卷积神经网络的几种模型
关于卷积神经网络的模型,我们这里只谈论关于图像分类的卷积神经网络的四种模型。
在这里我们就不对卷积神经网络的结构进行阐述,不了解的同学可以参考我之前的博客
卷积神经网络经典结构入门(图像分类)_星星也倦了/的博客-CSDN博客
LeNet-5
首先我们先阐述的是1989年提出来的的LeNet-5结构。它其实就是最原始的结构,卷积层后衔接池化层,再接卷积层和其后的池化层,最后一个全连接层。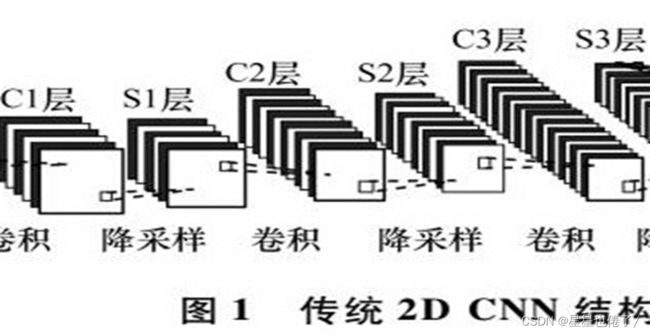
(c1=convolution layer1,s1=subsampling layer1[降采样层,就是池化层])
这个模型是实现识别手写数字的功能为目的而提出来的,经典模型下它的输入图片为单通道灰度图,图片大小为28*28.
这里有一个不错的演示网址,网站中给出了许多常见的卷积核,如sharpen,left sobel等。
https://setosa.io/ev/image-kernels/
(最右边的图片是原图,即28*28的原图)
(最左边是图片的灰度值,均位于0-255之间)
(中间是便于观察而放大后的原图)
而以上就是LeNet-5的经典结构。而在各大深度学习框架中自带的用作demo目的的LeNet结构对此进行了稍微的改进,如将tanh的激活函数改为了ReLU函数(不饱和非线性函数)。
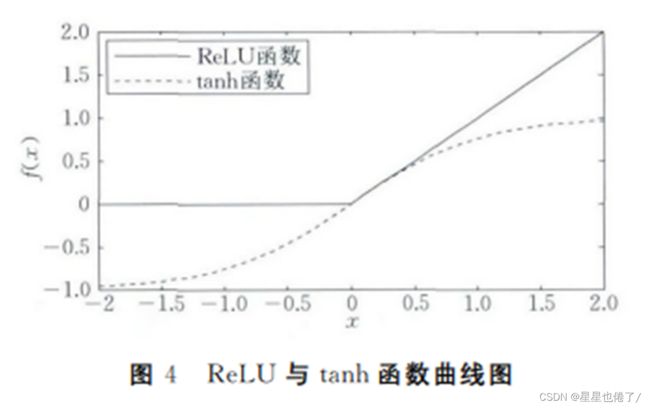
从这幅图中我们可以明显看到ReLU函数在负数(X<0)的值全部置为0,这个操作一定程度上提升了网络的性能。
AlexNet
接下来我们分享AlexNet,它是ImageNet(2012)的夺冠模型,相比于LeNet-5,它的改进就是增加了通道数和深度。
1.输入图片变为了256*256的三通道彩色图片。
2.它成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决Sigmoid在网络较深时的梯度弥散问题。
3.训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合(即随机失活)。
(在CNN结构中,深度越深,特征面数目越多,则网络学习能力越强。但是这也使网络更加复杂,极易出现过拟合的现象。有很多避免过拟合的方法,特别是正则化。正则化是将系数约束为0的过程。正则化可以概括为用于惩罚学习系数的技术,使得他们趋向于0,例如随机失活。)
4.在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果(效果图如下)。

GoogleNet
接下来我们要分享的就是GoogleNet,在分享之前,先介绍三个术语,1*1卷积,NIN(network in
network),全局平均池化。
1*1卷积
大家可能会感到疑问,1*1不就是相当于一个矩阵里的所有元素*k么?这有什么优化啊!
其实不然,对于多通道的图片,每个通道上的图片做1*1卷积可以做到降维的目的,减少运算的数量级。
NIN(network in network)
字如其名。就是网络中还嵌套了网络,它不同于AlexNet增加网络通道数和深度,它提出了另外一个思路,即串联多个由卷积层和“全连接”层构成的小网络来构建一个深层网络。
全局平均池化
采用全局平均池化技术,相比于过去的模型有三大优点。
一捕捉全局的特征,遗漏的特征更少,结构更加精确。
二全局平均池化因为使全局平均,不需要参数,所以减少了参数的数量。
三全局平均池化,使得图片分类的程序更加健壮,程序的鲁棒性更强。
在了解了以上三个术语后,我们再来看inception,这个GoogleNet的核心部分。
一般来说,增加网络的深度与宽度可以提升网络的性能,(例如AlexNet,VGG)但是这样做也会带来参数量的大幅度增加,而且容易产生过拟合现象和梯度消失等问题。
Inception网络较好地解决了这个问题。
Inception v1 网络是一个精心设计的22层卷积网络,并提出了具有良好局部特征结构的Inception模块,即对特征并行地执行多个大小不同的卷积运算与池化,最后再拼接到一起。由于1×1、3×3和5×5的卷积运算对应不同的特征图区域,因此这样做的好处是可以得到更好的图像表征信息。
Inception模块如下图所示,使用了三个不同大小的卷积核进行卷积运算,同时还有一个最大池化,然后将这4部分级联起来(拼接通道),送入下一层。

AlexNetAlexNet
使用inception的好处有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。
GoogleNet不再是像VGG和AlexNet一样增加网络深度来提升训练效果,而是通过inception来获取更多的特征来提高分类的准确度。
ResNet
正如我们之前所说的,深度越深,特征面越广,网络越复杂。根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。
这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
而ResNet就是一种非加深网络层数的一种网络,他是一种残差网络。
这里对其原理进行简述。
设求解的目标映射为H(x);
那么现在咱们将这个目标映射H(x)转换为求解网络的残差映射函数,设为F(x);
其中F(x) = H(x)-x;
所以有H(x)=F(x)+x;
那么对于目标映射H(x),对于每次计算后新得到的权重,我们只需要更改F(x)的函数值就可以了,而不是像卷积层一样在进行大量卷积。
听上去好像还是很抽象,那么我们来举个例子把。
例如现在我们的网络已经达到了最优状态,但是我们当前的层数还没有达到最后一层,再往后走可能会过拟合,造成退化问题(错误率上升),那么我们使用之前的模型解决这个问题会很麻烦,而使用残差网络ResNet就会很简单,我们只需要令F(x)=0就好啦!这样就能在最后仍能输出H(x)=x的目标映射了。
当然上面提到的只是理想情况下,咱们实际测试的时候x肯定是难以达到最优解的,但是总会到达一个无限接近于最优解的一个解,这个时候我们稍微更改一下F(x)的权重值就可以实现目的啦!
这就使得普通的卷积神经网络最多几十层,但是ResNet的深度可以轻松上百层。