2022泰迪杯B题思路解析(LSTM神经网络,时间序列ARIMA模型)可供学习参考
仅以本文记录我和另外两位小伙伴参加的本次数模比赛,聊表纪念
完整论文和代码请点赞关注收藏后私信博主要
电力系统负荷预测是一个影响因素众多,意义巨大的重要问题。本文通过建 立 LSTM 电力预测模型与 ARIMA(p,d,q)预测模型,将深度学习算法与统计学方法 结合,给出了系统负荷预测值并与传统预测模型对比分析其预测精度;同时建立 统计学模型挖掘分析负荷数据的突变情况。该问题的研究有利于提高电力系统预 测的精确性以及电网运行的效能与稳定性。 针对问题一第一小问,本文利用长短期记忆神经网络,建立 LSTM 电力负荷 预测模型,根据历史负荷数据预测出未来十天间隔 15 分钟共 960 条结果,预测 精度为 0.0001309;使用 spss 专家建模器建立 ARIMA(0,1,12)(1,1,1)模型,预 测该地区电网未来十天间隔 15 分钟共 960 条结果,并得出相关的拟合度量。 针对问题一第二小问,采用上一问建立的 LSTM 预测模型进行预测,从预测 出的完整序列抽取出日负荷最大值和最小值,预测精度为 0.000237。 针对问题二第一小问,本文引入气象学中气候数据突变检测的曼肯德尔 (Mann-Kendall)检验法,分别测算出大工业、非普工业、普通工业和商业历史 用电负荷各自的突变点与突变量级,分析突变原因与天气因素及社会因素有关。 针对问题二第二小问,在问题一第一小问建立的 LSTM 模型基础上,将气象数据 转化为独热编码,与原历史数据一起组成二维输入进行预测,得到相应预测精度 为 0.000029;ARIMA 模型对四个行业未来三个月的日负荷最大值、最小值进行预 测 , 分 别 得 出 对 应 的 ARIMA 模 型 是 : ARIMA(0,1,14) , ARIMA(0,1,14) , ARIMA(0,0,9),ARIMA(0,0,1),ARIMA(0,0,14),ARIMA(1,0,14),ARIMA(0,1,8), ARIMA(0,1,0)。 针对问题二第三小问,由 LSTM 和 ARIMA 模型得出的预测值可以观察知大工 业和普通工业的最大最小日负荷的起伏程度较大,与原始数据相比发展较为平稳, 非普工业和商业都有日负荷下降的趋势,建议根据各行业以新能源代替传统能源, 控制碳排放,完成行业的绿色转型。
关键词:LSTM ARIMA 电力负荷预测 突变检验 “双碳”目标
一、 问题重述
电力负荷是指电力用户的用电设备在某一个时刻使用由电力系统提供的电 功率之和。准确的负荷预测可以保持电网运行的安全性和稳定性,保障社会生产 和生活正常进行。预测电力系统负荷需要充分考虑历史数据、经济状况、气象条 件等因素。其中按照预测的时间跨度可分为短期、中期、长期预测,对于电网内 部、企业生产、社会生活等具有重要意义。电力系统负荷结构的多元化使得传统 负荷预测模型的效果产生了一定程度的降低,需进一步改进相关模型和算法以提 高预测的准确性。建立模型,解决以下负荷预测问题:
1. 根据某地区电网 2018 年 1 月 1 日起至 2021 年 8 月 31 日每间隔 15 分钟 的电力系统负荷数据,建立适当的中短期负荷预测模型:
(1) 得出该地区电网未来 10 天每间隔 15 分钟的预测结果,分析该模型或算 法的预测精度;
(2) 得出该地区电网未来 3 个月内日负荷的最大值和最小值的预测结果,以 及达到最值对应的时间,分析其预测精度。
2. 根据该地区四个行业各自的 2019 年 1 月 1 日起至 2021 年 8 月 31 日用电 的电荷数最大值和最小值数据,建立适当的中期预测模型:
(1) 分析并指出以上四个行业用电负荷突变的时间、量级以及可能原因;
(2) 得出各行业未来 3 个月内日负荷的最大值以及最小值的预测结果,分析 其预测精度;
(3) 从各行业的实际情况出发,研究国家“双碳”目标对未来各行业用电负 荷有可能产生的影响,并针对相关行业提出对应的建议。
2.1 问题一的分析
问题一要求根据某地区电网在一段时期内间隔 15 分钟的负荷数据建立中短 期负荷预测模型。由于是中短期预测,于是我们首先考虑使用预测问题的传统方 法——时间序列预测法;在智能算法选择上,鉴于数据为时间序列,且样本量极 大,为避免可能的误差梯度消失或爆炸问题,我们使用长短期记忆神经网络(LSTM) 进行预测并与时间序列预测法得出的结果进行比较。为了在所有模型之间建立有
4
效的比较,对所有预测计算 MAE(平均绝对误差)以反映其预测精度。 第一小问要求使用建立的模型预测该地区电网未来10天内间隔15分钟的负 荷数据并分析预测精度。由于输入数据为一维序列,将特征维度定为 1,同时考 虑将时间步长设为样本总数除以预测数,并将机器学习中的损失函数定义为预测 精度。 第二小问要求预测未来 3 个月日负荷的最大值和最小值,原理与第一小问 相同。我们考虑先预测出 3 个月的完整数据序列,再从中抽取每日负荷的最大与 最小值。
2.2 问题二的分析
第一小问要求根据大工业、非普工业、普通工业、商业日负荷最大值和最小 值的历史数据分析各行业用电负荷突变的时间、量级和可能的原因。我们考虑引 入气象学中用于长时间尺度数据检验的滑动 t 检验(sliding t-test) 和曼肯德尔检 验(Man-Kendall test)进行求解。 第二小问要求在第一小问的基础上求出各行业未来 3 个月日负荷最大值和 最小值。我们考虑沿用问题一中的方法与模型,spss 建立 ARIMA 模型对四个行 业分别预测结果并得出拟合参数,另外沿用上一问的 LSTM 模型,同时考虑气象 因素,对气象数据进行独热编码提取特征,作为一新输入维度输入,通过与未输 入气象因素时的预测结果对比分析气象因素对于电力负荷的影响。 第三小问:在国家“双碳”政策目标的大背景下,我们根据各行业的用电特 点等实际情况,结合前面几问对电网、各行业电力负荷数据的分析与预测情况, 探讨分析政策可能对各行业用电造成的影响并提出改善建议。
三、 模型假设
1. 使用 spss 专家建模器得出的模型及模型对应的参数是时间序列模型中 预测精度最高、拟合效果最好的模型以及参数;
2. 假设时间序列分析模型受特殊因素的扰动较小;
3. 仅考虑历史负荷、气象条件对于电力系统负荷预测的影响;
4. 在进行滑动 t 检验时假设两序列均值差异的显著性水平α=0.05。
5.1 问题一模型的建立与求解 5.1.1 第一小问模型的建立与求解
(1)ARIMA 模型 第一小问中,建立针对电力负荷时间序列预测模型,运用 spss 软件的“专 家建模器”可以在众多模型中选择一个准确性相对最高的数学模型以描述因变量 即从 2021 年 8 月 31 日起未来十天的每隔 15 分钟负荷变化过程的规律性统计, 进而在数学模型的基础上确定本题中电力负荷的预测模型,以得出对未来负荷的 预报结果[1]。
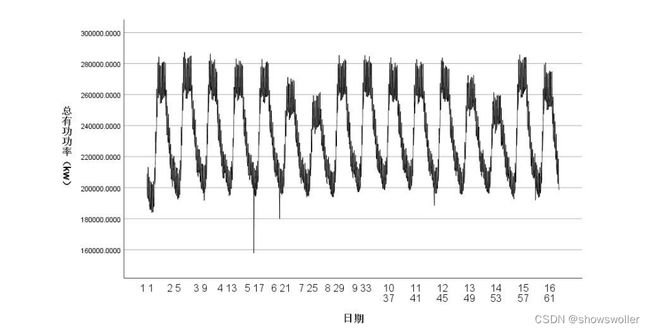
ARIMA 模型(Autoregressive Integrated Moving Average Model,差分整合移 动平均自回归模型),将 p 阶的自回归模型(AR(p)模型)及 q 阶移动平均过程 (MA(q)模型)结合起来,并用 d 表示使整体数据成为平稳序列所做的差分次数。 为保证预测的准确性,选取 2021 年 8 月 16 日 0:00 起,至 2021 年 8 月 31
日 23:45 共 1536 项数据建立时间序列预测模型。 为绘制时序图及建立时序模型,在 spss 中执行如下语法,将历史数据进行 每天视为一个周期,每个周期视为 96 个时段的划分:
DATE OBS 1 96 (1)
绘制上述历史数据的时序图如下:
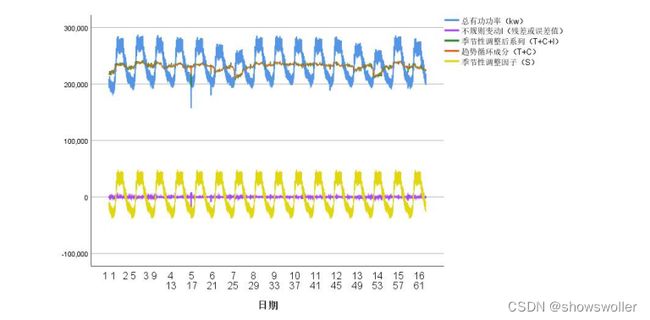
绘制周期性分解后的时序图如下:
运用 spss 的专家建模器检测离群值并创建传统模型,得出最优的模型类型 是 ARIMA(0,1,12)(1,1,1),未来十天预测的部分数据如下:(完整数据见附录 2) 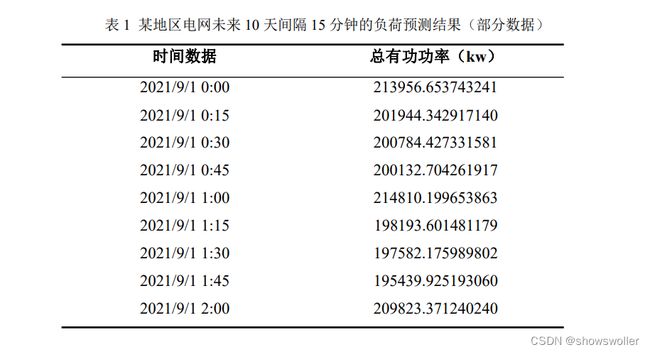
ARIMA 模型(Autoregressive Integrated Moving Average Model,差分整合移 动平均自回归模型),将 p 阶的自回归模型(AR(p)模型)及 q 阶移动平均过程 (MA(q)模型)结合起来,并用 d 表示使整体数据成为平稳序列所做的差分次数。
ARIMA(0,1,12)(1,1,1)表示非季节性 0 阶自回归,非季节性 1 阶差分,非季节性
12 阶移动平均,季节性 1 阶自回归,季节性 1 阶差分,季节性 1 阶移动平均的 时间序列预测模型。预测与拟合图如下:
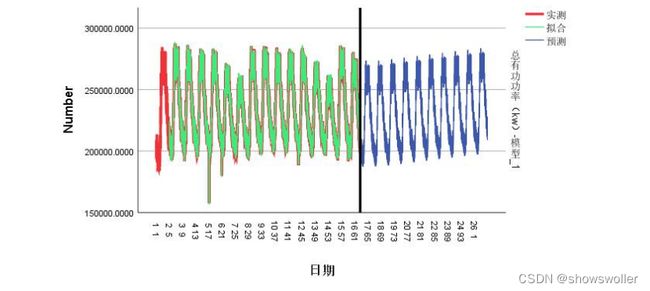
由图可知,该模型的拟合值曲线与观测值曲线重合度很高,拟合效果很好。 此题建立的 ARIMA(0,1,12)(1,1,1)模型的拟合度如下表所示:

预测精度由以上几个参数值可知:平稳 R 方和 R 方分别为 0.787 和 0.998, 与 1 较为接近;均方根误差 RMSE,平均绝对误差百分比 MAPE 以及平均绝对 误差 MAE 分别为 1227.667,0.419,950.705,表示因变量序列与该模型预测水 平的相差程度不大;最大绝对误差百分比 MaxAPE 和最大绝对误差 MaxAE 分别 是 2.400,4696.848,均表示最大的预测误差;正态化 BIC 的值仅为 14.337,表 示此最优模型的拟合程度较好。
(2)LSTM 模型 长短时记忆网络(Long Short Term Memory,简称 LSTM),本质上是一种特 殊的循环神经网络(Recurrent Neural Network,简称 RNN)。LSTM 在 RNN 的基 础结构上增加了输入门限(Input Gate)、输出门限(Output Gate)、遗忘门限(Forget Gate)3个逻辑控制单元,且各自连接到一个乘法元件上(见图1)。通过设定 记忆单元与其他部分连接处的权重控制信息流的输入、输出以及细胞单元 (Memory cell)的状态,从而实现选择记忆重要信息,过滤噪声信息,解决了
RNN 遗忘最开始输入内容的问题,能够有效地利用长距离且波动较大的时序信 息进行预测[5]。其拓扑结构如下图所示。



首先注意到附件一中的数据含有缺失值我们采用 resample 方法填补缺失值 后,绘制时间序列查看大致的走向。

随后我们定义 LSTM 模型。由于附件一的数据为一维数据,设置输入特征 维度(input size)为 1,同理得输出特征维度(output size)为 1。LSTM 模型的 输出格式为(sequence_length, bacth_size,hidden_size),Sequence legth 如前所述 设为 134,同时暂定批量大小(bacth size)为 1,设置隐藏层特征维度(hidden size) 为 20 。其余如隐含层层数、偏置等参数按 LSTM 官方例程设为默认值。 最后选择损失函数为 MSE,优化函数为 adam。 模型训练部分,暂时设置训练次数为 4,绘制出模型训练过程图
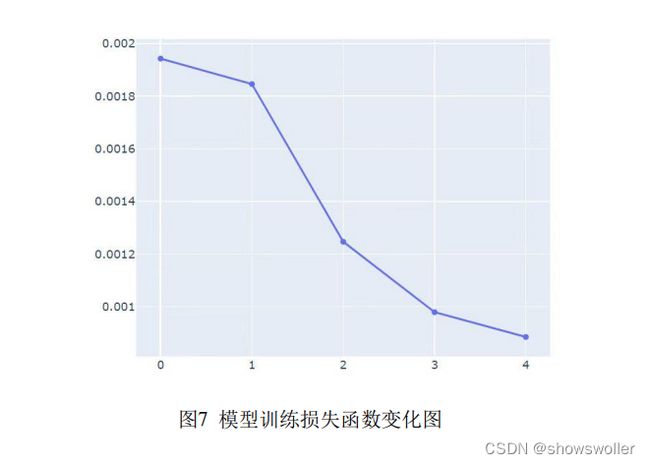
如训练过程图所示,随着训练次数的增加,训练集的损失值不断降低,LSTM
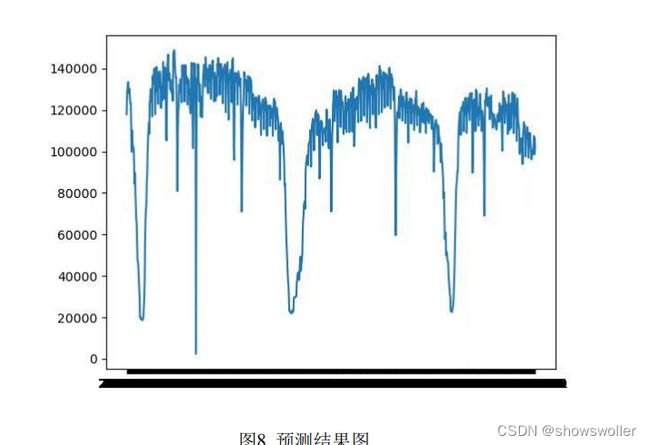
单元内部各参数在不断更新优化。 通过模型测试(这一部分我们将在“六、模型的分析与检验”中详细阐述) 后,我们使用整个样本集作为模型输入,预测出题目要求的未来 10 天间隔 15
分钟共 960 个负荷数据。预测基本思路为开始时使用样本集中第 1-134 个值预测 第 1 个值,然后再用第 2-135 个值预测第 2 个值,依次类推直到 960 个值都被预 测到
预测结果可视化如下
部分预测代码如下
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 由于训练数据存在相差较大的,因此使用min/max尺度变换对训练数据进行归一化
# 注意只对训练数据进行归一化,为了防止有些信息从训练数据泄露到的测试数据
from sklearn.preprocessing import MinMaxScaler
flight_data = pd.read_csv(r"填补缺失值.csv")
fig_size = plt.rcParams["figure.figsize"]
fig_size[0] = 15
fig_size[1] = 5
plt.rcParams["figure.figsize"] = fig_size
plt.title('power vs day')
plt.ylabel('power')
plt.xlabel('day')
plt.grid(True)
plt.autoscale(axis='x',tight=True)
plt.plot(flight_data['power'])
plt.show()
#提取数据
all_data = flight_data['power'].values.astype(float)
print(all_data)
#将数据区分为训练数据和测试数据
test_data_size = 960
train_data = all_data[:-test_data_size]
test_data = all_data[-test_data_size:]
# 由于训练数据存在相差较大的,因此使用min/max尺度变换对训练数据进行归一化
# 注意只对训练数据进行归一化,为了防止有些信息从训练数据泄露到的测试数据
scaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data.reshape(-1, 1))
print(train_data_normalized)
# 将数据转换为张量
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L-tw):
train_seq = input_data[i:i+tw]
train_label = input_data[i+tw:i+tw+1]
inout_seq.append((train_seq ,train_label))
return inout_seq
train_window =5
train_inout_seq = create_inout_sequences(train_data_normalized, train_window)
#定义LSTM模型
class LSTM(nn.Module):
def __init__(self, input_size=1, hidden_size=55, output_size=1):
super().__init__()
self.hidden_size = hidden_size
# 定义lstm 层
self.lstm = nn.LSTM(input_size, hidden_size)
# 定义线性层,即在LSTM的的输出后面再加一个线性层
self.linear = nn.Linear(hidden_size, output_size)
return predictions[-1]
# 模型实例化并定义损失函数和优化函数
model = LSTM()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
print(model)
epochs = 1
optimizer.step()
#if i%25 == 1:
print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
print(f'epoch: {i:3} loss: {single_loss.item():10.10f}')
# 以train data的最后12个数据进行预测
fut_pred = 960
test_inputs = train_data_normalized[-train_window:].tolist()
print(test_inputs)
model.eval()
# 基于最后12个数据来预测第133个数据,并基于新的预测数据进一步预测
# 134-144 的数据
for i in range(fut_pred):
seq = torch.FloatTensor(test_inputs[-train_window:])
# 模型评价时候关闭梯度下降
with torch.no_grad():
model.hidden = (torch.zeros(1, 1, model.hidden_size),
torch.zeros(1, 1, model.hidden_size))
test_inputs.append(model(seq).item())
test_inputs[fut_pred:]
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:] ).reshape(-1, 1))
print(actual_predictions)
# 绘制图像查看预测的[133-144]的数据和实际的133-144 之间的数据差别
x = np.arange(127584,128544, 1)
plt.title('power vs day')
plt.ylabel('power')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(flight_data['power'])
plt.plot(x,actual_predictions)
plt.show()
5.2 问题二模型的建立与求解
5.2.1 问题二第一小问模型的建立与求解
题目要求对负荷数据进行突变检测,考虑引入气象学中常用于检验年代际变 化的曼肯德尔(Mann-Kendall)检验[6]。 曼肯德尔检验法是一种非参数统计检验方法,其优点是不需要样本遵从一定的分 布,也不受到少数异常值的干扰,适用于类型变量和顺序变量,因此适合此处用 于检验电力负荷数据的突变。 将和两个统计量序列曲线和±两条显著区间分界线绘制在一张图构成 MK
突变检验图:
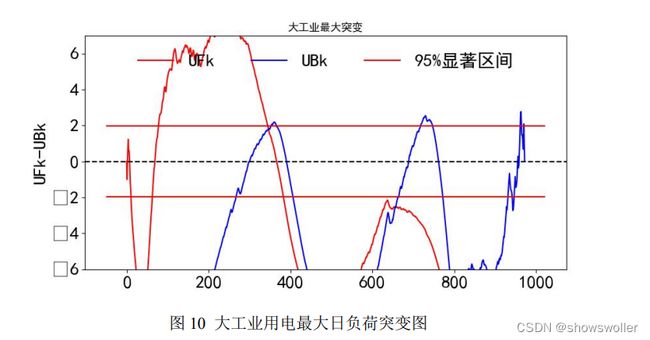
大工业用电最大日负荷突变点位置为[347,471,656]。突变量级在
20000-30000。对应数值、时间点与天气为 116067.43(2019 12 10 晴),102863.9
(2020 4 12 晴),129905.64(2020 10 14 小雨)。突变结果可能主要跟天气有关, 天气好时用电较少,反之较多。
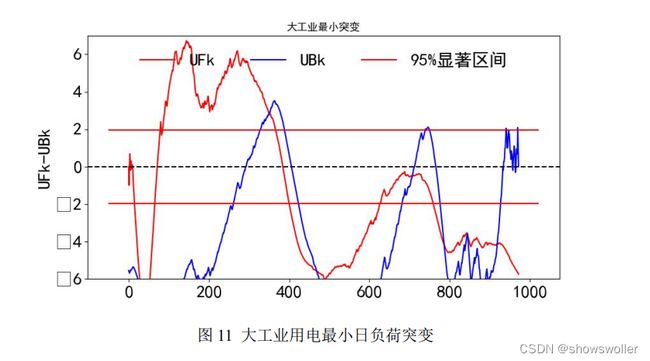
大工业用电最小日负荷突变点位置为[31,44,351,469,708,787,845,
846,919]。量级大概在 90000-100000 左右。最小值突变在一月底二月初,可能 与春节放假的原因有关。
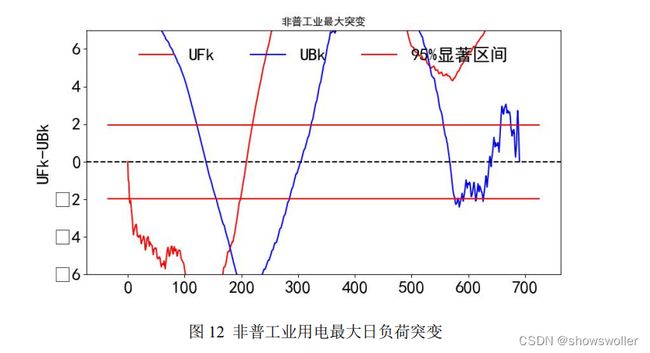
非普工业用电最大日负荷突变点位置为[181,441,532]。对应数值、时间 点与天气为 1982.0484 2020 4 3 小雨, 2539.9632 2020 12 23 阵雨多云,
1871.3442 2021 3 22 多云。
其他几种工业请点赞关注收藏后私信博主要
5.2.2 问题二第二小问模型的建立与求解
一、ARIMA 模型 第二小问中,模型建立的原理和过程与第一题第一小问类似,运用 spss 软 件的“专家建模器”分别对四个行业进行模型的建立,获取 spss 计算得出的四 个行业未来 3 个月内日负荷的最大值及最小值,并根据其给出的参数和有关系数 等分析预测结果及预测精度。 为保证预测的准确性,选取 2021 年 1 月 1 日起,至 2021 年 8 月 31 日共 243
项数据建立时间序列预测模型。 在建立模型前进行缺失值的替换。四个行业 2021 年 1 月 26 日的日负荷数据 均存在缺失,故对缺失值以序列平均值或临近点的线性趋势进行替换。
(1) 大工业用电 大工业用电日负荷最大值及最小值的时间序列图如下:
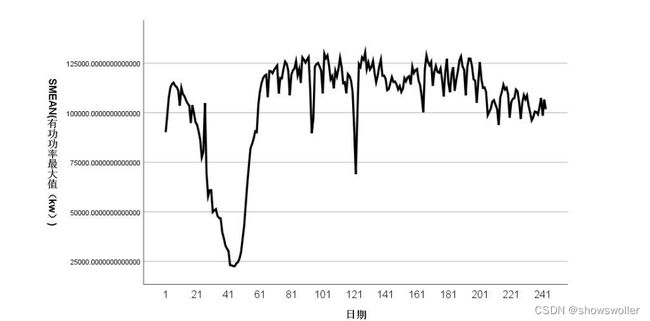
spss 专家建模器计算出预测大工业用电日负荷最大值的最优模型为
ARIMA(0,1,14),表示 0 阶自回归, 1 阶差分,14 阶移动平均的时间序列预测模 型。大工业用电日负荷最小值的最优模型为 ARIMA(0,1,14),表示 0 阶自回归,
1 阶差分,14 阶移动平均的时间序列预测模型[3][4]。
大工业用电未来 3 个月内日负荷最大值和最小值的部分预测值如下:
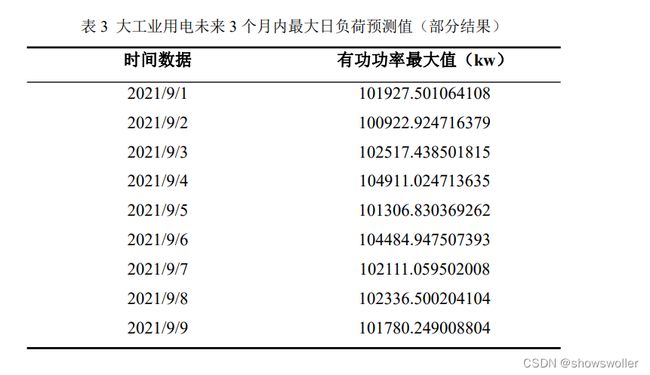
上述两类日负荷的拟合及预测图如下:

观察上面两图可知,上述两个模型的拟合程度均很好。 此题建立的大工业用电未来三个月日负荷最大值预测的 ARIMA(0,1,14)模 型及最小值预测的 ARIMA(0,1,14)模型的拟合度如下两表所示:
表 5 大工业用电日负荷最大值预测 ARIMA(0,1,14)模型拟合统计量

预测精度由以上几个参数值可知: 对于大工业用电未来三个月日负荷最大值预测 ARIMA(0,1,14)模型:平稳 R方和 R 方分别为 0.560 和 0.961,其中 R 方与 1 较为接近;均方根误差 RMSE, 平均绝对误差百分比 MAPE 以及平均绝对误差 MAE 分别为 5187.752,4.279,3997.133,表示因变量序列与该模型预测水平的相差程度尚在可接受的范围内;
最大绝对误差百分比MaxAPE和最大绝对误差MaxAE分别是27.494,14321.564, 均表示最大的预测误差;标准化 BIC 的值仅为 17.358,表示此最优模型的拟合 程度较好。
对于大工业用电未来三个月日负荷最小值预测 ARIMA(0,1,14)模型:平稳 R23方和 R 方分别为 0.912 和 0.960,二者都与 1 较为接近;均方根误差 RMSE,平 均绝对误差百分比 MAPE 以及平均绝对误差 MAE 分别为 5343.336,10.016,3945.040,
表示因变量序列与该模型预测水平的相差程度尚在可接受的范围内; 最大绝对误差百分比MaxAPE和最大绝对误差MaxAE分别是287.526,15679.873, 均表示最大的预测误差;标准化 BIC 的值仅为 17.666,表示此最优模型的拟合 程度较好。
其他几种工业请点赞关注收藏后私信博主要
二、LSTM 模型 根据该题的题目要求,在改变训练集的情况下即可沿用问题一的模型。而在 模型输入时,除了历史数据外,我们考虑气象因素,通过输入更多的特征以期获 得更为精确有效的预测结果,同时分析气象条件对于电力负荷数据预测的影响。 以下详细阐述提取气象特征的过程,其余步骤同问题一。 由附件 3 可得气象特征有“天气状况”、“最高温度”、“最低温度”、“白天风
37
力风向”、“夜间风力风向”五个。我们将这五个气象特征进行独热编码提取特征, 作为一新输入维度输入,通过与未输入气象因素时的预测结果对比分析气象因素 对于电力负荷的影响。
预测结果如下:

5.2.3 第二题第三小问模型的建立与求解
第三小问中,国家的“双碳”目标是为实现“碳减排”提出的“碳达峰”(在 某一时点,二氧化碳的排放达到峰值并不再排放,后逐步回落)、“碳中和”(国 家、企业、产品、活动或个人在一定时间内直接或间接产生的二氧化碳或温室气 体排放总量,通过植树造林、节能减排等形式,以抵消自身产生的二氧化碳或温 室气体排放量,实现正负抵消,达到相对“零排放”),对于构建“碳达峰”、“碳 中和”的政策体系至关重要。 由 LSTM 和 ARIMA 的预测结果可知,大工业和普通工业的最大最小日负荷 的起伏程度较大,与原始数据相比发展较为平稳,因此建议大工业实现绿色低碳
39
转型,促进传统大工业绿色发展进而带动经济社会的进步[7];对于普通工业, 尽量节约传统化石能源并且提高能效,做到“存量减排”,响应“双碳”号召[8]。 而从非普工业和商业的预测结果来看,两个行业都有日负荷下降的趋势。且据资 料显示,商业地产低碳转型有着极广阔的战略前景,建议对存量物业在资产运营 层面进行价值的提升[9];对于非普工业,可以考虑积极发展光伏产业链或使用 其他新型无污染能源来新增产能,完成非普工业的低碳战略转型[10]。
六、 模型的分析与检验
一、ARIMA 模型 第一题第一问中,spss 专家建模器得出的 ARIMA(0,1,12)(1,1,1)模型在时间 序列数据相对平稳的情况下,因变量进行非季节性一阶差分以及季节性一阶差分 后,大部分滞后阶数的自相关系数 ACF 与偏自相关系数 PACF 均和 0 没有显著 的差异,二者表示残差可以视作白噪声。但 spss 计算得出杨-博克斯 Q 检验的显 著性为 0.000,在 95%的置信水平下小于α,说明残差存在无法视为白噪声的可 能性,即原始数据没有被预测模型完全识别,仍有待改进。
