torch.optim.lr_scheduler:pytorch必须掌握的的4种学习率衰减策略
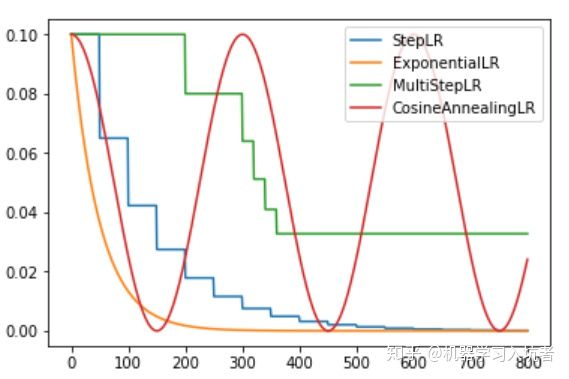
梯度下降算法需要我们指定一个学习率作为权重更新步幅的控制因子,常用的学习率有0.01、0.001以及0.0001等,学习率越大则权重更新。一般来说,我们希望在训练初期学习率大一些,使得网络收敛迅速,在训练后期学习率小一些,使得网络更好的收敛到最优解。下图展示了随着四种常用的学习率衰减策略曲线:
1、指数衰减
学习率按照指数的形式衰减是比较常用的策略,我们首先需要确定需要针对哪个优化器执行学习率动态调整策略,也就是首先定义一个优化器:
optimizer_ExpLR = torch.optim.SGD(net.parameters(), lr=0.1)定义好优化器以后,就可以给这个优化器绑定一个指数衰减学习率控制器:
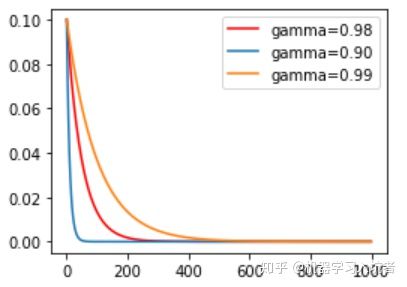
ExpLR = torch.optim.lr_scheduler.ExponentialLR(optimizer_ExpLR, gamma=0.98)其中参数gamma表示衰减的底数,选择不同的gamma值可以获得幅度不同的衰减曲线,如下:
2、固定步长衰减
有时我们希望学习率每隔一定步数(或者epoch)就减少为原来的gamma分之一,使用固定步长衰减依旧先定义优化器,再给优化器绑定StepLR对象:
optimizer_StepLR = torch.optim.SGD(net.parameters(), lr=0.1)
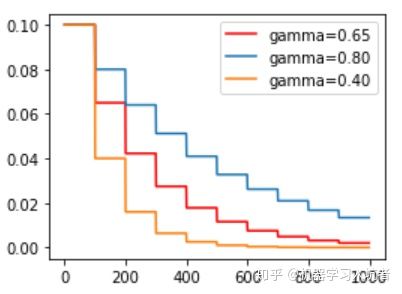
StepLR = torch.optim.lr_scheduler.StepLR(optimizer_StepLR, step_size=step_size, gamma=0.65)其中gamma参数表示衰减的程度,step_size参数表示每隔多少个step进行一次学习率调整,下面对比了不同gamma值下的学习率变化情况:
3、多步长衰减
上述固定步长的衰减的虽然能够按照固定的区间长度进行学习率更新,但是有时我们希望不同的区间采用不同的更新频率,或者是有的区间更新学习率,有的区间不更新学习率,这就需要使用MultiStepLR来实现动态区间长度控制:
optimizer_MultiStepLR = torch.optim.SGD(net.parameters(), lr=0.1)
torch.optim.lr_scheduler.MultiStepLR(optimizer_MultiStepLR,
milestones=[200, 300, 320, 340, 200], gamma=0.8)其中milestones参数为表示学习率更新的起止区间,在区间[0. 200]内学习率不更新,而在[200, 300]、[300, 320].....[340, 400]的右侧值都进行一次更新;gamma参数表示学习率衰减为上次的gamma分之一。其图示如下:
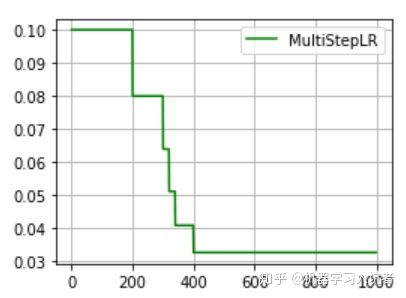
从图中可以看出,学习率在区间[200, 400]内快速的下降,这就是milestones参数所控制的,在milestones以外的区间学习率始终保持不变。
4、余弦退火衰减
严格的说,余弦退火策略不应该算是学习率衰减策略,因为它使得学习率按照周期变化,其定义方式如下:
optimizer_CosineLR = torch.optim.SGD(net.parameters(), lr=0.1)
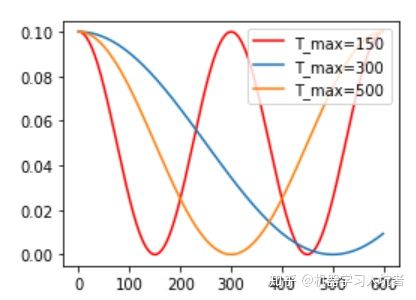
CosineLR = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_CosineLR, T_max=150, eta_min=0)其包含的参数和余弦知识一致,参数T_max表示余弦函数周期;eta_min表示学习率的最小值,默认它是0表示学习率至少为正值。确定一个余弦函数需要知道最值和周期,其中周期就是T_max,最值是初试学习率。下图展示了不同周期下的余弦学习率更新曲线:
5.step_size和iteration在学习率衰减中的关系:
笔者之前也一直没搞明白step_size和iteration在学习率衰减中的关系,知道刚才在训练模型的时候使用余弦退火衰减的时候发现学习率震荡变化了太多次,跟预期的相差太多,模型的loss曲线也一直在震荡。相信大家看完下面的代码便会知晓。
import torch
import torch.nn as nn
import time
import torch.optim.lr_scheduler as lr_scheduler
from torchvision.models import vgg16_bn
model = vgg16_bn(pretrained=False)
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
lr_scheduler = lr_scheduler.CosineAnnealingLR(optimizer,T_max=10)
num_epochs = 100
#注:以下两段伪代码对应了两种不同的学习率衰减方式,大家写代码的时候可能会产生混淆,导致学习率的衰减和预期不一样
for epoch in range(num_epochs):
for i,data in enumerate(data_loader):
optimizer.step()
lr_scheduler.step()
#在代码中我们采用余弦退火的方法来调整学习率,T-max设置为10,即在100个epoch中学习率周期性变化10次,
#但是在这段代码中学习率并不会周期性变化10次,而是周期性变化n次,其中n等于num_samples/batch_size/T_max*num_epoch,远远大于10
#即在本段代码中,10个epoch学习率周期震荡一次变成了10个iteration周期震荡一次
for epoch in range(num_epochs):
for i,data in enumerate(data_loader):
optimizer.step()
lr_scheduler.step()
#在这段代码中学习率会周期性变化10次
#要注意学习率衰减是在内层循环还是外层循环中使用
reference:
1.pytorch必须掌握的的4种学习率衰减策略 链接:https://zhuanlan.zhihu.com/p/93624972