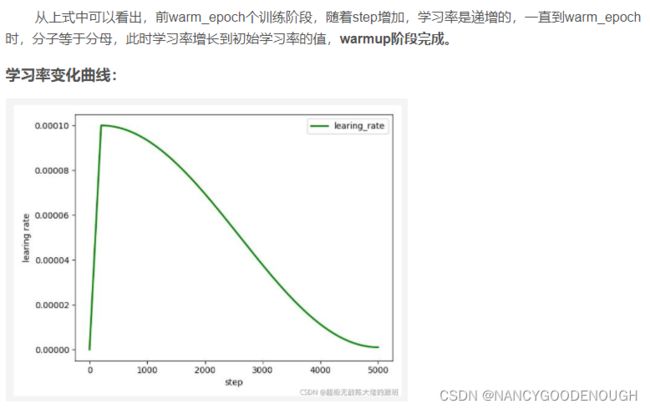
Trick : PyTorch学习率 warm up + 余弦退火
学习率是神经网络训练中最重要的超参数之一,针对学习率的优化方式很多,Warmup是其中的一种。
为什么引入学习率衰减?
我们都知道几乎所有的神经网络采取的是梯度下降法来对模型进行最优化,其中标准的权重更新公式:
![]()
- 学习率a控制着梯度更新的步长(step),a越大,意味着下降的越快,到达最优点的速度也越快,如果为0,则网络就会停止更新
- 学习率过大,在算法优化的前期会加速学习,使得模型更容易接近局部或全局最优解。但是在后期会有较大波动,甚至出现损失函数的值围绕最小值徘徊,波动很大,始终难以达到最优。所以引入学习率衰减的概念,直白点说,就是在模型训练初期,会使用较大的学习率进行模型优化,随着迭代次数增加,学习率会逐渐进行减小,保证模型在训练后期不会有太大的波动,从而更加接近最优解
Pytorch 余弦退火
PyTorch内置了很多学习率策略,详情请参考torch.optim — PyTorch 1.10.1 documentation,这里只介绍常用的余弦退火学习率策略。
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
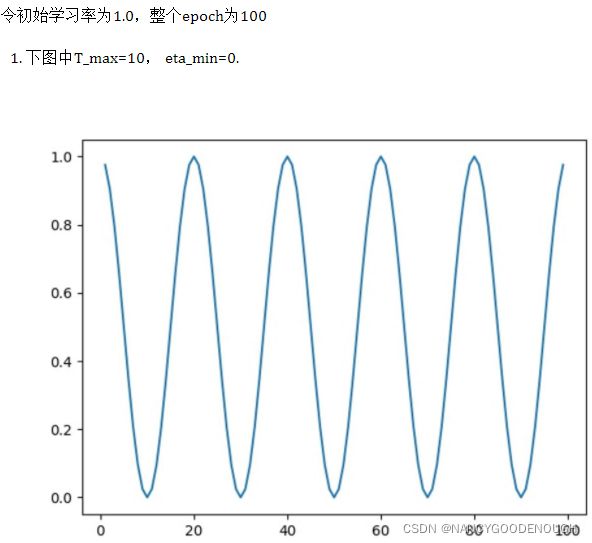
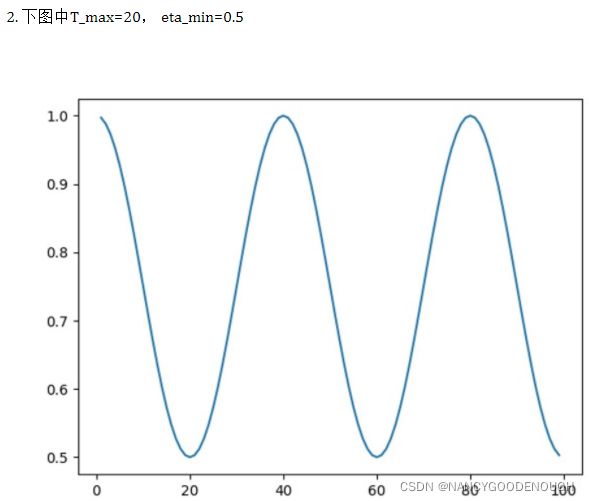
更新策略:按照余弦波形的衰减周期来更新学习率,前半个周期从最大值降到最小值,后半个周期从最小值升到最大值
主要参数:
optimizer:优化器,比如SGD、Adam之类的。
T_max:关键参数,余弦退火最大的迭代次数,即:学习率衰减到最小值时,迭代的次数,通常是len(dataloader)*epochs。余弦波形周期的一半,比如T_max=10,则学习率衰减周期为20,其中前半段即前10个周期学习率从最大值降到最小值,后10个周期从最小值升到最大值
eta_min:退火过程中最小的学习率。Default:0
last_epoch(int):最后一个epoch的index。Default:0.1
verbose(bool):如果为True,每一次更新都会打印一个标准的输出信息 ,Default:False
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max = 20)
for epoch in range(50):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')

PyTorch warmup
Pytorch内部并没有warmup的接口,为此需要使用第三方包pytorch_warmup ,可以使用命令pip install pytorch_warmup进行安装。
(一)、什么是Warmup?
Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习率来进行训练。
(二)、为什么使用Warmup?
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
Example:Resnet论文中使用一个110层的ResNet在cifar10上训练时,先用0.01的学习率训练直到训练误差低于80%(大概训练了400个steps),然后使用0.1的学习率进行训练。
(三)、Warmup的改进
(二)所述的Warmup是constant warmup,它的不足之处在于从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。于是18年Facebook提出了gradual warmup来解决这个问题,即从最初的小学习率开始,每个step增大一点点,直到达到最初设置的比较大的学习率时,采用最初设置的学习率进行训练。