复盘离线电商数仓3.0项目–数据开发梳理
复盘离线电商数仓项目–数据开发梳理
-
业务数据
-
数仓分层
-
ods层到ads层的开发
-
开源BI工具Superset
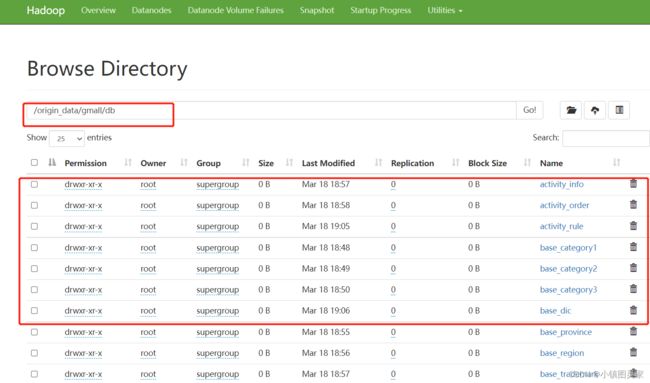
ODS层业务数据&日志数据
ods层业务数据
-
使用Sqoop脚本从Mysql数据库拉取数据落盘到hdfs
-
然后创建ods层的外部表_分区表
-
使用封装好的shell脚本将数据load到对应的表中,脚本如下(参考模板):
-
#!/bin/bash APP=gmall hive=/opt/module/hive/bin/hive # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天 if [ -n "$2" ] ;then do_date=$2 else do_date=`date -d "-1 day" +%F` fi sql1=" load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table ${APP}.ods_order_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table ${APP}.ods_order_detail partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/sku_info/$do_date' OVERWRITE into table ${APP}.ods_sku_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/user_info/$do_date' OVERWRITE into table ${APP}.ods_user_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/payment_info/$do_date' OVERWRITE into table ${APP}.ods_payment_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/base_category1/$do_date' OVERWRITE into table ${APP}.ods_base_category1 partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/base_category2/$do_date' OVERWRITE into table ${APP}.ods_base_category2 partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/base_category3/$do_date' OVERWRITE into table ${APP}.ods_base_category3 partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/base_trademark/$do_date' OVERWRITE into table ${APP}.ods_base_trademark partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/activity_info/$do_date' OVERWRITE into table ${APP}.ods_activity_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/activity_order/$do_date' OVERWRITE into table ${APP}.ods_activity_order partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/cart_info/$do_date' OVERWRITE into table ${APP}.ods_cart_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/comment_info/$do_date' OVERWRITE into table ${APP}.ods_comment_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/coupon_info/$do_date' OVERWRITE into table ${APP}.ods_coupon_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/coupon_use/$do_date' OVERWRITE into table ${APP}.ods_coupon_use partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/favor_info/$do_date' OVERWRITE into table ${APP}.ods_favor_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/order_refund_info/$do_date' OVERWRITE into table ${APP}.ods_order_refund_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/order_status_log/$do_date' OVERWRITE into table ${APP}.ods_order_status_log partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/spu_info/$do_date' OVERWRITE into table ${APP}.ods_spu_info partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/activity_rule/$do_date' OVERWRITE into table ${APP}.ods_activity_rule partition(dt='$do_date'); load data inpath '/origin_data/$APP/db/base_dic/$do_date' OVERWRITE into table ${APP}.ods_base_dic partition(dt='$do_date'); " sql2=" load data inpath '/origin_data/$APP/db/base_province/$do_date' OVERWRITE into table ${APP}.ods_base_province; load data inpath '/origin_data/$APP/db/base_region/$do_date' OVERWRITE into table ${APP}.ods_base_region; " case $1 in "first"){ $hive -e "$sql1$sql2" };; "all"){ $hive -e "$sql1" };; esac -
修改脚本权限为可执行:chmod 777 hdfs_to_ods_db.sh
-
脚本执行与传参,cd到脚本的目录下,hdfs_to_ods_db.sh first 2022-03-17
- 传参:first为首次加载数据,为加载数据的日期,也就是为分区字段传的参数变量
ods层日志数据
-
启动kafka和Flume服务,执行Flume脚本去拉取日志数据到ods_log,数据落盘到hdfs
-
创建日志表 ods_log
-

-
1)创建支持 lzo 压缩的分区表
-
hive (gmall)> drop table if exists ods_log; --将整个json存入表中 CREATE EXTERNAL TABLE ods_log (line string) PARTITIONED BY (`dt` string) -- 按照时间创建分区 STORED AS -- 指定存储方式,读数据采用 LzoTextInputFormat; INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '/warehouse/gmall/ods/ods_log' -- 指定数据在 hdfs 上的存储位置; -
2)加载数据–load数据到表中
-
hive (gmall)> load data inpath '/origin_data/gmall/log/topic_log/2020-06-14' into table ods_log partition(dt='2020-06-14'); --注意:时间格式都配置成 YYYY-MM-DD 格式,这是 Hive 默认支持的时间格式 -
查看是否加载成功
-
hive (gmall)> select * from ods_log limit 2; -
为 lzo 压缩文件创建索引
-
[atguigu@hadoop102 bin]$ hadoop jar /opt/module/hadoop3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer -Dmapreduce.job.queuename=hive /warehouse/gmall/ods/ods_log/dt=2020-06-14 -
ODS 层加载数据脚本,vim hdfs_to_ods_log.sh
-
#!/bin/bash # 定义变量方便修改 APP=gmall hive=/opt/module/hive/bin/hive hadoop=/opt/module/hadoop-3.1.3/bin/hadoop # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天 if [ -n "$1" ] ;then do_date=$1 else do_date=`date -d "-1 day" +%F` fi echo ================== 日志日期为 $do_date ================== sql=" load data inpath '/origin_data/$APP/log/topic_log/$do_date' into table ${APP}.ods_log partition(dt='$do_date'); " $hive -e "$sql" $hadoop jar /opt/module/hadoop3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer - Dmapreduce.job.queuename=hive /warehouse/$APP/ods/ods_log/dt=$do_date -
赋予脚本执行权限 chmod 777 hdfs_to_ods_log.sh
-
使用脚本加载数据—>hdfs_to_ods_log.sh 2022-03-17
- 执行脚本时后跟要加载数据的日期,对应日期分区字段
-
数仓DWD层
dwd层做三件事:
- 1)对用户行为数据解析。
- 2)对核心数据进行判空过滤。
- 3)对业务数据采用维度模型重新建模。
DWD 层(用户行为日志解析)
我们要收集和分析的数据主要包括:页面数据、事件数据、曝光数据、启动数据和错误数据。
-
用户行为日志数据按内容划分为五种类型
-
页面数据
-
事件数据
-
曝光数据
-
启动数据
-
错误数据
-
-
用户行为数据按结构划分为两类:
- 页面埋点生成的日志
- 启动时生成的日志
数据埋点
主流埋点方式
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点三种。
代码埋点是通过调用埋点 SDK 函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。
- 例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用 SDK 提供的数据发送接口,来发送数据。
可视化埋点 只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的 “圈选” 功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入 SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
埋点数据日志结构
我们的日志结构大致可分为两类,一是普通页面埋点日志,二是启动日志。
普通页面日志结构如下,每条日志包含了,当前页面的页面信息,所有事件(动作)、所有曝光信息以及错误信息。除此之外,还包含了一系列公共信息,包括设备信息,地理位置,应用信息等,即下边的 common 字段。
1)普通页面埋点日志格式
{
"common": { -- 公共信息
"ar": "230000", -- 地区编码
"ba": "iPhone", -- 手机品牌
"ch": "Appstore", -- 渠道
"md": "iPhone 8", -- 手机型号
"mid": "YXfhjAYH6As2z9Iq", -- 设备 id
"os": "iOS 13.2.9", -- 操作系统
"uid": "485", -- 会员 id
"vc": "v2.1.134" -- app 版本号
},
"actions": [ --动作(事件)
{
"action_id": "favor_add", --动作 id
"item": "3", --目标 id
"item_type": "sku_id", --目标类型
"ts": 1585744376605 --动作时间戳
}
],
"displays": [
{
"displayType": "query", -- 曝光类型
"item": "3", -- 曝光对象 id
"item_type": "sku_id", -- 曝光对象类型
"order": 1 --出现顺序
},
{
"displayType": "promotion",
"item": "6",
"item_type": "sku_id",
"order": 2
},
{
"displayType": "promotion",
"item": "9",
"item_type": "sku_id",
"order": 3
},
{
"displayType": "recommend",
"item": "6",
"item_type": "sku_id",
order": 4
},
{
"displayType": "query ",
"item": "6",
"item_type": "sku_id",
"order": 5
}
],
"page": { --页面信息
"during_time": 7648, -- 持续时间毫秒
"item": "3", -- 目标 id
"item_type": "sku_id", -- 目标类型
"last_page_id": "login", -- 上页类型
"page_id": "good_detail", -- 页面 ID
"sourceType": "promotion" -- 来源类型
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744374423 --跳入时间戳
}
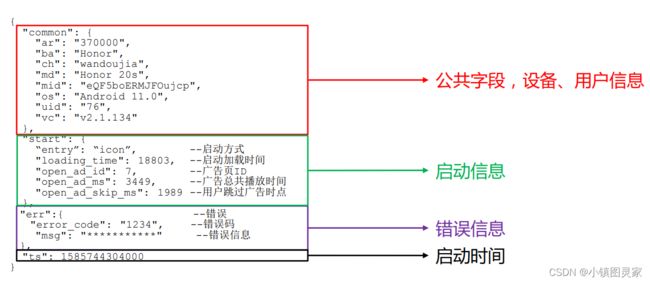
2)启动日志格式
启动日志结构相对简单,主要包含公共信息,启动信息和错误信息。
{
"common": {
"ar": "370000",
"ba": "Honor",
"ch": "wandoujia",
"md": "Honor 20s",
"mid": "eQF5boERMJFOujcp",
"os": "Android 11.0",
"uid": "76",
"vc": "v2.1.134"
},
"start": {
"entry": "icon", --icon 手机图标 notice 通知 install
安装后启动
"loading_time": 18803, --启动加载时间
"open_ad_id": 7, --广告页 ID
"open_ad_ms": 3449, -- 广告总共播放时间
"open_ad_skip_ms": 1989 -- 用户跳过广告时点
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744304000
}
埋点数据上报时机
埋点数据上报时机包括两种方式。
- 方式一,在离开该页面时,上传在这个页面产生的所有数据(页面、事件、曝光、错误等)。优点,批处理,减少了服务器接收数据压力。缺点,不是特别及时。
- 方式二,每个事件、动作、错误等,产生后,立即发送。优点,响应及时。缺点,对服
务器接收数据压力比较大。
日志格式回顾
(1)页面埋点日志

(2)启动日志
使用get_json_object函数解析json字段
-
1)数据
-
[{"name":" 大 郎 ","sex":" 男 ","age":"25"},{"name":" 西 门 庆 ","sex":"男","age":"47"}]
-
-
2)取出第一个 json 对象
hive (gmall)>
select get_json_object('[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]', '$[0]');
结果是:{“name”:“大郎”,“sex”:“男”,“age”:“25”}
- 3)取出第一个 json 的 age 字段的值
hive (gmall)>
SELECT get_json_object('[{"name":" 大 郎 ","sex":" 男","age":"25"},{"name":"西门 庆","sex":"男","age":"47"}]',"$[0].age");
结果是:25
启动日志表
启动日志解析思路:启动日志表中每行数据对应一个启动记录,一个启动记录应该包含日志中的公共信息和启动信息。先将所有包含 start 字段的日志过滤出来,然后使用get_json_object 函数解析每个字段。

-
- 建表语句
-
drop table if exists dwd_start_log; CREATE EXTERNAL TABLE dwd_start_log( `area_code` string COMMENT '地区编码', `brand` string COMMENT '手机品牌', `channel` string COMMENT '渠道', `model` string COMMENT '手机型号', `mid_id` string COMMENT '设备 id', `os` string COMMENT '操作系统', `user_id` string COMMENT '会员 id', `version_code` string COMMENT 'app 版本号', `entry` string COMMENT ' icon 手机图标 notice 通知 install 安装后启动', `loading_time` bigint COMMENT '启动加载时间', `open_ad_id` string COMMENT '广告页 ID ', `open_ad_ms` bigint COMMENT '广告总共播放时间', `open_ad_skip_ms` bigint COMMENT '用户跳过广告时点', `ts` bigint COMMENT '时间' ) COMMENT '启动日志表' PARTITIONED BY (dt string) -- 按照时间创建分区 stored as parquet -- 采用 parquet 列式存储 LOCATION '/warehouse/gmall/dwd/dwd_start_log' -- 指定在 HDFS 上存储位置 TBLPROPERTIES('parquet.compression'='lzo'); -- 采用 LZO 压缩 -
说明:数据采用 parquet 存储方式,是可以支持切片的,不需要再对数据创建索引。如果单纯的 text 方式存储数据,需要采用支持切片的,lzop 压缩方式并创建索引。
-
2)数据导入
- 此处使用insert overwrite 代替insert into向启动日志表中插入数据,由于dwd层后期会使用调度工具每天定时执行,因此使用insert overwrite。
- 数据来源于ods_log表,该表只有一个字段,将整个json存入表中,这里使用get_json_object()函数解析json字段;比如:获取json中公共字段—> ar 地区编码 get_json_object(line, ‘$.common.ar’)
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFo
rmat;
insert overwrite table dwd_start_log partition(dt='2020-06-14')
select
get_json_object(line,'$.common.ar'), ---- 地区编码
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.start.entry'),
get_json_object(line,'$.start.loading_time'),
get_json_object(line,'$.start.open_ad_id'),
get_json_object(line,'$.start.open_ad_ms'),
get_json_object(line,'$.start.open_ad_skip_ms'),
get_json_object(line,'$.ts')
from ods_log
where dt='2020-06-14'and get_json_object(line,'$.start') is not null;
3)查看数据
select * from dwd_start_log where dt='2020-06-14' limit 2;
--查询数据有多少行
select count(*) from ods_log;
-- 结果2959
页面日志表

页面日志解析思路:
页面日志表中每行数据对应一个页面访问记录,一个页面访问记录应该包含日志中的公共信息和页面信息。 先将所有包含 page 字段的日志过滤出来,然后使用 get_json_object 函数解析每个字段。
1)建表语句
drop table if exists dwd_page_log;
CREATE EXTERNAL TABLE dwd_page_log(
`area_code` string COMMENT '地区编码',
`brand` string COMMENT '手机品牌',
`channel` string COMMENT '渠道',
`model` string COMMENT '手机型号',
`mid_id` string COMMENT '设备 id',
`os` string COMMENT '操作系统',
`user_id` string COMMENT '会员 id',
`version_code` string COMMENT 'app 版本号',
`during_time` bigint COMMENT '持续时间毫秒',
`page_item` string COMMENT '目标 id ',
`page_item_type` string COMMENT '目标类型',
`last_page_id` string COMMENT '上页类型',
`page_id` string COMMENT '页面 ID ',
`source_type` string COMMENT '来源类型',
`ts` bigint
) COMMENT '页面日志表'
PARTITIONED BY (dt string)
stored as parquet
LOCATION '/warehouse/gmall/dwd/dwd_page_log'
TBLPROPERTIES('parquet.compression'='lzo');
2)数据导入
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFo
rmat;
insert overwrite table dwd_page_log partition(dt='2022-03-17')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.ts')
from ods_log
where dt='2022-03-17'
and get_json_object(line,'$.page') is not null;
3)查看数据
select * from dwd_page_log where dt='2020-06-14' limit 2;
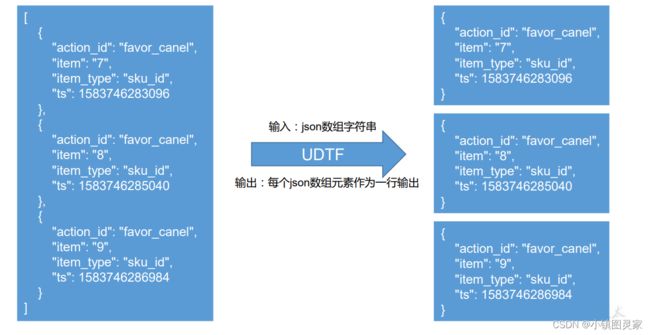
动作日志表

动作日志解析思路:
动作日志表中每行数据对应用户的一个动作记录,一个动作记录应当包含公共信息、页面信息以及动作信息。先将包含 action 字段的日志过滤出来,然后通过UDTF 函数,将 action 数组“炸开”(类似于 explode 函数的效果),然后使用 get_json_object函数解析每个字段。
1)建表语句
drop table if exists dwd_action_log;
CREATE EXTERNAL TABLE dwd_action_log(
`area_code` string COMMENT '地区编码',
`brand` string COMMENT '手机品牌',
`channel` string COMMENT '渠道',
`model` string COMMENT '手机型号',
`mid_id` string COMMENT '设备 id',
`os` string COMMENT '操作系统',
`user_id` string COMMENT '会员 id',
`version_code` string COMMENT 'app 版本号',
`during_time` bigint COMMENT '持续时间毫秒',
`page_item` string COMMENT '目标 id ',
`page_item_type` string COMMENT '目标类型',
`last_page_id` string COMMENT '上页类型',
`page_id` string COMMENT '页面 id ',
`source_type` string COMMENT '来源类型',
`action_id` string COMMENT '动作 id',
`item` string COMMENT '目标 id ',
`item_type` string COMMENT '目标类型',
`ts` bigint COMMENT '时间'
) COMMENT '动作日志表'
PARTITIONED BY (dt string)
stored as parquet
LOCATION '/warehouse/gmall/dwd/dwd_action_log'
TBLPROPERTIES('parquet.compression'='lzo');
2)创建 UDTF 函数——设计思路
思路:

3)创建 UDTF 函数——编写代码略
4)创建函数
-
(1)打包
-
(2)将 hivefunction-1.0-SNAPSHOT.jar 上传到 hadoop102 的/opt/module,然后再将该jar 包上传到 HDFS 的/user/hive/jars 路径下
-
hadoop fs -mkdir -p /user/hive/jars hadoop fs -put hivefunction-1.0-SNAPSHOT.jar /user/hive/jars
-
-
(3)创建永久函数与开发好的 java class 关联
-
create function explode_json_array as 'com.xxx.hive.udtf.ExplodeJSONArray' using jar 'hdfs://hadoop102:8020/user/hive/jars/hivefunction-1.0-SNAPSHOT.jar';
-
-
(4)注意:如果修改了自定义函数重新生成 jar 包怎么处理?只需要替换 HDFS 路径上的旧 jar 包,然后重启 Hive 客户端即可。
5)数据导入
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFo rmat;
insert overwrite table dwd_action_log partition(dt='2022-03-17')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(action,'$.action_id'),
get_json_object(action,'$.item'),
get_json_object(action,'$.item_type'),
get_json_object(action,'$.ts')
from ods_log lateral view
explode_json_array(get_json_object(line,'$.actions')) tmp as
action
where dt='2022-03-17'and get_json_object(line,'$.actions') is not null;
6)查看数据
select * from dwd_action_log where dt='2020-06-14' limit 2;
曝光日志表

曝光日志解析思路:
曝光日志表中每行数据对应一个曝光记录,一个曝光记录应当包含公共信息、页面信息以及曝光信息。先将包含 display 字段的日志过滤出来,然后通过 UDTF函数,将 display 数组“炸开”(类似于 explode 函数的效果),然后使用get_json_object 函数解析每个字段。
1)建表语句
drop table if exists dwd_display_log;
CREATE EXTERNAL TABLE dwd_display_log(
`area_code` string COMMENT '地区编码',
`brand` string COMMENT '手机品牌',
`channel` string COMMENT '渠道',
`model` string COMMENT '手机型号',
`mid_id` string COMMENT '设备 id',
`os` string COMMENT '操作系统',
`user_id` string COMMENT '会员 id',
`version_code` string COMMENT 'app 版本号',
`during_time` bigint COMMENT 'app 版本号',
`page_item` string COMMENT '目标 id ',
`page_item_type` string COMMENT '目标类型',
`last_page_id` string COMMENT '上页类型',
`page_id` string COMMENT '页面 ID ',
`source_type` string COMMENT '来源类型',
`ts` bigint COMMENT 'app 版本号',
`display_type` string COMMENT '曝光类型',
`item` string COMMENT '曝光对象 id ',
`item_type` string COMMENT 'app 版本号',
`order` bigint COMMENT '出现顺序'
) COMMENT '曝光日志表'
PARTITIONED BY (dt string)
stored as parquet
LOCATION '/warehouse/gmall/dwd/dwd_display_log'
TBLPROPERTIES('parquet.compression'='lzo');
2)数据导入
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFo
rmat;
insert overwrite table dwd_display_log partition(dt='2022-03-17')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.ts'),
get_json_object(display,'$.displayType'),
get_json_object(display,'$.item'),
get_json_object(display,'$.item_type'),
get_json_object(display,'$.order')
from ods_log lateral view
explode_json_array(get_json_object(line,'$.displays')) tmp as
display
where dt='2022-03-17' and get_json_object(line,'$.displays') is not null;
3)查看数据
select * from dwd_display_log where dt='2020-06-14' limit 2;
错误日志表
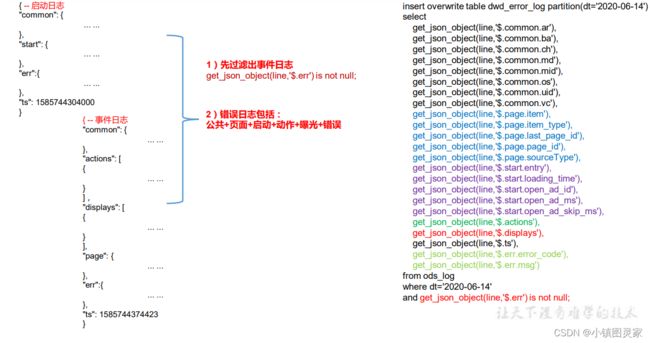
错误日志解析思路:
-
启动可能会报错
-
页面操作可能会报错
- 动作
- 曝光
错误日志表中每行数据对应一个错误记录,为方便定位错误,一个错误记录应当包含与之对应的公共信息、页面信息、曝光信息、动作信息、启动信息以及错误信息。先将包含 err 字段的日志过滤出来,然后使用 get_json_object 函数解析所有字段。
1)建表语句
drop table if exists dwd_error_log;
CREATE EXTERNAL TABLE dwd_error_log(
--公共字段
`area_code` string COMMENT '地区编码',
`brand` string COMMENT '手机品牌',
`channel` string COMMENT '渠道',
`model` string COMMENT '手机型号',
`mid_id` string COMMENT '设备 id',
`os` string COMMENT '操作系统',
`user_id` string COMMENT '会员 id',
`version_code` string COMMENT 'app 版本号',
--页面信息
`page_item` string COMMENT '目标 id ',
`page_item_type` string COMMENT '目标类型',
`last_page_id` string COMMENT '上页类型',
`page_id` string COMMENT '页面 ID ',
`source_type` string COMMENT '来源类型',
`entry` string COMMENT ' icon 手机图标 notice 通知 install 安装后启动',
--启动信息
`loading_time` string COMMENT '启动加载时间',
`open_ad_id` string COMMENT '广告页 ID ',
`open_ad_ms` string COMMENT '广告总共播放时间',
`open_ad_skip_ms` string COMMENT '用户跳过广告时点',
--错误出现的类型是动作还是曝光
`actions` string COMMENT '动作',
`displays` string COMMENT '曝光',
`ts` string COMMENT '时间', --事件产生时间
--错误信息
`error_code` string COMMENT '错误码',
`msg` string COMMENT '错误信息'
) COMMENT '错误日志表'
PARTITIONED BY (dt string)
stored as parquet
LOCATION '/warehouse/gmall/dwd/dwd_error_log'
TBLPROPERTIES('parquet.compression'='lzo');
- 说明:此处为对动作数组和曝光数组做处理,如需分析错误与单个动作或曝光的关联,可先使用 explode_json_array 函数将数组“炸开”,再使用 get_json_object 函数获取具体字段.
4)数据导入
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFo
rmat;
insert overwrite table dwd_error_log partition(dt='2022-03-17')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.start.entry'),
get_json_object(line,'$.start.loading_time'),
get_json_object(line,'$.start.open_ad_id'),
get_json_object(line,'$.start.open_ad_ms'),
get_json_object(line,'$.start.open_ad_skip_ms'),
get_json_object(line,'$.actions'),
get_json_object(line,'$.displays'),
get_json_object(line,'$.ts'),
get_json_object(line,'$.err.error_code'),
get_json_object(line,'$.err.msg')
from ods_log
where dt='2022-03-17'
and get_json_object(line,'$.err') is not null;
5)查看数据
select * from dwd_error_log where dt='2020-06-14' limit 2;
dwd层日志数据加载脚本
- vim ods_to_dwd_log.sh
#!/bin/bash
hive=/opt/module/hive/bin/hive
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
SET mapreduce.job.queuename=hive;
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFo
rmat;
insert overwrite table ${APP}.dwd_start_log
partition(dt='$do_date')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.start.entry'),
get_json_object(line,'$.start.loading_time'),
get_json_object(line,'$.start.open_ad_id'),
get_json_object(line,'$.start.open_ad_ms'),
get_json_object(line,'$.start.open_ad_skip_ms'),
get_json_object(line,'$.ts')
from ${APP}.ods_log
where dt='$do_date'
and get_json_object(line,'$.start') is not null;
insert overwrite table ${APP}.dwd_action_log
partition(dt='$do_date')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(action,'$.action_id'),
get_json_object(action,'$.item'),
get_json_object(action,'$.item_type'),
get_json_object(action,'$.ts')
from ${APP}.ods_log lateral view
${APP}.explode_json_array(get_json_object(line,'$.actions'))
tmp as action
where dt='$do_date'
and get_json_object(line,'$.actions') is not null;
insert overwrite table ${APP}.dwd_display_log
partition(dt='$do_date')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.ts'),
get_json_object(display,'$.displayType'),
get_json_object(display,'$.item'),
get_json_object(display,'$.item_type'),
get_json_object(display,'$.order')
from ${APP}.ods_log lateral view
${APP}.explode_json_array(get_json_object(line,'$.displays'))
tmp as display
where dt='$do_date'
and get_json_object(line,'$.displays') is not null;
insert overwrite table ${APP}.dwd_page_log
partition(dt='$do_date')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.ts')
from ${APP}.ods_log
where dt='$do_date'
and get_json_object(line,'$.page') is not null;
insert overwrite table ${APP}.dwd_error_log
partition(dt='$do_date')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.start.entry'),
get_json_object(line,'$.start.loading_time'),
get_json_object(line,'$.start.open_ad_id'),
get_json_object(line,'$.start.open_ad_ms'),
get_json_object(line,'$.start.open_ad_skip_ms'),
get_json_object(line,'$.actions'),
get_json_object(line,'$.displays'),
get_json_object(line,'$.ts'),
get_json_object(line,'$.err.error_code'),
get_json_object(line,'$.err.msg')
from ${APP}.ods_log
where dt='$do_date'
and get_json_object(line,'$.err') is not null;
"
$hive -e "$sql"
- 为脚本赋权限chmod 777 ods_to_dwd_log.sh
- 脚本使用 ods_to_dwd_log.sh 2020-06-15
DWD层业务数据
业务数据方面 DWD 层的搭建主要注意点在于维度建模,减少后续大量 Join 操作。
通过业务分析建模最终确定8张事实表和6张维度表.
8张事实表:
- 事务型事实表
- 支付事实表
- 退款事实表
- 评价事实表
- 订单明细事实表
- 周期型快照事实表—>每日快照
- 加购事实表
- 收藏事实表
- 累积型快照事实表
- 优惠券领用事实表
- 订单事实表
6张维度表: 一般维表全量同步,数据量不大,一般是小表。
- 全量维度表
- 商品维度表
- 优惠券维度表
- 活动维度表
- 枚举维度表(特殊维表)
- 地区维度表
- 时间维度表
- 拉链表
- 用户维度表(再如:订单物流详情表等)

商品维度表(全量)
商品维度表主要是将商品表 SKU 表、商品一级分类、商品二级分类、商品三级分类、商品品牌表和商品 SPU 表联接为商品表。

1)建表语句—加载数据
-- 商品维度表
drop table if exists dwd_dim_sku_info;
create external table if not exists dwd_dim_sku_info(
id string comment '商品id',
spu_id string comment 'spu_id',
`price` decimal(16,2) COMMENT '商品价格',
`sku_name` string COMMENT '商品名称',
`sku_desc` string COMMENT '商品描述',
`weight` decimal(16,2) COMMENT '重量',
`tm_id` string COMMENT '品牌 id',
`tm_name` string COMMENT '品牌名称',
`category3_id` string COMMENT '三级分类 id',
`category2_id` string COMMENT '二级分类 id',
`category1_id` string COMMENT '一级分类 id',
`category3_name` string COMMENT '三级分类名称',
`category2_name` string COMMENT '二级分类名称',
`category1_name` string COMMENT '一级分类名称',
`spu_name` string COMMENT 'spu 名称',
`create_time` string COMMENT '创建时间'
) COMMENT '商品维度表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_sku_info/'
tblproperties ("parquet.compression"="lzo");
-- 加载数据
insert overwrite table dwd_dim_sku_info partition(dt='2022-03-17')
select
sku.id,
sku.spu_id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.tm_id,
ob.tm_name,
sku.category3_id,
c2.id category2_id,
c1.id category1_id,
c3.name category3_name,
c2.name category2_name,
c1.name category1_name,
spu.spu_name,
sku.create_time
from (
select * from ods_sku_info where dt='2022-03-17'
)sku
join(
select * from ods_base_trademark where dt='2022-03-17'
)ob on sku.tm_id=ob.tm_id
join(
select * from ods_spu_info where dt='2022-03-17'
)spu on spu.id=sku.tm_id
join (
select * from ods_base_category3 where dt='2022-03-17'
)c3 on sku.category3_id=c3.id
join
(
select * from ods_base_category2 where dt='2022-03-17'
)c2 on c3.category2_id=c2.id
join (
select * from ods_base_category1 where dt='2022-03-17'
)c1 on c2.category1_id=c1.id;
活动维度表(全量)
-
活动信息表
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rPWA82eU-1648101873769)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220318182204030.png)]](http://img.e-com-net.com/image/info8/bd91f0024b37413ab1ce34d122a17d08.jpg)
-
活动规则表
-
活动订单表
-
由于mock数据存在问题,当活动信息表和订单活动表join时出现一个活动id对应多条订单记录,一个活动id又对应多条优惠规则。因此此处事实表和维度表关联会出错…,所以此处只取活动信息表的数据。

- 建表语句和数据加载
drop table if exists dwd_dim_activity_info;
create external table dwd_dim_activity_info(
`id` string COMMENT '编号',
`activity_name` string COMMENT '活动名称',
`activity_type` string COMMENT '活动类型',
`start_time` string COMMENT '开始时间',
`end_time` string COMMENT '结束时间',
`create_time` string COMMENT '创建时间'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_activity_info/'
tblproperties ("parquet.compression"="lzo");
--数据装载
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_activity_info partition(dt='2020-06-14')
select
id,
activity_name,
activity_type,
start_time,
end_time,
create_time
from ods_activity_info
where dt='2020-06-14';
2)查询加载结果
select * from dwd_dim_activity_info where dt='2020-06-14' limit 2;
优惠券维度表(全量)
把 ODS 层 ods_coupon_info 表数据导入到 DWD 层优惠卷维度表,在导入过程中可以做适当的清洗。
1)建表语句
drop table if exists dwd_dim_coupon_info;
create external table dwd_dim_coupon_info(
`id` string COMMENT '购物券编号',
`coupon_name` string COMMENT '购物券名称',
`coupon_type` string COMMENT '购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券',
`condition_amount` decimal(16,2) COMMENT '满额数',
`condition_num` bigint COMMENT '满件数',
`activity_id` string COMMENT '活动编号',
`benefit_amount` decimal(16,2) COMMENT '减金额',
`benefit_discount` decimal(16,2) COMMENT '折扣',
`create_time` string COMMENT '创建时间',
`range_type` string COMMENT '范围类型 1、商品 2、品类 3、品牌',
`spu_id` string COMMENT '商品 id',
`tm_id` string COMMENT '品牌 id',
`category3_id` string COMMENT '品类 id',
`limit_num` bigint COMMENT '最多领用次数',
`operate_time` string COMMENT '修改时间',
`expire_time` string COMMENT '过期时间'
) COMMENT '优惠券维度表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_coupon_info/'
tblproperties ("parquet.compression"="lzo")
2)数据装载
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_coupon_info partition(dt='2020-06-14')
select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
spu_id,
tm_id,
category3_id,
limit_num,
operate_time,
expire_time
from ods_coupon_info
where dt='2020-06-14';
--查询加载结果
select * from dwd_dim_coupon_info where dt='2020-06-14' limit 2;
地区维度表(不变)
- 不用分区
- 数据量很小,无需压缩
1)建表语句
DROP TABLE IF EXISTS `dwd_dim_base_province`;
CREATE EXTERNAL TABLE `dwd_dim_base_province` (
`id` string COMMENT 'id',
`province_name` string COMMENT '省市名称',
`area_code` string COMMENT '地区编码',
`iso_code` string COMMENT 'ISO 编码',
`region_id` string COMMENT '地区 id',
`region_name` string COMMENT '地区名称'
) COMMENT '地区维度表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_base_province/'
tblproperties ("parquet.compression"="lzo");
- 加载数据
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_base_province
select
bp.id,
bp.name,
bp.area_code,
bp.iso_code,
bp.region_id,
br.region_name
from ods_base_province bp
join
ods_base_region br
on bp.region_id = br.id;
-- 查询结果
select * from dwd_dim_base_province limit 2;
时间维度表(特殊)
- 时间维度表中的数据不来源于任何业务系统
1)建表语句
DROP TABLE IF EXISTS `dwd_dim_date_info`;
CREATE EXTERNAL TABLE `dwd_dim_date_info`(
`date_id` string COMMENT '日',
`week_id` string COMMENT '周',
`week_day` string COMMENT '周的第几天',
`day` string COMMENT '每月的第几天',
`month` string COMMENT '第几月',
`quarter` string COMMENT '第几季度',
`year` string COMMENT '年',
`is_workday` string COMMENT '是否是周末',
`holiday_id` string COMMENT '是否是节假日'
) COMMENT '时间维度表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_date_info/'
tblproperties ("parquet.compression"="lzo");
2)把 date_info.txt 文件上传到 hadoop102 的/opt/module/db_log/路径
3)数据装载
注意:由于 dwd_dim_date_info 是列式存储+LZO 压缩。直接将 date_info.txt 文件导入到目标表,并不会直接转换为列式存储+LZO 压缩。我们需要创建一张普通的临时表dwd_dim_date_info_tmp,将 date_info.txt 加载到该临时表中。最后通过查询临时表数据,把
查询到的数据插入到最终的目标表中。
(1)创建临时表,非列式存储
DROP TABLE IF EXISTS `dwd_dim_date_info_tmp`;
CREATE EXTERNAL TABLE `dwd_dim_date_info_tmp`(
`date_id` string COMMENT 'YYYY-MM-dd',
`week_id` string COMMENT '一年中的第几周',
`week_day` string COMMENT '周的第几天',
`day` string COMMENT '每月的第几天',
`month` string COMMENT '第几月',
`quarter` string COMMENT '第几季度',
`year` string COMMENT '年',
`is_workday` string COMMENT '是否是周末',
`holiday_id` string COMMENT '是否是节假日'
) COMMENT '时间临时表'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/dwd/dwd_dim_date_info_tmp/';
(2)将数据导入临时表
load data local inpath '/opt/module/db_log/date_info.txt' into table dwd_dim_date_info_tmp;
(3)将数据导入正式表
insert overwrite table dwd_dim_date_info select * from dwd_dim_date_info_tmp;
4)查询加载结果
select * from dwd_dim_date_info;
支付事实表(事务型事实表)
- 该表特点:只会新增记录,历史数据不会变化,增量同步
- 事实表有两类字段,一类是度量值,一类是维度外键及维度相关字段(维度退化)
- 支付事实表与那些维度相关,度量值是什么:
- 时间维度
- 用户维度
- 地区维度
- 度量值为:金额
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jKWnZDSR-1648101873775)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220319113536613.png)]](http://img.e-com-net.com/image/info8/9fd1261a54db4e68b0a64711533947fd.jpg)
- dwd_fact_payment_info数据主要来源于ods层的支付信息表
- 支付信息表里面在订单信息表里包含着,因此用支付信息表
left join订单信息表
1)建表语句
drop table if exists dwd_fact_payment_info;
create external table dwd_fact_payment_info (
`id` string COMMENT 'id',
`out_trade_no` string COMMENT '对外业务编号',
`order_id` string COMMENT '订单编号',
`user_id` string COMMENT '用户编号',
`alipay_trade_no` string COMMENT '支付宝交易流水编号',
`payment_amount` decimal(16,2) COMMENT '支付金额',
`subject` string COMMENT '交易内容',
`payment_type` string COMMENT '支付类型',
`payment_time` string COMMENT '支付时间',
`province_id` string COMMENT '省份 ID'
) COMMENT '支付事实表表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_payment_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_payment_info partition(dt='2022-03-17')
select
pay.id ,
pay.out_trade_no, --对外业务编号
pay.order_id, --订单编号
pay.user_id, --用户编号
pay.alipay_trade_no, --支付交易单编号
pay.total_amount, --支付金额
pay.subject, --支付内容
pay.payment_type, --支付类型
pay.payment_time, --支付时间
ord.province_id --省份id
from
(
select * from
ods_payment_info pay where dt='2022-03-17')pay
left join
(
select id, province_id from ods_order_info where dt='2022-03-17'
)ord on ord.id=pay.order_id;
退款事实表(事务型事实表)
- dwd_fact_order_refund_info退款事实表中的一行数据就是一笔退款记录
- 退款事实表与那些维度相关,度量值是什么?
- 时间维度
- 用户维度
- 商品维度
- 度量值为:金额、件数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KcSLsF0z-1648101873778)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220319145517967.png)]](http://img.e-com-net.com/image/info8/fcbae6711c2140f18d29f20626ff1918.jpg)
1)建表语句
drop table if exists dwd_fact_order_refund_info;
create external table dwd_fact_order_refund_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户 ID',
`order_id` string COMMENT '订单 ID',
`sku_id` string COMMENT '商品 ID',
`refund_type` string COMMENT '退款类型',
`refund_num` bigint COMMENT '退款件数',
`refund_amount` decimal(16,2) COMMENT '退款金额',
`refund_reason_type` string COMMENT '退款原因类型',
`create_time` string COMMENT '退款时间'
) COMMENT '退款事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_order_refund_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_order_refund_info partition(dt='2022-03-17')
select
id,
user_id,
order_id,
sku_id,
refund_type,
refund_num,
refund_amount,
refund_reason_type,
create_time
from ods_order_refund_info
where dt='2022-03-17';
3)查询加载结果
select * from dwd_fact_order_refund_info where dt='2020-06-14' limit 2;
评价事实表(事务型事实表)
把 ODS 层 ods_comment_info 表数据导入到 DWD 层评价事实表,在导入过程中可以做适当的清洗。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0JlaAyIU-1648101873779)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220319150352834.png)]](http://img.e-com-net.com/image/info8/ef55b10cfdfe4df3b58976c6f335e0b6.jpg)
-
dwd_fact_comment_info评价事实表中的一行数据代表一次评价记录
-
评价事实表与那些维度相关,度量值是什么?
- 时间维度
- 用户维度
- 商品维度
- 也可以与地区维度外键关联(这里就不考虑地区了)
-
度量值为:个数
-
数据来源:
- 数据来源于ODS 层 ods_comment_info 表,关于地区id;评价的订单不是当天的订单,因此用order_id与order_info表join有可能join不了。解决方案考虑评价有效时间周期,假设我一周;就可以用最近一周已经发货的商品的id,查询出地区id,就可以拿到这个字段了。
1)建表语句
drop table if exists dwd_fact_comment_info;
create external table dwd_fact_comment_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户 ID',
`sku_id` string COMMENT '商品 sku',
`spu_id` string COMMENT '商品 spu',
`order_id` string COMMENT '订单 ID',
`appraise` string COMMENT '评价',
`create_time` string COMMENT '评价时间'
) COMMENT '评价事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_comment_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_comment_info partition(dt='2022-03-17')
select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
create_time
from ods_comment_info
where dt='2020-03-17';
*订单明细事实表(事务型事实表)
- 数据粒度:订单明细表中的一行数据记录代表一个订单中的一个商品项,比如id为3275的商品中购买了5款商品,联想电脑和华为手机。那么订单明细中就会有5条明细。

- 订单明细表的维度和度量值
- 时间维度
- 用户维度
- 商品维度
- 地区维度
- 度量值:件数/金额



1)建表语句
drop table if exists dwd_fact_order_detail;
create external table dwd_fact_order_detail (
`id` string COMMENT '订单编号',
`order_id` string COMMENT '订单号',
`user_id` string COMMENT '用户 id',
`sku_id` string COMMENT 'sku 商品 id',
`sku_name` string COMMENT '商品名称',
`order_price` decimal(16,2) COMMENT '商品价格',
`sku_num` bigint COMMENT '商品数量',
`create_time` string COMMENT '创建时间',
`province_id` string COMMENT '省份 ID',
`source_type` string COMMENT '来源类型',
`source_id` string COMMENT '来源编号',
`original_amount_d` decimal(20,2) COMMENT '原始价格分摊',
`final_amount_d` decimal(20,2) COMMENT '购买价格分摊',
`feight_fee_d` decimal(20,2) COMMENT '分摊运费',
`benefit_reduce_amount_d` decimal(20,2) COMMENT '分摊优惠'
) COMMENT '订单明细事实表表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_order_detail/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
-
ods层的ods_order_detail表与ods_order_info表进行join操作,订单信息表是每天新增及变化,是增量表;order_detail是订单的明细;这里可以使用left join。
-
需要计算的度量值:
-
原始金额分摊 round(order_price*sku_num, 2)
-
分摊优惠 round(商品价格order_price * sku_num/订单信息表中的original_total_amount*benefit_reduce_amount,2)
- a商品20元,b商品30元,c商品50元;优惠规则满100减20,折合每件商品的分摊优惠为:a: 4元,b: 6 元,c: 10元
- 误差问题,1. 假设优惠规则为满30减10元。若a,b,c三个商品金额都是10元,每个商品平均分摊金额为3.333…这里需要处理误差问题。
-
group by与over(partition by 分区字段, 【可选 Order by 字段 】)开窗函数的区别: ----------------------------------------------------------------------------- OVER子句用于为行为定义一个窗口(windows),以便进行特定的运算。可以把行的窗口简单地认为是运算将要操作的一个行的集合。例如,聚合函数和排名函数都是可以支持OVER子句的运算类型。由于OVER子句为这些函数提供了一个行的窗口,所以这些函数也称之为开窗函数。 聚合函数的要点就是要对一组值进行聚合,聚合函数传统上一直以GROUP BY查询作为操作的上下文。在前面的“GROUP BY”子句的讨论中,我们知道在对数据进行分组以后,查询为每个组只返回一行;因此,也就是要限制所有的表达式为每个组只能返回一个值。 聚合开窗函数使用OVER子句提供窗口作为上下文,对窗口中的一组值进行操作,而不是使用GROUP BY子句提供的上下文。这样就不必对数据进行分组,还能够在同一行中同时返回基础行的列和聚合列。 -
ROW_NUMBER()函数将针对SELECT语句返回的每一行,从1开始编号,赋予其连续的编号。在查询时应用了一个排序标准后,只有通过编号才能够保证其顺序是一致的,当使用ROW_NUMBER函数时,也需要专门一列用于预先排序以便于进行编号 ------------------------ partition by关键字是分析性函数的一部分,它和聚合函数不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录,partition by用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,分区函数一般与排名函数一起使用。 ------------------------ -
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sq2Ss8D9-1648101873792)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220319172809682.png)]](http://img.e-com-net.com/image/info8/1b1530ac5dca4c79a316da1ff3595c3a.jpg)
- benefit_reduce_amount优惠金额
- benefit_reduce_amount_d分摊优惠金额
- benefit_reduce_amount_d_sum总的分摊优惠
- row_number开窗后排序,行号,方便为分摊优惠金额补误差0.01元
-
-
数据装载sql
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_order_detail partition(dt='2020-06-14')
select
id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
create_time,
province_id,
source_type,
source_id,
original_amount_d,
if(rn=1,final_total_amount -(sum_div_final_amount - final_amount_d),final_amount_d),
if(rn=1,feight_fee - (sum_div_feight_fee - feight_fee_d),feight_fee_d),
if(rn=1,benefit_reduce_amount - (sum_div_benefit_reduce_amount -
benefit_reduce_amount_d), benefit_reduce_amount_d)
from
(
select
od.id,
od.order_id,
od.user_id,
od.sku_id,
od.sku_name,
od.order_price,
od.sku_num,
od.create_time,
oi.province_id,
od.source_type,
od.source_id,
round(od.order_price*od.sku_num,2) original_amount_d,--原始金额分摊
round(od.order_price*od.sku_num/oi.original_total_amount*oi.final_total_amount,2)
final_amount_d, --
round(od.order_price*od.sku_num/oi.original_total_amount*oi.feight_fee,2)
feight_fee_d,
--oi.benefit_reduce_amount订单优惠金额
round(od.order_price*od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2)
benefit_reduce_amount_d, --分摊优惠金额
row_number() over(partition by od.order_id order by od.id desc) rn,
oi.final_total_amount,
oi.feight_fee,
oi.benefit_reduce_amount,
sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.final_total_amount,2))
over(partition by od.order_id) sum_div_final_amount,
sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.feight_fee,2))
over(partition by od.order_id) sum_div_feight_fee,
--分摊优惠之和
sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2)) over(partition by od.order_id) sum_div_benefit_reduce_amount
from
(
select * from ods_order_detail where dt='2020-06-14'
) od
join
(
select * from ods_order_info where dt='2020-06-14'
) oi
on od.order_id=oi.id
)t1;
加购事实表(周期型快照事实表,每日快照)
- 每日全量
- 由于购物车的数量是会发生变化,所以导增量不合适。
每天做一次快照,导入的数据是全量,区别于事务型事实表是每天导入新增。
周期型快照事实表劣势:存储的数据量会比较大。
解决方案:周期型快照事实表存储的数据比较讲究时效性,时间太久了的意义不大,可以删除以前的数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EuNi1AyV-1648101873794)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220319180055693.png)]](http://img.e-com-net.com/image/info8/f363e332583c47c39388c1705be3d591.jpg)
- 加购物车事实表中的一行数据是一个用户加入购物车的一个商品,对应商品sku
- 加购事实表维度字段和度量值】
- 时间维度
- 用户维度
- 商品维度
- 度量值
- 件数、金额
1)建表语句
drop table if exists dwd_fact_cart_info;
create external table dwd_fact_cart_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户 id',
`sku_id` string COMMENT 'skuid',
`cart_price` string COMMENT '放入购物车时价格',
`sku_num` string COMMENT '数量',
`sku_name` string COMMENT 'sku 名称 (冗余)',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '修改时间',
`is_ordered` string COMMENT '是否已经下单。1 为已下单;0 为未下单',
`order_time` string COMMENT '下单时间',
`source_type` string COMMENT '来源类型',
`srouce_id` string COMMENT '来源编号'
) COMMENT '加购事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_cart_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_cart_info partition(dt='2022-03-17')
select
id,
user_id,
sku_id,
cart_price,
sku_num,
sku_name,
create_time,
operate_time,
is_ordered,
order_time,
source_type,
source_id
from ods_cart_info
where dt='2022-03-17';
收藏事实表(周期型快照事实表,每日快照)
收藏的标记,是否取消,会发生变化,做增量不合适。每天做一次快照,导入的数据是全量,区别于事务型事实表是每天导入新增。
-
表中一行数据代表一个用户收藏一个商品
-
维度字段和度量值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JeCZrx5C-1648101873795)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220319180816762.png)]](http://img.e-com-net.com/image/info8/b283b7e08c4b4b27a8d60cbe28ed0cb1.jpg)
1)建表语句
drop table if exists dwd_fact_favor_info;
create external table dwd_fact_favor_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户 id',
`sku_id` string COMMENT 'skuid',
`spu_id` string COMMENT 'spuid',
`is_cancel` string COMMENT '是否取消',
`create_time` string COMMENT '收藏时间',
`cancel_time` string COMMENT '取消时间'
) COMMENT '收藏事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_favor_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_favor_info partition(dt='2022-03-17')
select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from ods_favor_info
where dt='2022-03-17';
*&重点-优惠券领用事实表(累积型快照事实表)
-
优惠券的生命周期:
- 领取优惠卷–> 用优惠卷下单–> 优惠券参与支付累积型快照事实表使用:统计优惠卷领取次数、优惠卷下单次数、优惠卷参与支付次数.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jcLhppnB-1648101873797)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220319181309601.png)]](http://img.e-com-net.com/image/info8/6837235d2b3a4f8d8ae951ae17ba0230.jpg)
- 领取优惠卷–> 用优惠卷下单–> 优惠券参与支付累积型快照事实表使用:统计优惠卷领取次数、优惠卷下单次数、优惠卷参与支付次数.
-
表中一行数据代表用户领取优惠券到最终使用支付的记录
-
每天导入数据需要修改之前的数据,hive如何修改数据?先查出要修改的字段,然后判断后是否修改之后再写入表中
-
累加型快照事实表,新增及变化—>也就是按照每天的新增数据和变化的数据,按天更新
-
要么以表为单位修改指定数据,要么以表的某个分区为单位修改指定数据。
-
Hive修改数据需要是分桶表,因为分桶表会根据某个字段Hash值取余分桶,将数据对应放入多个文件,数据修改会减小数据检索的范围。
-
-
优惠券领用事实表的数据包含:
- 按天分区,每天从mysql导入的数据为:当天领券的记录,使用的记录,以及使用过券的记录。
- 按天分区,每天只存放当天领取记录
-
表中数据要修改的为:
- 领取的券的时间
- 券使用时的时间
- 券被支付使用过
1)建表语句
drop table if exists dwd_fact_coupon_use;
create external table dwd_fact_coupon_use(
`id` string COMMENT '编号',
`coupon_id` string COMMENT '优惠券 ID',
`user_id` string COMMENT 'userid',
`order_id` string COMMENT '订单 id',
`coupon_status` string COMMENT '优惠券状态',
`get_time` string COMMENT '领取时间',
`using_time` string COMMENT '使用时间(下单)',
`used_time` string COMMENT '使用时间(支付)'
) COMMENT '优惠券领用事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_coupon_use/'
tblproperties ("parquet.compression"="lzo")
注意:dt 是按照优惠卷领用时间 get_time 做为分区。
2)数据装载
- 思路

- 优惠券领用事实表数据装载思路

-
从mysql每天导入的新增领券记录以及使用记录存放到了ods_coupon_use这张表中,对应的每天的分区表。
-
查询那种表:dwd_fact_coupon_use
-
--返回的是所有需要修改的分区数据集 select* from dwd_fact_coupon_use where --dt=? --这里分区时间怎么写,多个分区 in() dt in ( select date_format(get_time,'yyyy-MM-dd') from ods_coupon_use where dt='2022-03-17' ) old full outer join ( --新增及变化的数据集 select* from ods_coupon_use where dt='2022-03-17' )new on old.id=new.id; -
全关联后在将这个整体数据集上查询需要修改的数据,做判断并修改
- 使用if()函数做判断
-
判断新的数据集是否为空,是空位old.id,不是空new. id
-
这里需要使用动态分区
-
--开启动态分区为非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_coupon_use partition(dt)
select
if(new.id is null,old.id,new.id),
if(new.coupon_id is null,old.coupon_id,new.coupon_id),
if(new.user_id is null,old.user_id,new.user_id),
if(new.order_id is null,old.order_id,new.order_id),
if(new.coupon_status is null,old.coupon_status,new.coupon_status),
if(new.get_time is null,old.get_time,new.get_time),
if(new.using_time is null,old.using_time,new.using_time),
if(new.used_time is null,old.used_time,new.used_time),
date_format(if(new.get_time is null,old.get_time,new.get_time),'yyyy-MM-dd')
from
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from dwd_fact_coupon_use
where dt in
(
select
date_format(get_time,'yyyy-MM-dd')
from ods_coupon_use
where dt='2022-03-17'
)
)old
full outer join
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from ods_coupon_use
where dt='2022-03-17'
)new
on old.id=new.id;
*&重点-订单事实表(累积型快照事实表)

- 订单生命周期:创建时间–>支付时间–> 取消时间–> 完成时间–> 退款时间–> 退款完成时间。
- 由于 ODS 层订单表只有创建时间和操作时间两个状态,不能表达所有时间含义,所以需要关联订单状态表。订单事实表里面增加了活动 id,所以需要关联活动订单表。
- 表中一行数据指代一个订单
- 表中字段:维度外键+度量值
- 用户维度
- 时间维度
- 地区维度
- 活动维度activity_id
- 度量值:
- 件数/金额
1)建表语句
-
drop table if exists dwd_fact_order_info; create external table dwd_fact_order_info ( `id` string COMMENT '订单编号', `order_status` string COMMENT '订单状态', `user_id` string COMMENT '用户 id', `out_trade_no` string COMMENT '支付流水号', `create_time` string COMMENT '创建时间(未支付状态)', `payment_time` string COMMENT '支付时间(已支付状态)', `cancel_time` string COMMENT '取消时间(已取消状态)', `finish_time` string COMMENT '完成时间(已完成状态)', `refund_time` string COMMENT '退款时间(退款中状态)', `refund_finish_time` string COMMENT '退款完成时间(退款完成状态)', `province_id` string COMMENT '省份 ID', `activity_id` string COMMENT '活动 ID', `original_total_amount` decimal(16,2) COMMENT '原价金额', `benefit_reduce_amount` decimal(16,2) COMMENT '优惠金额', `feight_fee` decimal(16,2) COMMENT '运费', `final_total_amount` decimal(16,2) COMMENT '订单金额' ) COMMENT '订单事实表' PARTITIONED BY (`dt` string) stored as parquet location '/warehouse/gmall/dwd/dwd_fact_order_info/' tblproperties ("parquet.compression"="lzo");
2)数据装载
-
理解订单事实表的分区:
-
订单事实表的数据如何修改
-
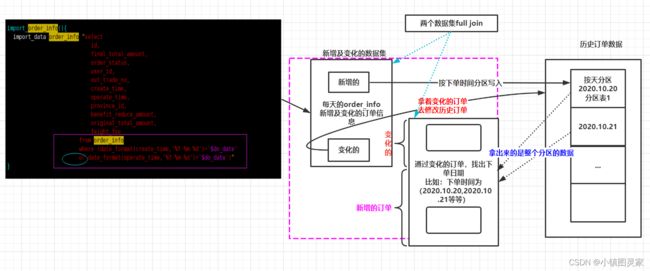
先要找到需要修改的数据集,通过变化的订单查询下单日期,然后通过下单日期(Create_time)找到需要修改的订单数据集,拿出来的是整个分区的数据。
-
-
新增及变化的数据集full outer join (根据变化的订单的下单时间查询出来的需要改变的数据集的多个整个分区)
-
从这个表dwd_fact_order_info查询dt分区包含在旧的订单信息表中的数据分区
-
---大体思路 select * from dwd_fact_order_info where dt in ( select date_format(create_time,'yyyy-MM-dd') from ods_order_info where dt='2020-06-14' )old full outer join ( --订单状态表join订单信息表 letf join活动订单表 select* from ods_order_status_log join ods_order_info left join ods_activity_order where dt='2022-03-17' )new on old.id=new.id;
-
-

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KTWjsjiw-1648101873808)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220319210350179.png)]](http://img.e-com-net.com/image/info8/ac94641c27af4a72a9c31c1282e2e10a.jpg)
3)常用函数
- 1)concat 函数
concat 函数在连接字符串的时候,只要其中一个是 NULL,那么将返回 NULL
select concat('a','b');
--结果 ab
select concat('a','b',null);
--结果 NULL
- 2)concat_ws 函数
concat_ws函数在连接字符串的时候,只要有一个字符串不是 NULL,就不会返回NULL。
concat_ws 函数需要指定分隔符。
hive> select concat_ws('-','a','b');
a-b
hive> select concat_ws('-','a','b',null);
a-b
hive> select concat_ws('','a','b',null);
ab
-
3)collect_set 函数
-
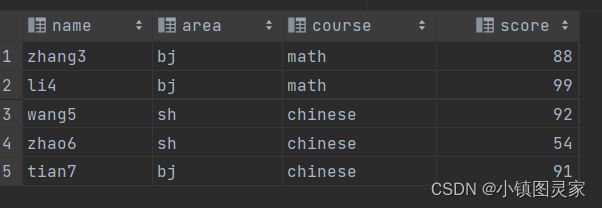
创建原数据表
drop table if exists stud; create table stud (name string, area string, course string, score int); -
向原数据表中插入数据
insert into table stud values('zhang3','bj','math',88); insert into table stud values('li4','bj','math',99); insert into table stud values('wang5','sh','chinese',92); insert into table stud values('zhao6','sh','chinese',54); insert into table stud values('tian7','bj','chinese',91);
-
-
把同一分组的不同行的数据聚合成一个集合
select course, collect_set(area), avg(score) from stud group by course; --结果 -
用下标可以取某一个
-
select course, collect_set(area)[0], avg(score) from stud group by course; ---结果 chinese sh 79.0 math bj 93.5
-
-
4)STR_TO_MAP 函数
-
语法描述
STR_TO_MAP(VARCHAR text, VARCHAR listDelimiter, VARCHAR keyValueDelimiter) -
功能描述
使用 listDelimiter 将 text 分隔成 K-V 对,然后使用 keyValueDelimiter 分隔每个 K-V 对,组装成 MAP 返回。默认 listDelimiter 为( ,),keyValueDelimiter 为(=)。 -
案例
-
str_to_map('1001=2020-06-14,1002=2020-06-14', ',' , '=') --输出 {"1001":"2020-06-14","1002":"2020-06-14"}
-
-

订单事实表中使用到的函数:
-
concat()
-
select order_id, concat(order_status,'=', operate_time) from ods_order_status_log where dt='2020-06-14'; --------------------------------------结果如下 3210 1001=2020-06-14 00:00:00.0 3211 1001=2020-06-14 00:00:00.0 3212 1001=2020-06-14 00:00:00.0 3210 1002=2020-06-14 00:00:00.0 3211 1002=2020-06-14 00:00:00.0 3212 1002=2020-06-14 00:00:00.0 3210 1005=2020-06-14 00:00:00.0 3211 1004=2020-06-14 00:00:00.0 3212 1004=2020-06-14 00:00:00.0
-
-
collect_set()
-
select order_id, collect_set(concat(order_status,'=',operate_time)) from ods_order_status_log where dt='2020-06-14' group by order_id; --- 3210 ["1001=2020-06-14 00:00:00.0","1002=2020-06-14 00:00:00.0","1005=2020-06-14 00:00:00.0"] 3211 ["1001=2020-06-14 00:00:00.0","1002=2020-06-14 00:00:00.0","1004=2020-06-14 00:00:00.0"] 3212 ["1001=2020-06-14 00:00:00.0","1002=2020-06-14 00:00:00.0","1004=2020-06-14 00:00:00.0"]
-
-
concat_ws()
-
select order_id, concat_ws(',', collect_set(concat(order_status,'=',operate_time))) from ods_order_status_log where dt='2020-06-14' group by order_id; ----结果为: 3210 1001=2020-06-14 00:00:00.0,1002=2020-06-14 00:00:00.0,1005=2020-06-14 00:00:00.0 3211 1001=2020-06-14 00:00:00.0,1002=2020-06-14 00:00:00.0,1004=2020-06-14 00:00:00.0 3212 1001=2020-06-14 00:00:00.0,1002=2020-06-14 00:00:00.0,1004=2020-06-14 00:00:00.0 --------------------------------------------------------------------------------------- select order_id, str_to_map(concat_ws(',',collect_set(concat(order_status,'=',operate_time))), ',' , '=') from ods_order_status_log where dt='2020-06-14' group by order_id; ---结果为: 3210 {"1001":"2020-06-14 00:00:00.0","1002":"2020-06-14 00:00:00.0","1005":"2020-06-14 00:00:00.0"} 3211 {"1001":"2020-06-14 00:00:00.0","1002":"2020-06-14 00:00:00.0","1004":"2020-06-14 00:00:00.0"}
-
数据加载
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_order_info partition(dt)
select
if(new.id is null,old.id,new.id),
if(new.order_status is null,old.order_status,new.order_status),
if(new.user_id is null,old.user_id,new.user_id),
if(new.out_trade_no is null,old.out_trade_no,new.out_trade_no),
if(new.tms['1001'] is null,old.create_time,new.tms['1001']),--1001 对应未支付状态
if(new.tms['1002'] is null,old.payment_time,new.tms['1002']),
if(new.tms['1003'] is null,old.cancel_time,new.tms['1003']),
if(new.tms['1004'] is null,old.finish_time,new.tms['1004']),
if(new.tms['1005'] is null,old.refund_time,new.tms['1005']),
if(new.tms['1006'] is null,old.refund_finish_time,new.tms['1006']),
if(new.province_id is null,old.province_id,new.province_id),
if(new.activity_id is null,old.activity_id,new.activity_id),
if(new.original_total_amount is
null,old.original_total_amount,new.original_total_amount),
if(new.benefit_reduce_amount is
null,old.benefit_reduce_amount,new.benefit_reduce_amount),
if(new.feight_fee is null,old.feight_fee,new.feight_fee),
if(new.final_total_amount is null,old.final_total_amount,new.final_total_amount),
date_format(if(new.tms['1001'] is null,old.create_time,new.tms['1001']),'yyyy-MMdd')
from
(
select
id,
order_status,
user_id,
out_trade_no,
create_time,
payment_time,
cancel_time,
finish_time,
refund_time,
refund_finish_time,
province_id,
activity_id,
original_total_amount,
benefit_reduce_amount,
feight_fee,
final_total_amount
from dwd_fact_order_info
where dt
in
(
select
date_format(create_time,'yyyy-MM-dd')
from ods_order_info
where dt='2022-03-17'
)
)old
full outer join
(
select
info.id,
info.order_status,info.user_id,
info.out_trade_no,
info.province_id,
act.activity_id,
log.tms,
info.original_total_amount,
info.benefit_reduce_amount,
info.feight_fee,
info.final_total_amount
from
(
select
order_id,
str_to_map(concat_ws(',',collect_set(concat(order_status,'=',operate_time))),',','=')
tms
from ods_order_status_log
where dt='2022-03-17'
group by order_id
)log
join
(
select * from ods_order_info where dt='2022-03-17'
)info
on log.order_id=info.id
left join
(
select * from ods_activity_order where dt='2022-03-17'
)act
on log.order_id=act.order_id
)new
on old.id=new.id;
**&重点-用户维度表(拉链表)
用户表中的数据每日既有可能新增,也有可能修改,但修改频率并不高,属于缓慢变化维度,此处采用拉链表存储用户维度数据。
1)什么是拉链表
拉链表,记录每条信息的生命周期,一 旦一条记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始日期。
如果当前信息至今有效,在生效结束日期中填入一个极大值(如9999-99-99 )。
- 表中一行数据是一个用户的一个状态

2)为什么要做拉链表
拉链表适合于:数据会发生变化,但是大部分是不变的。(即:缓慢变化维) 比如:用户信息会发生变化,但是每天变化的比例不高。如果数 据量有一定规模,按照每日全量的 方式保存效率很低。 比如:1亿用户*365天,每天一份用户信息。(做每日全量效率低)
通过,生效开始日期<=某个日期 且 生效结束日期>=某个日期 ,能够得到某个时间点的数据全量切片。

3)拉链表形成过程
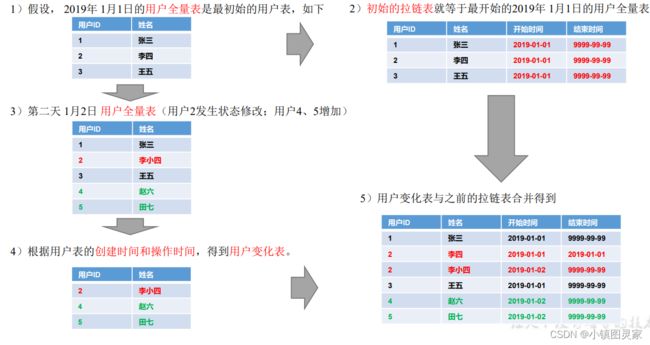
4)拉链表制作过程图

5)拉链表制作过程
步骤 0:初始化拉链表(首次独立执行)
- (1)建立拉链表
drop table if exists dwd_dim_user_info_his;
create external table dwd_dim_user_info_his(
`id` string COMMENT '用户 id',
`name` string COMMENT '姓名',
`birthday` string COMMENT '生日',
`gender` string COMMENT '性别',
`email` string COMMENT '邮箱',
`user_level` string COMMENT '用户等级',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间',
`start_date` string COMMENT '有效开始日期',
`end_date` string COMMENT '有效结束日期'
) COMMENT '用户拉链表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_user_info_his/'
tblproperties ("parquet.compression"="lzo");
- (2)初始化拉链表
- 生产环境下:
- 使用数据库同步工具 Sqoop或者DataX单独执行一次同步任务,将业务系统的用户表的全部数据一次性的导入到拉链表中
- 生产环境下:
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_user_info_his
select
id,
name,
birthday,
gender,
email,
user_level,
create_time,
operate_time,
'2022-03-17',
'9999-99-99'
from ods_user_info oi
where oi.dt='2022-03-17';
步骤 1:制作当日变动数据(包括新增,修改)每日执行
- 每天新增及变化的用户数据经过Sqoop导入到ods层的ods_user_info中了
(1)如何获得每日变动表
a. 最好表内有创建时间和变动时间(Lucky! 直接使用这两个字段获取数据)
b. 如果没有,可以利用第三方工具监控比如 canal,监控 MySQL 的实时变化进行记录(麻烦)。
c. 逐行对比前后两天的数据,检查 md5(concat(全部有可能变化的字段))是否相同(low)
d. 要求业务数据库提供变动流水
(2)因为 ods_user_info 本身导入过来就是新增变动明细的表,所以不用处理
a)数据库中新增 2020-06-15 一天的数据
b)通过 Sqoop 把 2020-06-15 日所有数据导入
mysql_to_hdfs.sh all 2020-06-15
c)ods 层数据导入
hdfs_to_ods_db.sh all 2020-06-15
步骤 2:先合并变动信息,再追加新增信息,插入到临时表中
1)建立临时表
drop table if exists dwd_dim_user_info_his_tmp;
create external table dwd_dim_user_info_his_tmp(
`id` string COMMENT '用户 id',
`name` string COMMENT '姓名',
`birthday` string COMMENT '生日',
`gender` string COMMENT '性别',
`email` string COMMENT '邮箱',
`user_level` string COMMENT '用户等级',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间',
`start_date` string COMMENT '有效开始日期',
`end_date` string COMMENT '有效结束日期'
) COMMENT '订单拉链临时表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_user_info_his_tmp/'
tblproperties ("parquet.compression"="lzo");
2)导入脚本

SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_user_info_his_tmp
select * from
(
select
id,
name,
birthday,
gender,
email,
user_level,
create_time,
operate_time,
'2022-03-18' start_date,
'9999-99-99' end_date
from ods_user_info where dt='2022-03-18'
union all
select
uh.id,
uh.name,
uh.birthday,
uh.gender,
uh.email,
uh.user_level,
uh.create_time,
uh.operate_time,
uh.start_date,
if(ui.id is not null and uh.end_date='9999-99-99', date_add(ui.dt,-1),
uh.end_date) end_date
from dwd_dim_user_info_his uh
left join
(
select
*
from ods_user_info
where dt='2022-03-18'
) ui on uh.id=ui.id
)
步骤 3:把临时表覆盖给拉链表
1)导入数据
insert overwrite table dwd_dim_user_info_his
select * from dwd_dim_user_info_his_tmp;
2)查询导入数据
select id, start_date, end_date from dwd_dim_user_info_his limit 2;
数仓搭建-DWS 层
- dws层仅是对每天的数据进行聚合统计形成宽表,dwt层是汇总层,对5天、7天、15天、一个月等等的数据进行汇总形成的宽表。
- DWS 层、DWT 层和 ADS 层都是以需求为驱动,和维度建模已经没有关系了。
- DWS 和 DWT 都是建宽表,按照主题去建表。主题相当于观察问题的角度。对应着维度表
- DWS 和 DWT 层的区别:DWS 层存放的所有主题对象当天的汇总行为,例如每个地区当天的下单次数,下单金额等,DWT 层存放的是所有主题对象的累积行为,例如每个地区最近7天(15天、30天、60天)的下单次数、下单金额等。
- ADS层对电商系统各大主题指标分别进行分析。
每日会员行为
- dws_user_action_daycount表中一行数据指代一个用户当天的所有行为的聚合值。
- dws层所创建的宽表服务于后续的各种业务分析
1)建表语句
drop table if exists dws_user_action_daycount;
create external table dws_user_action_daycount(
user_id string comment '用户 id',
login_count bigint comment '登录次数',
cart_count bigint comment '加入购物车次数',
order_count bigint comment '下单次数',
order_amount decimal(16,2) comment '下单金额',
payment_count bigint comment '支付次数',
payment_amount decimal(16,2) comment '支付金额',
order_detail_stats
---结构体中的数据,代表订单明细的一个商品项
array<struct<sku_id:string,sku_num:bigint,order_count:bigint,order_amount:decimal(20,2)>> comment '下单明细统计'
) COMMENT '每日会员行为'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dws/dws_user_action_daycount/'
tblproperties ("parquet.compression"="lzo");

2)数据装载
-
登录次数–>用户登录次数来源于启动日志表,App启动一次,用户需要登录一次。但用户也有可能没有登录,因此存在user_id为空的,需要过滤一下空值,求出用户登录次数。
-
select user_id, count(*) login_count from dwd_start_log where dt='2022-03-17' and user_id is not null group by user_id;
-
-
加入购物车次数
-
数据来源于用户动作日志表;先按dt过滤一天的,然后把action_id=cart_add的字段过滤出来,用户id不为空的数据过滤出来。
-
select user_id, count(*) as cartAdd_count from dwd_action_log where dt='2022-03-17' and action_id='cart_add' and user_id is not null group by user_id;
-
-
下单次数&下单金额
-
过滤当天的订单数据;数据来源dwd_fact_order_info,按照用户分组,求出每个用户的下单次数和下单总金额sum(金额)
-
select user_id, count(*) order_counts, sum(final_total_amount) order_amount from dwd_fact_order_info where dt='2022-03-17' group by user_id
-
-
支付次数&支付金额
-
select user_id, count(*) payment_counts, sum(payment_amount) payment_amount from dwd_fact_payment_info where dt='2022-03-17' group by user_id
-
-
下单明细统计是个结构体数据
-
统计的是当天时间每个用户的每个sku的各种信息(sku_id,商品数量,下单次数,总金额),数据来源于dwd_fact_order_detail表。
-
select user_id, sku_id, sum(sku_num) sku_num, count(*) order_count, sum(final_amount_d) order_amount from dwd_fact_order_detail where dt='2022-03-17' group by user_id,sku_id -
将上面的数据集封装成一个结构体
-
select user_id, named_struct('sku_id',sku_id,'sku_num',sku_num, 'order_count',order_count,'order_amount',order_amount) from ( select user_id, sku_id, sum(sku_num) sku_num, count(*) order_count, sum(final_amount_d) order_amount from dwd_fact_order_detail where dt='2022-03-17' group by user_id,sku_id )tmp -

-
-
将结构体封装到数组中,先分组后聚合—>这样就把每个用户购买的所有商品放入到一个数组中
-
select user_id, collect_list(named_struct('sku_id',sku_id,'sku_num',sku_num, 'order_count',order_count,'order_amount',order_amount)) order_stats from ( select user_id, sku_id, sum(sku_num) sku_num, count(*) order_count, sum(final_amount_d) order_amount from dwd_fact_order_detail where dt='2022-03-17' group by user_id,sku_id )tmp group by user_id

-
-
将所有的子查询数据集拼接起来,join关联起来
- 使用with tmp_table as( 子查询1) , tmp_table2 as(子查询2) …
-
with tmp_login as( select user_id, count(*) login_count from dwd_start_log where dt='2022-03-17' and user_id is not null group by user_id ), tmp_cart as ( select user_id, count(*) cart_count from dwd_action_log where dt='2022-03-17' and user_id is not null and action_id='cart_add' group by user_id ), tmp_order as( select user_id, count(*) order_count, sum(final_total_amount) order_amount from dwd_fact_order_info where dt='2022-03-17' group by user_id ), tmp_payment as( select user_id, count(*) payment_count, sum(payment_amount) payment_amount from dwd_fact_payment_info where dt='2022-03-17' group by user_id ), tmp_order_detail as ( select user_id, collect_set(named_struct('sku_id',sku_id,'sku_num',sku_num,'order_count',ord er_count,'order_amount',order_amount)) order_stats from ( select user_id, sku_id, sum(sku_num) sku_num, count(*) order_count, cast(sum(final_amount_d) as decimal(20,2)) order_amount from dwd_fact_order_detail where dt='2022-03-17' group by user_id,sku_id )tmp group by user_id )
数据加载sql
with tmp_login as( select user_id, count(*) login_count from dwd_start_log where dt='2022-03-17' and user_id is not null group by user_id ), tmp_cart as ( select user_id, count(*) cart_count from dwd_action_log where dt='2022-03-17' and user_id is not null and action_id='cart_add' group by user_id ), tmp_order as( select user_id, count(*) order_count, sum(final_total_amount) order_amount from dwd_fact_order_info where dt='2022-03-17' group by user_id ), tmp_payment as( select user_id, count(*) payment_count, sum(payment_amount) payment_amount from dwd_fact_payment_info where dt='2022-03-17' group by user_id ), tmp_order_detail as ( select user_id, collect_set(named_struct('sku_id',sku_id,'sku_num',sku_num,'order_count',ord er_count,'order_amount',order_amount)) order_stats from ( select user_id, sku_id, sum(sku_num) sku_num, count(*) order_count, cast(sum(final_amount_d) as decimal(20,2)) order_amount from dwd_fact_order_detail where dt='2022-03-17' group by user_id,sku_id )tmp group by user_id ) insert overwrite table dws_user_action_daycount partition(dt='2022-03-17') select tmp_login.user_id, login_count, nvl(cart_count,0), nvl(order_count,0), nvl(order_amount,0.0), nvl(payment_count,0), nvl(payment_amount,0.0), order_stats from tmp_login left join tmp_cart on tmp_login.user_id=tmp_cart.user_id left join tmp_order on tmp_login.user_id=tmp_order.user_id left join tmp_payment on tmp_login.user_id=tmp_payment.user_id left join tmp_order_detail on tmp_login.user_id=tmp_order_detail.user_id; -
每日设备行为
- dwd层每个维度对应dws层的一个主题
- 每日设备行为,主要按照设备 id 统计

- 设备主题比较特殊,因为在业务系统中并没有设备这个表,在dwd层并没有设备维度表。
- dws层设备行为表,表中一行数据代表一个设备当天的行为汇总信息,设备id——>即独立访客流量的统计
- 页面访问统计字段为一个结构体数组:
page_statsarray < struct < page_id:string,page_count:bigint >>- struct < page_id:string,page_count:bigint >这个结构体中的数据代表该设备访问的一次记录,访问了那个页面,访问次数等等。
- 数组中数据代表了一个设备用户当天访问的所有页面的信息
1)建表语句
drop table if exists dws_uv_detail_daycount;
create external table dws_uv_detail_daycount
(
`mid_id` string COMMENT '设备 id',
`brand` string COMMENT '手机品牌',
`model` string COMMENT '手机型号',
`login_count` bigint COMMENT '活跃次数',
`page_stats` array<struct<page_id:string,page_count:bigint>> COMMENT '页面访问统计'
) COMMENT '每日设备行为表'
partitioned by(dt string)
stored as parquet
location '/warehouse/gmall/dws/dws_uv_detail_daycount'
tblproperties ("parquet.compression"="lzo");
2)数据装载
-
设备id字段和手机品牌、手机型号字段来自于dwd_start_log启动日志表,因此直接查询
-
login_count字段需要根据每个设备分组统计登录次数,一行数据代表一个设备的访问记录
-
select mid_id, brand,model,count(*) login_count from dwd_start_log where dt='2022-03-17' group by mid_id,brand,model;- hive中涉及分组的sql语句,查询的字段只能是一下三种:
- 分组字段
- 聚合函数
- 常量值
- 因此这里需要按照设备id,brand, model手机型号三个字段分组。
- hive中涉及分组的sql语句,查询的字段只能是一下三种:
-
page_statsarray < struct-
首先结构体中的数据是代表一个设备的一个页面访问记录;因此我们需要根据设备id,page_id进行分组查询;然后再使用count(*)聚合函数统计访问页面次数;再把这个数据封装为结构体。
-
select mid_id, brand, model, collect_list(named_struct('page_id',page_id,'page_count',view_page_count)) page_stats from ( select mid_id,page_id,count(*) view_page_count from dwd_page_log where dt='2022-03-17' group by mid_id,brand,model,page_id )tmp group by mid_id -
再将上面这两个数据集join起来,可以使用with table1 as( 子查询1 ) table2 as(子查询2)…;使用的是全外联
-
最终SQL:
with
tmp_start as
(
select
mid_id,
brand,
model,
count(*) login_count
from dwd_start_log
where dt='2022-03-17'
group by mid_id,brand,model
),
tmp_page as
(
selectmid_id,
brand,
model,
collect_set(named_struct('page_id',page_id,'page_count',page_count))
page_stats
from
(
select
mid_id,
brand,
model,
page_id,
count(*) page_count
from dwd_page_log
where dt='2022-03-17'
group by mid_id,brand,model,page_id
)tmp
group by mid_id,brand,model
)
insert overwrite table dws_uv_detail_daycount partition(dt='2022-03-17')
select
nvl(tmp_start.mid_id,tmp_page.mid_id),
nvl(tmp_start.brand,tmp_page.brand),
nvl(tmp_start.model,tmp_page.model),
tmp_start.login_count,
tmp_page.page_stats
from tmp_start
full outer join tmp_page
on tmp_start.mid_id=tmp_page.mid_id
and tmp_start.brand=tmp_page.brand
and tmp_start.model=tmp_page.model;
- 结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jTvxQ8GC-1648101873823)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220321105314431.png)]](http://img.e-com-net.com/image/info8/95ff22162cf94c7198a98bc19d5bdda3.jpg)
每日商品行为
- 每日商品表:每行数据表示与商品相关的各种操作记录,如被下单次数,被支付次数等等
1)建表语句
drop table if exists dws_sku_action_daycount;
create external table dws_sku_action_daycount
(
sku_id string comment 'sku_id',
---订单明细事实表
order_count bigint comment '被下单次数',
order_num bigint comment '被下单件数',
order_amount decimal(16,2) comment '被下单金额',
---从订单表中过滤出已支付的商品
payment_count bigint comment '被支付次数',
payment_num bigint comment '被支付件数',
payment_amount decimal(16,2) comment '被支付金额',
---退款事实表
refund_count bigint comment '被退款次数',
refund_num bigint comment '被退款件数',
refund_amount decimal(16,2) comment '被退款金额',
---action_log动作日志表
cart_count bigint comment '被加入购物车次数',
favor_count bigint comment '被收藏次数',
--评价事实表
appraise_good_count bigint comment '好评数',
appraise_mid_count bigint comment '中评数',
appraise_bad_count bigint comment '差评数',
appraise_default_count bigint comment '默认评价数'
) COMMENT '每日商品行为'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dws/dws_sku_action_daycount/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
- 注意:如果是 23 点 59 下单,支付日期跨天。需要从订单详情里面取出支付时间是今天,且订单时间是昨天或者今天的订单。
dws层商品主题每日汇总表的数据装载SQL思路:
-

-
第一张表dwd_fact_order_detail,每个商品的下单次数,下单件数,被下单金额
-
select sku_id, count(*) order_count, sum(sku_num) order_num, sum(final_amount_d) order_amount from dwd_fact_order_detail where dt='2022-03-17' group by sku_id
-
-
第二张表dwd_fact_payment_info,按照当天分区,从订单详情事实表中过滤出已支付的所有订单,把它这些order_id作为过滤条件order_id in(…)
-
当天支付的订单
-
select order_id from dwd_fact_payment_info where dt='2022-03-17' -
但是存在一个问题? 当天支付的订单不一定是当天下的单,因此我们需要做一下处理,把筛选条件放宽至两日( 一般2天内没支付的订单就会被取消 )
-
select order_id from dwd_fact_payment_info where dt='2022-03-17' or date_add('2022-03-17',-1)
-
-
select sku_id, count(*) order_count, sum(sku_num) order_num, sum(final_amount_d) order_amount from dwd_fact_order_detail where ( dt='2022-03-17' or date_add('2022-03-17',-1) ) and order_id in( select order_id from dwd_fact_payment_info where dt='2022-03-17' ) group by sku_id
-
-
第三张表中获取的数据:从订单退款事实表dwd_fact_order_refund_info 中查询出每件商品的退款次数,退款件数、退款金额。按时间分区过滤表中数据,按商品sku_id分组查询,使用count()、sum()聚合函数求出退款商品总件数、总金额。
-
select sku_id, count(*) refund_count, sum(refund_num) refund_num, sum(refund_amount) refund_amount from dwd_fact_order_refund_info where dt='2022-03-17' group by sku_id
-
-
第四张表中查询数据:从动作日志表中dwd_action_log 获取当天时间分区的数据,然后过滤action_id为添加购物车和添加收藏的商品数据。动作日志表中的每一条数据代表了当前设备在页面的一次行为记录。
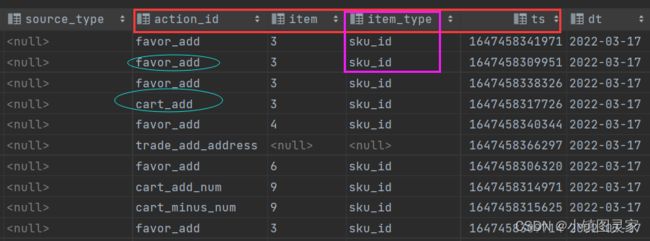
-
从上面的图中可以看出,前端actions的json字段,包含了动作_id,item动作对象id,动作目标类型,出现顺序。item–>对应的是操作的对象的id也就是商品的id,比如将sku_id为3的商品对象进行了收藏添加,也就是item商品项对象id为3.
-
因此这里需要按照item进行分组:
-
select item sku_id, count(*) favor_count from dwd_action_log where dt='2022-03-17' and user_id is not null and action_id='favor_add' group by item ---再过滤出添加购物车的操作,两个数据集join -
可以使用sum( if(action_id=‘cart_add’ ,1,0) ) 和sum( if(action_id=‘favor_add’ ,1,0) )进行整合
-
select item sku_id, sum( if(action_id='cart_add' ,1,0)) cart_add_num, sum( if(action_id='favor_add' ,1,0)) favor_add_num from dwd_action_log where dt='2022-03-17' and user_id is not null and action_id in('favor_add','card_add') group by item
-
-
第五张表:从评论事实表中dwd_fact_comment_info查询出数据。
-
评价事实表中的appraise这个字段的数值对应的是评价的编号—>对应字典编码表ods_base_dic中的:
-
1201 --->好评 1202-->中评 1203-->差评 1204-->自动评价
-
-
select sku_id, sum(if(appraise='1201',1,0)) appraise_good_count, sum(if(appraise='1202',1,0)) appraise_mid_count, sum(if(appraise='1203',1,0)) appraise_bad_count, sum(if(appraise='1204',1,0)) appraise_default_count from dwd_fact_comment_info where dt='2022-03-17' group by sku_id
-
-
将以上多张表查询的数据集full join得到最终的数据,最终SQL
with
tmp_order as
(
select
sku_id,
count(*) order_count,
sum(sku_num) order_num,
sum(final_amount_d) order_amount
from dwd_fact_order_detail
where dt='2022-03-17'
group by sku_id
),
tmp_payment as
(
select
sku_id,
count(*) payment_count,
sum(sku_num) payment_num,
sum(final_amount_d) payment_amount
from dwd_fact_order_detail
where (dt='2022-03-17'
or dt=date_add('2022-03-17',-1))
and order_id in
(
select
id
from dwd_fact_order_info
where (dt='2022-03-17'
or dt=date_add('2022-03-17',-1))
and date_format(payment_time,'yyyy-MM-dd')='2022-03-17'
)
group by sku_id
),
tmp_refund as
(
select
sku_id,
count(*) refund_count,
sum(refund_num) refund_num,
sum(refund_amount) refund_amount
from dwd_fact_order_refund_info
where dt='2022-03-17'
group by sku_id
),
tmp_cart as
(
select
item sku_id,
count(*) cart_count
from dwd_action_log
where dt='2022-03-17'
and user_id is not null
and action_id='cart_add'
group by item
),tmp_favor as
(
select
item sku_id,
count(*) favor_count
from dwd_action_log
where dt='2022-03-17'
and user_id is not null
and action_id='favor_add'
group by item
),
tmp_appraise as
(
select
sku_id,
sum(if(appraise='1201',1,0)) appraise_good_count,
sum(if(appraise='1202',1,0)) appraise_mid_count,
sum(if(appraise='1203',1,0)) appraise_bad_count,
sum(if(appraise='1204',1,0)) appraise_default_count
from dwd_fact_comment_info
where dt='2022-03-17'
group by sku_id
)
insert overwrite table dws_sku_action_daycount partition(dt='2022-03-17')
select
sku_id,
sum(order_count),
sum(order_num),
sum(order_amount),
sum(payment_count),
sum(payment_num),
sum(payment_amount),
sum(refund_count),
sum(refund_num),
sum(refund_amount),
sum(cart_count),
sum(favor_count),
sum(appraise_good_count),
sum(appraise_mid_count),
sum(appraise_bad_count)
sum(appraise_default_count)
from
(
select
sku_id,
order_count,
order_num,
order_amount,
0 payment_count,
0 payment_num,
0 payment_amount,
0 refund_count,
0 refund_num,
0 refund_amount,
0 cart_count,
0 favor_count,
0 appraise_good_count,
0 appraise_mid_count,
0 appraise_bad_count,
0 appraise_default_count
from tmp_order
union all
select
sku_id,
0 order_count,
0 order_num,
0 order_amount,
payment_count,
payment_num,
payment_amount,
0 refund_count,
0 refund_num,
0 refund_amount,
0 cart_count,
0 favor_count,
0 appraise_good_count,
0 appraise_mid_count,
0 appraise_bad_count,
0 appraise_default_count
from tmp_payment
union all
select
sku_id,
0 order_count,
0 order_num,
0 order_amount,
0 payment_count,
0 payment_num,
0 payment_amount,
refund_count,
refund_num,
refund_amount,
0 cart_count,
0 favor_count,
0 appraise_good_count,
0 appraise_mid_count,
0 appraise_bad_count,
0 appraise_default_count
from tmp_refund
union all
select
sku_id,
0 order_count,
0 order_num,
0 order_amount,
0 payment_count,
0 payment_num,
0 payment_amount,
0 refund_count,
0 refund_num,
0 refund_amount,
cart_count,
0 favor_count,
0 appraise_good_count,
0 appraise_mid_count,
0 appraise_bad_count,
0 appraise_default_count
from tmp_cart
union all
select
sku_id,
0 order_count,
0 order_num,
0 order_amount,
0 payment_count,
0 payment_num,
0 payment_amount,
0 refund_count,
0 refund_num,
0 refund_amount,
0 cart_count,
favor_count,
0 appraise_good_count,
0 appraise_mid_count,
0 appraise_bad_count,
0 appraise_default_count
from tmp_favor
union all
select
sku_id,
0 order_count,
0 order_num,
0 order_amount,
0 payment_count,
0 payment_num,
0 payment_amount,
0 refund_count,
0 refund_num,
0 refund_amount,
0 cart_count,
0 favor_count,
appraise_good_count,
appraise_mid_count,
appraise_bad_count,
appraise_default_count
from tmp_appraise
)tmp
group by sku_id;
dws层每日活动统计
- 每日活动统计表:粒度:一行数据代表一个活动当天的行为,即那些订单参与了活动。
- 首先该表是跟活动维度相关的字段和度量值。

1)建表语句
drop table if exists dws_activity_info_daycount;
create external table dws_activity_info_daycount(
--来自dwd层的活动维度表
`id` string COMMENT '编号',
`activity_name` string COMMENT '活动名称',
`activity_type` string COMMENT '活动类型',
`start_time` string COMMENT '开始时间',
`end_time` string COMMENT '结束时间',
`create_time` string COMMENT '创建时间',
--来自于曝光日志
`display_count` bigint COMMENT '曝光次数',
--来自于订单事实表
`order_count` bigint COMMENT '下单次数',
`order_amount` decimal(20,2) COMMENT '下单金额',
--由于支付事实表直接跟订单挂钩与商品是否参与活动无关,这里需要通过订单事实表筛选出已支付的且参与活动的订单获取
`payment_count` bigint COMMENT '支付次数',
`payment_amount` decimal(20,2) COMMENT '支付金额'
) COMMENT '每日活动统计'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dws/dws_activity_info_daycount/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
- 每日活动统计表的数据来源:
- id、activity_name、activity_type、start_time、end_time、create_time来自于dwd_dim_activity活动维度表
- display_count来自于曝光日志表
- 下单次数、下单金额可以从订单事实表中通过活动id筛选出参与活动的商品,然后统计出下单次数和金额
- 支付次数和支付金额需要通过订单事实表,筛选出已支付的订单中参与活动的订单的商品,然后再统计支付次数和支付金额
with
tmp_op as(
--下单和支付的统计
select
activity_id,
sum(if(date_format(create_time,'yyyy-MM-dd')='2022-03-17',1,0)) order_count,
sum(if(date_format(create_time,'yyyy-MM-dd')='2022-03-17',final_total_amount,0)) order_amount,
sum(if(date_format(payment_time,'yyyy-MM-dd')='2022-03-17',1,0)) payment_count,
sum(if(date_format(payment_time,'yyyy-MM-dd')='2022-03-17',final_total_amount,0)) payment_amount
from dwd_fact_order_info
where (dt='2022-03-17' or dt=date_add('2022-03-17',-1))
and activity_id is not null
group by activity_id
),
tmp_display as(
--商品项活动id,曝光次数和
select
item activity_id,
count(*) display_count
from dwd_display_log
where dt='2022-03-17'
and item_type='2022-03-17'
group by item
),
tmp_activity as(
--活动维度表中的所有数据
select
*
from dwd_dim_activity_info
where dt='2022-03-17'
)
insert overwrite table dws_activity_info_daycount partition(dt='2022-03-17')
select
nvl(tmp_op.activity_id,tmp_display.activity_id),
tmp_activity.activity_name,
tmp_activity.activity_type,
tmp_activity.start_time,
tmp_activity.end_time,
tmp_activity.create_time,
tmp_display.display_count,
tmp_op.order_count,
tmp_op.order_amount,
tmp_op.payment_count,
tmp_op.payment_amount
from tmp_op
full outer join tmp_display on tmp_op.activity_id=tmp_display.activity_id
left join tmp_activity on
nvl(tmp_op.activity_id,tmp_display.activity_id)=tmp_activity.id;
每日地区统计
- 地区维度—> 每日地区统计的粒度:每行数据指代一个地区当天的各种统计表,如一个地区的下单次数、下单金额、支付次数、支付金额等。
- dws层 每日地区统计宽表是以地区维度为主题,进行每日统计的相关数据集。
- 每日地区统计表包含两部分:
- 地区维度表中的字段
- 以维度为主题的各种相关度量统计值 (如:一个地区当日活跃设备数、下单次数、当日下单金额、支付次数、支付金额等等)
- 每日地区统计表包含两部分:
1)建表语句
drop table if exists dws_area_stats_daycount;
create external table dws_area_stats_daycount(
`id` bigint COMMENT '编号',
`province_name` string COMMENT '省份名称',
`area_code` string COMMENT '地区编码', ---一个地区编码对应一个省份
`iso_code` string COMMENT 'iso 编码',
`region_id` string COMMENT '地区 ID',
`region_name` string COMMENT '地区名称',
--从启动日志表中按照地区编码分组查询,然后统计出每个地区的登录次数即为活跃设备数
`login_count` string COMMENT '活跃设备数',
--从dwd_fact_order_info订单事实表中按照province_id分组查询,然后统计出近一天的下单次数和下单金额
`order_count` bigint COMMENT '下单次数',
`order_amount` decimal(20,2) COMMENT '下单金额',
--从支付事实表中按照省份id分组查询,然后按照近一日的支付次数、支付金额
`payment_count` bigint COMMENT '支付次数',
`payment_amount` decimal(20,2) COMMENT '支付金额'
) COMMENT '每日地区统计表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dws/dws_area_stats_daycount/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
-
数据来源那些表:
- 地区维度表、启动日志表、订单事实表、支付事实表
- 数据如何查询?
-
地区维度表:id、province_name、area_code、iso_code、region_id、region_name这5个字段的数据直接从地区维度表查询
-
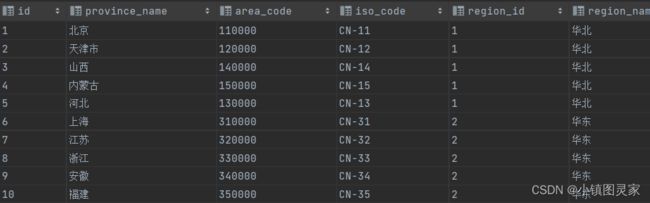
-
dwd订单事实表–>从dwd_fact_order_info订单事实表中按照province_id分组查询,然后统计出近一天的下单次数和下单金额
-

-
启动日志表–>从启动日志表中按照地区编码分组查询,然后统计出每个地区的登录次数即为活跃设备数
-
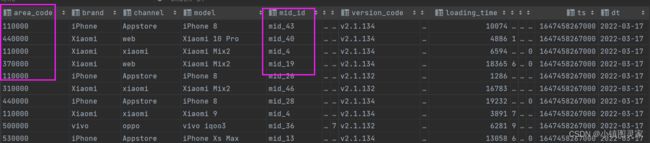
-
支付事实表—>从支付事实表中按照省份id分组查询,然后按照近一日的支付次数、支付金额
-
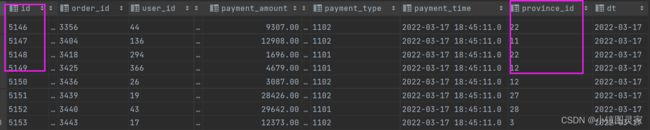
-
4张表通过full join连接获取最终数据,或者采用下面的这种方式。
最终加载数据的SQL:
with
tmp_login as(
--每个地区的活跃设备数
select
area_code,
count(*) login_count
from dwd_start_log where dt='2022-03-17'
group by area_code
),
tmp_op as(
--订单及支付,每个地区下单次数、下单金额,以及支付次数、支付金额
select
province_id,
sum(if(date_format(create_time,'yyyy-MM-dd')='2022-03-17',1,0)) order_count,
sum(if(date_format(create_time,'yyyy-MM-dd')='2022-03-17',final_total_amount,0)) order_amount,
sum(if(date_format(payment_time,'yyyy-MM-dd')='2022-03-17',1,0)) payment_count,
sum(if(date_format(payment_time,'yyyy-MM-dd')='2022-03-17',final_total_amount,0)) payment_amount
from dwd_fact_order_info
where (dt='2022-03-17' or dt=date_add('2022-03-17',-1))
group by province_id
)
insert overwrite table dws_area_stats_daycount partition(dt='2022-03-17')
select
pro.id,
pro.province_name,
pro.area_code,
pro.iso_code,
pro.region_id,
pro.region_name,
nvl(tmp_login.login_count,0),
nvl(tmp_op.order_count,0),
nvl(tmp_op.order_amount,0.0),
nvl(tmp_op.payment_count,0),
nvl(tmp_op.payment_amount,0.0)
from dwd_dim_base_province pro --地区表的一个全量数据
left join tmp_login on pro.area_code=tmp_login.area_code
left join tmp_op on pro.id=tmp_op.province_id;
- 需要注意的是地区维表的主键是area_code,而订单表的地区id为province_id,虽然他们都代表一个省份,但是字段不同该怎么join? 关联的字段不同无法join怎么解决?
- 这里解决的方式是:用地区维度表
left join登陆表子查询tmp_login,关联的字段为area_code;然后再左外连接订单支付表子查询的虚表tmp_op;通过province_id进行关联。 - 另外一点是这里的地区维度表是一个全量的数据,因为后期可视化如地图需要每个地区都有才行!
dws层数据加载脚本
- 略
数仓搭建-DWT 层
- DWT 层存放的是所有主题对象的累积行为,例如每个地区最近7天(15天、30天、60天)的下单次数、下单金额等。
- 宽表字段怎么来?维度关联的事实表度量值+开头、结尾+累积+累积一个时间段。
会员主题宽表
- DWS 和 DWT层都是按照主题去建宽表。主题相当于观察问题的角度。对应着维度表
- 会员主题宽表中的一行数据代表的是对应一个用户的各种累积值,如某user的登录天数、首次下单时间、最近30日下单次数,累加支付次数等等。
- 会员主题表中数据如何更新?


1)建表语句
drop table if exists dwt_user_topic;
create external table dwt_user_topic
(
user_id string comment '用户 id',
login_date_first string comment '首次登录时间',
login_date_last string comment '末次登录时间',
login_count bigint comment '累积登录天数',
login_last_30d_count bigint comment '最近 30 日登录天数',
order_date_first string comment '首次下单时间',
order_date_last string comment '末次下单时间',
order_count bigint comment '累积下单次数',
order_amount decimal(16,2) comment '累积下单金额',
order_last_30d_count bigint comment '最近 30 日下单次数',
order_last_30d_amount bigint comment '最近 30 日下单金额',
payment_date_first string comment '首次支付时间',
payment_date_last string comment '末次支付时间',
payment_count decimal(16,2) comment '累积支付次数',
payment_amount decimal(16,2) comment '累积支付金额',
payment_last_30d_count decimal(16,2) comment '最近 30 日支付次数',
payment_last_30d_amount decimal(16,2) comment '最近 30 日支付金额'
)COMMENT '会员主题宽表'
stored as parquet
location '/warehouse/gmall/dwt/dwt_user_topic/'
tblproperties ("parquet.compression"="lzo");
- 那些表需要初始化,从dwd层开始,维度表中的拉链表需要做初始化。需要全量数据的表,需要创建初始化表。
(2) 会员主题表的数据如何更新?—>思路:

-
首次登录时间字段:
- 老用户不变,新用户的首次登录时间就是当天日期
-
末次登录时间:
- 对于变化的用户的末次登录时间,需要改成当天
-
累积登录天数
- 1)对于未变化的用户,累积登录天数不变
- 2)对于变化了的活跃用户,累积登录天数加1
- 3)新增用户累积登录天数为1
-
最近30日登录天数:
- 把用户最近30天的登录次数求出来覆盖历史的数据
<1> 查询出当天活跃登录的用户
-
select user_id from dws_user_action_daycount where dt='2022-03-17' and login_count>0
<2> 查询出最近30天用户的累积登录天数,登录了加1,没有登录为0
-
select user_id, sum(if(login_count>0,1,0)) from dws_user_action_daycount where dt>=data_add('2022-03-17',-29) and dt<='2022-03-17' group by user_id -
由于最近30天活跃的用户包含当天活跃的用户,因此可以通过一个筛选条件将(1)和(2)的SQL合成一个SQL
-
select user_id, sum(if(dt='2022-03-17',login_count,0)), sum(if(login_count>0,1,0)) from dws_user_action_daycount where dt>=data_add('2022-03-17',-29) and dt<='2022-03-17' group by user_id
(3) 历史用户的数据dwt_user_topic —> old —>大体思路如下:
select
--查询需要的字段
nvl(new.user_id,old.user_id),
nvl(old.login_date_first,'2022-03-17',old.login_date_last),
if(new.login_day_count>0,'2022-03-17',old.login_date_last),
nvl(old.login_count,0)+if(login_day_count>0,1,0),
nvl(new.login_last_30d_count,0)
from dwt_user_topic old --历史数据
full join
--最近30天的用户
(
select
user_id,
sum(if(dt='2022-03-17',login_count,0)) login_day_count, --当天登录的用户
sum(if(login_count>0,1,0)) login_last_30d_count --最近30天登录的用户
from dws_user_action_daycount
where dt>=data_add('2022-03-17',-29) and dt<='2022-03-17'
group by user_id
)new
on new.user_id=old.user_id
- 其他字段思路相同
最终数据加载SQL
--覆写数据
insert overwrite table dwt_user_topic
select
nvl(new.user_id,old.user_id),
if(old.login_date_first is null and new.login_count>0,'2022-03-17',old.login_date_first),
if(new.login_count>0,'2022-03-17',old.login_date_last),
nvl(old.login_count,0)+if(new.login_count>0,1,0),
nvl(new.login_last_30d_count,0),
if(old.order_date_first is null and new.order_count>0,'2022-03-17',old.order_date_first),
if(new.order_count>0,'2022-03-17',old.order_date_last),
nvl(old.order_count,0)+nvl(new.order_count,0),
nvl(old.order_amount,0)+nvl(new.order_amount,0),
nvl(new.order_last_30d_count,0),
nvl(new.order_last_30d_amount,0),
if(old.payment_date_first is null and new.payment_count>0,'2022-03-17',old.payment_date_first),
if(new.payment_count>0,'2022-03-17',old.payment_date_last),
nvl(old.payment_count,0)+nvl(new.payment_count,0),
nvl(old.payment_amount,0)+nvl(new.payment_amount,0),
nvl(new.payment_last_30d_count,0),
nvl(new.payment_last_30d_amount,0)
from
dwt_user_topic old --会员用户历史数据
full outer join
(
select
user_id,
sum(if(dt='2022-03-17',login_count,0)) login_count,
sum(if(dt='2022-03-17',order_count,0)) order_count,
sum(if(dt='2022-03-17',order_amount,0)) order_amount,
sum(if(dt='2022-03-17',payment_count,0)) payment_count,
sum(if(dt='2022-03-17',payment_amount,0)) payment_amount,
sum(if(login_count>0,1,0)) login_last_30d_count,
sum(order_count) order_last_30d_count,
sum(order_amount) order_last_30d_amount,
sum(payment_count) payment_last_30d_count,
sum(payment_amount) payment_last_30d_amount
from dws_user_action_daycount
where dt>=date_add('2022-03-17',-30)
group by user_id
)new --最近30天会员用户的登录数据
on old.user_id=new.user_id;
设备主题宽表

-
dwt设备主题宽表的表结构:
- 设备主题宽表应该有全量信息表,因此首次需要初始化。
- 设备主题宽表没有分区,表中一行数据代表一个设备的汇总信息。后续每天重复执行逻辑,将每日 ”新增及变化的数据“ 更新到历史设备主题宽表中。
-
设备主题累积汇总表——新增用户与首次注册或下载的标记
-
新增用户标记采集
新用户的标记主要是在客户端完成,神策 SDK 默认会采集的区分新增用户的字段有前端事件公共属性:是否首日访问($is_first_day)
字段名称 类型 说明 JS SDK 自动采集 iOS SDK 自动采集 Android SDK 自动采集 小程序 SDK 自动采集 服务端 SDK 自动采集 $is_first_day 布尔值 是否首日访问 Y Y Y Y N 实现逻辑:
-
Web 端:用户第一次访问埋入神策 SDK 页面的当天(即第一天),JS SDK 会在网页的 cookie 中设置一个首日访问的标记,并设置第一天 24 点之前,该标记记为首日为 true,即第一天触发的网页端所有事件中,is_first_day=true。第一天之后,该标记则为 首日为 false,即第一天之后触发的网页端所有事件中,is_first_day= false;
-
小程序端:用户第一天访问埋入神策 SDK 的页面时,小程序 SDK 会在 storage 缓存中创建一个首日为 true 的标记,并且设置第一天 24 点之前,该标记均为 true。即第一天触发的小程序端所有事件中,is_first_day=true。第一天之后,该标记则为 首日为 false,即第一天之后触发的小程序端所有事件中,is_first_day= false;
-
APP 端:用户安装 App 后,第一次打开埋入神策 SDK 的 App 的当天,Android/iOS SDK 会在手机本地缓存内,创建一个首日为 true 的标记,并且设置第一天 24 点之前,该标记均为 true。即第一天触发的 APP 端所有事件中,is_first_day=true。第一天之后,该标记则为 首日为 false,即第一天之后触发的 APP 端所有事件中,is_first_day= false;
前端事件属性:是否首次触发事件($is_first_time)
-
-
-
首次访问在服务端的修正:
- 如上文所述,判断新增用户时,是通过 App/Web/小程序上报的属性 is_first_day (是否首日访问)为 true 来进行判断的。在如下场景下,is_first_day 取值会出现错误,这就需要依靠神策服务端来进行修正。
- 场景一:App 缓存被清理或者用户卸载重装。这会导致前端标记被清除。标记清除之后再使用,首日首次属性又会被识别为 true 进行上报。神策服务端会对此进行修正,修正逻辑:当有 is_first_day (是否首日访问)属性上报并且取值为 true 时,神策服务端会对本次日期与历史该用户首个 is_first_day (是否首日访问)为 true 的日期进行比较。如果不在同一天,那么修正本次 is_first_day 为 false。
- 场景二:由未接入神策 SDK 的版本升级到接入神策 SDK 的版本。比如:小明从 2012 年就开始使用您家的 App,是一个元老级用户。在 2020-1-1 日您家上线了集成神策 SDK 的 Android 新版本,小明升级了 App。神策 SDK 第一次打标记,识别小明的 is_first_day (是否首日访问)属性为 true 并进行上报。显然这样是不准确的。因为小明虽然对神策来说是新用户,但是本质上他是一个老用户。
- 如上文所述,判断新增用户时,是通过 App/Web/小程序上报的属性 is_first_day (是否首日访问)为 true 来进行判断的。在如下场景下,is_first_day 取值会出现错误,这就需要依靠神策服务端来进行修正。
1)建表语句
drop table if exists dwt_uv_topic;
create external table dwt_uv_topic
(
`mid_id` string comment '设备 id',
`brand` string comment '手机品牌',
`model` string comment '手机型号',
`login_date_first` string comment '首次活跃时间',
`login_date_last` string comment '末次活跃时间',
`login_day_count` bigint comment '当日活跃次数',
`login_count` bigint comment '累积活跃天数'
) COMMENT '设备主题宽表'
stored as parquet
location '/warehouse/gmall/dwt/dwt_uv_topic'
tblproperties ("parquet.compression"="lzo");
2)设备主题累积汇总宽表__数据装载
-
思路:新旧数据对比,历史数据和当日新增及变化的数据进行对比
-
历史数据,dwt_uv_topic as old
-
当日新增及变化的数据在dws层的dws_detail_daycount中存在,直接按照时间分区查询即可:对应sql如下
-
select mid_id,brand,model,login_count from dws_uv_detail_daycount where dt='2022-03-17' -
历史数据和当天新增及变化数据进行full join
select xxxx, xxxx dwt_uv_topic old full outer join ( select mid_id,brand,model,login_count from dws_uv_detail_daycount where dt='2022-03-17' )new on old.mid_id=new.mid_id
-
-
最终SQL
-

insert overwrite table dwt_uv_topic
select
nvl(new.mid_id,old.mid_id),
nvl(new.model,old.model),
nvl(new.brand,old.brand),
if(old.mid_id is null,'2022-03-17',old.login_date_first),
if(new.mid_id is not null,'2022-03-17',old.login_date_last),
if(new.mid_id is not null, new.login_count,0),
nvl(old.login_count,0)+if(new.login_count>0,1,0)
from
(
select
*
from dwt_uv_topic
)old
full outer join
(
select
*
from dws_uv_detail_daycount
where dt='2022-03-17'
)new
on old.mid_id=new.mid_id;
dwt层商品主题宽表
- dwt层商品主题宽表,要求该表有全量的sku数据才可以,因此需要有初始化表。dwt商品主题宽表初始化表为一个临时表,从mysql中以全量的形式导入。
- dwt层商品主题宽表中一行数据代表一个商品sku对应的各种汇总累积的聚合值。
1)建表语句
drop table if exists dwt_sku_topic;
create external table dwt_sku_topic(
sku_id string comment 'sku_id',
spu_id string comment 'spu_id',
order_last_30d_count bigint comment '最近 30 日被下单次数',
order_last_30d_num bigint comment '最近 30 日被下单件数',
order_last_30d_amount decimal(16,2) comment '最近 30 日被下单金额',
order_count bigint comment '累积被下单次数',
order_num bigint comment '累积被下单件数',
order_amount decimal(16,2) comment '累积被下单金额',
payment_last_30d_count bigint comment '最近 30 日被支付次数',
payment_last_30d_num bigint comment '最近 30 日被支付件数',
payment_last_30d_amount decimal(16,2) comment '最近 30 日被支付金额',
payment_count bigint comment '累积被支付次数',
payment_num bigint comment '累积被支付件数',
payment_amount decimal(16,2) comment '累积被支付金额',
refund_last_30d_count bigint comment '最近三十日退款次数',
refund_last_30d_num bigint comment '最近三十日退款件数',
refund_last_30d_amount decimal(16,2) comment '最近三十日退款金额',
refund_count bigint comment '累积退款次数',
refund_num bigint comment '累积退款件数',
refund_amount decimal(16,2) comment '累积退款金额',
cart_last_30d_count bigint comment '最近 30 日被加入购物车次数',
cart_count bigint comment '累积被加入购物车次数',
favor_last_30d_count bigint comment '最近 30 日被收藏次数',
favor_count bigint comment '累积被收藏次数',
appraise_last_30d_good_count bigint comment '最近 30 日好评数',
appraise_last_30d_mid_count bigint comment '最近 30 日中评数',
appraise_last_30d_bad_count bigint comment '最近 30 日差评数',
appraise_last_30d_default_count bigint comment '最近 30 日默认评价数',
appraise_good_count bigint comment '累积好评数',
appraise_mid_count bigint comment '累积中评数',
appraise_bad_count bigint comment '累积差评数',
appraise_default_count bigint comment '累积默认评价数'
)COMMENT '商品主题宽表'
stored as parquet
location '/warehouse/gmall/dwt/dwt_sku_topic/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
insert overwrite table dwt_sku_topic
select
nvl(new.sku_id,old.sku_id),
sku_info.spu_id,
nvl(new.order_count30,0),
nvl(new.order_num30,0),
nvl(new.order_amount30,0),
nvl(old.order_count,0) + nvl(new.order_count,0),
nvl(old.order_num,0) + nvl(new.order_num,0),
nvl(old.order_amount,0) + nvl(new.order_amount,0),
nvl(new.payment_count30,0),
nvl(new.payment_num30,0),
nvl(new.payment_amount30,0),
nvl(old.payment_count,0) + nvl(new.payment_count,0),
nvl(old.payment_num,0) + nvl(new.payment_count,0),
nvl(old.payment_amount,0) + nvl(new.payment_count,0),
nvl(new.refund_count30,0),
nvl(new.refund_num30,0),
nvl(new.refund_amount30,0),
nvl(old.refund_count,0) + nvl(new.refund_count,0),
nvl(old.refund_num,0) + nvl(new.refund_num,0),
nvl(old.refund_amount,0) + nvl(new.refund_amount,0),
nvl(new.cart_count30,0),
nvl(old.cart_count,0) + nvl(new.cart_count,0),
nvl(new.favor_count30,0),
nvl(old.favor_count,0) + nvl(new.favor_count,0),
nvl(new.appraise_good_count30,0),
nvl(new.appraise_mid_count30,0),
nvl(new.appraise_bad_count30,0),
nvl(new.appraise_default_count30,0) ,
nvl(old.appraise_good_count,0) + nvl(new.appraise_good_count,0),
nvl(old.appraise_mid_count,0) + nvl(new.appraise_mid_count,0),
nvl(old.appraise_bad_count,0) + nvl(new.appraise_bad_count,0),
nvl(old.appraise_default_count,0) + nvl(new.appraise_default_count,0)
from dwt_sku_topic old
full outer join
(
select
sku_id,
sum(if(dt='2022-03-17', order_count,0 )) order_count,
sum(if(dt='2022-03-17',order_num ,0 )) order_num,
sum(if(dt='2022-03-17',order_amount,0 )) order_amount ,
sum(if(dt='2022-03-17',payment_count,0 )) payment_count,
sum(if(dt='2022-03-17',payment_num,0 )) payment_num,
sum(if(dt='2022-03-17',payment_amount,0 )) payment_amount,
sum(if(dt='2022-03-17',refund_count,0 )) refund_count,
sum(if(dt='2022-03-17',refund_num,0 )) refund_num,
sum(if(dt='2022-03-17',refund_amount,0 )) refund_amount,
sum(if(dt='2022-03-17',cart_count,0 )) cart_count,
sum(if(dt='2022-03-17',favor_count,0 )) favor_count,
sum(if(dt='2022-03-17',appraise_good_count,0 )) appraise_good_count,
sum(if(dt='2022-03-17',appraise_mid_count,0 ) ) appraise_mid_count ,
sum(if(dt='2022-03-17',appraise_bad_count,0 )) appraise_bad_count,
sum(if(dt='2022-03-17',appraise_default_count,0 )) appraise_default_count,
sum(order_count) order_count30 ,
sum(order_num) order_num30,
sum(order_amount) order_amount30,
sum(payment_count) payment_count30,
sum(payment_num) payment_num30,
sum(payment_amount) payment_amount30,
sum(refund_count) refund_count30,
sum(refund_num) refund_num30,
sum(refund_amount) refund_amount30,
sum(cart_count) cart_count30,
sum(favor_count) favor_count30,
sum(appraise_good_count) appraise_good_count30,
sum(appraise_mid_count) appraise_mid_count30,
sum(appraise_bad_count) appraise_bad_count30,
sum(appraise_default_count) appraise_default_count30
from dws_sku_action_daycount
where dt >= date_add ('2022-03-17', -29)
group by sku_id
)new
on new.sku_id = old.sku_id
left join
(select * from dwd_dim_sku_info where dt='2022-03-17') sku_info
on nvl(new.sku_id,old.sku_id)= sku_info.id;
活动主题汇总表
- 活动主题累积宽表:应该保存有全量维度数据,首次应该初始化。
- 表中一行数据代表一个活动的所有汇总的聚合值。

1)建表语句
drop table if exists dwt_activity_topic;
create external table dwt_activity_topic(
`id` string COMMENT '编号',
`activity_name` string COMMENT '活动名称',
`activity_type` string COMMENT '活动类型',
`start_time` string COMMENT '开始时间',
`end_time` string COMMENT '结束时间',
`create_time` string COMMENT '创建时间',
`display_day_count` bigint COMMENT '当日曝光次数',
`order_day_count` bigint COMMENT '当日下单次数',
`order_day_amount` decimal(20,2) COMMENT '当日下单金额',
`payment_day_count` bigint COMMENT '当日支付次数',
`payment_day_amount` decimal(20,2) COMMENT '当日支付金额',
`display_count` bigint COMMENT '累积曝光次数',
`order_count` bigint COMMENT '累积下单次数',
`order_amount` decimal(20,2) COMMENT '累积下单金额',
`payment_count` bigint COMMENT '累积支付次数',
`payment_amount` decimal(20,2) COMMENT '累积支付金额'
) COMMENT '活动主题宽表'
stored as parquet
location '/warehouse/gmall/dwt/dwt_activity_topic/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
insert overwrite table dwt_activity_topic
select
nvl(new.id,old.id),
nvl(new.activity_name,old.activity_name),
nvl(new.activity_type,old.activity_type),
nvl(new.start_time,old.start_time),
nvl(new.end_time,old.end_time),
nvl(new.create_time,old.create_time),
nvl(new.display_count,0),
nvl(new.order_count,0),
nvl(new.order_amount,0.0),
nvl(new.payment_count,0),
nvl(new.payment_amount,0.0),
nvl(new.display_count,0)+nvl(old.display_count,0),
nvl(new.order_count,0)+nvl(old.order_count,0),
nvl(new.order_amount,0.0)+nvl(old.order_amount,0.0),
nvl(new.payment_count,0)+nvl(old.payment_count,0),
nvl(new.payment_amount,0.0)+nvl(old.payment_amount,0.0)
from
(
select*
from dwt_activity_topic
)old
full outer join
(
select*
from dws_activity_info_daycount
where dt='2022-03-17'
)new
on old.id=new.id;
地区主题宽表
1)建表语句
drop table if exists dwt_area_topic;
create external table dwt_area_topic(
`id` bigint COMMENT '编号',
`province_name` string COMMENT '省份名称',
`area_code` string COMMENT '地区编码',
`iso_code` string COMMENT 'iso 编码',
`region_id` string COMMENT '地区 ID',
`region_name` string COMMENT '地区名称',
`login_day_count` string COMMENT '当天活跃设备数',
`login_last_30d_count` string COMMENT '最近 30 天活跃设备数',
`order_day_count` bigint COMMENT '当天下单次数',
`order_day_amount` decimal(16,2) COMMENT '当天下单金额',
`order_last_30d_count` bigint COMMENT '最近 30 天下单次数',
`order_last_30d_amount` decimal(16,2) COMMENT '最近 30 天下单金额',
`payment_day_count` bigint COMMENT '当天支付次数',
`payment_day_amount` decimal(16,2) COMMENT '当天支付金额',
`payment_last_30d_count` bigint COMMENT '最近 30 天支付次数',
`payment_last_30d_amount` decimal(16,2) COMMENT '最近 30 天支付金额'
) COMMENT '地区主题宽表'
stored as parquet
location '/warehouse/gmall/dwt/dwt_area_topic/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
insert overwrite table dwt_area_topic
select
nvl(old.id,new.id),
nvl(old.province_name,new.province_name),
nvl(old.area_code,new.area_code),
nvl(old.iso_code,new.iso_code),
nvl(old.region_id,new.region_id),
nvl(old.region_name,new.region_name),
nvl(new.login_day_count,0),
nvl(new.login_last_30d_count,0),
nvl(new.order_day_count,0),
nvl(new.order_day_amount,0.0),
nvl(new.order_last_30d_count,0),
nvl(new.order_last_30d_amount,0.0),
nvl(new.payment_day_count,0),
nvl(new.payment_day_amount,0.0),
nvl(new.payment_last_30d_count,0),
nvl(new.payment_last_30d_amount,0.0)
from
(
select*
from dwt_area_topic
)old
full outer join
(
select
id,
province_name,
area_code,
iso_code,
region_id,
region_name,
sum(if(dt='2022-03-17',login_count,0)) login_day_count,
sum(if(dt='2022-03-17',order_count,0)) order_day_count,
sum(if(dt='2022-03-17',order_amount,0.0)) order_day_amount,
sum(if(dt='2022-03-17',payment_count,0)) payment_day_count,
sum(if(dt='2022-03-17',payment_amount,0.0)) payment_day_amount,
sum(login_count) login_last_30d_count,
sum(order_count) order_last_30d_count,
sum(order_amount) order_last_30d_amount,
sum(payment_count) payment_last_30d_count,
sum(payment_amount) payment_last_30d_amount
from dws_area_stats_daycount
where dt>=date_add('2022-03-17',-30)
group by id,province_name,area_code,iso_code,region_id,region_name
)new
on old.id=new.id;
DWT 层数据导入脚本
- 数据导入脚本略
数仓搭建-ADS 层
建表说明
- ads层的表是根据具体的业务需求开发出来的指标,最终结果需要导出到mysql数据库做数据分析
- ads层的表无需压缩,无需列式存储,无需分区,因为数据量很小,一行数据就代表一个统计值。
设备主题
活跃设备数(日、周、月)
- 需求定义:
- 日活:当日活跃的设备数
- 周活:当周活跃的设备数
- 月活:当月活跃的设备数
1)建表语句
drop table if exists ads_uv_count;
create external table ads_uv_count(
`dt` string COMMENT '统计日期',
`day_count` bigint COMMENT '当日用户数量',
`wk_count` bigint COMMENT '当周用户数量',
`mn_count` bigint COMMENT '当月用户数量',
`is_weekend` string COMMENT 'Y,N 是否是周末,用于得到本周最终结果',
`is_monthend` string COMMENT 'Y,N 是否是月末,用于得到本月最终结果'
) COMMENT '活跃设备数'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_uv_count/';
-
ads_uv_count统计的是独立访客数据,即当日用户数量、当周用户数量、当月用户数量,表中一行数据对应一个设备(独立访客)的日活跃、周活、月活的统计数据。
-
计算逻辑:
-
日活:
- 从dwt层的dwt_uv_topic表中查询出最后登录日期为当日的数据,最后登录日期为当日,即为当天设备用户活跃
-
周活:
- 为了后期Azkaban调度方便,计算频率按照每日计算数据,进行任务调度;因此将周活按照时间区间计算。例如当日为本周三,则计算从周一到本周日的数据,后边没有的数据不参与计算。如当日为周末,则使用next_day()函数获取下周一日期,在此基础上减去7天;即可活得本周一的时间日期;然后计算这个时间区间的数据。
- 使用sum()和if()函数嵌套,判断时间周期login_date_last是否大于等于周一,小于等于周日。如:sum( if( login_date_last>=date_add( next_day(‘2022-03-17’, ’ monday '), -7 ) and login_date_last<=date_add( next_day(‘2022-03-17’, ’ monday '), -1 ), 1 ,0 ))
-
月活:
- 思路是使用date_format(login_date_last, 'yyyy-MM ’ ),把日期转换成年月,然后使用 if() 函数做判断,是当月的就加1,否则加0.
-
ads_uv_count,每天新增数据采用insert into 插入表中,会导致出现很多小文件存储在HDFS上,这样对于HDFS很不利;因此采用先查询出历史数据;然后再union当天的新增数据;最后将合并的数据覆写到表中。这样就避免的小文件的产生。注意: union all不去重,union去重
-
2)导入数据
insert overwrite table ads_uv_count
select * from ads_uv_count
union
select
'2022-03-17',
sum(if(login_date_last='2022-03-17',1,0)),
sum(if(login_date_last>=date_add(next_day('2022-03-17','monday'),-7) and login_date_last<=date_add(next_day('2022-03-17','monday'),-1),1,0)),
sum(if(date_format(login_date_last,'yyyy-MM')=date_format('2022-03-17','yyyy-MM'),1,0)),
if('2022-03-17'=date_add(next_day('2022-03-17','monday'),-1),'Y','N'),
if('2022-03-17'=last_day('2022-03-17'),'Y','N')
from dwt_uv_topic
每日新增设备
- ads_new_mid_count表中一条数据代表一天的新增设备,每行对应一天的新增设备统计值;最终是以折线图的形式展现的。
- 如果没有dws层和dwt层的设备主题宽表,那么该怎么求新增设备数量
- 1)可以从dwd层的start_log全查出来,按照设备id分组,求最小登录日期,最小登录日期为当天日期就是新增的用户。
- 2)按照当天的时间分区查出ods_start_log的当天数据作为子查询,然后再查询出除了当天之外的所有分区的登录数据;然后两个子查询的数据集进行right join比对,历史数据的设备id为null的即为当天新增的设备,然后count()汇总。
- 有图可知若没有dws和dwt层的宽表,计算量会非常大。
1)建表语句
drop table if exists ads_new_mid_count;
create external table ads_new_mid_count(
`create_date` string comment '创建时间' ,
`new_mid_count` BIGINT comment '新增设备数量'
) COMMENT '每日新增设备数量'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_new_mid_count/';
2)导入数据
insert overwrite table ads_new_mid_count
select * from ads_new_mid_count
union
select
'2022-03-17',
count(*)
from dwt_uv_topic
where login_date_first='2022-03-17';
---------或者在查询字段哪里使用sum(if(login_date_first='2022-03-17',1,0))这样也可以,后边就不用where过滤了,但是效率并不高。
沉默用户数
- 需求定义:
- 沉默用户:只在安装当天启动过,且启动时间是在 7 天前
- 首先只在当天启动过,最小启动时间就是最后启动时间;且在当天时间之前的7天前。从dwt层的设备主题宽表,dwt_uv_topic表中查询出累积登录次数为1,也就是自从安装只使用了一次。
1)建表语句
drop table if exists ads_silent_count;
create external table ads_silent_count(
`dt` string COMMENT '统计日期',
`silent_count` bigint COMMENT '沉默设备数'
) COMMENT '沉默用户数'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_silent_count';
2)导入 2022-03-17 数据
insert overwrite table ads_silent_count
select* from ads_silent_count
union
select
'2022-03-17',
count(*)
from dwt_uv_topic
where login_date_first=login_date_last
and login_date_last<=date_add('2022-03-17',-7);
流失用户数
- 需求定义:
- 流失用户:最近 7 天未活跃的设备,即认定该用户流失。
- 最后一次活跃时间是7天前
1)建表语句
drop table if exists ads_wastage_count;
create external table ads_wastage_count(
`dt` string COMMENT '统计日期',
`wastage_count` bigint COMMENT '流失设备数'
) COMMENT '流失用户数'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_wastage_count';
2)导入 2022-03-17 数据
insert overwirte table ads_wastage_count
select * from ads_wastage_count
union
select
'2022-03-17',
count(*)
from(
select
mid_id
from dwt_uv_topic
where login_date_last<=date_add('2022-03-17',-7)
group by mid_id
)t1;
&重要–留存率
- 留存用户:某段时间内的新增用户(活跃用户),经过一段时间后,又继续使用应用的被认作是留存用户;
- 留存率:留存用户占当时新增用户(活跃用户)的比例即是留存率。
- 例如,6月14日新增用户100,这100人在6月15日启动过应用的有30人,6月16日启动过应用的有25人,6月17日启动过应用的有32人;则6月14日新增用户次日的留存率是30/100 = 30%,两日留存率是25/100=25%,三日留存率是32/100=32%。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nNOAmfvX-1648101873840)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220322160312014.png)]](http://img.e-com-net.com/image/info8/d1b1488aaf1d4eba9e44a30d393587ce.jpg)
- ads_user_retention_day_rate表结构,看出表中一行数据代表一个留存记录。
1)建表语句
drop table if exists ads_user_retention_day_rate;
create external table ads_user_retention_day_rate(
`stat_date` string comment '统计日期',
`create_date` string comment '设备新增日期',
`retention_day` int comment '截止当前日期留存天数',
`retention_count` bigint comment '留存数量',
`new_mid_count` bigint comment '设备新增数量',
`retention_ratio` decimal(16,2) comment '留存率'
) COMMENT '留存率'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_user_retention_day_rate/';
2)导入数据
- 计算每一天的1日、2日、3日留存率。
- 在求1日留存率、2日留存率和3日留存率时应该明确,一天的计算任务是什么?例如:求2022-03-17的1日留存率
- 首先得求出2022-03-17的新增用户即新增设备数
- 次日2022-03-18的活跃设备数,且次日活跃的设备数中昨日新增的设备数量
- 用2022-03-18日活跃设备中包含昨日新增设备的数量/ 前一日新增的设备数量
- 2022-03-18日的活跃设备数据,2022-03-19日才能获取
例子:
-
求2022-03-17的1日留存率 需获取2022-03-17的新增设备数 需要获取2022-03-18的活跃设备数 ----> 2022-03-19日拿到18日的活跃设备数 ----------------------------- 求2022-03-17的2日留存率 需获取2022-03-17的新增设备数 需要获取2022-03-19的活跃设备数 ----> 2022-03-20日拿到19日的活跃设备数 ----------------------------- 求2022-03-17的3日留存率 需获取2022-03-17的新增设备数 需要获取2022-03-20的活跃设备数 ----> 2022-03-21日拿到20日的活跃设备数 -
同一天的1日、2日、3日留存率并不是当天计算出来的。那么同一天的计算任务到底是什么?
- 例如2022-03-21日的计算任务是:
- 2022-03-17日的3日留存率
- 2022-03-18日的2日留存率
- 2022-03-19日的1日留存率
- 例如2022-03-21日的计算任务是:
-
以2022-03-21日的计算任务为例求3日留存率SQL如下:
-
--2022-03-21 的计算任务 --求2022-03-17日的3日留存率 --1) 首先,要先求出当天的新增设备数 select count(*) from dwt_uv_topic where login_date_first='2022-03-17'; --2) 再查出当天的三日留存设备数: 即在17号新增首次登录,且在20日最后一次出现登录 select count(*) from dwt_uv_topic where login_date_first='2022-03-17' and login_date_last='2022-03-20' ---将1)和2)的子查询join,然后用2)除以1)求出留存率了 -
上面的SQL可以进一步优化,因为数据集都来自于同一张表dwt_uv_topic,因此可以使用sum( if( ) )嵌套函数进行优化。
-
select '2022-03-21', --统计日期 '2022-03-17', --设备新增日期 3, --留存天数 sum(if(login_date_first='2022-03-17' and login_date_last='2022-03-20',1,0)), --留存数量 sum(if(login_date_first='2022-03-17',1,0)), --新增设备数 sum(if(login_date_first='2022-03-17' and login_date_last='2022-03-20',1,0))/sum(if(login_date_first='2022-03-17',1,0))*100, --留存/新增 -->留存率 from dwt_uv_topic -
观察SQL可以知道,留存设备数是在新增的基础上进行查询的,因此都有login_date_first=‘2022-03-17’ 的过滤条件,因此可以先过滤出新增的用户,然后再次基础上在判断最后一次登录时间出现在20日的设备数;也就是留存设备数中包含了新增设备。优化SQl
-
select '2022-03-20', --统计日期(t-1) '2022-03-17', --设备新增日期 3, --留存天数 sum(if(login_date_last='2022-03-20',1,0)), --留存数量 count(*), --新增设备数 sum(if(login_date_last='2022-03-20',1,0))/count(*)*100, --留存/新增 -->留存率 from dwt_uv_topic where login_date_first='2022-03-17'
-
-
2022-03-18日的2日留存率
-
select '2022-03-20', --统计日期(t-1) '2022-03-18', --设备新增日期 2, --留存天数 sum(if(login_date_last='2022-03-20',1,0)), --留存数量 count(*), --新增设备数 sum(if(login_date_last='2022-03-20',1,0))/count(*)*100, --留存/新增 -->留存率 from dwt_uv_topic where login_date_first='2022-03-18'
-
-
2022-03-19日的1日留存率
-
select '2022-03-20', --统计日期(t-1) '2022-03-19', --设备新增日期 1, --留存天数 sum(if(login_date_last='2022-03-20',1,0)), --留存数量 count(*), --新增设备数 sum(if(login_date_last='2022-03-20',1,0))/count(*)*100, --留存/新增 -->留存率 from dwt_uv_topic where login_date_first='2022-03-19'
-
-
最终将这个三个数据集union all合并到一起插入留存率表中
最终数据加载SQL
insert into table ads_user_retention_day_rate
select
'2022-03-20', --统计日期(t-1)
'2022-03-19', --设备新增日期
1, --留存天数
sum(if(login_date_last='2022-03-20',1,0)), --留存数量
count(*), --新增设备数
sum(if(login_date_last='2022-03-20',1,0))/count(*)*100 --留存/新增 -->留存率
from dwt_uv_topic where login_date_first='2022-03-19'
union all
select
'2022-03-20', --统计日期(t-1)
'2022-03-18', --设备新增日期
2, --留存天数
sum(if(login_date_last='2022-03-20',1,0)), --留存数量
count(*), --新增设备数
sum(if(login_date_last='2022-03-20',1,0))/count(*)*100 --留存/新增 -->留存率
from dwt_uv_topic where login_date_first='2022-03-18'
union all
select
'2022-03-20', --统计日期(t-1)
'2022-03-17', --设备新增日期
3, --留存天数
sum(if(login_date_last='2022-03-20',1,0)), --留存数量
count(*), --新增设备数
sum(if(login_date_last='2022-03-20',1,0))/count(*)*100 --留存/新增 -->留存率
from dwt_uv_topic where login_date_first='2022-03-17'

-
继续优化上面的SQL得:
-
select '2022-03-20', login_date_first, datediff('2022-03-20',login_date_first), sum(if(login_date_last='2022-03-20',1,0)), --留存数量 count(*), --新增设备数 sum(if(login_date_last='2022-03-20',1,0))/count(*)*100 --留存/新增 -->留存率 from dwt_uv_topic where login_date_first in('2022-03-17','2022-03-18','2022-03-19') group by login_date_first
-
&本周回流用户数
- 需求定义:
- 本周回流用户:上周未活跃,本周活跃的设备,且不是本周新增设备
- 以周为频率计算,为了调度任务的方便,改成按天计算
1)建表语句
drop table if exists ads_back_count;
create external table ads_back_count(
`dt` string COMMENT '统计日期',
`wk_dt` string COMMENT '统计日期所在周',
`wastage_count` bigint COMMENT '回流设备数'
) COMMENT '本周回流用户数'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_back_count'
2)导入2020-03-17数据
insert into table ads_back_count
select
'2022-03-17',
concat(date_add(next_day('2022-03-17','MO'),-7),'_',
date_add(next_day('2022-03-17','MO'),-1)),
count(*)
from
(
select
mid_id
from dwt_uv_topic
where login_date_last>=date_add(next_day('2022-03-17','MO'),-7)
and login_date_last<= date_add(next_day('2022-03-17','MO'),-1)
and login_date_first<date_add(next_day('2022-03-17','MO'),-7)
)current_wk
left join
(
select
mid_id
from dws_uv_detail_daycount
where dt>=date_add(next_day('2022-03-17','MO'),-7*2) and
dt<= date_add(next_day('2022-03-17','MO'),-7-1)
group by mid_id
)last_wk
on current_wk.mid_id=last_wk.mid_id
where last_wk.mid_id is null;
最近连续三周活跃用户数
- 计算最近三周都活跃的用户设备
1)建表语句
drop table if exists ads_continuity_wk_count;
create external table ads_continuity_wk_count(
`dt` string COMMENT '统计日期,一般用结束周周日日期,如果每天计算一次,可用当天日期',
`wk_dt` string COMMENT '持续时间',
`continuity_count` bigint COMMENT '活跃用户数'
) COMMENT '最近连续三周活跃用户数'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_continuity_wk_count';
2)导入2022-03-17 所在周的数据
insert into table ads_continuity_wk_count
select
'2022-03-17',
concat(date_add(next_day('2022-03-17','MO'),-7*3),'_',date_add(next_day('2022-03-17','MO'),-1)),
count(*)
from
(
select
mid_id
from
(
select
mid_id
from dws_uv_detail_daycount
where dt>=date_add(next_day('2022-03-17','monday'),-7)
and dt<=date_add(next_day('2022-03-17','monday'),-1)
group by mid_id
union all
select
mid_id
from dws_uv_detail_daycount
where dt>=date_add(next_day('2022-03-17','monday'),-7*2)
and dt<=date_add(next_day('2022-03-17','monday'),-7-1)
group by mid_id
union all
select
mid_id
from dws_uv_detail_daycount
where dt>=date_add(next_day('2022-03-17','monday'),-7*3)
and dt<=date_add(next_day('2022-03-17','monday'),-7*2-1)
group by mid_id
)t1
group by mid_id
having count(*)=3
)t2;
&-最近七天内连续三天活跃用户数
- 最近七天中,有连续3天活跃的用户设备数量进行统计,还要考虑去重
1)建表语句
drop table if exists ads_continuity_uv_count;
create external table ads_continuity_uv_count(
`dt` string COMMENT '统计日期',
`wk_dt` string COMMENT '最近 7 天日期',
`continuity_count` bigint
) COMMENT '最近七天内连续三天活跃用户数'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_continuity_uv_count';
-
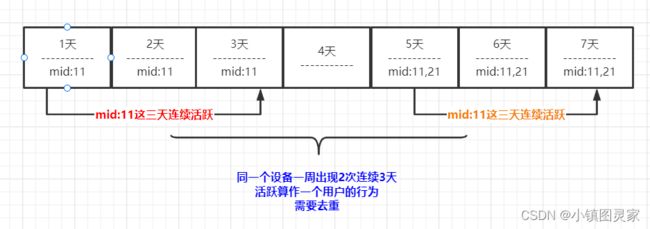
-
举个例子:例如我们需要求出用户张三近七天是否存在连续3天登录的事件;则可以先查询出张三近7天所有登录日期,但是有可能同一天,张三登录了多次;因此需要对日期进行去重;然后再对登录日期进行一个升序排序。如果后一天比前一天日期相差为1,就可以判断这个两个日期连续。那么该如何用下一行的日期减去上一行的日期呢?
- 查询张三近7天所有登录时间,然后去重
- 查询张三近7天所有登录时间,然后去重
-
分析近7天内连续三天活跃用户数,这个需求。
-
思路1:
-
查询出所有人最近7天的登录记录,然后再判断这些记录中是否存在连续三天登录的用户。
-
对所有登录日期去重,然后排序,在使用lead() 函数,求出第一天和第三天之间的差值,这里日期差值使用datediff( )函数。最后再将差值为2的查询出来,然后去重,在求出个数。
-
select count(*) from ( select mid_id from ( select mid_id, datediff(lead2,dt) diff from ( select mid_id,dt, lead(dt,2,'170-01-01') over(partition by mid_id order by dt) lead2 from dws_uv_detail_daycount where dt>=date_add('2022-03-17',-6) and dt<='2022-03-17' and login_count>0 )t1 )t2 where diff=2 group by mid_id )t3 -
思路2:
-
示例数据 :

-
按照mid_id和dt-rank分组,求出相同日期的统计数量,count(*) 为3即存在连续三天登录的日期
-
select count(*) from ( select mid_id from ( select mid_id from ( select mid_id, date_add(dt,-rk) diff from ( select mid_id,dt, rank() over(partition by mid_id order by dt) rk from dws_uv_detail_daycount where dt>=date_add('2022-03-17',-6) and dt<='2022-03-17' and login_count>0 )t1 )t2 group by mid_id,diff having count(*)>=3 )t3 group by mid_id )t4
-

2)最终导入数据的 SQL 语句
insert into table ads_continuity_uv_count
select
'2022-03-17',
concat(date_add('2022-03-17',-6),'_','2022-03-17'),
count(*)
from
(
select mid_id
from
(
select mid_id
from
(
select
mid_id,
date_sub(dt,rank) date_dif
from
(
select
mid_id,
dt,
rank() over(partition by mid_id order by dt) rank
from dws_uv_detail_daycount
where dt>=date_add('2022-03-17',-6) and dt<='2022-03-17'
)t1
)t2
group by mid_id,date_dif
having count(*)>=3
)t3
group by mid_id
)t4;
会员主题
会员信息
- 用户新鲜度:
- 每天启动应用的新老用户比例,即新增用户数占活跃用户数的比例。
1)建表—会员信息表
drop table if exists ads_user_topic;
create external table ads_user_topic(
`dt` string COMMENT '统计日期',
`day_users` string COMMENT '活跃会员数',
`day_new_users` string COMMENT '新增会员数',
`day_new_payment_users` string COMMENT '新增消费会员数',
`payment_users` string COMMENT '总付费会员数',
`users` string COMMENT '总会员数',
`day_users2users` decimal(16,2) COMMENT '会员活跃率',
`payment_users2users` decimal(16,2) COMMENT '会员付费率',
`day_new_users2users` decimal(16,2) COMMENT '会员新鲜度'
) COMMENT '会员信息表'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_user_topic';
2)导入数据
insert into table ads_user_topic
select
'2022-03-17',
sum(if(login_date_last='2022-03-17',1,0)), --当日活跃会员数
sum(if(login_date_first='2022-03-17',1,0)), --新增用户数
sum(if(payment_date_first='2022-03-17',1,0)),--新增支付会员数
sum(if(payment_count>0,1,0)), --总支付会员数
count(*), --会员总数
sum(if(login_date_last='2022-03-17',1,0))/count(*), --会员活跃率
sum(if(payment_count>0,1,0))/count(*), --会员付费率
sum(if(login_date_first='2022-03-17',1,0))/sum(if(login_date_last='2022-03-17',1,0)) --会员新鲜度
from dwt_user_topic;
&重要–漏斗分析
- 统计“ 浏览首页->浏览商品详情页->加入购物车->下单->支付 ”的转化率
- 思路:统计各个行为的人数,然后计算比值。
1)建表语句
drop table if exists ads_user_action_convert_day;
create external table ads_user_action_convert_day(
`dt` string COMMENT '统计日期',
`home_count` bigint COMMENT '浏览首页人数',
`good_detail_count` bigint COMMENT '浏览商品详情页人数',
`home2good_detail_convert_ratio` decimal(16,2) COMMENT '首页到商品详情转化率',
`cart_count` bigint COMMENT '加入购物车的人数',
`good_detail2cart_convert_ratio` decimal(16,2) COMMENT '商品详情页到加入购物车转化率',
`order_count` bigint COMMENT '下单人数',
`cart2order_convert_ratio` decimal(16,2) COMMENT '加入购物车到下单转化率',
`payment_count` bigint COMMENT '支付人数',
`order2payment_convert_ratio` decimal(16,2) COMMENT '下单到支付的转化率'
) COMMENT '漏斗分析'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_user_action_convert_day/';
-
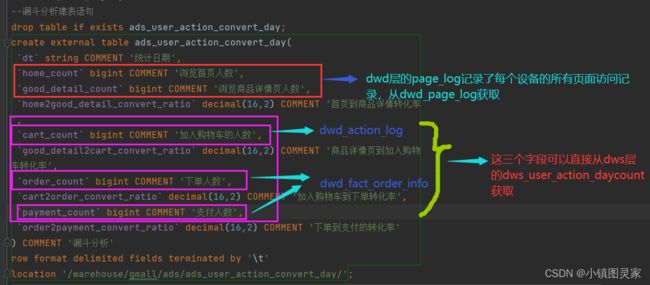
-
home_count与good_detail_count字段
-
select sum(if(page_id='home',1,0)) home_count, sum(if(page_id='good_detail',1,0)) good_detail_count from ( --子查询拿到了对应设备的首页访问记录和商品详情访问记录 select mid_id, page_id from dwd_page_log where dt='2022-03-17' and page_id in('home','good_detail') group by mid_id,page_id ) t1 -
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8wja8JT6-1648101873848)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220323103448690.png)]](http://img.e-com-net.com/image/info8/1ebc56479478414b83a6fa93df90a291.jpg)
-
-
cart_count与order_count与payment_count字段
-
select sum(if(cart_count>0,1,0)) cart_count, sum(if(order_count>0,1,0)) order_count, sum(if(payment_count>0,1,0)) payment_count from dws_user_action_daycount where dt='2022-03-17' -
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TjbpR4pO-1648101873849)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220323104244841.png)]](http://img.e-com-net.com/image/info8/397545f89b944ead84db8d278d4972c2.jpg)
-
两个子查询结果集进行join:
-
select t_uv.dt, home_count, good_detail_count, cart_count, order_count, payment_count from ( select '2022-03-17' dt, sum(if(page_id = 'home', 1, 0)) home_count, sum(if(page_id = 'good_detail', 1, 0)) good_detail_count from ( --子查询拿到了对应设备的首页访问记录和商品详情访问记录 select '2022-03-17' dt, mid_id, page_id from dwd_page_log where dt = '2022-03-17' and page_id in ('home', 'good_detail') group by mid_id, page_id ) tmp_uv ) t_uv join ( select '2022-03-17' dt, sum(if(cart_count > 0, 1, 0)) cart_count, sum(if(order_count > 0, 1, 0)) order_count, sum(if(payment_count > 0, 1, 0)) payment_count from dws_user_action_daycount where dt = '2022-03-17' ) tmp_cop on t_uv.dt = tmp_cop.dt -
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hpuUtUZl-1648101873851)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220323113143816.png)]](http://img.e-com-net.com/image/info8/83771ef741994d16af41736620958cc9.jpg)
-
首页到商品详情转化率、商品详情页到加入购物车转化率、加入购物车到下单转化率、下单到支付的转化率;这四个转换率通过对应字段的计算得到:
-
首页到商品详情转化率—>商品详情页访问人数占主页访问人数的占比
- 商品详情访问人数/首页访问人数 *100
-
商品详情页到加入购物车转化率—> 加入购物车人数占商品详情页访问人数的占比
- 加入购物车人数/浏览商品详情人数*100
-
加入购物车到下单转化率—> 下单人数占加入购物车人数的占比
- 下单人数/加入购物车人数*100
-
下单到支付的转化率—>支付人数占下单人数的占比
- 支付人数/下单人数*100
-
获取每个设备首页访问记录和商品详情访问记录的方法2:
-
home_count与good_detail_count字段
-
从dws层的dws_uv_detail_daycount这张表中获取—>这个表中有mid_id、page_stats字段,page_stats字段是个 “结构体” 数组里面封装了对应设备的所有页面访问记录
-
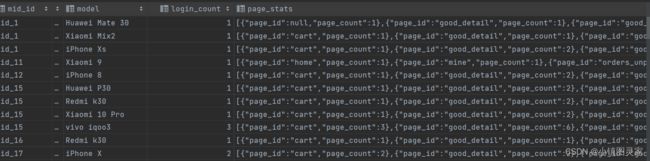
-
使用explode( col )函数对这个页面状态字段炸开,然后配合侧视图构成多行虚表;在从对应的结构体中取出page_id字段即可处理
-
select '2022-03-17' dt, sum(if(page_id='home',1,0)) home_count, sum(if(page_id='good_detail',1,0)) good_detail_count from ( select mid_id, page_struct.page_id page_id from dws_uv_detail_daycount leteral view explode(page_stats) tmp as page_struct where dt='2022-03-17' )t1
-
2)最终数据装载
with
tmp_uv as
(
select
'2022-03-17' dt,
sum(if(array_contains(pages,'home'),1,0)) home_count,
sum(if(array_contains(pages,'good_detail'),1,0)) good_detail_count
from
(
select
mid_id,
collect_set(page_id) pages
from dwd_page_log
where dt='2022-03-17'
and page_id in ('home','good_detail')
group by mid_id
)tmp
),
tmp_cop as
(
select
'2022-03-17' dt,
sum(if(cart_count>0,1,0)) cart_count,
sum(if(order_count>0,1,0)) order_count,
sum(if(payment_count>0,1,0)) payment_count
from dws_user_action_daycount
where dt='2022-03-17'
)
insert into table ads_user_action_convert_day
select
tmp_uv.dt,
tmp_uv.home_count,
tmp_uv.good_detail_count,
tmp_uv.good_detail_count/tmp_uv.home_count*100,
tmp_cop.cart_count,
tmp_cop.cart_count/tmp_uv.good_detail_count*100,
tmp_cop.order_count,
tmp_cop.order_count/tmp_cop.cart_count*100,
tmp_cop.payment_count,
tmp_cop.payment_count/tmp_cop.order_count*100
from tmp_uv
join tmp_cop on tmp_uv.dt=tmp_cop.dt;
商品主题
商品个数信息
1)建表语句
drop table if exists ads_product_info;
create external table ads_product_info(
`dt` string COMMENT '统计日期',
`sku_num` string COMMENT 'sku 个数',
`spu_num` string COMMENT 'spu 个数'
) COMMENT '商品个数信息'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_product_info';
2)数据导入
insert into table ads_product_info
select
'2022-03-17' dt,
sku_num,
spu_num
from
(
select
'2022-03-17' dt,
count(*) sku_num
from
dwt_sku_topic
) tmp_sku_num
join
(
select
'2022-03-17' dt,
count(*) spu_num
from
(
select
spu_id
from
dwt_sku_topic
group by
spu_id
) tmp_spu_id
) tmp_spu_num
on tmp_sku_num.dt=tmp_spu_num.dt;
商品销量排名
-
topN这里统计前面10,所有商品按照sku统计,统计当天的数据。
-
销量按商品支付金额去统计
-
payment_amount销量这个字段来自于那个表?
-
在前面dws层我们已经按天统计了每日商品行为的宽表,因此可以直接从dws_sku_action_daycount表中获取需要的字段
-
dws_sku_action_daycount表结构:
-
select '2022-03-17' dt, sku_id, payment_amount from dws_sku_action_daycount where dt='2022-03-17' order by payment_amount desc limit 10;
-

1)建表语句
drop table if exists ads_product_sale_topN;
create external table ads_product_sale_topN(
`dt` string COMMENT '统计日期',
`sku_id` string COMMENT '商品 ID',
`payment_amount` bigint COMMENT '销量'
) COMMENT '商品销量排名'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_product_sale_topN';
2)数据导入
insert into table ads_product_sale_topN
select
'2022-03-17' dt,
sku_id,
payment_amount
from
dws_sku_action_daycount
where
dt='2022-03-17'
order by payment_amount desc
limit 10;
商品品牌分组topN需求
- 需求:每个品牌下的销量排行前十的sku
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-70emXIJb-1648101873858)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220323160258588.png)]](http://img.e-com-net.com/image/info8/ac8acaaad1c046c3825028c47aad3aac.png)
1)建表语句
drop table if exists ads_product_tm_sale_topN;
create external table ads_product_tm_sale_topN(
`dt` string COMMENT '统计日期',
`sku_id` string COMMENT '商品 ID',
tm_id string comment '品牌id',
`payment_amount` bigint COMMENT '销量'
) COMMENT '商品品牌销量排名'
2)数据导入
insert into table ads_product_tm_sale_topN
select
'2022-03-17' dt,
tm_id,
sku_id,
payment_amount,
rk
from
( --这里面的子查询是商品按品牌排名的数据集
select
tm_id,
sku_id,
payment_amount,
rank() over(partition by tm_id order by payment_amount desc) rk
from
(
--子查询,每个商品的销量信息
select
sku_id,
payment_amount
from dws_sku_action_daycount
where dt='2022-03-17'
)sku_pay
left join
(
--商品维度表中获取每个商品的品牌信息
select
id,
tm_id
from dwd_dim_sku_info
where dt='2022-03-17'
) sku_info
on sku_pay.sku_id=sku_info.id
)t_rk
where rk<=10
商品收藏排名
1)建表语句
drop table if exists ads_product_favor_topN;
create external table ads_product_favor_topN(
`dt` string COMMENT '统计日期',
`sku_id` string COMMENT '商品 ID',
`favor_count` bigint COMMENT '收藏量'
) COMMENT '商品收藏排名'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/
2)数据导入
- 数据可以直接从dws层的dws_sku_action_daycount当中获取
insert into table ads_product_favor_topN
select
'2022-03-17' dt,
sku_id,
favor_count
from
dws_sku_action_daycount
where
dt='2022-03-17'
order by favor_count desc
limit 10;
商品加入购物车排名
1)建表语句
drop table if exists ads_product_cart_topN;
create external table ads_product_cart_topN(
`dt` string COMMENT '统计日期',
`sku_id` string COMMENT '商品 ID',
`cart_count` bigint COMMENT '加入购物车次数'
) COMMENT '商品加入购物车排名'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_product_cart_topN';
2)数据导入
insert into table ads_product_cart_topN
select
'2022-03-17' dt,
sku_id,
cart_count
from
dws_sku_action_daycount
where
dt='2022-03-17'
order by cart_count desc
limit 10;
商品退款率排名(最近 30 天)
-
按照最近30天统计,退款率计算公式:退款次数/支付次数
- 退款率,求出每件商品的退款率,然后再排序,最终得到商品退款率的topN
-
数据直接从dwt_sku_topic表中获取refund_last_30d_count/payment_last_30d_count*100
1)建表语句
drop table if exists ads_product_refund_topN;
create external table ads_product_refund_topN(
`dt` string COMMENT '统计日期',
sku_id` string COMMENT '商品 ID',
`refund_ratio` decimal(16,2) COMMENT '退款率'
) COMMENT '商品退款率排名'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_product_refund_topN';
2)数据导入
insert into table ads_product_refund_topN
select
'2022-03-17',
sku_id,
refund_last_30d_count/payment_last_30d_count*100 refund_ratio
from dwt_sku_topic
order by refund_ratio desc
limit 10
商品差评率
- 差评率:差评数/总得评价数
- 先求出每件商品的差评率,再进行排序;然后求出前10 topN
- 数据从dws_sku_action_daycount表中获取
1)建表语句
drop table if exists ads_appraise_bad_topN;
create external table ads_appraise_bad_topN(
`dt` string COMMENT '统计日期',
`sku_id` string COMMENT '商品 ID',
`appraise_bad_ratio` decimal(16,2) COMMENT '差评率'
) COMMENT '商品差评率'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_appraise_bad_topN';
2)数据导入
insert into table ads_appraise_bad_topN
select
'2022-03-17' dt,
sku_id,
appraise_bad_count/(appraise_good_count+appraise_mid_count+appraise_bad_coun
t+appraise_default_count) appraise_bad_ratio
from
dws_sku_action_daycount
where
dt='2022-03-17'
order by appraise_bad_ratio desc
limit 10;
&营销主题(用户+商品+购买行为)
下单数目统计
需求分析:统计每日下单数,下单金额及下单用户数。
- 可以从dwd层的订单事实表拿到下单笔数、下单金额等字段;也可从dws层的用户主题表dws_user_action_daycount,一行数据表示一个用户的各种行为;只需要汇总每个用户每天的下单笔数和下单金额,下单用户数量统计出来即可。
1)建表语句
drop table if exists ads_order_daycount;
create external table ads_order_daycount(
dt string comment '统计日期',
order_count bigint comment '单日下单笔数',
order_amount bigint comment '单日下单金额',
order_users bigint comment '单日下单用户数'
) comment '下单数目统计'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_order_daycount';
2)数据导入
insert into table ads_order_daycount
select
'2022-03-17',
sum(order_count),
sum(order_amount),
sum(if(order_count>0,1,0))
from dws_user_action_daycount
where dt='2022-03-17';
支付信息统计
- 每日支付金额、支付人数、支付商品数、支付笔数以及下单到支付的平均时长(取自 DWD)
1)建表语句
drop table if exists ads_payment_daycount;
create external table ads_payment_daycount(
dt string comment '统计日期',
order_count bigint comment '单日支付笔数',
order_amount bigint comment '单日支付金额',
payment_user_count bigint comment '单日支付人数',
payment_sku_count bigint comment '单日支付商品数',
payment_avg_time decimal(16,2) comment '下单到支付的平均时长,取分钟数'
) comment '支付信息统计'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_payment_daycount';
-
order_count、order_amount、payment_user_count这三个字段,可以从每日会员行为dws_user_action_daycount表中获取
-
select '2022-03-17', sum(payment_count), sum(payment_amount), sum(if(payment_count>0,1,0)) from dws_user_action_daycount where dt='2022-03-17';
-
-
单日支付商品数payment_sku_count这个字段,是指多少个商品的sku被支付了。从dws_sku_action_daycount表中可以直接求出支付次数大于0的数量
-
dws_sku_action_daycount表结构:

-
select '2022-03-17', count(*) from dws_sku_action_daycount where dt='2022-03-17' and payment_count>0;
-
-
payment_avg_time下单到支付的平均时长这个字段如何获取?
-
需要获取当天的每一个订单的支付时间和下单时间,从那个表中获取?–>订单的明细数据—>dwd_fact_order_info表
-
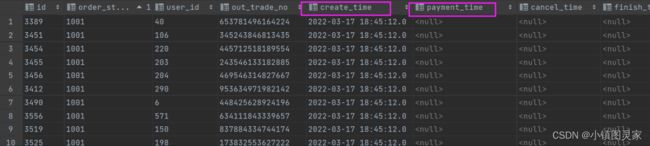
-
思路是从dwd_fact_order_info表中获取下单时间和支付时间,然后支付时间-下单时间;时间如何相减。
- 先将时间转换成时间戳(以秒单位),然后两个时间戳再相减,最后差值换算成分钟。
- avg(unix_timestamp(payment_time) - unix_timestamp(create_time)) /60 —>得到差值分钟数
-
select avg(unix_timestamp(payment_time)-unix_timestamp(create_time))/60 from dwd_fact_order_info where dt='2022-03-17' and payment_time is not null -
最后将这几个字段的数据集join到一起就ok了!
-
2)数据导入
insert into table ads_payment_daycount
select
tmp_payment.dt,
tmp_payment.payment_count,
tmp_payment.payment_amount,
tmp_payment.payment_user_count,
tmp_skucount.payment_sku_count,
tmp_time.payment_avg_time
from(
select
'2022-03-17' dt,
sum(payment_count) payment_count,
sum(payment_amount) payment_amount,
sum(if(payment_count>0,1,0)) payment_user_count
from dws_user_action_daycount
where dt='2022-03-17'
)tmp_payment
join
(
select
'2022-03-17' dt,
sum(if(payment_count>0,1,0)) payment_sku_count
from dws_sku_action_daycount
where dt='2022-03-17'
)tmp_skucount on tmp_payment.dt=tmp_skucount.dt
join
(
select
'2022-03-17' dt,
sum(unix_timestamp(payment_time)-unix_timestamp(create_time))/count(*)/60 payment_avg_time
from dwd_fact_order_info
where dt='2022-03-17'
and payment_time is not null
)tmp_time on tmp_payment.dt=tmp_time.dt;
品牌复购率
复购率:统计一段时间内(这里按一整月统计),某品牌产品的再次购买的频率,占首次购买品牌产品的人数占比。
-
计算复购率有2种方法。
-
1.重复购买客户数量/客户样本数量。
- 举例:客户样本100人,其中50人重复购买(不用考虑重复购买了几次),复购率=50/100,即:50%。
-
2.客户购买行为次数(或交易次数)/客户样本数量。
- 举例:客户样本100人,其中20人重复购买,这20人中有5人重复购买1次(即:购买2次),有15人重复购买3次(即:购买3次),复购率=(51+152)/100,结果为35%。
在进行复购率计算时,一定要确认好我们的统计周期,以便于我们对不同周期的数据进行对比来判断购买趋势。
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HWAuW31R-1648101873863)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220323163022514.png)]](http://img.e-com-net.com/image/info8/0699eb242ced4ca28c01ca1a2fcee110.jpg)
-
我们需要先求出每个人购买每个品牌的次数。先拿到每个人购买每个品牌的订单记录,我们可以通过dwd层的order_detail,先拿到那个用户购买了那个商品sku,然后再关联商品维度表拿到sku对应的品牌。这样即可获得那个人购买了那个品牌的商品信息。
-
例如:求每个人购买每个品牌商品的次数
-
每个人购买小米品牌的次数,张三购买2次,李四购买3次,王五购买6次;张三购买小米品牌2次,即2次复购1次。
-
dwd层的order_detail体现了用户与商品之间的联系,然后join商品维表,即可得到用户与品牌的数据。SQL如下:
-
--从dwd层->订单详情事实表 dwd_fact_order_detail中获取下单的用户和对应的商品sku信息 select user_id, sku_id, tm_id, tm_name, --这个字段是为了虚表看起来更清楚加上的,可以不写 category1_id, category1_name, count(*) order_count from ( select user_id, sku_id from dwd_fact_order_detail where date_format(dt,'yyyy-MM')=date_format('2022-03-17','yyyy-MM') )od left join ---从商品维表->dwd_dim_sku_info中查询出商品id对应的品牌id,以及1级品类id,1级品类名称等信息 ( select id, tm_id, tm_name,--这个字段可以省略不写 category1_id, category1_name from dwd_dim_sku_info where dt='2022-03-17' )sku_inf on od.sku_id=sku_inf.id group by user_id, sku_id, tm_id,tm_name, category1_id, category1_name -
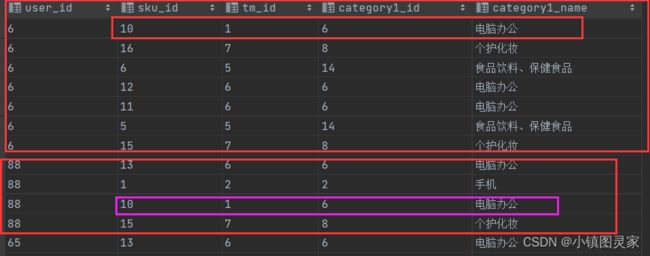
-
按照用户id、sku_id、品牌id、品牌名称、1级品类id、1级品类名称字段分组后,就拿到了每个用户购买每个商品品牌的品类和次数。
-

-
表中一行数据就代表一个用户购买某个商品品牌的次数。但是复购率,我们最终是要计算某个品牌商品购买1次的人数,复购2次的人数…。因此在上面虚表数据集的基础上按照品牌id、1级品类id、1级品类名称分组;然后最终按组统计复购1次的人数…
-
select tm_id, tm_name, --可以省略 category1_id, category1_name, sum(if(order_count>1,1,0)) repurchase_1, sum(if(order_count>2,1,0)) repurchase_2, sum(if(order_count>3,1,0)) repurchase_3 from ( select user_id, sku_id, tm_id, tm_name, --这个字段是为了虚表看起来更清楚加上的,可以不写 category1_id, category1_name, count(*) order_count from ( select user_id, sku_id from dwd_fact_order_detail where date_format(dt,'yyyy-MM')=date_format('2022-03-17','yyyy-MM') )od left join ---从商品维表->dwd_dim_sku_info中查询出商品id对应的品牌id,以及1级品类id,1级品类名称等信息 ( select id, tm_id, tm_name,--这个字段可以省略不写 category1_id, category1_name from dwd_dim_sku_info where dt='2022-03-17' )sku_inf on od.sku_id=sku_inf.id group by user_id, sku_id, tm_id,tm_name, category1_id, category1_name )t1 group by tm_id,tm_name,category1_id, category1_name --此时相同品牌和相同品类的分到一组中 -
复购次数统计表:

-
-
方法2:
从dws层拿数据,对上面的方法优化一下。dws_user_action_daycount表,这个表中每行数据代表一个用户的所有日常购买行为信息。如下表结构,其中最为关键的是有user_id和order_detail_stats这两个字段;可以使用explode( order_detail_stats )炸开这个字段,然后配合lateral view侧视图形成多行虚表;再跟商品维度join,也可以获得每个用户购买每个品牌商品的次数信息。
-
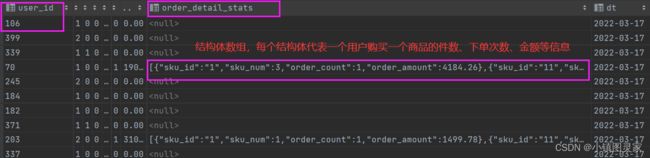
-
--获取到对应用户购买某商品的次数 select user_id, sku_struct.sku_id, sum(sku_struct.order_count) order_count from dws_user_action_daycount lateral view explode(order_detail_stats) tmp as sku_struct where date_format(dt,'yyyy-MM')=date_format('2022-03-17','yyyy-MM') group by user_id, sku_struct.sku_id -

-
与商品维表left join
-
select tm_id, tm_name, category1_id, category1_name, sum(if(order_count>1,1,0)) repurchase_1, sum(if(order_count>2,1,0)) repurchase_2, sum(if(order_count>3,1,0)) repurchase_3 from ( select user_id, sku_id, tm_id, tm_name, --这个字段是为了虚表看起来更清楚加上的,可以不写 category1_id, category1_name, count(*) order_count from ( select user_id, sku_struct.sku_id, sum(sku_struct.order_count) order_count from dws_user_action_daycount lateral view explode(order_detail_stats) tmp as sku_struct where date_format(dt,'yyyy-MM')=date_format('2022-03-17','yyyy-MM') group by user_id, sku_struct.sku_id )od left join ( select id, tm_id, tm_name,--这个字段可以省略不写 category1_id, category1_name from dwd_dim_sku_info where dt='2022-03-17' ) sku_inf on od.sku_id=sku_inf.id group by user_id, sku_id, tm_id,tm_name, category1_id, category1_name ) t1 group by tm_id,tm_name, category1_id, category1_name; -

1)建表语句
-
drop table ads_sale_tm_category1_stat_mn;
create external table ads_sale_tm_category1_stat_mn
(
tm_id string comment '品牌 id',
category1_id string comment '1 级品类 id ',
category1_name string comment '1 级品类名称 ',
buycount bigint comment '购买人数',
buy_twice_last bigint comment '两次以上购买人数',
buy_twice_last_ratio decimal(16,2) comment '单次复购率',
buy_3times_last bigint comment '三次以上购买人数',
buy_3times_last_ratio decimal(16,2) comment '多次复购率',
stat_mn string comment '统计月份',
stat_date string comment '统计日期'
) COMMENT '品牌复购率统计'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_sale_tm_category1_stat_mn/';
2)数据导入
with
tmp_order as(
select
user_id,
order_stats_struct.sku_id sku_id,
order_stats_struct.order_count order_count
from dws_user_action_daycount lateral view explode(order_detail_stats) tmp
as order_stats_struct
where date_format(dt,'yyyy-MM')=date_format('2022-03-17','yyyy-MM')
),
tmp_sku as(
select
id,
tm_id,
category1_id,
category1_name
from dwd_dim_sku_info
where dt='2022-03-17'
)
insert into table ads_sale_tm_category1_stat_mn
select
tm_id,
category1_id,
category1_name,
sum(if(order_count>=1,1,0)) buycount,
sum(if(order_count>=2,1,0)) buyTwiceLast,
sum(if(order_count>=2,1,0))/sum( if(order_count>=1,1,0)) buyTwiceLastRatio,
sum(if(order_count>=3,1,0)) buy3timeLast ,
sum(if(order_count>=3,1,0))/sum( if(order_count>=1,1,0)) buy3timeLastRatio ,
date_format('2022-03-17' ,'yyyy-MM') stat_mn,
'2022-03-17' stat_date
from
(
select
tmp_order.user_id,
tmp_sku.category1_id,
tmp_sku.category1_name,
tmp_sku.tm_id,
sum(order_count) order_count
from tmp_order
join tmp_sku
on tmp_order.sku_id=tmp_sku.id
group by
tmp_order.user_id,tmp_sku.category1_id,tmp_sku.category1_name,tmp_sku.tm_id
)tmp
group by tm_id, category1_id, category1_name;
地区主题
地区主题信息
1)建表语句
drop table if exists ads_area_topic;
create external table ads_area_topic(
`dt` string COMMENT '统计日期',
`id` bigint COMMENT '编号',
`province_name` string COMMENT '省份名称',
`area_code` string COMMENT '地区编码',
`iso_code` string COMMENT 'iso 编码',
`region_id` string COMMENT '地区 ID',
`region_name` string COMMENT '地区名称',
`login_day_count` bigint COMMENT '当天活跃设备数',
`order_day_count` bigint COMMENT '当天下单次数',
`order_day_amount` decimal(16,2) COMMENT '当天下单金额',
payment_day_count` bigint COMMENT '当天支付次数',
`payment_day_amount` decimal(16,2) COMMENT '当天支付金额'
) COMMENT '地区主题信息'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_area_topic/';
2)数据导入
insert into table ads_area_topic
select
'2022-03-17',
id,
province_name,
area_code,
iso_code,
region_id,
region_name,
login_day_count,
order_day_count,
order_day_amount,
payment_day_count,
payment_day_amount
from dwt_area_topic;
ADS 层导入脚本
- 略
复盘离线电商数仓3.0项目–数据开发梳理笔记