【VC】Converting Foreign Accent Speech Without a Reference
文章目录
-
- 1. INTRODUCTION
- 2. RELATED WORK
-
- A. 传统FAC方法
- B. 基于sequence-to-sequence模型的FAC
- C. 之前的reference-free的FAC方法
- 3. METHOD
-
- A. 提取说话人无关的speech embedding
- B. step 1: 产生L1-GS
- C. step 2: 训练发音纠正模型
- D. WaveGlow声码器
- 4. 实验配置
- 5. 实验结果
-
- exp1: 评估L1-GS
-
- 客观评测
- 主观评测
-
- 口音测试&音质测试
- 说话人相似度
- exp2. 评估新的L2-GS(即转换后的输出)
-
- 客观评测
- 主观评测
-
- 口音&音质评测
- 说话人相似度
来源:IEEE/ACM Transactions on Audio, Speech and Language Processing 2021
Foreign accent conversion(FAC)是想保留第二语言(L2)学习者的说话人特性和母语(L1)者的发音,合成新的声音。合成的声音在发声训练课中被称作golden speaker。FAC的实现方式通常是应用voice conversion将L1说话人说的句子转换为L2说话人的句子。因此FAC需要一个reference的L1说话人的句子,这样严格地限制了FAC系统的应用。本文提出了一种新的方法,即在推理阶段不需要reference音频,直接对L2句子进行转换。训练步骤分两步,首先,一个传统的FAC过程用于产生golden speaker,这个时候有L1句子的reference。接下来,训练发音纠正模型,使得L2能够转换,并匹配golden speaker。在合成阶段,发音纠正模型直接将一个新的L2句子转换成了golden-speaker. 实验结果表示,转换后的音频在美式英语语音识别系统下,相对WER降低了20.5%,可感知的外国口音的句子数降低了19%,超过73%的测听者认为L2句子和转换后得到的golden speaker是同一个说话人。
1. INTRODUCTION
FAC目的是合成non-native speaker的音色,但是发音模式是native speaker的音频。合成的声音常常被称作golden speaker,golden speaker的音频模仿L2的音色,因此和L2的音频只有发音不同,使得发音错误更明显,更有利于non-native speaker 模仿。FAC在电影配音,个性化文本到语音(TTS)合成,以及提高自动语音识别(ASR)性能上都有应用。
FAC主要的挑战在于没有golden speaker的ground truth,因为一般来说,L2 speaker是无法产生native accent的语音的。因此无法直接用传统的voice conversion的技术。之前解决这个问题的方法是在inference阶段需要一句native speaker的语音,但是这种发音练习使得L2只能联系那些L1事先录好的句子。
为了解决这个问题,本文提出了一个新的FAC系统,在推理阶段不需要reference L1句子,称之为reference-free FAC system. 假设我们有L2和L1的平行语料,训练过程可以分为如下两步。第一步,构建L2的合成器,将他们的speech embedding(后面会提到)映射到mel谱。speech embedding是由native speech的大语料中训练的声学模型得到的,因此是说话人无关的。接着我们使用从 L1句子中提取的speech embedding来驱动 L2 合成器。结果得到的就是带有L2音色和L1发音模式的golden speaker.(这里应该是假设accent耦合在speech embedding里面了)。这个时候L1就可以被丢弃了,后面不会用到了。第二步,训练一个发音纠正模型,使得L2能够转成golden speaker的句子。推理时,输入一个新的L2句子,即可输出没有口音的句子。
发音纠正模型基于state-of-the-art sequence-to- sequence语音转换模型1作为baseline。baseline系统由一个encoder(mel中提取hidden representation),注意力机制学习input和output之间的alignment,一个decoder预测输出的mel谱,以及phoneme classifiers帮助训练过程更加平滑。在本文的实验中,发现baseline很难把L2转成L1,因为L2句子有些不流利和犹豫,使得attention很难正确的对齐input和output。为了解决这个问题,本文提出的系统引入了双向解码技术,帮助发音纠正模型充分利用数据。其基本原理是,通过迫使解码器在训练过程中从正向和向后两个方向计算注意对齐,我们可以使解码器在产生对齐时从过去和未来合并有用的上下文信息。声码器用的是WaveGlow。
2. RELATED WORK
A. 传统FAC方法
口音转换是一个比语者转换还要难的任务,因为需要对口音和说话人解耦。传统方法可以分为发音(articulatory)和声学(acoustic)方法。发音方法的基本策略是构建一个L2 speaker的发音合成器,即构建L2 speaker的发声通道( articulatory trajectories,比如舌头和唇的移动)到mel谱的映射。一旦合成器构建完成,L1 speaker 驱动 articulatory trajectories应用L2的合成器,生成L2无accent的语音。(这里没太懂,后续看一下)
将音色特性从口音当中解耦的方法是直观的,但是实际上大部分情况下收集发音数据是比较昂贵的,而且需要专业的器材。相反,在声学层面将音色特性从口音当中解耦更可实现,因为只需要用麦克风记录数据,但是对于后续的语音处理提供了更大的挑战。传统的VC用的方法(如用DTW讲source和target对齐)不能用于口音转换,因为口音转换中要求音色是不变的。2用L1和L2做完VTL normalization的MFCC相似度,然后用GMM将生成了含有L1发音,但是有L2说话特性的句子。最近,3用说话人无关的ASR声学模型估计每一帧的phone的后验概率得到 phonetic posteriorgram(PPG),一旦L1和L2的PPG被计算出来,可以应用PPG完成many-to-many的转换,得到的效果在口音和音质方面都超过了2。
B. 基于sequence-to-sequence模型的FAC
最近4应用seq2seq模型实现FAC。首先训练L2的合成器,将L2的PPG转换为mel,接着用L1的PPG输入L2合成器,得到golden speaker句子,这种方法明显降低了L2 speech的口音。自那个时候起,seq2seq在VC领域广泛应用,并且取得了更好的效果。
C. 之前的reference-free的FAC方法
5应用了一个speaker encoder,一个多说话人的TTS和一个ASR的encoder。speaker encoder 和TTS用L1 speech训练,ASR用L1和L2的speaker训练。在推理阶段,应用speaker encoder和ASR分别提取说话人embeddings和语言学表达。将二者feed到多说话人的TTS模型中,转换成没有口音的音频。他们的评估表明转换后的音频是接近native口音的,但是转换后的音频说话人与L2的相似度不高。本文的方法为了避免这个问题,口音纠正模型是应用golden speaker数据训练的,保证了说话人的一致性。
3. METHOD
本文提出的方法需要L1+L2平行语料,具体方法如下图所示,分为两步,第一步构建一个L2 speech embedding到mel的合成器,然后将L1的speech embedding输入合成器,即得到golden speaker的句子(即发音人是L2但是发音模式是L1),称之为L1-GS。在第二步,训练发音纠正模型,使得L2句子可以直接转换成L1-GS。在推理时,可以直接把新的L2的句子转成L2-GS。
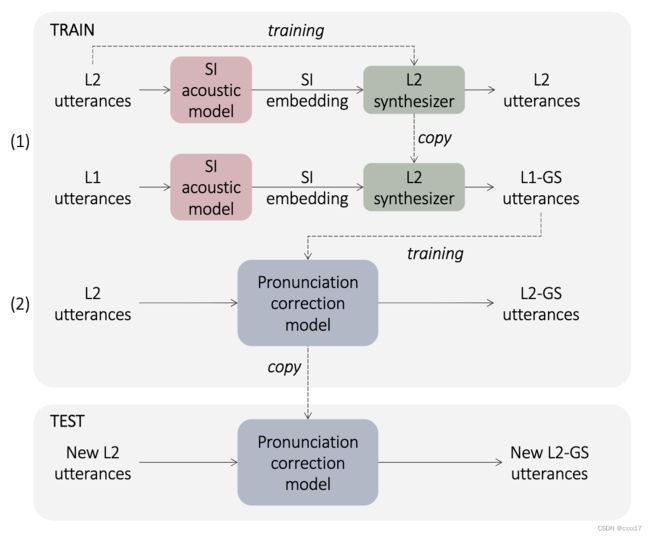
A. 提取说话人无关的speech embedding
用语音识别中的声学模型提取说话人无关的speech embedding,采用了TDNN结构,为了得到和说话人无关的speech embedding,声学模型的输入是将40-dim mfcc与i-vector拼接,用librispeech数据训练。
本文尝试了3种speech embedding:
- Senone phonetic posteriorgram (Senone-PPG): softmax后的输出,这里应该用的是tri-phone,共6024维
- Bottleneck feature (BNF): softmax层之前的输出,维度低一些,256维
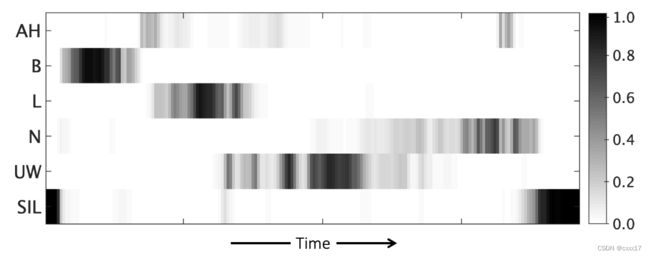
- Monophone phonetic posteriorgram (Mono-PPG): 单独的phone,但是会区分phone在词中的位置“BIE”,346维,“balloon”音频的Mono-PPG如下图所示:
B. step 1: 产生L1-GS
合成器基于Tacotron2结构,具体结构如下:
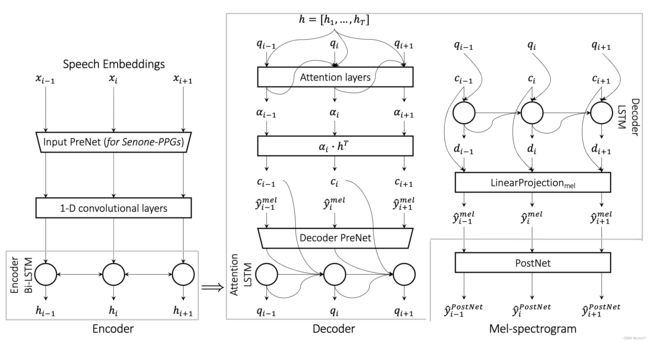
输入是speech embedding,如果输入纬度过高,就用可学习的PreNet降维(对于高维的speech embedding很重要,会影响到手收敛)。对于低维度的Mono-PPGs和BNFs,就不用PreNet了。
最终的loss用公式表示:
L = w 1 ( ∥ Y m e l − Y ^ m e l D e c o d e r ∥ 2 + ∥ Y m e l − Y ^ m e l PostNet ∥ 2 ) + w 2 C E ( Y stop , Y ^ stop ) \begin{aligned} L=& w_1\left(\left\|Y_{m e l}-\hat{Y}_{m e l}^{D e c o d e r}\right\|_2+\left\|Y_{m e l}-\hat{Y}_{m e l}^{\text {PostNet }}\right\|_2\right)+\\ & w_2 \mathrm{CE}\left(Y_{\text {stop }}, \hat{Y}_{\text {stop }}\right) \end{aligned} L=w1(∥ ∥Ymel−Y^melDecoder∥ ∥2+∥ ∥Ymel−Y^melPostNet ∥ ∥2)+w2CE(Ystop ,Y^stop )
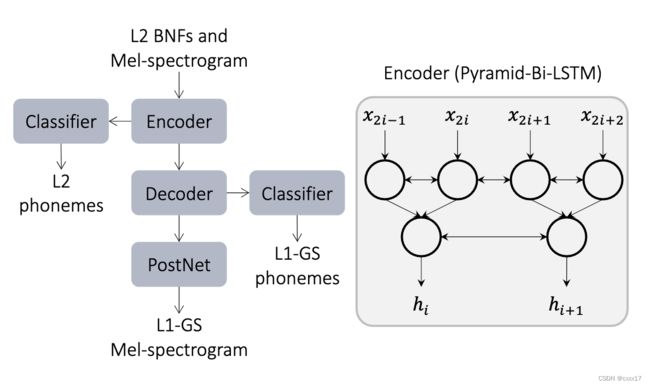
C. step 2: 训练发音纠正模型
Baseline1如下图所示:
 L base = w 1 ( ∥ Y mel − Y ^ mel Decoder ∥ 2 + ∥ Y mel − Y ^ mel Post Net ∥ 2 ) + w 2 C E ( Y stop , Y ^ stop ) + w 3 ( C E ( Y inP , Y ^ inP ) + C E ( Y out P , Y ^ out P ) ) \begin{aligned} L_{\text {base }}=& w_1\left(\left\|Y_{\text {mel }}-\hat{Y}_{\text {mel }}^{\text {Decoder }}\right\|_2+\left\|Y_{\text {mel }}-\hat{Y}_{\text {mel }}^{\text {Post Net }}\right\|_2\right)+\\ & w_2 \mathrm{CE}\left(Y_{\text {stop }}, \hat{Y}_{\text {stop }}\right)+\\ & w_3\left(\mathrm{CE}\left(Y_{\text {inP }}, \hat{Y}_{\text {inP }}\right)+\mathrm{CE}\left(Y_{\text {out } P}, \hat{Y}_{\text {out } P}\right)\right) \end{aligned} Lbase =w1(∥ ∥Ymel −Y^mel Decoder ∥ ∥2+∥ ∥Ymel −Y^mel Post Net ∥ ∥2)+w2CE(Ystop ,Y^stop )+w3(CE(YinP ,Y^inP )+CE(Yout P,Y^out P))
L base = w 1 ( ∥ Y mel − Y ^ mel Decoder ∥ 2 + ∥ Y mel − Y ^ mel Post Net ∥ 2 ) + w 2 C E ( Y stop , Y ^ stop ) + w 3 ( C E ( Y inP , Y ^ inP ) + C E ( Y out P , Y ^ out P ) ) \begin{aligned} L_{\text {base }}=& w_1\left(\left\|Y_{\text {mel }}-\hat{Y}_{\text {mel }}^{\text {Decoder }}\right\|_2+\left\|Y_{\text {mel }}-\hat{Y}_{\text {mel }}^{\text {Post Net }}\right\|_2\right)+\\ & w_2 \mathrm{CE}\left(Y_{\text {stop }}, \hat{Y}_{\text {stop }}\right)+\\ & w_3\left(\mathrm{CE}\left(Y_{\text {inP }}, \hat{Y}_{\text {inP }}\right)+\mathrm{CE}\left(Y_{\text {out } P}, \hat{Y}_{\text {out } P}\right)\right) \end{aligned} Lbase =w1(∥ ∥Ymel −Y^mel Decoder ∥ ∥2+∥ ∥Ymel −Y^mel Post Net ∥ ∥2)+w2CE(Ystop ,Y^stop )+w3(CE(YinP ,Y^inP )+CE(Yout P,Y^out P))
提出的方法对加入了双向的attention,多了一个decoder的输出,前向attention和反向attention应该是一致的,loss重写为下:
L b w d = w 1 ( ∥ Y m e l − Y ^ m e l b w d ∥ 2 + ∥ Y m e l − Y ^ m e l − P o s t N e t b w d ∥ 2 ) + w 2 C E ( Y stop , Y ^ stop b w d ) + w 3 ( CE ( Y outP , Y ^ outP b w d ) ) \begin{aligned} L_{b w d}=& w_1\left(\left\|Y_{m e l}-\hat{Y}_{m e l}^{b w d}\right\|_2+\left\|Y_{m e l}-\hat{Y}_{m e l-P o s t N e t}^{b w d}\right\|_2\right)+\\ & w_2 \mathrm{CE}\left(Y_{\text {stop }}, \hat{Y}_{\text {stop }}^{b w d}\right)+w_3\left(\operatorname{CE}\left(Y_{\text {outP }}, \hat{Y}_{\text {outP }}^{b w d}\right)\right) \end{aligned} Lbwd=w1(∥ ∥Ymel−Y^melbwd∥ ∥2+∥ ∥Ymel−Y^mel−PostNetbwd∥ ∥2)+w2CE(Ystop ,Y^stop bwd)+w3(CE(YoutP ,Y^outP bwd))
L a t t = w 4 ∥ α f w d − α b w d ∥ 2 L_{a t t}=w_4\left\|\alpha_{f w d}-\alpha_{b w d}\right\|_2 Latt=w4∥αfwd−αbwd∥2
L proposed = L b a s e + L b w d + L a t t L_{\text {proposed }}=L_{b a s e}+L_{b w d}+L_{a t t} Lproposed =Lbase+Lbwd+Latt
D. WaveGlow声码器
用WaveGlow声码器,用于将转换后的mel生成audio samples。
4. 实验配置
数据集:CMU-ARCTIC
挑出了一个native 口音的说话人:BDL; American accent
数据集: L2-ARCTIC
两个non-native的说话人:YKWK, Korean; TXHC, Chinese
训练集,验证集,测试集没有重叠,分别是1032句,50句和50句。
采样率都转成16k ,声码器是按照WaveGlow的官方代码,用L2数据训练的。
5. 实验结果
分别从客观和主观指标来评价。
exp1: 评估L1-GS
L1-GS是本文提出的model的上界,探索了3种不同的speech embedding对L1-GS的影响:

客观评测
三种不同的speech embedding生成音频的WER。
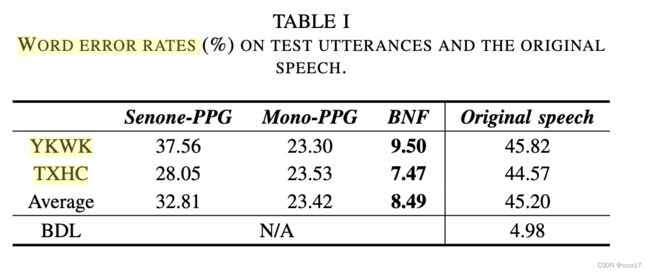
可以看到L1-GS的WER在使用BNF时最低,在这里说明口音可能和native比较接近,native的ASR更适用。
主观评测
口音测试&音质测试
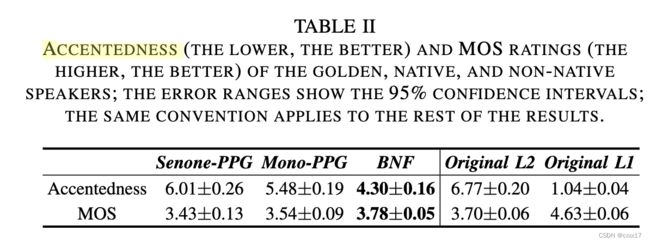
BNF都达到了最好的效果,且在音质上BNF稍稍好于原始的L2音频。
说话人相似度
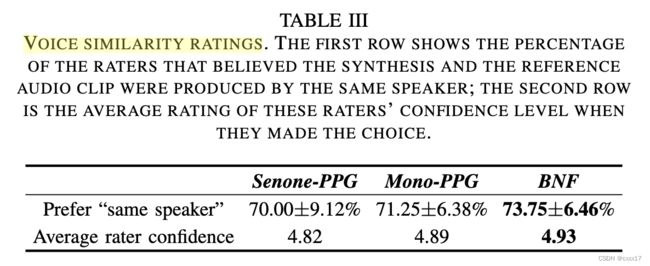
exp2. 评估新的L2-GS(即转换后的输出)
- Baseline1: C. step 2中提到的baseline,当前最好的VC模型结构
- Baseline2: 5 FAC之前的工作
- Proposed(without att loss)
- Proposed
客观评测
- MCD
- F 0 F_0 F0 RMSE
- DDUR
- WER
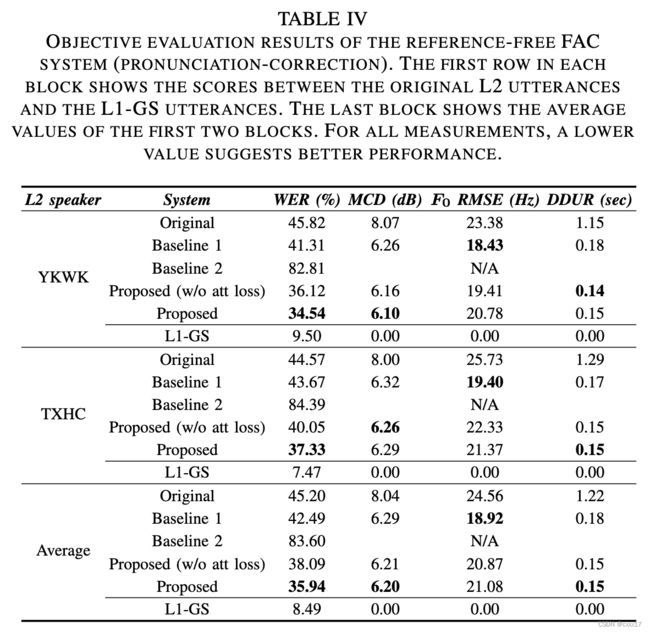
主观评测
口音&音质评测
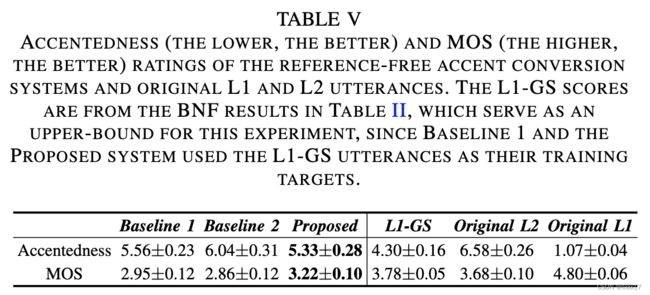
说话人相似度
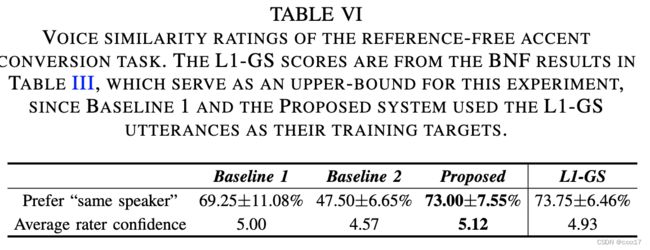
说话人相似度基本已经达到了上限。