数据分析:单元2 NumPy数据存取与函数
本单元的主要围绕NumPy数据存取与函数,我们会学到很多的函数,基本上都是由NumPy提供的函数,具体的内容说明我记录在了表格之中,不过代码的实例需要你自己去敲,因为我提供的是图片。
目录
内容导论
- 数据的CSV文件存取
- 多维数据的存取
- NumPy的随机数函数
- NumPy的统计函数
- Numpy的梯度函数
-
本单元总结
数据的CSV文件存取
-
CSV文件
CSV (Comma‐Separated Value, 逗号分隔值)
它是一种常见的文件格式,用来存储批量数据。
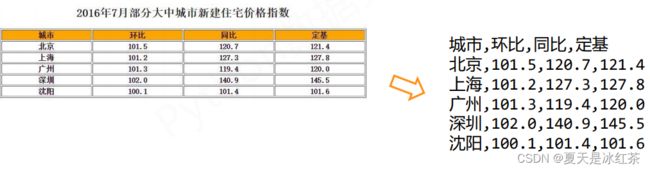
创建的方式
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
• frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件
• array : 存入文件的数组
• fmt : 写入文件的格式,例如:%d %.2f %.18e
• delimiter : 分割字符串,默认是任何空格np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
• frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件
• dtype : 数据类型,可选
• delimiter : 分割字符串,默认是任何空格
• unpack : 如果True,读入属性将分别写入不同变量实例1
实例2 
-
CSV文件的局限性
CSV只能有效存储一维和二维数据,
np.savetxt() np.loadtxt()只能有效存取一维和二维数组。
多维数据的存取
-
任意维度数据的存取
我们已经学会了一维和二维数组的存取,任意维度数据是如何存取呢?
首先,对于NumPy当中的ndarray数组,我们可以使用数组中的一个方法,如下:
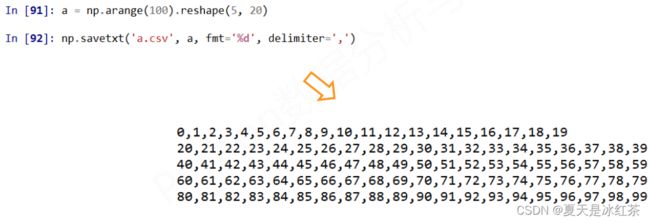
a.tofile(frame, sep='', format='%s')
• frame : 文件、字符串
• sep : 数据分割字符串,如果是空串,写入文件为二进制
• format : 写入数据的格式实例1
a.tofile(frame, sep=',', format='%s')
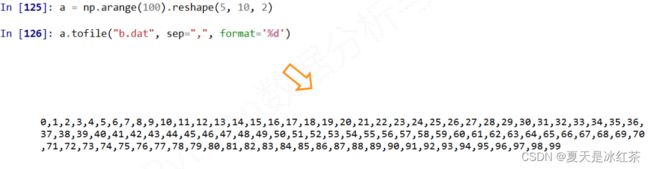
与CSV不同,这个文件并没有包含任何的维度信息。只是将数组中的所有元素逐一地列出并输出到这个文件当中
a.tofile(frame, sep='', format='%d')
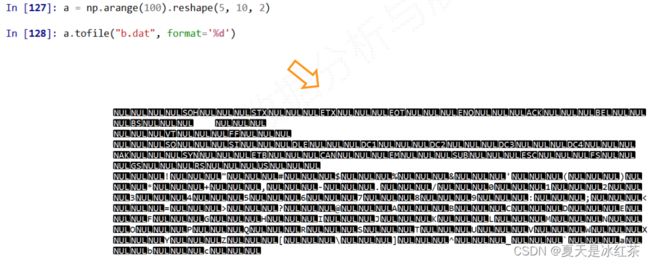
如上图,这个时候生成的文件是一个二进制格式文件,我们打开后会发现这个格式我们无法用文本编辑器看懂。事实上,二进制文件比文本文件占用更小的空间,如果知道显示字符的编码与字节之间的关系,就能理解这个问题,那么我也不在这里多做赘述。在写入二进制文件之后,由于我们看不了文件的内容,所有我们只能将它作为数据备份的一种方式。
那么如何从这样的文本文件或二进制文件中还原出这些数据呢?我们可以使用NumPy提供的函数,如下:
np.fromfile(frame, dtype=float, count=‐1, sep='')
• frame : 文件、字符串
• dtype : 读取的数据类型
• count : 读入元素个数,‐1表示读入整个文件
• sep : 数据分割字符串,如果是空串,写入文件为二进制实例2
np.fromfile(frame, dtype=float, count=‐1, sep='')

这个方法大家可以看到将数组写到文件之后,其中的维度信息丢失,那么我们必须在读入的时候知道维度信息,才能够有效地还原数组的信息。

-
需要注意
该方法需要读取时知道存入文件时的维度和元素类型,a.tofile()和np.fromfile()需要配合使用,可以通过元数据文件来存储额外信息
NumPy的便捷文件存取
p.save(fname, array) 或 np.savez(fname, array)
• fname : 文件名,以.npy为扩展名,压缩扩展名为.npz
• array : 数组变量
np.load(fname)
• fname : 文件名,以.npy为扩展名,压缩扩展名为.npz
可以在第一行看到,它把数组的语言信息,包括维度,数据类型写到了第一行中,这样在NumPy的load函数在读取这个文件时,通过解析第一行的元信息,知道这个文件中存储数据大概是什么样的一个形状和使用了什么类型,这样它就可以很有效的还原返回一个数组。对于编写程序来说,如果我们中间需要通过文件进行数据缓存,那么使用load和save方法是一个有效和快捷的方法。如果你希望存储一个文件能够与其他的程序做数据交换和对接,那么你要考虑CSV文件,或使用之前的tofile方法生成一个其他程序可以识别的文件,至于使用什么样的方法来存储和提取文件,这个需要针对不同的场景来判断。
NumPy的随机数函数
-
np.random的随机函数(1)
| 函数 | 说明 |
|---|---|
| rand(d0,d1,..,dn) | 根据d0‐dn创建随机数数组,浮点数,[0,1),均匀分布 |
| randn(d0,d1,..,dn) | 根据d0‐dn创建随机数数组,标准正态分布 |
| randint(low[,high,shape]) | 根据shape创建随机整数或整数数组,范围是[low, high) |
| seed(s) | 随机数种子,s是给定的种子值 |
实例1

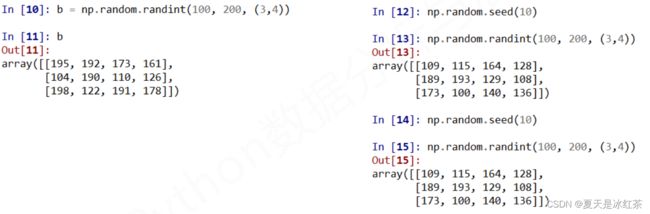
-
np.random的随机函数(2)
| 函数 | 说明 |
|---|---|
| shuffle(a) | 根据数组a的第1轴进行随排列,改变数组x |
| permutation(a) | 根据数组a的第1轴产生一个新的乱序数组,不改变数组x |
| choice(a[,size,replace,p]) | 从一维数组a中以概率p抽取元素,形成size形状新数组 replace表示是否可以重用元素,默认为False |
实例2

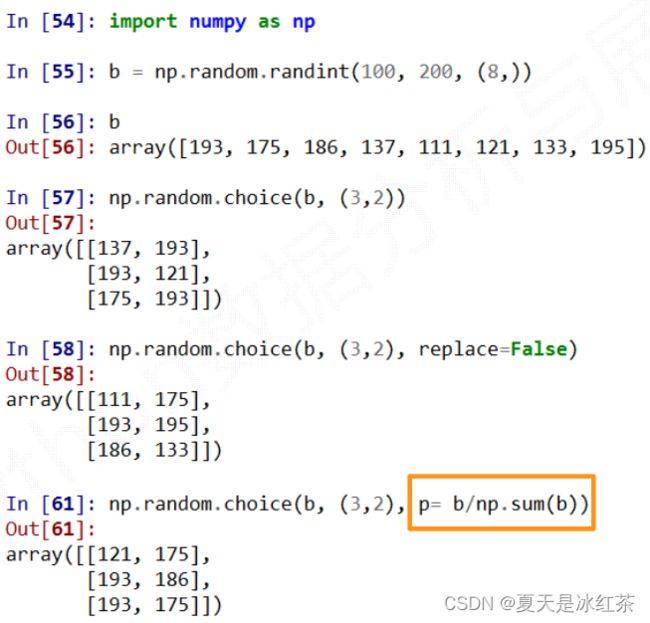
-
np.random的随机函数(3)
| 函数 | 说明 |
|---|---|
| uniform(low,high,size) | 产生具有均匀分布的数组,low起始值,high结束值,size形状 |
| normal(loc,scale,size) | 产生具有正态分布的数组,loc均值,scale标准差,size形状 |
| poisson(lam,size) | 产生具有泊松分布的数组,lam随机事件发生率,size形状 |

NumPy的统计函数
-
统计函数(1)
| 函数 | 说明 |
|---|---|
| sum(a, axis=None) | 根据给定轴axis计算数组a相关元素之和,axis整数或元组 |
| mean(a, axis=None) | 根据给定轴axis计算数组a相关元素的期望,axis整数或元组 |
| average(a,axis=None,weights=None) | 根据给定轴axis计算数组a相关元素的加权平均值 |
| std(a, axis=None) | 根据给定轴axis计算数组a相关元素的标准差 |
| var(a, axis=None) | 根据给定轴axis计算数组a相关元素的方差 |
axis=None 是统计函数的标配参数
实例1

-
统计函数(2)
| 函数 | 说明 |
|---|---|
| min(a) max(a) | 计算数组a中元素的最小值、最大值 |
| argmin(a) argmax(a) | 计算数组a中元素最小值、最大值的降一维后下标 |
| unravel_index(index, shape) | 根据shape将一维下标index转换成多维下标 |
| ptp(a) | 计算数组a中元素最大值与最小值的差,就是求极差 |
| median(a) | 计算数组a中元素的中位数(中值) |
实例2

通常,我们会将argmax与unravel_index联系在一起使用。
NumPy的梯度函数
| 函数 | 说明 |
|---|---|
| np.gradient(f) | 计算数组f中元素的梯度,当f为多维时,返回每个维度梯度 |
梯度:连续值之间的变化率,即斜率
XY坐标轴连续三个X坐标对应的Y轴值:a, b, c,其中,b的梯度是: (c‐a)/2。
实例1


本单元总结
-
CSV文件
np.loadtxt()
np.savetxt()
-
多维数据存取
a.tofile()
np.fromfile()
np.save()
np.savez()
np.load()
-
随机函数
np.random.rand() np.random.randn()
np.random.randint() np.random.seed()
np.random.shuffle() np.random.choice()
np.random.permutation()
-
NumPy的统计函数
np.sum() np.mean()
np.average() np.std()
np.var() np.median()
np.min() np.max()
np.argmin() np.argmax()
np.unravel_index() np.ptp()
-
NumPy的梯度函数
np.gradient()