【论文分享】ACL 2020 图神经网络在自然语言处理中的应用

引言

随着神经网络的不断发展,各种模型已经被广泛应用于实际应用中,这使得模型在性能上需要不断提升。本次分享我们将介绍三篇ACL的论文,对不同应用场景下的模型改进,使得模型可以更加适用于下游任务。这三篇论文分别介绍了图模型适用于inductive learning情景的改进、语言模型在数据集数量较少的情况下的模型改进,以及大型模型(如BERT)的压缩改进。
文章概览
1. Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks
图神经网络(GNN)最近被应用于文本分类。然而现有的模型既不能捕捉到每个文档中的上下文关系,也不能很好地完成新词的归纳学习。在这项工作中,作者为每个文档构建单独的图,通过TextING对文本进行归纳学习。作者在四个基准数据集上做了大量实验,实验表明此方法优于最先进的文本分类方法。
2. Few-Shot NLG with Pre-Trained Language Model
基于神经网络的自然语言生成(NLG)对数据量的需求特别大,因此在数据有限的情况下很难在实际应用中采用。在这项工作中,作者提出了一种新的few-shot的自然语言生成方法,模型体系结构的设计基于两个方面:从输入数据中选择内容和通过语言建模来构造连贯的句子,这些句子可以从先验知识中获取。通过200个跨多个领域的训练实例,证明了此方法取得了令人满意的性能。
3. DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference
大规模的预训练语言模型(如BERT)给NLP应用带来了显著的改进。然而,它们的推理速度很慢,这使得它们很难部署到应用程序中。作者提出了一种简单而有效的加速bert推理的方法:DeeBERT。此方法允许样本在不经过整个模型的情况下提前退出。实验表明,DeeBERT可以在模型质量下降最小的情况下节省40%的推理时间。
数据概览
MR:classifying moview reviews into positive or negative sentiment polarities.
R8 and R52**:classifying documents that appear on Reuters newswire into 8 and 52 categories.
Ohsumed:classifying medical abstracts into 23 cardiovascular diseases categories.
论文细节
1

动机
文本分类为其他NLP任务提供了基本的方法,如情感分析、意图检测等。传统的文本分类方法有朴素贝叶斯、k近邻和支持向量机。然而,它们主要依赖于人工制作的特征,以牺牲劳动力和效率为代价。
针对这一问题,提出了多种深度学习方法,其中递归神经网络(RNN)和卷积神经网络(CNN)是最基本的方法。然而,它们都集中在词的局部性上,因而缺乏长距离、非连续的单词交互。
近年来,基于图的方法被用来解决这一问题,它不把文本看作一个序列,而是将文本看作一组共现词。然而,这些基于图的方法有两个主要的缺点。首先,忽略了每个文档中的上下文意识单词关系。第二,由于全局结构,测试文件在训练中是必须出现的。因此,它们具有内在的转化性,很难进行归纳学习(inductive learning)。
模型
作者在本文中提出了一种基于图神经网络的文本分类方法TextING(Inductive Text Classification via Graph Neural Networks)。与以往的基于全局结构的图方法相比,作者训练了一个GNN,它只使用训练文档来描述详细的词-词关系,并在测试中推广到新的文档。在这个模型下,每一个文档都是一个独立的拓扑图,在文档级别的单词关系可以被学习到。同时这个模型也可以适用于训练过程中未出现的新单词。
模型包括三个关键部分:图形构造、基于图形的单词交互和读出功能。架构如下图所示。

(1)Graph Construction 作者使用一个长度为3的sliding windows去学习单词之间的共现关系,对于每一个文档都构造出了一个拓扑图。
(2)Graph-based Word Interaction 作者使用GGNN门控图神经网络来学习文档的词项embedding。
(3)readout function 通过两个多层感知机MLP得到一个文档上每一个节点的特征表示,然后通过这个这些节点计算出整张图的特征表示,也就是这个文档的特征表示。
作者还提出了一个模型的变体TextING-M。作者将局部图和全局图结合在一起,将他们单独训练,然后以1:1的比例来做最终预测。这个模型并不能进行归纳学习,所以作者的重点是从微观和宏观两个角度来考察二者是否可以互补。
实验
作者按照9:1的比例划分训练集和验证集。学习率是0.01,dropout是0.5,初始的单词特征表示用的是维度为300的GloVe。为了公平比较,其他基线模型共享相同的嵌入,实验的结果见下表。

数值是分类的准确率accuracy,作者做了十次实验,正负是这些实验的上下波动情况。可以看出每一个任务中,TextING都是结果最好的。其中在MR任务中,TextING的效果是比TextGCN好最多的,是因为在MR中,这些评论都是短文本,导致了textGCN中的低密度图,它限制了文档节点之间的标签消息的传递,但是TextING的单个图不依赖于这种标签消息传递机制。
2

动机
最近有很多神经网络模型应用到的NLP任务中,这种基于神经网络的系统大大减少了特征工程的工作量,提高了文本的多样性和流畅性。
但是基于神经网络的NLP任务也是有缺点的,就是需要大量的训练数据集,同时训练出来的也是在某个特定的领域中很强大的语言模型,但是在少量的样本情况few-shot下表现很差,这使得这些模型很难应用到现实中去。
模型
本文模型的encoder是沿用了seq2seq的encoder,不同的是模型的输入是word embedding和field embedding的信息结合。除此之外作者加入了Switch Policy和Pre-Trained Language Model。模型结构如下图。

(1)Switch Policy 作者创建了一个Pcopy来判断生成的词是从原来的数据数据表中直接选择复制还是从词表vocabulary中生成新的词。Pcopy的计算方法如下,其中ct是注意力模型中的ct,也就是at乘ht的求和。St是t时刻的状态,Xt是decoder的输入,Wc, Ws, Wx, b是可训练参数。
为了让使模型更加清楚哪些是需要从原始数据数据表中复制的,对于decoder的输出,如果在原始的数据表中可以找到,就将之与输入匹配,并且通过更新Loss函数将对应的Pcopy最大化。
(2)Pre-Trained Language Model 作者不仅使用了预训练的word embedding,也使用了Pre-Trained Language Models作为先天的语言技巧。使用的是12层的transformer结构GPT-2。
实验
本次实验的数据集包括wikibio的人物传记数据集、wikipedia爬取的books数据集和songs数据集。
训练集作者分别选取了20,100,200和500的样本数,剩下的数据用于验证集和测试集。实验的结果如下。
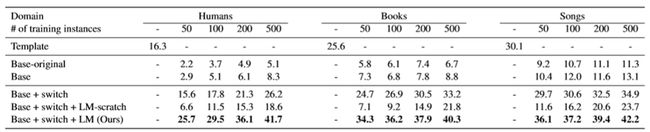
使用的指标是BLUE。Template是非神经网络方法;Base-original是Table-to-text generation by structure-aware seq2seq learning(Liu et al., 2018)中的模型;Base是加入了预训练的word embedding;Base+switch是加了switch策略;Base+switch+LM-scratch的整体结构是一样的,但是LM是空模型,没有预训练的权重;Base+switch+LM(Ours)是加入了已经训练好的权重的pre-trained LM,也就是GPT-2。
可以看出,原来文章中的模型在few-shot情况下的表现很差,第一次性能的明显增强是加入了switch策略,带来了10个BLUE的增加。当加入了pre-trained model之后又带了一次大的提升。
从这篇文章中,我们了解到了通过引入pre-trained model作为一个先天语言技巧,可以用少量的样本得到很好的效果,也可以更好地应用到现实任务中去。
3

动机
大规模的预训练语言模型(如BERT)给NLP应用带来了显著的改进。然而,它们的推理速度很慢,这使得它们很难部署到应用程序中,所以需要对模型进行压缩加速。
模型
作者考虑到,在深层次的模型中,较高的层会包含更多的信息,所以也许较高层的transformer层已经足够对得出任务的结果并进行输出了。模型的结构如下图。

灰色部分就是原来的BERT中的组成单元transformer,黄色部门就是本文中新添加的部分,用来判断是否可以提前退出模型的板块,作者称之为off-ramps。蓝色的向下线条代表提前退出了BERT模型。
此文的重点是off-ramps模块,它是接在tranformer模块之后,当样本输出tranformer之后,就会进入off-ramps层。如果off-ramps的模块已经足够对结果做出判断,那么就直接返回off-ramps的输出作为最终的结果,第i层的off-ramp层的损失函数如下图。
(1)fine-turning 首先按照Ln也就是最后一个off-ramp层的损失函数作为整体的损失函数,按照正常BERT训练,更新embedding层(BERT中初始输入是由token embedding、segment embedding和position embedding加总而成的)、所有的transformer 层和最后一个off-ramp层的参数。然后冻结第一步训练出来的所有参数,通过1到n-1层的off-ramp层的损失函数的和作为新的损失函数来更新1到n-1层的off-ramp层的参数。这里冻结的原因是因为要保持原来的transformer结构可以有最优的输出。(2)inference 对于每一个off-ramp层的输出,都是经过softmax得到每一个类别的概率分布Z。我们对这个概率分布求熵(熵代表输出的混杂度,越小代表输出的类别信息越清晰),将这个熵与预先设置好的阈值S作比较,如果小于S则直接作为结果输出,如果不满足则进入下一个transformer来进行学习。
实验
作者将DeeBERT运用到了BERT和RoBERTa中去,使用了六个数据集:SST-2, MRPC, QNLI, RTE, QQP, MNLI。结果如下图。
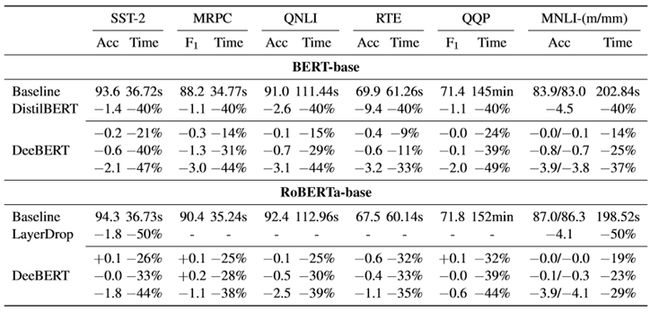
distillBERT是BERT蒸馏,LayerDrop是模型层剪枝。可以看出,与模型蒸馏不同的是,DeeBERT可以根据需求来调节模型的quality和efficiency。但是并不能说在所有情况下,DeeBERT都比baselines好,比如在MRPC数据集上就不如DistillBERT。
作者还分析了不同的阈值S对模型的影响,如下图。
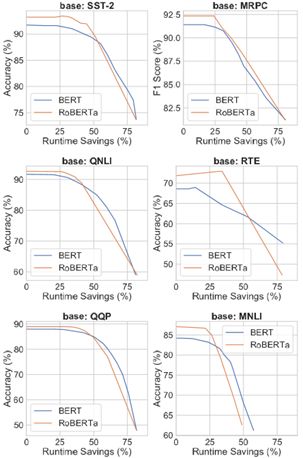
S越大,模型越快但是准确度越低,S越小,模型越慢但是准确度越高。图中蓝色的是将DeeBERT应用于BERT上,黄色的是应用与RoBERTa上。可以看出在一开始accuracy几乎保持不变,但是到了某一个点后开始锐减,这也启发我们选取拐点的S。
同时我们也发现有的曲线会有峰值,如RTE数据集中。作者解释是因为在某些情况下,用BERT全部的transformer不如只应用其中的一部分。
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!



后台回复【五件套】
下载二:南大模式识别PPT

后台回复【南大模式识别】
参考文献
Ion Androutsopoulos, John Koutsias, Konstantinos V Chandrinos, George Paliouras, and Constantine D Spyropoulos. 2000. An evaluation of naive bayesian anti-spam filtering. arXiv preprint cs/0006013.
Roi Blanco and Christina Lioma. 2012. Graph-based term weighting for information retrieval. Information retrieval.
Alison J Cawsey, Bonnie L Webber, and Ray B Jones. 1997. Natural language generation in health care.
Tianyu Liu, Kexiang Wang, Lei Sha, Baobao Chang, and Zhifang Sui. 2018. Table-to-text generation by structure-aware seq2seq learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative ApplicationsofArtificialIntelligence(IAAI-18),and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, pages 4881– 4888.
B. Barla Cambazoglu, Hugo Zaragoza, Olivier Chapelle, Jiang Chen, Ciya Liao, Zhaohui Zheng, and Jon Degenhardt. 2010. Early exit optimizations for additive machine learned ranking systems. In Proceedings of the Third ACM International Conference on Web Search and Data Mining (WSDM 2010), pages 411–420, New York, New York.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota.
供稿人:李寅子丨研究生一年级丨研究方向:多模态与机器学习丨邮箱:[email protected]
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读
专辑 | 情感分析
整理不易,还望给个在看!