时间序列模型算法 - Prophet,LSTM(二)
时间序列模型 - Prophet
- 1.时间序列简介
-
- 1.1 时间序列 - 平稳性检验
-
- 1.1.1 log法
- 1.1.2 差分法
- 1.2 平稳性的单位根检验
- 2.ARIMA
- 3.Prophet
-
- 3.1 Prophet的优点
- 3.2 安装Prophet
- 3.3 数据处理
- 3.4 预测
- 4.LSTM
-
- 4.1 数据处理
- 4.2 训练预测
1.时间序列简介
在做时间序列时,首先要知道什么样的数据可以做时间序列。
满足时间序列的数据:
时间序列具备平稳性条件,数据有规律的,不是随机性的,这里的规律就可以是数据有明显季节性,周期性的变化。
平稳性:
平稳性表示的是数据整体的均值和方差不发生“明显”变化,在这种现象下,平稳性又分强稳定和弱平稳。
强平稳 vs 弱平稳
强平稳:强平稳的分布不随时间的改变而改变,存在一些白噪声
弱平稳:期望与相关系数不变,未来时刻的值,就会依赖过去的信息,存在依赖性
那数据长什么样子:
如下图所示,做时间序列模型,数据就只有二个特征,一个是时间,一个就是值。

1.1 时间序列 - 平稳性检验
拿到数据后,第一步就是观察数据是否具备平稳性,如果不具备就需要对数据做处理例如:
- 对数变换:变换的序列必须满足大于0
- 平滑法
- 差分
- 分解
以kaggle数据中 航空乘客数据为例:AirPassengers.csv
data = pd.read_csv('AirPassengers.csv')
数据集是这样的:
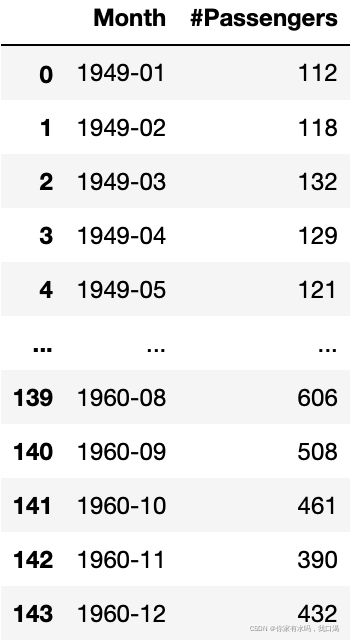
求时间序列数据均值,方差,我们通常可以以年或者月为单位,求连续几年,或者连续几月的均值和方差,这里就需要用到一个函数rolling,函数详细如下
data.rolling(3).mean()
首先对时间序列数据按时间顺序排序,rolling函数对每个数据,选择其自身数据加上最近前的二个数据,然后对这三个数据进行运算聚合(mean)(std)。
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.stattools import acf, pacf
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.arima_model import ARIMA
# Display and Plotting
import seaborn as sns
%matplotlib inline
rcParams['figure.figsize']=10,6
def test_stationarity(timeseries):
rolmean = timeseries.rolling(12).mean()
rolstd = timeseries.rolling(12).std()
plt.plot(timeseries, color='blue',label='Original')
plt.plot(rolmean, color='red', label='Rolling Mean')
plt.plot(rolstd, color='black', label = 'Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean and Standard Deviation')
plt.show(block=False)
print("Results of dickey fuller test")
adft = adfuller(timeseries,autolag='AIC')
output = pd.Series(adft[0:4],index=['Test Statistics','p-value','No. of lags used','Number of observations used'])
for key,values in adft[4].items():
output['critical value (%s)'%key] = values
print(output)
test_stationarity(data.Passengers)
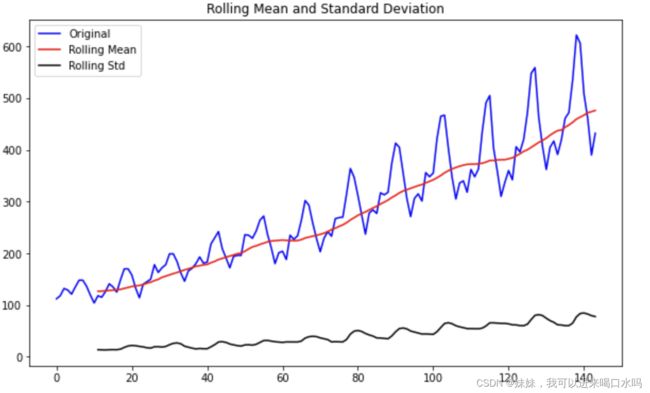
从上图看,黑色色为方差数据,红色为均值数据,从数据上看,是不具备平稳性,那我们就需要对数据进行差分或者log处理
1.1.1 log法
data_log = np.log(data.Passengers)
moving_avg = data_log.rolling(12).mean()
std_dev = data_log.rolling(12).std()
plt.legend(loc='best')
plt.title('Moving Average')
plt.plot(data_log, label='Original')
plt.plot(std_dev, color ="black", label = "Standard Deviation")
plt.plot(moving_avg, color="red", label = "Mean")
plt.legend()

1.1.2 差分法
前一时刻减后一时刻,一阶差分
data_diff=data['#Passengers'].diff(1)
moving_avg = data_diff.rolling(12).mean()
std_dev = data_diff.rolling(12).std()
plt.legend(loc='best')
plt.title('Moving Average')
plt.plot(data_diff, label='Original')
plt.plot(std_dev, color ="black", label = "Standard Deviation")
plt.plot(moving_avg, color="red", label = "Mean")
plt.legend()

1.2 平稳性的单位根检验
ADF是一种常用的单位根检验方法,他的原假设为序列具有单位根,即非平稳,对于一个平稳的时序数据,就需要在给定的置信水平上显著,拒绝原假设
观察数据平稳性就是观察它的均值和方差 是否发生明显变化,来判断是不是平稳的,是不是适合做时间序列。
也可以使用单位根来检验是否平稳性,单位根检验更准确些,具体如何参考如下博客内容:单位根解释
2.ARIMA
ARIMA模型
3.Prophet
Prophet是一种基于加法模型的时间序列数据预测程序,其中非线性趋势与年度、每周和每日的季节性以及假日效应相匹配。它最适用于具有强烈季节性影响的时间序列和几个季节的历史数据。Prophet对缺失数据和趋势变化非常敏感,通常能很好地处理异常值。
Prophet是Facebook核心数据科学团队发布的开源软件。可在PyPI上下载
3.1 Prophet的优点
- 准确快速——Prophet准确快速。Facebook上的许多应用程序都使用它来为规划和目标设定提供可靠的预测。
- 全自动-Prophet是全自动的。无需人工操作,我们就能对混乱的数据做出合理的预测。
- 可调预测——Prophet生成可调预测。它包括许多用户调整预测的可能性。通过添加领域知识,我们可以使用人类可解释的参数来改进预测
- 在R或Python中可用-我们可以在R或Python中实现Prophet过程。
- 能够很好地处理季节变化——Prophet能够适应多个时期的季节性。
- 对异常值的鲁棒性——它对异常值具有鲁棒性。它通过删除异常值来处理异常值。
- 对缺失数据的鲁棒性——Prophet对缺失数据具有弹性
3.2 安装Prophet
亲测有效
conda install pystan
conda install -c conda-forge fbprophet
conda install plotly -y

3.3 数据处理
Prophet还强制要求输入列必须命名为ds(时间列)和y(度量列),因此,我们必须重命名数据框中的列。
data = data.rename(columns={'Month': 'ds','AirPassengers': 'y'})
3.4 预测
接下来,我们来使用Prophet库预测时间序列数据的未来值
model = Prophet(interval_width=0.95)
model.fit(data)
我们可以通过make_future_DataFrame函数来修改我们预测的范围和预测数据帧。
future_dates = model.make_future_dataframe(periods=36, freq='MS')
future_dates.head()
模型生成了未来36个月的数据帧时间戳

预测future_dates的数据帧,模型Prophet返回一个包含特征列的大型数据框,其中比较重要的就如下特征:
- ds:预测值的日期戳
- yhat:时间序列预测的值
- yhat_lower:预测值的下限(类似于箱型图的25%)
- yhat_upper:预测值的上限
forecast = my_model.predict(future_dates)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].head()

绘制的预测结果:
model.plot(forecast, uncertainty=True)
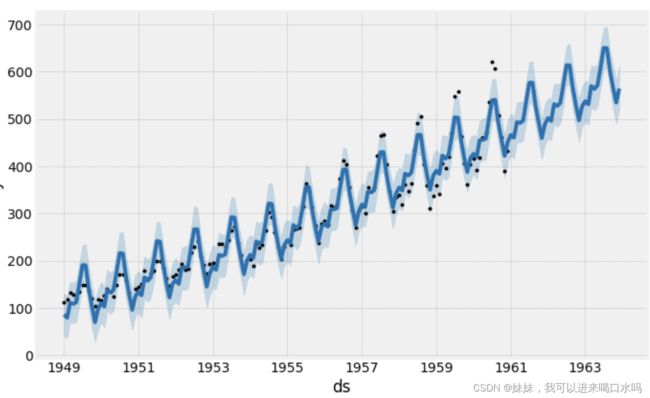
其中观测值为黑点,蓝线就是预测的值,预测的不确定性区间(蓝色阴影区域)。
为了反映预测值的数据分布趋势情况,可以使用函数plot_components绘制图
model.plot_components(forecast)

从上面二个图可以得到二个特点,也可以作为模型的预测,可解释:
- 第一个图显示,每月的航空乘客量随着时间的推移呈线性增长。
- 第二个图显示,每周的乘客数量在周末和周六达到高峰
增加趋势变化点,趋势变化点是时间序列在轨迹上发生突变的日期时间点,默认情况下,Prophet会在最初80%的数据集中添加25个趋势变化点。
from fbprophet.plot import add_changepoints_to_plot
fig = model.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), model, forecast)
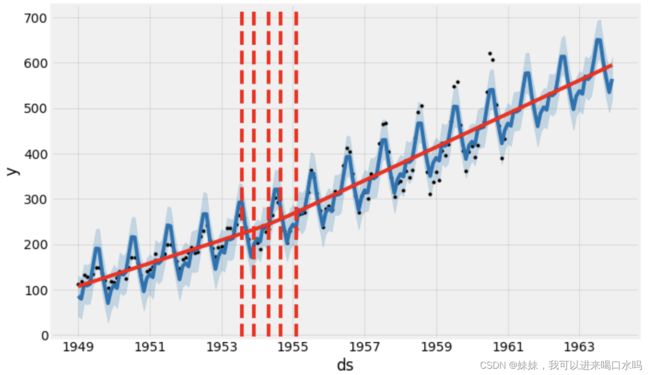
查看发生转折点的日期
model.changepoints
在一些真实的时间序列数据往往在趋势中存在一些突变点,这个时候就需要去调整趋势变化点,相当于正则化处理。
#调整数据趋势变化点为20个,changepoint_Preor_scale增加到0.01,使趋势更灵活
pro_change= Prophet(n_changepoints=20,yearly_seasonality=True, changepoint_prior_scale=0.001)
forecast = pro_change.fit(df).predict(future_dates)
fig= pro_change.plot(forecast);
a = add_changepoints_to_plot(fig.gca(), pro_change, forecast)

4.LSTM
LSTM(Long Short Term Memory Network)长短时记忆网络,是一种改进之后的循环神经网络,可以解决 RNN 无法处理长距离的依赖的问题,模型有很多种如下:
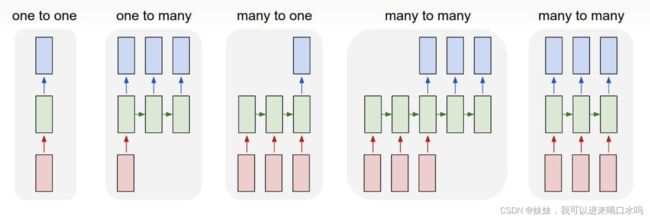
我们模型选择的是“many to one”,通过过去的连续的时间段的乘客值,来预测未来下一点时间点的乘客值。
4.1 数据处理
data.set_index('Month', inplace=True)
#标准化
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler(feature_range=(0,1))
data=scaler.fit_transform(data)
train = int(len(data)*0.75)
test = len(data)-train
train_data,test_data=data[0:train,:],data[train:len(data),:1]
我们这里选择连续4个时间点的数据作为训练集的X,用这个4个时间点的下个时间点的数据作为训练集的Y,因此我需要把数据处理成如下的格式:
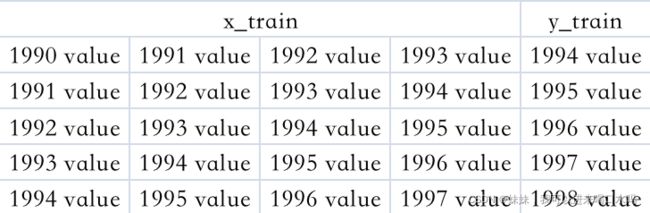
def create_dataset(dataset, time_step=1):
dataX, dataY = [], []
for i in range(len(dataset)-time_step-1):
a = dataset[i:(i+time_step), 0] ###i=0, 0,1,2,3
dataX.append(a)
dataY.append(dataset[i + time_step, 0])
return np.array(dataX), np.array(dataY)
time_step = 4
X_train, y_train = create_dataset(train_data, time_step)
X_test, ytest = create_dataset(test_data, time_step)
X_train =X_train.reshape(X_train.shape[0], 4, 1)
X_test = X_test.reshape(X_test.shape[0], 4, 1)
4.2 训练预测
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
model=Sequential()
model.add(LSTM(50,return_sequences=True,input_shape=(4,1)))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(loss='mean_squared_error',optimizer='adam')
model.fit(X_train,y_train,validation_data=(X_test,ytest),epochs=100,batch_size=1,verbose=1)
train_predict=model.predict(X_train)
test_predict=model.predict(X_test)
转化数据
train_predict=scaler.inverse_transform(train_predict)
test_predict=scaler.inverse_transform(test_predict)
评估
math.sqrt(mean_squared_error(ytest,test_predict))
452.56696011597353