aiohttp 异步http请求-5.下载大文件边下载边保存(节省内存)
前言
当从网络上下载小文件时,比如一张图片,可以直接用response.read() 来读取返回的数据流文件。
但是当下载一个几百兆,几千兆的文件会占用很大的内存,为了减少内存的占用可以一边读取一边下载的方式。
流式响应内容
平常返回的response 对象,使用read(), json()和且text()非常方便,但是需谨慎使用它们。所有这些方法都将整个响应加载到内存中。
例如,如果您要下载几个千兆字节大小的文件,这些方法将加载内存中的所有数据。相反,您可以使用该content 属性。它是aiohttp.StreamReader 类的一个实例。和transfer-encodings gzip deflate自动为您解码.
async with session.get('https://api.github.com/events') as resp:
await resp.content.read(10)
一般来说,您应该使用这样的模式来保存正在流式传输到文件的内容:
with open(filename, 'wb') as fd:
async for chunk in resp.content.iter_chunked(chunk_size):
fd.write(chunk)
使用resp.content.iter_chunked()可以一边下载一边保存,无需使用read(), json() 和text()显式读取content.
使用示例
比如当我们需下载一个几百兆的文件,以下载pycharm为例 https://download.jetbrains.com/python/pycharm-professional-2022.1.exe
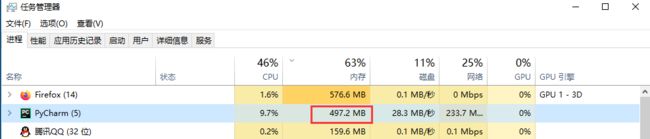
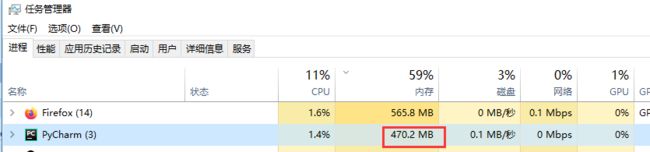
先看下内存使用情况,pycharm 编辑器自身占用470M
如果是用read()方法一次性读取,然后写入到文件
import aiohttp
import asyncio
async def main():
async with aiohttp.ClientSession() as session:
url = 'https://download.jetbrains.com/python/pycharm-professional-2022.1.exe'
async with session.post(url) as resp:
content = await resp.content.read()
with open('pycharm.exe', 'wb') as fd:
fd.write(content)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
运行的时候,会看到pycharm内存占用峰值会达到980M,也就是python运行的时候下载文件占用了500兆,因为文件本身占450M,文件越大,占用的内存也就越大,如果是一个几G的文件,那会直接把内存消耗完。

边下载边保存
于是我们需要一边下载一边保存的方式,设置iter_chunked()的值,每次读取的文件内容大小bytes
import aiohttp
import asyncio
from aiohttp import FormData
async def main():
async with aiohttp.ClientSession() as session:
url = 'https://download.jetbrains.com/python/pycharm-professional-2022.1.exe'
async with session.post(url) as resp:
with open('pycharm.exe', 'wb') as fd:
# iter_chunked() 设置每次保存文件内容大小,单位bytes
async for chunk in resp.content.iter_chunked(1024):
fd.write(chunk)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
pycharm 运行的时候占用内存497M左右,也就是代码运行只占了27M内存