【ELK】ElasticSearch+Logstash+Kibana搭建并集成SpringBoot
前言
为什么需要引进这个ELK日志采集系统呢?在我管理团队的时候,部门还是比较齐全的,运维、测试、前端、后端都是具备的,在没有运维的时候,后端开发是有服务器全部权限的,完全可以直接操作服务器的,可以部署、配置、查看日志等等操作,后来运维部门建立之后,运维部门就全权负责了公司所有的组件平台,比如Gitlab、Nexus、SVN、禅道、Jenkins等等,不过这些大多数都是我搭建(在运维没成立之前),因为后端开发主要还是写服务接口为主要工作,对运维方面的工作也只能说是半吊子,论起专业肯定没有运维人员来得直接,所以开发也就丧失了很多权利,比如:自定义代理、自定义中间件配置等等,这些都需要跟运维解释清楚之后,运维人员帮忙调整,最难受的就是不能够直接看到实时的日志情况,每次都必须让运维把日志文件下载下来或者后端去找运维把日志调出来现场看,时间和效率方面大打折扣,所以这才引进了ELK日志采集系统
引进好处
1、关注集中,后端开发只需要关注自己负责的项目日志即可,如果是直接操作服务器,而且那个服务器还有其他服务,搞不好一个命令没处理好,导致服务器崩掉了,那可是灾难
2、查阅方便:有人说:我习惯了直接看日志文件,对,我们都习惯了看控制台打印出来的日志,但是对权限特别注重的企业,一般都会开放ELK,ELK会对日志进行区分,让我们在查阅的时候更加关注,只不过前提是要事先适应ELK系统
3、方便追溯历史:以往的查看历史日志,都需要把日志文件下载下来,ELK提供了时间范围的查询能够帮我们更好的查看历史日志
4、日志格式统一:通过 logback.xml文件的设置,可以对日志打印的格式等做统一处理
5、使用方便:ELK有Kibana平台直接查阅,如果是以往服务器直接查阅,还要先链接服务器,然后找到日志文件,如果要查看实时日志,还要清空当前控制台等等琐碎而且没必要的操作
ELK介绍
看标题其实就知道,ELK是三个开源中间件的首字母拼接而成的,中文就是日志采集系统
ELK分别对应的是: ElasticSearch+Logstash+Kibana
ElasticSearch:搜索引擎,为了把指定时间的日志生成一个索引,加快日志查询和访问速度
Logstash:日志收集工具,可以从各个方面收集各种各样的日志,然后进行过滤分析,并把日志输出到ES中
Kibana:可视化工具,主要是做日志的查看
安装教程
Elasticsearch的安装
1、wget下载安装包,我这里下载的是7.8.0版本的
[root@localhost home]# wget https://mirrors.huaweicloud.com/elasticsearch/7.8.0/elasticsearch-7.8.0-linux-x86_64.tar.gz2、创建解压并解压到指定目录
[root@localhost home]# tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /usr/local/elasticsearch/3、进入安装目录
[root@localhost home]# cd /usr/local/elasticsearch/elasticsearch-7.8.0/4、修改配置文件
[root@localhost elasticsearch-7.8.0]# vim config/elasticsearch.yml只需要修改如下几个配置即可:
node.name: node-1 # 设置节点名,注释打开即可 network.host: 0.0.0.0 # 允许外部 ip 访问,默认是本地 cluster.initial_master_nodes: ["node-1"] # 设置集群初始主节点,默认是node-1、node-25、为了考虑安全,这些组件暂时不允许root用户来操作es,所以创建一个专门操作es的用户即可,这里创建一个es普通用户
[root@localhost elasticsearch-7.8.0]# adduser es # 设置用户名 [root@localhost elasticsearch-7.8.0]# passwd es # 给es用户设置密码,然后会让你输入和确认密码 Changing password for user es. New password: BAD PASSWORD: The password is shorter than 8 characters Retype new password: passwd: all authentication tokens updated successfully.6、将es用户添加权限给对应的文件夹
[root@localhost elasticsearch-7.8.0]# chown -R es /usr/local/elasticsearch/elasticsearch-7.8.07、切换用户
[root@localhost elasticsearch-7.8.0]# su es8、在es用户下启动es
[root@localhost elasticsearch-7.8.0]# ./bin/elasticsearch -d这个时候需要等待一会,如果没有启动成功,会直接报错,我此时的报错是如下文本:
解决方案如下:
①切换到root用户,编辑vim /etc/security/limits.conf,添加如下配置
* soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096②还是root用户下,编辑vim /etc/sysctl.conf,添加如下配置
vm.max_map_count=655360保存之后使用命令:sysctl -p,如果返回上面的配置即为配置成功
保证如上两步全部操作完毕,然后切换到es用户,再次启动es
9、关闭防火墙或开启9200安全组端口
命令这里我就不讲了,关于安全组怎么开放端口的我也不讲了
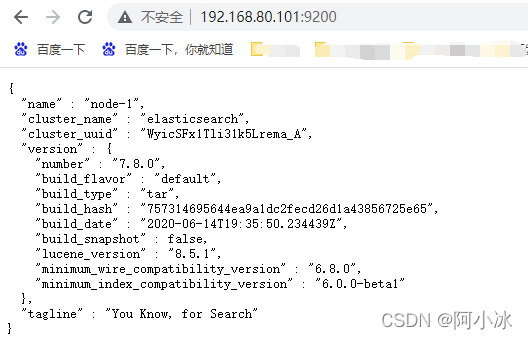
10、访问es,http://ip:9200
如果配置无误并且启动成功,浏览器会返回一段json文本,如下即为安装成功
Logstash的安装
1、下载安装包,要与es版本一致
[root@localhost home]# wget https://mirrors.huaweicloud.com/logstash/7.8.0/logstash-7.8.0.tar.gz2、解压安装包
[root@localhost home]# tar -zxvf logstash-7.8.0.tar.gz3、移动到指定目录下
[root@localhost home]# mv logstash-7.8.0 /usr/local/logstash-7.8.04、复制并重命名配置文件
[root@localhost logstash-7.8.0]# cp config/logstash-sample.conf config/logstash-es.conf5、修改配置文件logstash-es.conf
添加如下配置:
input { # 可以理解为一个tcp等于一个项目,这下面只设置了一个项目, # 如果还有其他的项目,再复制一层tcp即可 # 只需要保证port端口不一样就行了,因为在项目里面, # 需要根据这个端口来确认日志到底在哪一个type中 # tcp创建完之后,需要在output再复制一份if,把index修改为tcp中的type即可 tcp { mode => "server" host => "0.0.0.0" # 允许任意主机发送日志 type => "elk1" # 设定type以区分每个输入源 port => 9601 # 监听的端口 codec => json_lines # 数据格式 } } filter { } output { if [type] == "elk1" { elasticsearch { action => "index" # 输出时创建映射 hosts => "192.168.80.101:9200" # ElasticSearch 的地址和端口 index => "elk1" # 指定索引名 codec => "json" } } }6、关闭防火墙或开放9601安全组端口
上面tcp的端口,用哪一个就开放哪一个即可
7、安装logstash-codec-json_lines插件
因为国内没有对应的源,所以需要修改logstash的gen source属性,修改为国内的源即可
操作如下:
[root@localhost logstash-7.8.0]# vim Gemfile #这个配置本身就存在,直接修改复制下方配置,覆盖原有配置即可 source "https://gems.ruby-china.com" [root@localhost logstash-7.8.0]# ./bin/logstash-plugin install logstash-codec-json_lines Validating logstash-codec-json_lines Installing logstash-codec-json_lines Installation successful #插件下载成功8、启动Logstash,这个不需要切换用户,root就行
# 后台启动Logstash,加上参数是为了检查配置,最好是用这个命令, # 也有不需要检查配置的启动命令,只需要把最后面的--去除即可 [root@localhost logstash-7.8.0]# nohup ./bin/logstash -f ./config/logstash-es.conf --config.reload.automatic &9、查看日志
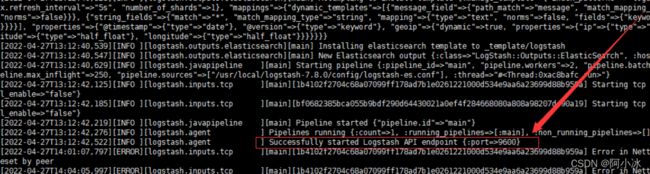
[root@localhost logstash-7.8.0]# tail -f nohup.out观察控制台输出:
看到这样,就说明logstash启动成功
Kibana的安装
1、下载安装包
[root@localhost home]# wget https://mirrors.huaweicloud.com/kibana/7.8.0/kibana-7.8.0-linux-x86_64.tar.gz2、解压
[root@localhost home]# tar -zxvf kibana-7.8.0-linux-x86_64.tar.gz3、重名并移动到指定目录
[root@localhost home]# mv kibana-7.8.0-linux-x86_64 /usr/local/kibana-7.8.04、切换到新目录,并修改配置文件
[root@localhost kibana-7.8.0]# cd /usr/local/kibana-7.8.0 [root@localhost kibana-7.8.0]# vim ./config/kibana.yml # 服务端口,打开注释即可 server.port: 5601 # 服务器ip,0.0.0.0表示所有都可以访问 server.host: "0.0.0.0" # Elasticsearch 服务地址,ELK组件,我都是安装在同一台机器上的,所以是localhost elasticsearch.hosts: ["http://localhost:9200"] # 设置语言为中文 i18n.locale: "zh-CN"5、让Kibana使用es用户
[root@localhost kibana-7.8.0]# chown -R es /usr/local/kibana-7.8.06、切换用户
root@localhost kibana-7.8.0]# su es7、后台方式启动Kibana
[es@localhost kibana-7.8.0]$ nohup ./bin/kibana &8、关闭防火墙或开放5601安全组端口
9、浏览器访问http://ip:5601
安装完成
集成SpringBoot
1、创建一个SpringBoot工程
2、引入logstash服务
net.logstash.logback logstash-logback-encoder 5.2 3、在resource下创建一个logback.xml,并添加如下配置
192.168.80.101:9601 4、编写接口
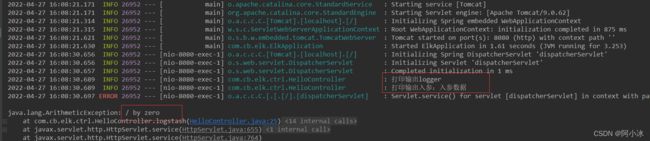
@RestController public class HelloController { Logger logger = LoggerFactory.getLogger(HelloController.class); @RequestMapping("logstash/{text}") public void logstash(@PathVariable("text") String text) { logger.info("打印输出logger"); logger.info("打印输出入参:"+text); //异常打印 int i = 1 / 0; } }5、请求接口并观察日志打印情况
首先我们先看本地服务日志:
虽然报错,但这个是我们想要的,就想看看Kibana是否会打印这红框中的三个日志
6、Kibana配置索引
在查看日志之前,我们需要配置日志读取的索引,因为上面说了,日志都是存放在es的索引中的,所以查看日志就相当于查看es的索引
①首先找到disconver
②创建索引模式
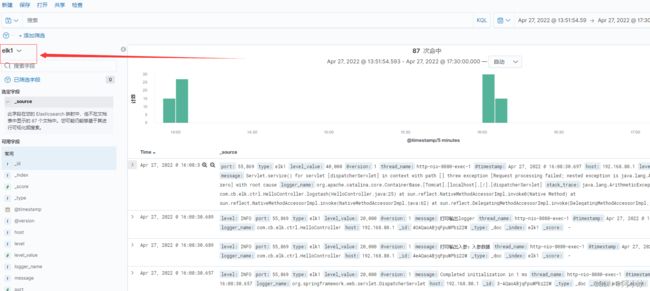
③重新进入Discover,然后就能看到日志平台了
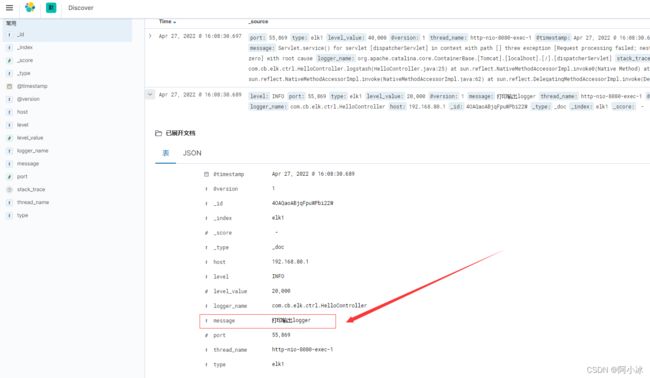
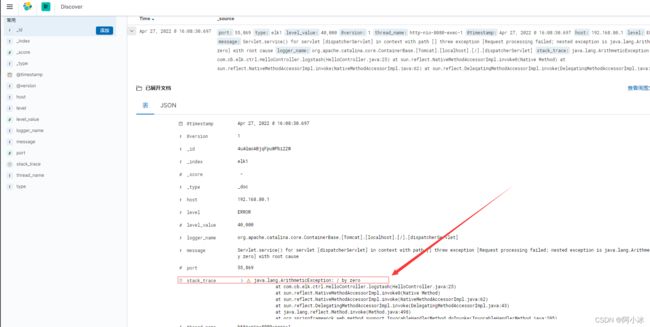
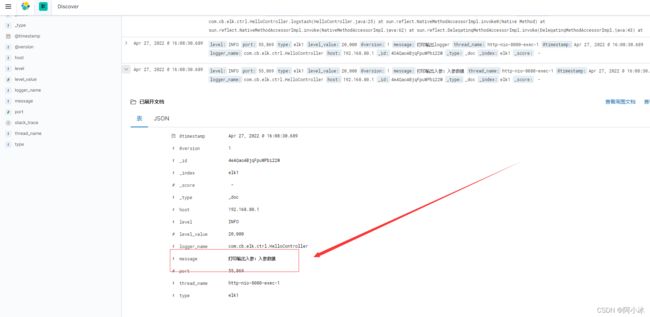
7、查看日志是否与步骤5中打印的结果一直
首先是异常
然后是两个文本打印:
所以到此ELK系统就整合完毕了

拓展
上面搭建的就是原生ELK,也就是传统的ELK,能用没错,而且也没啥问题,但现如今的互联网开发,大多都是很大级别的日志,如果直接是这样的ELK三个开源组件之间来回的直接调用,而且ELK本身还有些一定缺陷的
【缺陷】
1、Logstash太多了,不太好拓展,因为如果要搞集群,logstash还要没太机器都要来一遍,而且Logstash占用CPU和内存较高,而且服务端和客户端没有消息机制,如果服务端宕机了,就会存在数据丢失的问题
2、日志的输入输出都是IO操作,IO本身效率不是特别好,这也会导致日志丢失的可能
3、日志获取和显示不是实时的
以上三点就是传统ELK的缺点,其实这三点都是相同场景下会出现的问题:大规模日志采集
那使用Kafka高可用和消息队列等机制,会优化ELK输入输出的过程,从而弥补上面的三个缺陷
【补充】
Kafka是在ELK基础上做拓展的,所以ELK搭建过程还是上面那些步骤,Kafka的集成其实除了安装和配置之外,最主要的就是对Logstash配置文件进行Kafka的集成,其他的并没有多少其他的讲究,说到底Kafka不是和ELK做集成,其实是和ELK中的L的代表-logstash组件做集成,了解Kafka的都清楚,它底层是异步多线程的,适用场景,官方也说明了其中一点是适用于数据采集,日志也属于数据,所以,引入Kafka保证了ELK的稳定性,也提高了ELK的性能和数据完整性
【最后】
关于Kafka集成ELK的教程,过两天再整理,然后在这里引入,到时候再通知大家,在此之前大家可以先把ELK安装好,毕竟Kafka是在ELK系统基础上做拓展的
【环境搭建】
最后一条我也说了,有时间,我会补上Kafka相关安装教程文章,这就给补上
【Linux】Kafka+ZooKeeper的安装_阿小冰的博客-CSDN博客【Linux】Kafka+ZooKeeper的安装https://blog.csdn.net/qq_38377525/article/details/124457397
总结
由此可见,Kibana的日志打印是按照时间降序,最上面的是时间最新的,除了展示顺序不一,其他的跟我们本地打印的日志完全一致,,kibana日志平台上,我们很明显能看得到很多参数,对于我们开发来说也是很有必要知道每个参数都是什么意思,也能够帮我们做到了平常直观查看日志文件所看不到的其他信息
领导再也不用担心我看日志啦!哈哈哈哈