法,只使用已有的样本数据来对模型的泛化能力进行一个评价。
实际上这个办法很容易想到:还是假设我们现在有 100 个西瓜的数据,这些西瓜的特征数据 X 以及是否为好瓜 Y 我们是知道的。
我们只拿出 80 个西瓜来训练我们的“西瓜分类器”,剩下的 20 个西瓜我们假装不知道它们是好瓜还是坏瓜。接下来,我们把这 20 个西瓜的 X 输入到我们的“西瓜分类器”中,来得到预测结果,并和这 20 个西瓜的真实类别进行对比来计算分类准确率,这个结果就能反映模型的泛化能力的好坏。我们将这里的 80 个西瓜称为训练集(train set),它们用来训练我们的模型,得到我们模型中的待估参数;剩下的 20 个西瓜我们不参与模型的训练过程,只用来最后对模型的好坏进行测试,因此被称为测试集(test set)。我们将上面这种对泛化能力进行评估的方法称为留出法(Hold-Out)。
有以下几点要说明:
(1) 假设我们总共的样本量为 N,我们要将其划分为训练集和测试集,这两个集合的划分比例通常设置为:6:4、7:3 或 8:2。
(2) 训练集和测试集的划分既要随机,又要尽可能保持数据分布的一致性(在分类问题中就是类别比例的相似),例如原来 100 个瓜中有 60 个好瓜,40个坏瓜,那么你按照 8:2 的比例生成训练集和测试集时,尽量保证测试集中的 20 个样本内有 12 个好瓜和 8 个坏瓜。在分类任务中,保留类别比例的采样方法称为分层采样(stratified sampling)。
下面请大家思考一下留出法有什么缺陷?
交叉检验
在留出法中,用于评价模型泛化能力的测试集只是所有样本的一部分,而且这个结果不是很稳定,对模型的泛化能力的评价依赖于哪些样本点落入训练集,哪些样本点在测试集。
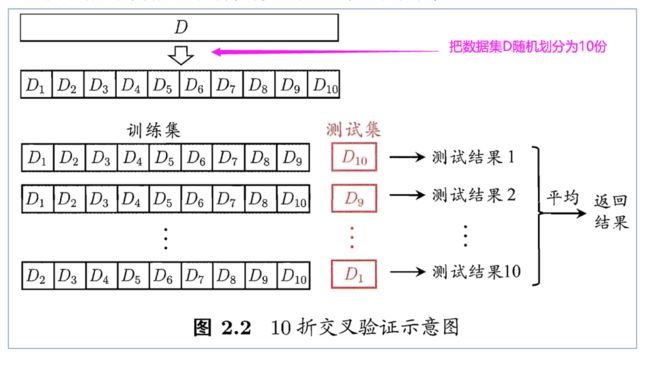
下面我们介绍一种用的更多的方法:k折交叉验证(K-fold cross-validation)。
我们先将数据集 D 随机的划分为 k 个大小相似的互斥子集。每一次用 k-1 个子集的并集作为训练集,剩下的一个子集作为测试集;这样就可以获得 k 组训练/测试集,从而可进行 k 次训练和测试,最终返回的是这 k 次测试的平均结果,通常 k 取 10,此时称为 10 折交叉验证。
下面的图片来自周志华老师的机器学习一书,非常形象:

选择最好的模型
对于同一个问题,我们可以建立不同的模型去解决。例如前面介绍的西瓜分类问题中,我们可以使用决策树、K 最近邻(KNN)、支持向量机(SVM)等常用的机器学习模型。那么,我们应该怎样衡量一个模型的好坏呢?
我们前面介绍了留出法和交叉验证法,这里面都需要将数据分成训练集和测试集。因此,我们可以在同一个训练集下,分别对这些模型进行训练,然后将这些模型分别在测试集上进行预测,并比较不同模型的泛化能力,我们选择泛化能力最好的模型。
(该模型在测试集上的表现最好,例如误差最小,具体的评价指标在前面有介绍)
另外,大多数的模型中都需要设定一些参数(parameter),参数不同得到的结果可能有很明显的差异。因此,除了要对模型进行选择外,还需要对模型中的参数进行设定,这就是机器学习中常说的**“参数调节”或简称“调参”**(parameter tuning)。通常调参依赖于经验,我们后面会介绍网格搜索的方法,来自动搜索使模型效果最好的参数。
下面这一点很容易被大家忽视,这在周志华老师的书中有介绍。
给定包含 N 个样本的数据集 D,在选择模型的过程中,因为需要留出测试集的数据进行评估测试,所以我们只使用了训练集的数据来训练模型,这会导致测试集的信息在训练模型的过程中没有被利用到。因此,在模型选择和参数都调整完成后,我们应该使用完整的数据集 D 来重新训练模型。这个模型在训练过程中使用了所有 N 个样本,这才是我们最终需要的模型。
意思就是前面交叉验证啥的,只是为了选出调参和选出哪种模型。真正的模型需要用所有的数据重新进行训练。
过拟合和欠拟合
过拟合(overfitting)指的是模型在训练集上表现的很好,但是在测试集上表现的并不理想,也就是说模型对未知样本的预测表现一般,泛化能力较差。
如果模型不仅在训练数据集上的预测结果不好,而且在测试数据集上的表现也不理想,也就是说两者的表现都很糟糕,那么我们有理由怀疑模型发生了欠拟合(underfitting)现象。
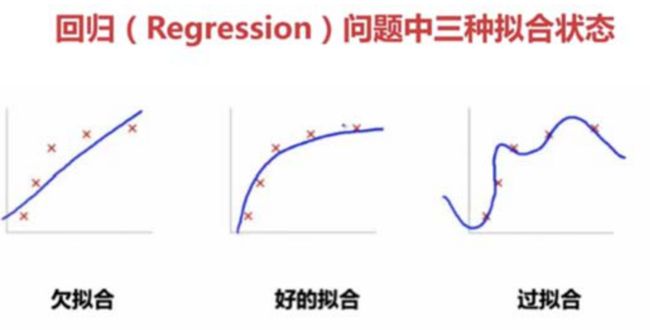


可能产生过拟合的常见原因:
(1) 模型中参数设置的过多导致模型过于复杂
(2) 训练集的样本量不够
(3) 输入了某些完全错误的特征
举个极端的例子:样本的编号。现在有 100 个西瓜,编号 1-60 的是好瓜,编号 61-100 的是坏瓜,如果你把编号作为了输入变量放入了我们的模型,那么有可能模型会将编号作为一个最重要的识别变量来对西瓜进行分类,模型会认为只要编号小于等于 60 的都是好瓜,此时在训练集上的误差一定为 0。。。。。。如果这时候你拿来编号大于 100 的需要判断好坏的瓜,模型都会认为是坏瓜!
解决过拟合的方法:
(1) 通过前面介绍的交叉验证的方法来选择合适的模型,并对参数进行调节。
(2) 扩大样本数量、训练更多的数据
(3) 对模型中的参数增加正则化(即增加惩罚项,参数越多惩罚越大)
解决欠拟合的方法:
欠拟合则和过拟合刚好相反,我们可以增加模型的参数、或者选择更加复杂的模型;也可以从数据中挖掘更多的特征来增加输入的变量,还可以使用一些集成算法(如装袋法(Bagging),提升法(Boosting))。
(注意:有可能模型的输入和输出一点关系都没有,举个极端的例子,你买的西瓜好坏和你的个人特征没任何关系,例如你的性别身高体重等)
关于欠拟合和过拟合的问题,我这里介绍的只是一个大概的思想。事实上,针对不同的机器学习算法,通常有特定的应对思路,例如在树模型中,我们可以控制树的深度来防止过拟合、神经网络在训练过程中使用dropout 的策略来缩减参数量避免过拟合。有兴趣深入了解的同学可以学习前面介绍的机器学习通识课程。
以后大家只需要知道这两个概念就可以啦,总而言之我们要保证我们的模型在测试集上表现的足够好。