docker搭建prometheus+node-exporter
#下载所需镜像
[root@iZ2zehf4k8wz7kksitgvc3Z ~]#docker pull prom/prometheus
[root@iZ2zehf4k8wz7kksitgvc3Z ~]# docker pull grafana/grafana
[root@iZ2zehf4k8wz7kksitgvc3Z ~]#docker pull prom/node-exporter
[root@iZ2zehf4k8wz7kksitgvc3Z ~]#docker pull prom/alertmanager
[root@iZ2zehf4k8wz7kksitgvc3Z ~]#docker pull timonwong/prometheus-webhook-dingtalk
[root@iZ2zehf4k8wz7kksitgvc3Z ~]#docker pull prom/mysqld-exporter
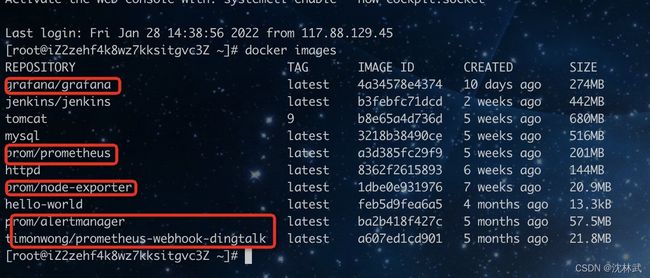
下载好镜像后查看镜像
[root@iZ2zehf4k8wz7kksitgvc3Z ~]# docker images
创建目录
mkdir -p /data/prometheus/server
#prometheus数据存放目录
mkdir /data/prometheus/prometheusdata
#grafana数据存放目录
mkdir /data/grafana-storage
#配置报警规则需要
touch /data/prometheus/server/rules.yml
#配置Prometheus.yml配置文件
vim data/prometheus/server/prometheus.yml
设置相应读写执行权限
[root@iZ2zehf4k8wz7kksitgvc3Z server]# chmod 777 /data/prometheus/server/rules.yml
[root@iZ2zehf4k8wz7kksitgvc3Z server]# chmod 777 -R /data/prometheus//prometheusdata/
[root@iZ2zehf4k8wz7kksitgvc3Z server]# chmod 777 -R /data/grafana-storage

Prometheus.yml配置文件编写 # 创建Prometheus.yml配置文件 data/prometheus/server/prometheus.yml
global:
scrape_interval: 60s #默认抓取周期,可用单位ms,smhdwy 设置每15s采集数据一次,默认一分钟
evaluation_interval: 60s #估算规则的默认周期 # 每15秒计算一次规则。默认1分钟
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ["172.20.226.XXX:9093"]
rule_files:
- "/data/prometheus//server/rules.yml"
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['172.20.226.XXX:9090']
labels:
instance: prometheus
- job_name: node
static_configs:
- targets: ['172.20.226.XXX:9100']
labels:
instance: node
- job_name: cadvisor
static_configs:
- targets: ['172.20.226.XXX:8080']
labels:
instance: cadvisor
- job_name: mysqld
static_configs:
- targets: ['172.20.226.XXX:9104']
labels:
instance: mysqld
Rules.yml配置文件编写
groups:
- name: Warning
rules:
- alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes) / node_memory_MemTotal_bytes*100 > 80
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: 内存使用率过高"
description: "{{$labels.instance}}: 内存使用率大于 80% (当前值: {{ $value }}"
- alert: NodeCpuUsage
expr: (1-((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) / (sum(increase(node_cpu_seconds_total[1m])) by (instance)))) * 100 > 70
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: CPU使用率过高"
description: "{{$labels.instance}}: CPU使用率大于 70% (当前值: {{ $value }}"
- alert: NodeDiskUsage
expr: 100 - node_filesystem_free_bytes{fstype=~"xfs|ext4"} / node_filesystem_size_bytes{fstype=~"xfs|ext4"} * 100 > 80
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: 分区使用率过高"
description: "{{$labels.instance}}: 分区使用大于 80% (当前值: {{ $value }}"
- alert: Node-UP
expr: up{job='node-exporter'} == 0
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: 服务宕机"
description: "{{$labels.instance}}: 服务中断超过1分钟"
- alert: TCP
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: TCP连接过高"
description: "{{$labels.instance}}: 连接大于1000 (当前值: {{$value}})"
- alert: IO
expr: 100 - (avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: 流入磁盘IO使用率过高"
description: "{{$labels.instance}}:流入磁盘IO大于60% (当前值:{{$value}})"
alertmanager.yml配置文件编写
global:
resolve_timeout: 5m
route:
group_by: ['service', 'alertname', 'cluster']
group_interval: 5m
group_wait: 10s
repeat_interval: 5m
receiver: webhook
routes:
- match:
severity: 'Critical'
receiver: 'webhook'
- match_re:
severity: ^(Warning|Disaster)$
receiver: 'webhook'
receivers:
- name: 'webhook'
webhook_configs:
- url: http://172.20.226.XXX:8060/dingtalk/webhook1/send #ip设置成启动alertmanager地址
send_resolved: true
启动Prometheus容器
#启动命令 关键地址/data/prometheus/server/prometheus.yml,/data/prometheus/server/rules.yml就是创建文档的绝对路径
docker run -d --restart always --name prometheus -p 9090:9090 -v /data/prometheus/server/prometheus.yml:/etc/prometheus/prometheus.yml -v /data/prometheus/server/rules.yml:/etc/prometheus/rules.yml -v /data/prometheus/prometheusdata:/prometheus prom/prometheus --config.file=/etc/prometheus/prometheus.yml --web.enable-lifecycle
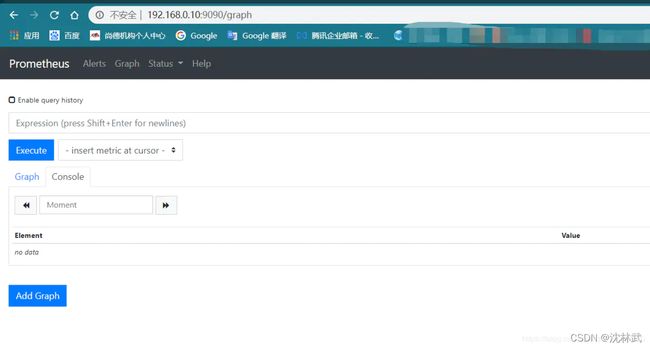
验证Prometheus容器启动成功,外部访问(外网ip):9090/graph和(外网ip):9090/targets

启动cadvisor,负责监控主机 #(外网ip):8080/containers
docker run -d -p 8080:8080 --name cadvisor --privileged=true -v /:/rootfs:ro -v /var/run:/var/run:rw -v /sys:/sys:ro -v /var/lib/docker/:/var/lib/docker:ro google/cadvisor:latest

启动mysqld-exporter,负责监控mysql,DATA_SOURCE_NAME=用户名:密码@mysql主机号:端口号
docker run -d -p 9104:9104 -e DATA_SOURCE_NAME="root:123456@(172.20.226.XXX:3306)/" prom/mysqld-exporter
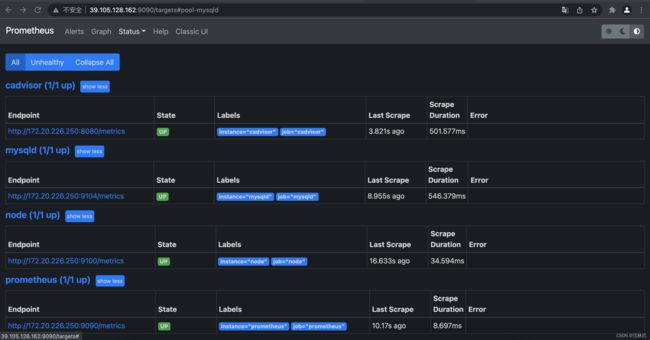
所有监控启动验证
启动grafana容器,负责图形化展示
docker run -d --restart always -p 3000:3000 --name=grafana -v /data/grafana-storage:/var/lib/grafana grafana/grafana
我们使用grafana来做展示数据;使用创建好的grafana容器
访问地址 XX.XXX.XXX.XXX:3000/login,用户名密码都是admin
登入后添加prometheus数据源

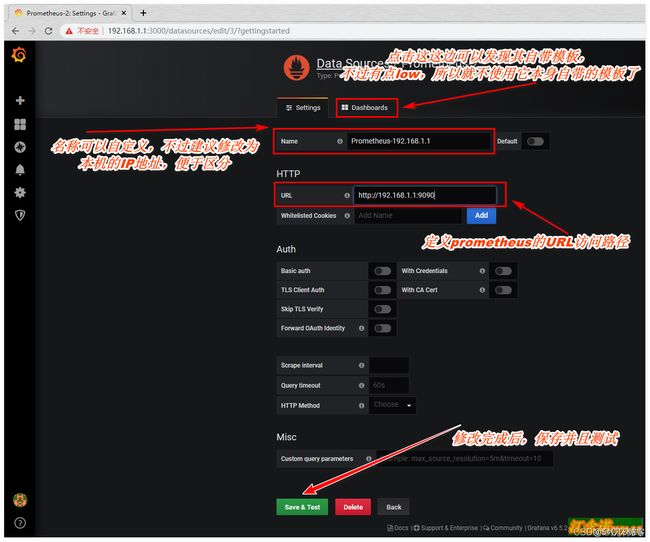
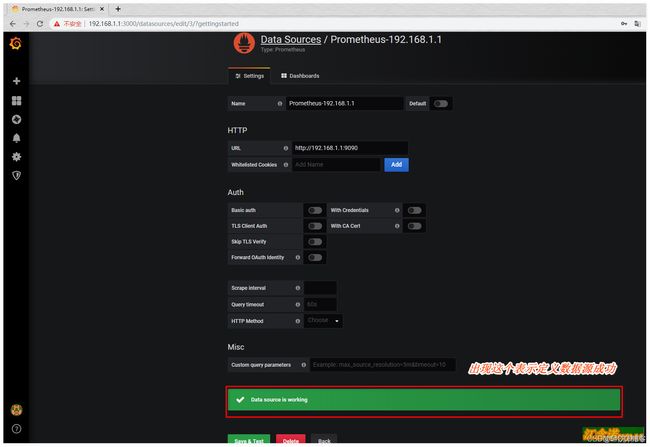
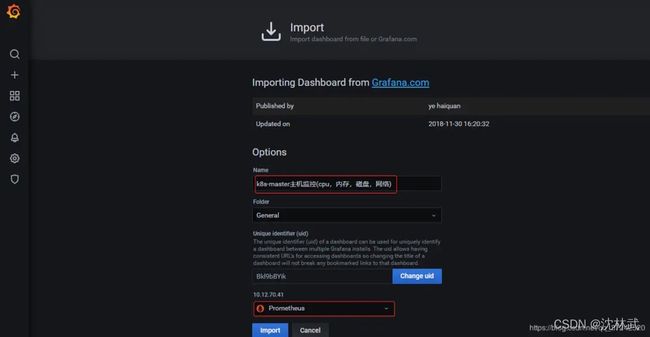
导入模板1、docker模板
搜索导入193模板
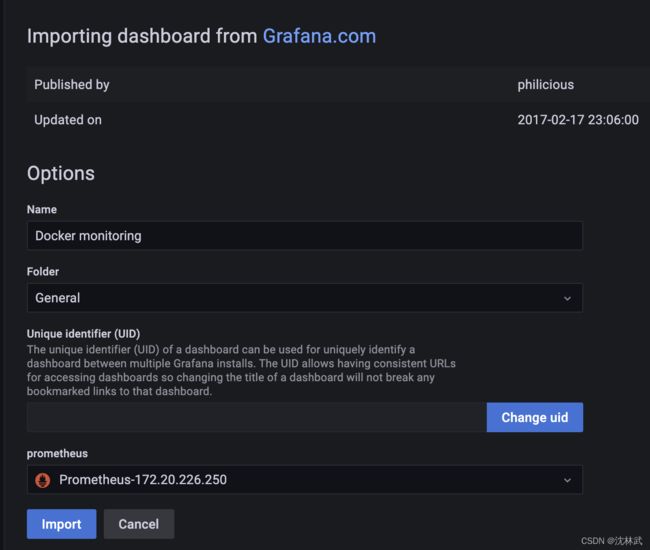
2、主机监控
搜索导入9276/8919模板

3、mysql模板
搜索导入7362模板