uboot源码分析(基于S5PV210)之uboot的命令体系与环境变量
目录
-
- 4、命令参数以argc&argv传给函数
- 二、uboot命令解析和执行过程分析
-
- 1、从main_loop说起(main.c中)
- 2、run_command函数详解
- 3、关键点分析
- 三、uboot如何处理命令集
-
- 1、可能的管理方式
- 2、命令结构体cmd_tbl_t
- 3、uboot实现命令管理的思路
- 4、uboot命令定义具体实现分析
- 5、find_cmd函数详解
- 6、U_BOOT_CMD宏详解
- 四、uboot中增加自定义命令
-
- 1、在已有的c文件中直接添加命令
- 2、自建一个c文件并添加命令
- 3、体会:uboot命令体系的优点
- 五、uboot的环境变量基础
-
- 1、环境变量的作用
- 2、环境变量的优先级
- 3、环境变量在uboot中工作方式
- 六、环境变量相关命令源码解析
-
- 1、printenv
- 2、setenv
- 3、saveenv
- 七、uboot内部获取环境变量
-
- 1、getenv
- 2、getenv_r
- 3、总结
在实际的项目开发中,我们经常需要添加自己的uboot命令和环境变量实现定制化的产品,故而了解二者在uboot中的工作机制很重要,本篇文章将针对这两方面的知识进行介绍,希望能给大家带来一定的帮助!
# 一、uboot命令体系基础 ## 1、使用uboot命令 uboot启动后进入命令行环境下,在此输入命令按回车结束,uboot会收取这个命令然后解析,然后执行,处于一个死循环的过程,要想跳出整个死循环,就需要执行bootm命令启动内核。 ## 2、uboot命令体系实现代码在哪里 uboot命令体系的实现代码在uboot/common/cmd_xxx.c中。有若干个.c文件和命令体系有关。(还有command.c 、main.c也是和命令有关的)  ## 3、每个命令对应一个函数 (1)每一个uboot的命令背后都对应一个函数。这就是uboot实现命令体系的一种思路和方法。
(2)我们要找到每一个命令背后所对应的那个函数,而且要分析这个函数和这个命令是怎样对应起来的。(通过函数指针)
4、命令参数以argc&argv传给函数
(1)有些uboot的命令还支持传递参数。也就是说命令背后对应的函数接收的参数列表中有argc和argv,然后命令体系会把我们执行命令时的 命令 + 参数以argc和argv的方式传递给执行命令的函数。
md 30000000 10
argv[0]=md, argv[1]=30000000 argv[2]=10
举例分析,以help命令为例:
help命令背后对应的函数名叫:do_help,在uboot/common/command.c的236行
int do_help (cmd_tbl_t * cmdtp, int flag, int argc, char *argv[])
cmd_tbl_t * cmdtp 命令相关的数据结构,重点关注int argc, char *argv[]
struct cmd_tbl_s {
char *name; /* Command Name */
int maxargs; /* maximum number of arguments */
int repeatable; /* autorepeat allowed?为1时当无命令输入时,自动重复上一个命令,为0则关闭 */
/* Implementation function */
int (*cmd)(struct cmd_tbl_s *, int, int, char *[]);//定义了一个函数指针类型
char *usage; /* Usage message (short) */
#ifdef CFG_LONGHELP
char *help; /* Help message (long) */
#endif
#ifdef CONFIG_AUTO_COMPLETE
/* do auto completion on the arguments */
int (*complete)(int argc, char *argv[], char last_char, int maxv, char *cmdv[]);
#endif
};
typedef struct cmd_tbl_s cmd_tbl_t;
二、uboot命令解析和执行过程分析
1、从main_loop说起(main.c中)
(1)uboot启动的第二阶段,在初始化了所有该初始化的东西后,进入了一个死循环,死循环的循环体就是main_loop。
(2)main_loop函数执行一遍,就是一个获取命令、解析命令、执行命令的过程。
#ifndef CFG_HUSH_PARSER
run_command (p, 0);//执行命令的函数
#else
parse_string_outer(p, FLAG_PARSE_SEMICOLON |
FLAG_EXIT_FROM_LOOP);//解析字符串
#endif
(3)run_command/parse_string_outer函数是两种用来执行命令的函数。可选用其中一种进行命令处理工作。
参考学习:https://blog.csdn.net/yakehy/article/details/39318299
parse_string_outer内部的函数通过一层层调用,最终会去执行run_list_real函数
2、run_command函数详解
/****************************************************************************
* returns:
* 1 - command executed, repeatable
* 0 - command executed but not repeatable, interrupted commands are
* always considered not repeatable
* -1 - not executed (unrecognized, bootd recursion or too many args)
* (If cmd is NULL or "" or longer than CFG_CBSIZE-1 it is
* considered unrecognized)
*
* WARNING:
*
* We must create a temporary copy of the command since the command we get
* may be the result from getenv(), which returns a pointer directly to
* the environment data, which may change magicly when the command we run
* creates or modifies environment variables (like "bootp" does).
*/
int run_command (const char *cmd, int flag)
{
cmd_tbl_t *cmdtp;
char cmdbuf[CFG_CBSIZE]; /* working copy of cmd */
char *token; /* start of token in cmdbuf */
char *sep; /* end of token (separator) in cmdbuf */
char finaltoken[CFG_CBSIZE];
char *str = cmdbuf;
char *argv[CFG_MAXARGS + 1]; /* NULL terminated */
int argc, inquotes;
int repeatable = 1;
int rc = 0;
#ifdef DEBUG_PARSER
printf ("[RUN_COMMAND] cmd[%p]=\"", cmd);
puts (cmd ? cmd : "NULL"); /* use puts - string may be loooong */
puts ("\"\n");
#endif
clear_ctrlc(); /* forget any previous Control C */
if (!cmd || !*cmd) {
return -1; /* empty command */
}
if (strlen(cmd) >= CFG_CBSIZE) {//CFG_CBSIZE,规定命令码的长度
puts ("## Command too long!\n");
return -1;
}
strcpy (cmdbuf, cmd);
/* Process separators and check for invalid
* repeatable commands
*/
#ifdef DEBUG_PARSER
printf ("[PROCESS_SEPARATORS] %s\n", cmd);
#endif
while (*str) {
/*
* Find separator, or string end
* Allow simple escape of ';' by writing "\;"
*/
for (inquotes = 0, sep = str; *sep; sep++) {
if ((*sep=='\'') &&
(*(sep-1) != '\\'))
inquotes=!inquotes;
if (!inquotes &&
(*sep == ';') && /* separator */
( sep != str) && /* past string start */
(*(sep-1) != '\\')) /* and NOT escaped */
break;
}
/*
* Limit the token to data between separators
*/
token = str;
if (*sep) {
str = sep + 1; /* start of command for next pass */
*sep = '\0';
}
else
str = sep; /* no more commands for next pass */
#ifdef DEBUG_PARSER
printf ("token: \"%s\"\n", token);
#endif
/* find macros in this token and replace them */
process_macros (token, finaltoken);
/* Extract arguments */
if ((argc = parse_line (finaltoken, argv)) == 0) {
rc = -1; /* no command at all */
continue;
}
/* Look up command in command table */
if ((cmdtp = find_cmd(argv[0])) == NULL) {//cmdtp结构体记录了命令的相关属性及信息
printf ("Unknown command '%s' - try 'help'\n", argv[0]);
rc = -1; /* give up after bad command */
continue;
}
/* found - check max args */
if (argc > cmdtp->maxargs) {//传的参数过多则会打印使用说明
printf ("Usage:\n%s\n", cmdtp->usage);//段说明
rc = -1;
continue;
}
#if defined(CONFIG_CMD_BOOTD)
/* avoid "bootd" recursion */
if (cmdtp->cmd == do_bootd) {
#ifdef DEBUG_PARSER
printf ("[%s]\n", finaltoken);
#endif
if (flag & CMD_FLAG_BOOTD) {
puts ("'bootd' recursion detected\n");
rc = -1;
continue;
} else {
flag |= CMD_FLAG_BOOTD;
}
}
#endif
/* OK - call function to do the command */
if ((cmdtp->cmd) (cmdtp, flag, argc, argv) != 0) {//调用函数指针cmdtp->cmd执行命令
rc = -1;
}
repeatable &= cmdtp->repeatable;
/* Did the user stop this? */
if (had_ctrlc ())
return -1; /* if stopped then not repeatable */
}
return rc ? rc : repeatable;
}
3、关键点分析
(1)控制台命令获取 (main.c453-459行或439-440行)

(2)命令解析。parse_line函数把"md 30000000 10"解析成argv[0]=md, argv[1]=30000000 argv[2]=10;
(3)run_command 函数中在命令集中查找命令。find_cmd(argv[0])函数去uboot的命令集合当中搜索有没有argv[0]这个命令,
(4)run_command 函数中执行命令。最后用函数指针的方式调用执行了对应函数。
思考:关键点就在于find_cmd函数如何查找到这个命令是不是uboot的合法支持的命令?
这取决于uboot的命令体系机制(uboot是如何完成命令的这一套设计的,命令如何去注册、存储、管理、索引)。
三、uboot如何处理命令集
1、可能的管理方式
(1)数组。结构体数组,数组中每一个结构体成员就是一个命令的所有信息。但大小是固定的
(2)链表。链表的每个节点data段就是一个命令结构体,所有的命令都放在一条链表上。这样就解决了数组方式的不灵活。坏处是需要额外的内存开销,然后各种算法(遍历、插入、删除等)需要一定复杂度的代码执行。
(3)有第三种吗?uboot没有使用数组或者链表,而是使用了一种新的方式来实现这个功能,欲知答案继续向下看。
2、命令结构体cmd_tbl_t
struct cmd_tbl_s {
char *name; /* Command Name */
int maxargs; /* maximum number of arguments */
int repeatable; /* autorepeat allowed? */
/* Implementation function */
int (*cmd)(struct cmd_tbl_s *, int, int, char *[]);
char *usage; /* Usage message (short) */
#ifdef CFG_LONGHELP
char *help; /* Help message (long) */
#endif
#ifdef CONFIG_AUTO_COMPLETE
/* do auto completion on the arguments */
int (*complete)(int argc, char *argv[], char last_char, int maxv, char *cmdv[]);
#endif
};
typedef struct cmd_tbl_s cmd_tbl_t;
(1)name:命令名称,字符串格式。
(2)maxargs:命令最多可以接收多少个参数
(3)repeatable:指示这个命令是否可重复执行。重复执行是uboot命令行的一种工作机制,就是直接按回车则执行上一条执行的命令。
(4)cmd:函数指针,命令对应的函数的函数指针,将来执行这个命令的函数时使用这个函数指针来调用。初始化这个结构体时让其指向真正对应的哪个函数
(5)usage:命令的短帮助信息。对命令的简单描述。
(6)help:命令的长帮助信息。细节的帮助信息。
(7)complete:函数指针,指向这个命令的自动补全的函数。
uboot的命令体系在工作时,一个命令对应一个cmd_tbl_t结构体的一个实例,然后uboot支持多少个命令,就需要多少个结构体实例。uboot的命令体系把这些结构体实例管理起来,当用户输入了一个命令时,uboot会去这些结构体实例中查找(查找方法和存储管理的方法有关)。如果找到则执行命令,如果未找到则提示命令未知。
3、uboot实现命令管理的思路
(1)填充1个结构体实例构成一个命令
(2)给命令结构体实例附加特定段属性(用户自定义段,不是代码段也不是数据段),链接时将带有该 段属性的内容链接在一起排列(挨着的,不会夹杂其他东西,也不会丢掉一个带有这种段属性的,但是顺序是乱序的)。

(3)uboot重定位时将uboot镜像中加载到DDR中。加载到DDR中的uboot镜像中带有特定段属性的这一段其实就是命令结构体的集合,有点像一个命令结构体数组。可使用类似遍历数组的方式遍历这些命令,以数组去理解
(4)段起始地址和结束地址(链接地址、定义在u-boot.lds中)决定了这些命令集的开始和结束地址。
__u_boot_cmd_start = .;//自定义的段,起始地址
.u_boot_cmd : { *(.u_boot_cmd) }
__u_boot_cmd_end = .;//结束地址
当初写uboot时,他的大小就确定好,当时想好设计好了,所以不需要使用链表进行动态添加,而且链表效率也比较低一些。
4、uboot命令定义具体实现分析
命令举例:version命令(command.c中33行开始的do_version函数)
(1)U_BOOT_CMD宏基本分析
#define U_BOOT_CMD(name,maxargs,rep,cmd,usage,help) \
cmd_tbl_t __u_boot_cmd_##name Struct_Section = {#name, maxargs, rep, cmd, usage, help}
#define Struct_Section __attribute__ ((unused,section (".u_boot_cmd")))
这个宏定义在uboot/common/command.h中。
U_BOOT_CMD(
version, 1, 1, do_version,
"version - print monitor version\n",
NULL
);
这个宏替换后变成:
cmd_tbl_t __u_boot_cmd_version __attribute__ ((unused,section (".u_boot_cmd"))) = {#name, maxargs, rep, cmd, usage, help}
__attribute__ :gcc扩展语法,用于给前边这个变量cmd_tbl_t __u_boot_cmd_version
赋予一个段属性,贴一个标签(.u_boot_cmd,类似于.text,.data),将其放在
.u_boot_cmd这个自定义段中
#name:#的作用是让version变成字符串“version”,可以赋值给cmd_tbl_t __u_boot_cmd_version成员字符串name
这个U_BOOT_CMD宏的理解,关键在于结构体变量的名字和段属性。名字使用##作为连字符(##name会被所传的name替换,保证了变量不会重名,uboot中不允许出现两个名字一样的命令,即使参数不同也不可以),附加了用户自定义段属性,以保证链接时将这些数据结构链接在一起排布。
每个命令对应的函数后,都有一个这样的宏
5、find_cmd函数详解
(1)find_cmd函数的任务是从当前uboot的命令集中查找是否有某个命令。如果找到则返回这个命令结构体的指针,如果未找到返回NULL。
(2)函数的实现思路很简单,如果不考虑命令带点的情况(md.b md.w这种)就更简单了。查找命令的思路其实就是for循环遍历数组的思路,不同的是数组的起始地址和结束地址是用地址值来给定的,数组中的元素个数是结构体变量类型。
6、U_BOOT_CMD宏详解
这个宏其实就是定义了一个命令对应的结构体变量,这个变量名和宏的第一个参数有关,因此只要宏调用时传参的第一个参数不同则定义的结构体变量不会重名。
四、uboot中增加自定义命令
1、在已有的c文件中直接添加命令
(1)在uboot/common/command.c中添加一个命令,比如叫:mycmd
(2)在已有的.c文件中添加命令比较简单,直接使用U_BOOT_CMD宏即可添加命令,给命令提供一个do_xxx的对应的函数这个命令就齐活了。
(3)添加完成后要重新编译工程(make distclean; make x210_sd_config; make),然后烧录新的uboot去运行即可体验新命令。
(4)还可以在函数中使用argc和argv来验证传参。
2、自建一个c文件并添加命令
(1)在uboot/common目录下新建一个命令文件,叫cmd_aston.c(对应的命令名就叫aston,对应的函数就叫do_aston函数),然后在c文件中添加命令对应的U_BOOT_CMD宏和函数。注意头文件包含不要漏掉。
do_aston函数中做的事情就是aston命令要完成的事情,根据自己的实际需求完成相应的功能。
(2)在uboot/common/Makefile中添加上aston.o,目的是让Make在编译时能否把cmd_aston.c编译链接进去。
(3)重新编译烧录。重新编译步骤是:make distclean; make x210_sd_config; make
3、体会:uboot命令体系的优点
(1)uboot的命令体系本身稍微复杂,但是他写好之后就不用动了。我们在移植uboot时也不会去动uboot的命令体系。我们最多就是向uboot中去添加命令。
(2)向uboot中添加命令非常简单。
五、uboot的环境变量基础
1、环境变量的作用
让我们可以不用修改uboot的源代码,而是通过修改环境变量来影响uboot运行时的一些数据和特性。譬如说通过修改bootdelay环境变量就可以更改系统开机自动启动时倒数的秒数。
2、环境变量的优先级
(1)uboot代码当中有一个环境变量的值,环境变量分区中也有一个值。uboot程序实际运行时规则是:如果环境变量分区为空则使用代码中的值;如果环境变量分区不为空则优先使用环境变量分区中对应的值。
(2)譬如machid(机器码)。uboot中在x210_sd.h中定义了一个机器码2456,写死在程序中的不能更改。如果要修改uboot中配置的机器码,可以修改x210_sd.h中的机器码,但是修改源代码后需要重新编译烧录,很麻烦;比较简单的方法就是使用环境变量machid。set machid 0x998类似这样,有了machid环境变量后,系统启动时会优先使用machid对应的环境变量,这就是优先级问题。
3、环境变量在uboot中工作方式
(1)默认环境变量,在uboot/common/env_common.c中default_environment,这东西本质是一个字符数组,大小为CFG_ENV_SIZE(16KB),里面内容就是很多个环境变量连续分布组成的,每个环境变量最末端以’\0’结束。
(2)SD卡中环境变量分区,在uboot的raw分区中。SD卡中其实就是给了个分区,专门用来存储而已。存储时其实是把DDR中的环境变量整体的写入SD卡中分区里。所以当我们saveenv时其实整个所有的环境变量都被保存了一遍,而不是只保存更改了的。
(3)DDR中环境变量,在default_environment中,实质是字符数组。在uboot中其实是一个全局变量,链接时在数据段,重定位时default_environment就被重定位到DDR中一个内存地址处了。这个地址处这个全局字符数组就是我们uboot运行时的DDR中的环境变量了。
总结:刚烧录的系统中环境变量分区是空白的,uboot第一次运行时加载的是uboot代码中自带的一份环境变量,叫默认环境变量。我们在saveenv时DDR中的环境变量会被更新到SD卡中的环境变量中,就可以被保存下来,下次开机会在环境变量relocate时会SD卡中的环境变量会被加载到DDR中去。
default_environment中的内容虽然被uboot源代码初始化为一定的值(这个值就是我们的默认环境变量),但是在uboot启动的第二阶段,env_relocate时代码会去判断SD卡中的env分区的crc是否通过。如果crc校验通过说明SD卡中有正确的环境变量存储,则relocate函数会从SD卡中读取环境变量来覆盖default_environment字符数组,从而每次开机可以保持上一次更改过的环境变量。
六、环境变量相关命令源码解析
以下三个函数均在:uboot/common/cmd_nvedit.c中
1、printenv
(1)找到printenv命令所对应的函数。通过printenv的help可以看出,这个命令有2种使用方法。第一种直接使用不加参数则打印所有的环境变量;第二种是printenv name则只打印出name这个环境变量的值。
(2)分析do_printenv函数。
/************************************************************************
* Command interface: print one or all environment variables
*/
int do_printenv (cmd_tbl_t *cmdtp, int flag, int argc, char *argv[])
{
int i, j, k, nxt;
int rcode = 0;
if (argc == 1) { /* Print all env variables */
for (i=0; env_get_char(i) != '\0'; i=nxt+1) {//i=nxt+1跳过了env_get_char(nxt) = '\0'
for (nxt=i; env_get_char(nxt) != '\0'; ++nxt)//确定命令在数组的的开始结束序号
;
for (k=i; k<nxt; ++k)//打印出命令
putc(env_get_char(k));
putc ('\n');
if (ctrlc()) {//用户可使用ctrl C随时终止
puts ("\n ** Abort\n");
return 1;
}
}
printf("\nEnvironment size: %d/%ld bytes\n",
i, (ulong)ENV_SIZE);
return 0;
}
for (i=1; i<argc; ++i) { /* print single env variables */
char *name = argv[i];
k = -1;
for (j=0; env_get_char(j) != '\0'; j=nxt+1) {
for (nxt=j; env_get_char(nxt) != '\0'; ++nxt)
;
k = envmatch((uchar *)name, j);
if (k < 0) {
continue;
}
puts (name);
putc ('=');
while (k < nxt)
putc(env_get_char(k++));
putc ('\n');
break;
}
if (k < 0) {
printf ("## Error: \"%s\" not defined\n", name);
rcode ++;
}
}
return rcode;
}
uchar env_get_char_memory (int index)
{
if (gd->env_valid) {
return ( *((uchar *)(gd->env_addr + index)) );//这个与else下的那个效果是相同的
} else { //都是返回环境变量数组中的元素,在env_init()函数中
return ( default_environment[index] );//有赋值,start_armboot()中调用过该函数
}
}
uchar env_get_char (int index)//在存放环境变量的数组中查找第I个元素等不等于'\0'
{
uchar c;
/* if relocated to RAM */
if (gd->flags & GD_FLG_RELOC)//default environment是否被加载到DDR中
c = env_get_char_memory(index);//故而使用这个
else
c = env_get_char_init(index);//让内存那份环境变量有效,我们工作时DDR中的环境变量一直有效
return (c);
}
(3)do_printenv函数首先区分argc=1还是不等于1的情况,若argc=1那么就循环打印所有的环境变量出来;如果argc不等于1,则后面的参数就是要打印的环境变量,给哪 个就打印哪个。
(4)argc=1时用双重for循环来依次处理所有的环境变量的打印。第一重for循环就是处理各个环境变量。所以有多少个环境变量则第一重就执行循环多少圈。
(5)这个函数要看懂,首先要明白整个环境变量在内存中如何存储的问题。
(6)关键点:第一要明白环境变量在内存中存储的方式;第二要C语言处理字符串的功底要好。
2、setenv
(1)命令定义和对应的函数在uboot/common/cmd_nvedit.c中,对应的函数为do_setenv。

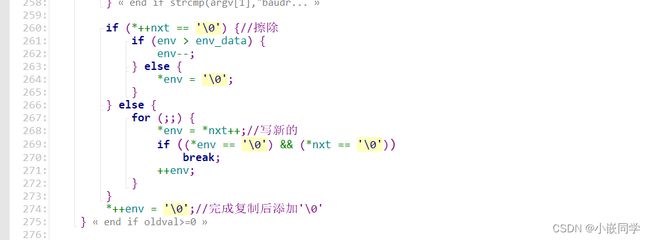
(2)setenv的思路就是:先去DDR中的环境变量处寻找原来有没有这个环境变量,如果原来就有则需要覆盖原来的环境变量,如果原来没有则在最后新增一个环境变量即可。
第1步:遍历DDR中环境变量的数组,找到原来就有的那个环境变量对应的地址。168-174行。
第2步:擦除原来的环境变量,259-265行
第3步:写入新的环境变量,266-273行。
(3)本来setenv做完上面的就完了,但是还要考虑一些附加的问题。
问题一:环境变量太多超出DDR中的字符数组,溢出的解决方法。
问题二:有些环境变量如baudrate、ipaddr等,在gd中有对应的全局变量。这种环境变量
在set更新的时候要同时去更新对应的全局变量,否则就会出现在本次运行中环境变量和全
局变量不一致的情况。
3、saveenv
(1)在uboot/common/cmd_nvedit.c中,对应函数为do_saveenv
int do_saveenv (cmd_tbl_t *cmdtp, int flag, int argc, char *argv[])
{
extern char * env_name_spec;
printf ("Saving Environment to %s...\n", env_name_spec);
return (saveenv() ? 1 : 0);
}
env_auto.c文件:
char * env_name_spec = "SMDK bootable device";
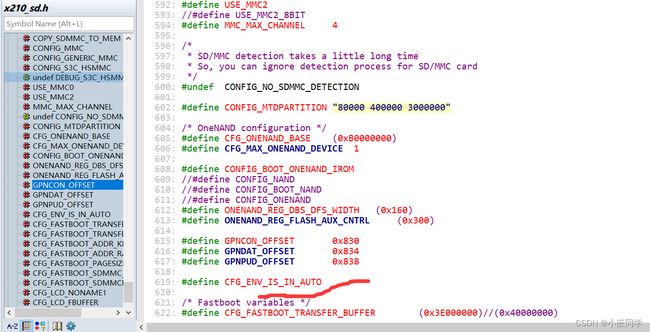
(2)从uboot实际执行saveenv命令的输出,和x210_sd.h中的配置(#define CFG_ENV_IS_IN_AUTO)可以分析出:我们实际使用的是env_auto.c中相关的内容。
没有一种芯片叫auto的,env_auto.c中是使用宏定义的方式去条件编译了各种常见的flash芯片(如movinand、norflash、nand等)。然后在程序中读取INF_REG(OMpin内部对应的寄存器)从而知道我们的启动介质,然后调用这种启动介质对应的操作函数来操作。
int saveenv(void)
{
#if defined(CONFIG_S5PC100) || defined(CONFIG_S5PC110) || defined(CONFIG_S5P6442)
if (INF_REG3_REG == 2)
saveenv_nand();
else if (INF_REG3_REG == 3)
saveenv_movinand();
else if (INF_REG3_REG == 1)
saveenv_onenand();
else if (INF_REG3_REG == 4)
saveenv_nor();
#elif defined(CONFIG_SMDK6440)
if (INF_REG3_REG == 3)
saveenv_nand();
else if (INF_REG3_REG == 4 || INF_REG3_REG == 5 || INF_REG3_REG == 6)
saveenv_nand_adv();
else if (INF_REG3_REG == 0 || INF_REG3_REG == 1 || INF_REG3_REG == 7)
saveenv_movinand();
#else // others
if (INF_REG3_REG == 2 || INF_REG3_REG == 3)
saveenv_nand();
else if (INF_REG3_REG == 4 || INF_REG3_REG == 5 || INF_REG3_REG == 6)
saveenv_nand_adv();
else if (INF_REG3_REG == 0 || INF_REG3_REG == 7)
saveenv_movinand();
else if (INF_REG3_REG == 1)
saveenv_onenand();
#endif
else
printf("Unknown boot device\n");
return 0;
}
s5pc110.h文件:
#define INF_REG3_REG __REG(INF_REG_BASE+INF_REG3_OFFSET)
#define INF_REG_BASE 0xE010F000
#define INF_REG3_OFFSET 0x0c
(3)do_saveenv内部调用env_auto.c中的saveenv函数来执行实际的环境变量保存操作。
(4)寄存器地址:E010F000+0C=E010_F00C,含义是用户自定义数据。
我们在之前的文章有讲过:start.S(259-260行,277-278行)中判断启动介质后将#BOOT_MMCSD(就是3,定义在x210_sd.h)写入了这个寄存器,所以这里读出的肯定是3,经过判断就是movinand。所以实际执行的函数是:saveenv_movinand
int saveenv_movinand(void)
{
#if defined(CONFIG_CMD_MOVINAND)//virt_to_phys,虚拟地址映射到物理地址,虚拟地址转换为物理地址
movi_write_env(virt_to_phys((ulong)env_ptr));//真正的写的命令,将环境变量写入inand
puts("done\n");//打印信息,表示保存完毕
return 1;
#else
return 0;
#endif /* CONFIG_CMD_MOVINAND */
}
(5)真正执行保存环境变量操作的是:cpu/s5pc11x/movi.c中的movi_write_env函数,这个函数肯定是写sd卡,将DDR中的环境变量数组(其实就是default_environment这个数组,大小16KB,刚好32个扇区)写入iNand中的ENV分区中。
void movi_write_env(ulong addr)
{
movi_write(raw_area_control.image[2].start_blk,//所传参数开始地址,扇区数,源
raw_area_control.image[2].used_blk, addr);
}
raw_area_t raw_area_control;
/*
* magic_number: 0x24564236
* start_blk: start block number for raw area
* total_blk: total block number of card
* next_raw_area: add next raw_area structure
* description: description for raw_area
* image: several image that is controlled by raw_area structure
* by scsuh
*/
typedef struct raw_area {
uint magic_number; /* to identify itself */
uint start_blk; /* compare with PT on coherency test */
uint total_blk;
uint next_raw_area; /* should be sector number */
char description[16];
member_t image[15];
} raw_area_t; /* 512 bytes */
(6)raw_area_control是uboot中规划iNnad/SD卡的原始分区表,这个里面记录了我们对iNand的分区,env分区也在这里,下标是2,追到这一层(movi_write()函数)就够了,再里面就是调用驱动部分的写SD卡/iNand的底层函数了。
(7)如果想要了解uboot中规划iNnad/SD卡的原始分区表,应该去研究这个函数:
uboot/common/cmd_movi.c
int init_raw_area_table (block_dev_desc_t * dev_desc)
{
struct mmc *host = find_mmc_device(dev_desc->dev);
/* when last block does not have raw_area definition. */
if (raw_area_control.magic_number != MAGIC_NUMBER_MOVI) {
int i = 0;
member_t *image;
u32 capacity;
if (host->high_capacity) {
capacity = host->capacity;
#ifdef CONFIG_S3C6410
if(IS_SD(host))
capacity -= 1024;
#endif
} else {
capacity = host->capacity;
}
dev_desc->block_read(dev_desc->dev,
capacity - (eFUSE_SIZE/MOVI_BLKSIZE) - 1,
1, &raw_area_control);
if (raw_area_control.magic_number == MAGIC_NUMBER_MOVI) {
return 0;
}
dbg("Warning: cannot find the raw area table(%p) %08x\n",
&raw_area_control, raw_area_control.magic_number);
/* add magic number */
raw_area_control.magic_number = MAGIC_NUMBER_MOVI;
/* init raw_area will be 16MB */
raw_area_control.start_blk = 16*1024*1024/MOVI_BLKSIZE;
raw_area_control.total_blk = capacity;
raw_area_control.next_raw_area = 0;
strcpy(raw_area_control.description, "initial raw table");
image = raw_area_control.image;
#if defined(CONFIG_EVT1)
#if defined(CONFIG_FUSED)
/* image 0 should be fwbl1 */
image[0].start_blk = (eFUSE_SIZE/MOVI_BLKSIZE);
image[0].used_blk = MOVI_FWBL1_BLKCNT;
image[0].size = FWBL1_SIZE;
image[0].attribute = 0x0;
strcpy(image[0].description, "fwbl1");
dbg("fwbl1: %d\n", image[0].start_blk);
#endif
#endif
/* image 1 should be bl2 */
#if defined(CONFIG_EVT1)
#if defined(CONFIG_FUSED)
image[1].start_blk = image[0].start_blk + MOVI_FWBL1_BLKCNT;
#else
image[1].start_blk = (eFUSE_SIZE/MOVI_BLKSIZE);
#endif
#else
image[1].start_blk = capacity - (eFUSE_SIZE/MOVI_BLKSIZE) -
MOVI_BL1_BLKCNT;
#endif
image[1].used_blk = MOVI_BL1_BLKCNT;
image[1].size = SS_SIZE;
image[1].attribute = 0x1;
strcpy(image[1].description, "u-boot parted");
dbg("bl1: %d\n", image[1].start_blk);
/* image 2 should be environment */
#if defined(CONFIG_EVT1)
image[2].start_blk = image[1].start_blk + MOVI_BL1_BLKCNT;
#else
image[2].start_blk = image[1].start_blk - MOVI_ENV_BLKCNT;
#endif
image[2].used_blk = MOVI_ENV_BLKCNT;
image[2].size = CFG_ENV_SIZE;
image[2].attribute = 0x10;
strcpy(image[2].description, "environment");
dbg("env: %d\n", image[2].start_blk);
/* image 3 should be bl2 */
#if defined(CONFIG_EVT1)
image[3].start_blk = image[2].start_blk + MOVI_ENV_BLKCNT;
#else
image[3].start_blk = image[2].start_blk - MOVI_BL2_BLKCNT;
#endif
image[3].used_blk = MOVI_BL2_BLKCNT;
image[3].size = PART_SIZE_BL;
image[3].attribute = 0x2;
strcpy(image[3].description, "u-boot");
dbg("bl2: %d\n", image[3].start_blk);
/* image 4 should be kernel */
#if defined(CONFIG_EVT1)
image[4].start_blk = image[3].start_blk + MOVI_BL2_BLKCNT;
#else
image[4].start_blk = image[3].start_blk - MOVI_ZIMAGE_BLKCNT;
#endif
image[4].used_blk = MOVI_ZIMAGE_BLKCNT;
image[4].size = PART_SIZE_KERNEL;
image[4].attribute = 0x4;
strcpy(image[4].description, "kernel");
dbg("knl: %d\n", image[4].start_blk);
/* image 5 should be RFS */
#if defined(CONFIG_EVT1)
image[5].start_blk = image[4].start_blk + MOVI_ZIMAGE_BLKCNT;
#else
image[5].start_blk = image[4].start_blk - MOVI_ROOTFS_BLKCNT;
#endif
image[5].used_blk = MOVI_ROOTFS_BLKCNT;
image[5].size = PART_SIZE_ROOTFS;
image[5].attribute = 0x8;
strcpy(image[5].description, "rfs");
dbg("rfs: %d\n", image[5].start_blk);
for (i=6; i<15; i++) {
raw_area_control.image[i].start_blk = 0;
raw_area_control.image[i].used_blk = 0;
}
}
}
七、uboot内部获取环境变量
以下两个函数均在:uboot\common\cmd_nvedit.c
1、getenv
(1)应该是不可重入的。
char *getenv (char *name)
{
int i, nxt;
WATCHDOG_RESET();
for (i=0; env_get_char(i) != '\0'; i=nxt+1) {
int val;
for (nxt=i; env_get_char(nxt) != '\0'; ++nxt) {
if (nxt >= CFG_ENV_SIZE) {
return (NULL);
}
}
if ((val=envmatch((uchar *)name, i)) < 0)
continue;
return ((char *)env_get_addr(val));
}
return (NULL);
}
(2)实现方式就是 去遍历default_environment数组,挨个拿出所有的环境变量比对name,找到相等的直接返回这个环境变量的首地址即可。
2、getenv_r
(1)可重入版本。
知识补充:
可重入函数主要用于多任务环境中,一个可重入的函数简单来说就是可以被中断的函数,
也就是说,可以在这个函数执行的任何时刻中断它,转入OS调度下去执行另外一段代码,而
返回控制时不会出现什么错误;而不可重入的函数由于使用了一些系统资源,比如全局变量
区,中断向量表等,所以它如果被中断的话,可能会出现问题,这类函数是不能运行在多任
务环境下的。
int getenv_r (char *name, char *buf, unsigned len)
{
int i, nxt;
for (i=0; env_get_char(i) != '\0'; i=nxt+1) {
int val, n;
for (nxt=i; env_get_char(nxt) != '\0'; ++nxt) {
if (nxt >= CFG_ENV_SIZE) {
return (-1);
}
}
if ((val=envmatch((uchar *)name, i)) < 0)
continue;
/* found; copy out */
n = 0;
while ((len > n++) && (*buf++ = env_get_char(val++)) != '\0')
;
if (len == n)
*buf = '\0';
return (n);
}
return (-1);
}
(2)getenv函数是直接返回这个找到的环境变量在DDR中环境变量处的地址,而getenv_r函数的做法是找到了DDR中环境变量地址后,将这个环境变量复制一份到提供的buf中,而不动原来DDR中环境变量。
所以差别就是:getenv中返回的地址只能读不能随便乱写,而getenv_r中返回的环境变量是在自己提供的buf中,是可以随便改写加工的。
3、总结
(1)功能是一样的,但是可重入版本会比较安全一些,建议使用。
(2)有关于环境变量的所有操作,主要理解了环境变量在DDR中的存储方法,理解了环境变量和gd全局变量的关联和优先级,理解了环境变量在存储介质中的存储方式(专用raw分区),整个环境变量相关的都清楚了。
注:本资料大部分由朱老师物联网大讲堂课程笔记整理而来、引用了百度百科、部分他人博客的内容并结合自己实际开发经历,如有侵权,联系删除!水平有限,如有错误,欢迎各位在评论区交流。