【NLP】第8章 将 Transformer 应用于法律和财务文件以进行 AI 文本摘要
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
在前七章中,我们探讨了几个 Transformer 生态系统的架构训练、微调和使用。在第 7 章“使用 GPT-3 引擎的超人变形金刚的崛起”中,我们发现 OpenAI 已经开始尝试零样本模型,无需微调、无需开发,只需几行代码即可实现。
这种进化的基本概念依赖于变形金刚如何努力教机器如何理解一种语言并以类似人类的方式表达自己。因此,我们已经从训练模型转变为向机器教授语言。
拉菲尔等人。(2019) 设计了一个基于简单断言的转换器元模型:每个 NLP 问题都可以表示为文本到文本的函数。每种类型的 NLP 任务都需要某种文本上下文来生成某种形式的文本响应。
任何 NLP 任务的文本到文本表示提供了一个独特的框架来分析转换器的方法和实践。这个想法是让转换器在训练和微调阶段使用文本到文本的方法通过迁移学习来学习语言。
拉菲尔等人。(2019 年)将此方法命名为T ext- T o - T ext Transfer转换器。5 Ts 变成了T5,一个新的模型诞生了。
我们将从介绍 T5 变压器模型的概念和架构开始本章。然后,我们将应用 T5 来总结具有 Hugging Face 模型的文档。
最后,我们会将文本到文本的方法转换为 GPT-3 引擎使用的显示和上下文过程。令人兴奋的,虽然不完美,零镜头的反应超出了人类的想象。
本章涵盖以下主题:
- 文本到文本转换器模型
- T5 模型的架构
- T5 方法论
- Transformer 模型从训练到学习的演变
- Hugging Face transformer模型
- 实施 T5 模型
- 总结法律文本
- 总结财务文本
- 变压器模型的限制
- GPT-3 用法
我们的第一步将是探索Raffel等人定义的文本到文本方法。(2019)。
设计通用的文本到文本模型
Google 的 NLP 技术革命始于Vaswani等人。(2017 年),最初的变形金刚,2017 年。注意力就是你所需要的,推翻了 30 多年的人工智能对应用于 NLP 任务的 RNN 和 CNN 的信念。它把我们从 NLP/NLU 的石器时代带到了 21世纪,这是一场姗姗来迟的演变。
第 7 章,使用 GPT-3 引擎的超人变形金刚的崛起,总结了在 Google 的Vaswani等人之间爆发并爆发的第二次革命。(2017) 原创 Transformer 和 OpenAI 的Brown等人。(2020) GPT-3 变压器。最初的 Transformer 专注于性能,以证明 NLP/NLU 任务只需要注意力。
OpenAI 通过 GPT-3 进行的第二次革命,专注于将变压器模型从经过微调的预训练模型转变为无需微调的少量训练模型。第二次革命是表明机器可以像人类一样学习一种语言并将其应用于下游任务。
了解这两次革命以了解 T5 模型所代表的意义至关重要。第一次革命是注意力技术。第二次革命是教机器理解一种语言(NLU),然后让它像我们一样解决 NLP 问题。
2019 年,谷歌与 OpenAI 的思路相同,思考如何超越技术考虑来感知转换器,并将其带到自然语言理解的抽象层次。
这些革命变得具有破坏性。是时候安定下来了,忘记源代码和机器资源,在更高的层次上分析转换器。
拉菲尔等人。(2019)设计了一个概念性的文本到文本模型,然后实现了它。
让我们来看看第二次变压器革命的这种表现形式:抽象模型。
文本到文本转换器模型的兴起
拉菲尔等人。(2019 年)作为先驱者踏上了旅程,其目标是:使用统一的文本到文本转换器探索迁移学习的极限。致力于这种方法的 Google 团队强调它不会从一开始就修改原始 Transformer 的基本架构。
那时,Raffel等人。(2019) 想要专注于概念,而不是技术。因此,正如我们经常看到的那样,他们对生产最新的变压器模型没有兴趣具有n 个参数和层的所谓的银弹变压器模型。这一次,T5 团队想要了解 Transformer 在理解语言方面的能力。
人类学习一门语言,然后通过迁移学习将这些知识应用到广泛的 NLP 任务中。T5模型的核心概念是找到一个可以像我们一样做事情的抽象模型。
当我们交流时,我们总是从一个序列(A)开始,然后是另一个序列(B)。B 依次成为通向另一个序列的起始序列,如图 8.1所示:

图 8.1:通信的序列到序列表示
我们还通过音乐与有组织的声音进行交流。我们通过有组织的肢体动作跳舞来交流。我们通过协调形状和颜色的绘画来表达自己。
我们通过语言与我们称为“文本”的一个词或一组词进行交流。当我们尝试要理解一个文本,我们要注意句子中各个方向的所有单词。我们尝试衡量每个术语的重要性。当我们不理解一个句子时,我们专注于一个单词并查询句子中的其余关键字,以确定它们的值以及我们必须关注它们。这定义了转换器的注意力层。
花几秒钟,让它沉入其中。这看起来很简单,对吧?然而,推翻围绕 RNN、CNN 以及伴随它们的思维过程的旧观念花了 35 年多的时间!
看着 T5 学习、进步,有时甚至帮助我们更好地思考,真是令人着迷!
同时关注序列中所有标记的注意力层的技术革命导致了 T5 概念革命。
T5 模型可以概括为一个T ext- T o - T ext T传输转换器。因此,每个 NLP 任务都表示为要解决的文本到文本问题。
前缀而不是特定于任务的格式
拉菲尔等人。(2019) 仍有一个问题需要解决:统一特定任务的格式。这个想法是为提交给转换器的每个任务找到一种输入格式。这样,模型参数将针对所有类型的任务使用一种文本到文本格式进行训练。
Google T5 团队想出了一个简单的解决方案:为输入序列添加前缀。如果没有某个被遗忘已久的天才发明前缀,我们将需要多种语言的数千个额外词汇表。例如,如果我们不使用“pre”作为前缀,我们将需要找到描述 prepayment、prehistoric、Precambrian 和数千个其他词的词。
拉菲尔等人。(2019)提出为输入序列添加前缀。T5 前缀不仅仅是一个标签或指示符,就像[CLS]某些变压器模型中的分类一样。相反,T5 前缀包含了转换器需要解决的任务的本质。前缀传达含义如下例所示:
translate English to German: + [sequence]对于翻译,就像我们在第 6 章中所做的那样,使用 Transformer 进行机器翻译cola sentence: + [sequence]用于语言可接受性语料库 (CoLA),正如我们在第 3 章微调BERT 模型中使用的那样,当我们微调 BERT 转换器模型时stsb sentence 1:+[sequence]用于语义文本相似性基准。自然语言推理和蕴涵是类似的问题,如第 5 章,带有 Transformer 的下游 NLP 任务中所述summarize + [sequence]对于文本摘要问题,我们将在本章的 T5 文本摘要部分解决
我们现在已经为广泛的 NLP 任务获得了一个统一的格式,如图 8.2 所示:

图 8.2:统一 Transformer 模型的输入格式
统一的输入格式导致一个转换器模型,无论它必须在T5中解决哪个问题,它都会产生一个结果序列。许多 NLP 任务的输入和输出已经统一,如图 8.3所示:
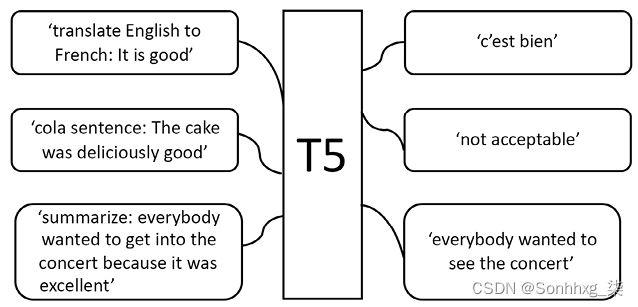 图 8.3:T5 文本到文本框架
图 8.3:T5 文本到文本框架
统一过程使得可以为广泛的任务使用相同的模型、超参数和优化器。
我们已经了解了标准的文本到文本输入输出格式。现在让我们看看 T5 变压器模型的架构。
T5 型号
拉菲尔等人。(2019)专注于设计标准输入格式以获得文本输出。Google T5 团队不想尝试从原始 Transformer 派生的新架构,例如类似 BERT 的仅编码器层或类似 GPT 的仅解码器层。相反,该团队专注于以标准格式定义 NLP 任务。
他们选择使用我们在第 2 章定义的原始 Transformer 模型,Transformer 模型的架构入门,如图 8.4 所示:
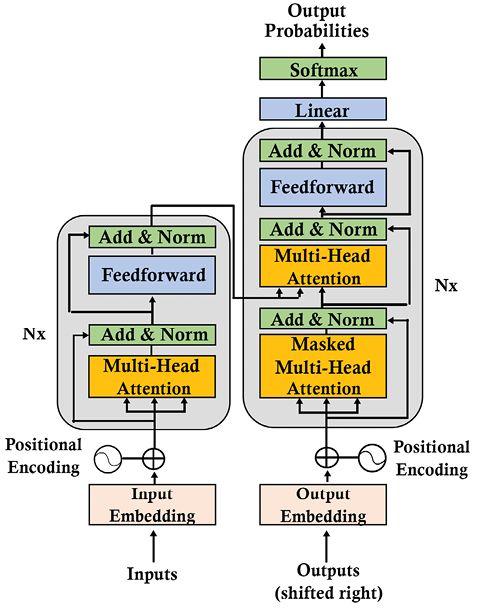
图 8.4:T5 使用的原始 Transformer 模型
拉斐尔等人。(2019) 保持最多原始的 Transformer 架构和术语。但是,他们强调了一些关键方面。此外,他们对词汇和功能做了一些细微的改变。以下列表包含一些T5模型的主要方面:
- 编码器和解码器保留在模型中。编码器和解码器层成为“块”,子层成为包含自注意力层和前馈网络的“子组件”。在类似 LEGO ®的语言中使用“块”和“子组件”一词允许您组装“块”、部件和组件来构建模型。变压器组件是您可以通过多种方式组装的标准构建块。一旦您了解了我们在第 2 章“ Transformer 模型架构入门”中介绍的基本构建块,您就可以理解任何 Transformer 模型。
- 自注意力是“顺序无关的”,这意味着它对集合执行操作,正如我们在第 2 章中看到的那样。自注意力使用矩阵的点积,而不是递归。它按顺序探索每个单词与其他单词之间的关系。在生成点积之前,将位置编码添加到单词的嵌入中。
- 这原始变压器将正弦和余弦信号应用于变压器。或者它使用学习的位置嵌入。T5 使用相对位置嵌入,而不是向输入添加任意位置。在 T5 中,位置编码依赖于自注意力的扩展来比较成对关系。有关更多信息,请参阅Shaw等人。(2018) 在本章的参考资料部分。
- 位置嵌入通过模型的所有层共享和重新评估。
我们已经通过文本到文本的方法定义了 T5 转换器模型的输入标准化。
现在让我们使用 T5 来汇总文档。
使用 T5 进行文本摘要
NLP 总结任务提取文本的简洁部分。本节将首先介绍我们将在本章中使用的拥抱脸资源。然后我们将初始化一个 T5-large Transformer 模型。最后,我们将看到如何使用 T5 来总结任何文件,包括法律和公司文件。
让我们从介绍 Hugging Face 的框架开始。
Hugging Face
Hugging Face设计在更高级别实现 Transformer 的框架。我们在第 3 章“微调 BERT 模型”中使用 Hugging Face 来微调BERT 模型,并在第 4 章“从头开始预训练 RoBERTa 模型”中训练 RoBERTa 模型。
为了扩展我们的知识,我们需要探索其他方法,例如第 6 章中的 Trax ,使用 Transformer 进行机器翻译,以及第 7 章,使用 GPT-3 引擎的超人变形金刚的崛起中的 OpenAI模型。本章将再次使用 Hugging Face 的框架并解释更多关于在线资源的信息。我们使用 GPT-3 引擎的独特潜力来结束本章。
Hugging Face 在其框架内提供了三种主要资源:模型、数据集和指标。
Hugging Face transformer 资源
在本小节中,我们将选择我们将在本章中实现的 T5 模型。
一个大范围模型可以在 Hugging Face 模型页面上找到,如图 8.5 所示:
 图 8.5:拥抱脸模型
图 8.5:拥抱脸模型
在此页面Models - Hugging Face上,我们可以搜索模型。在我们的例子中,我们正在寻找t5-large,一个我们可以在 Google Colaboratory 中顺利运行的模型。
我们首先键入T5以搜索 T5 模型并获取我们可以选择的 T5 模型列表:

图 8.6:搜索 T5 模型
我们可以看到有几款原装的T5变压器可用,其中有:
- base,这是基线模型。它的设计类似于具有 12 层和大约 2.2 亿个参数的 BERT BASE
- small,这是一个较小的模型,有 6 层和 6000 万个参数
- large被设计成类似于 BERT LARGE,有 12 层和 7.7 亿个参数
- 3B和11B使用 24 层编码器和解码器,大约有 28 亿和 110 亿个参数
有关 BERT BASE和 BERT LARGE的更多描述,您可以现在或稍后在第 3 章,微调 BERT 模型中查看这些模型。
在我们的例子中,我们选择t5-large:
 图 8.7:如何使用拥抱脸模型
图 8.7:如何使用拥抱脸模型
图 8.7显示了如何在我们将编写的代码中使用模型。我们还可以查看文件列表在模型和基本配置文件中。我们将在本章的初始化 T5 大型变压器模型部分中初始化模型时查看配置文件。
Hugging Face 还提供数据集和指标:
- 这数据集可用于训练和测试您的模型:https ://huggingface.co/datasets
- 指标资源可用于衡量模型的性能:https ://huggingface.co/metrics
数据集和指标是 NLP 的经典方面。在本章中,我们不会实现这些数据集或指标。相反,我们将专注于如何实现任何要总结的文本。
让我们从初始化 T5 变压器模型开始。
初始化 T5-large transformer 模型
在这个小节,我们将初始化一个 T5-large 模型。打开以下笔记本 ,Summarizing_Text_with_T5.ipynb您可以在 GitHub 上的本章目录中找到它。
让我们开始使用 T5!
T5 入门
在本小节中,我们将安装 Hugging Face 的框架,然后初始化一个 T5 模型。
我们将首先安装 Hugging Face 的变压器:
!pip install transformers注意:Hugging Face 转换器不断发展,更新库和模块以适应市场。如果默认版本不起作用,您可能必须使用
!pip install transformers==[version that runs with the other functions in the notebook].
我们固定版本0.1.94以sentencepiece使使用 Hugging Face 的笔记本尽可能稳定:
!pip install sentencepiece==0.1.94Hugging Face 有一个可以克隆的 GitHub 存储库。然而,Hugging Face 的框架提供了一系列我们可以实现的高级转换器函数。
我们可以在初始化模型时选择是否显示模型的架构:
display_architecture=False如果我们设置display_architecture为True,将显示编码器层、解码器层和前馈子层的结构。
该程序现在导入torch和json:
import torch
import json研究变压器意味着对研究实验室与我们共享的许多变压器架构和框架持开放态度。另外,我建议尽可能使用 PyTorch 和 TensorFlow 来适应这两种环境。重要的是 Transformer 模型(特定任务模型或零样本模型)的抽象级别及其整体性能。
让我们导入标记器、生成和配置类:
from transformers import T5Tokenizer, T5ForConditionalGeneration, T5Config我们将在T5-large此处使用该模型,但您可以在本章的“拥抱脸”部分中介绍的“拥抱脸”列表中选择其他 T5 模型。
我们将现在导入T5-large条件生成模型以生成文本和 T5-large 分词器:
model = T5ForConditionalGeneration.from_pretrained('t5-large')
tokenizer = T5Tokenizer.from_pretrained('t5-large')初始化一个预训练的分词器只需要一行。然而,没有任何证据证明分词词典包含了我们需要的所有词汇。我们将在第 9 章“匹配分词器和数据集”中研究分词器和数据集之间的关系。
程序现在torch.devic用 A CPU 初始化 e'cpu.'对这个笔记本来说已经足够了。torch.device对象是将分配 Torch 张量的设备:
device = torch.device('cpu')我们准备探索 T5 模型的架构。
探索 T5 模型的架构
在这个小节,我们将探讨 T5 大型模型的架构和配置。
如果display_architecture==true,我们可以看到模型的配置:
if display_architecture==True:
print(model.config)例如,我们可以看到模型的基本参数:
.../...
"num_heads": 16,
"num_layers": 24,
.../...模型为16头24层T5变压器。
我们还可以看到 T5 的 text-to-text 实现,它为输入句子添加前缀以触发任务执行。该前缀可以在不修改模型参数的情况下以文本到文本的格式表示各种任务。在我们的例子中,前缀是summarization:
"task_specific_params": {
"summarization": {
"early_stopping": true,
"length_penalty": 2.0,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},我们可以看到T5:
- 实施束搜索算法,该算法将扩展四个最重要的文本完成预测
num_beam当每批句子完成时应用提前停止- 确保不重复 ngram 等于
no_repeat_ngram_size min_length用和控制样本的长度max_length- 应用长度惩罚
另一个有趣的参数是词汇量:
"vocab_size": 32128词汇量本身就是一个话题。太多的词汇会导致稀疏的表示。另一方面,词汇量太少会扭曲 NLP 任务。我们将在第 9 章“匹配标记器和数据集”中进一步探讨这一点。
我们还可以通过简单地打印以下内容来查看变压器堆栈的详细信息model:
if(display_architecture==True):
print(model)例如,我们可以窥视layer编码器堆栈的块 ( )(编号从0到23):
(12): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=1024, bias=False)
(k): Linear(in_features=1024, out_features=1024, bias=False)
(v): Linear(in_features=1024, out_features=1024, bias=False)
(o): Linear(in_features=1024, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseReluDense(
(wi): Linear(in_features=1024, out_features=4096, bias=False)
(wo): Linear(in_features=4096, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)我们可以看到模型1,024对注意力子层的特征和4,096前馈网络子层的内部计算运行操作,这将产生1,024特征输出。变压器的对称结构贯穿所有层。
您可以花几分钟时间浏览编码器堆栈、解码器堆栈、注意力子层和前馈子层。
您还可以通过仅运行您希望的单元格来选择模型的特定方面:
if display_architecture==True:
print(model.encoder)
if display_architecture==True:
print(model.decoder)
if display_architecture==True:
print(model.forward)我们已初始化 T5 变压器。现在让我们总结一下文件。
使用 T5-large 汇总文档
本节将创建一个汇总函数,您可以使用要汇总的任何文本调用该函数。我们将总结法律和财务示例。最后,我们将定义该方法的限制。
我们将首先创建一个汇总函数。
创建汇总函数
首先,让我们创建一个名为 的汇总函数summarize。这样,我们将只发送文本我们想总结一下我们的功能。该函数有两个参数。第一个参数是preprocess_text,要总结的文本。第二个参数是ml,摘要文本的最大长度。这两个参数都是您每次调用函数时发送给函数的变量:
def summarize(text,ml):Hugging Face 等提供即用型汇总功能。但是,我建议学习如何构建自己的函数,以便在必要时自定义此关键任务。
然后删除上下文文本或基本事实的\n字符:
preprocess_text = text.strip().replace("\n","")然后我们将创新的T5任务前缀 summarize应用于输入文本:
t5_prepared_Text = "summarize: "+preprocess_textT5 模型具有统一的结构,无论任务是通过前缀+输入序列的方法。这看起来很简单,但它使 NLP 转换器模型更接近通用训练和零样本下游任务。
我们可以显示已处理(剥离)和准备好的文本(任务前缀):
print ("Preprocessed and prepared text: \n", t5_prepared_Text)简单吧?好吧,从 RNN 和 CNN 到 Transformer,花了 35 年以上的时间。然后,世界上一些最聪明的研究团队从为特定任务设计的转换器转变为几乎不需要微调的多任务模型。最后,谷歌研究团队为转换器的输入文本创建了一个标准格式,其中包含一个前缀,表示要解决的 NLP 问题。这真是一个壮举!
这显示的输出包含预处理和准备好的文本:
Preprocessed and prepared text:
summarize: The United States Declaration of Independence我们可以看到summarize表示要解决的任务的前缀。
文本现在被编码为令牌 ID 并将它们作为火炬张量返回:
tokenized_text = tokenizer.encode(t5_prepared_Text, return_tensors="pt").to(device)编码文本已准备好发送到模型以使用我们在T5 入门部分中描述的参数生成摘要:
# Summarize
summary_ids = model.generate(tokenized_text,
num_beams=4,
no_repeat_ngram_size=2,
min_length=30,
max_length=ml,
early_stopping=True)梁的数量与我们导入的模型中的相同。但是,no_repeat_ngram_size已经降级2为3.
生成的输出现在使用以下代码解码tokenizer:
output = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
return output我们导入、初始化和定义汇总函数。现在让我们用一个通用主题来试验 T5 模型。
一般主题示例
在本小节中,我们将通过 T5 模型运行由Project Gutenberg编写的文本。我们将使用示例对我们的汇总函数进行测试。您可以复制和粘贴您希望的任何其他文本或通过添加代码加载文本。您还可以加载您选择的数据集并循环调用摘要。
本章程序的目标是运行一些示例来了解 T5 的工作原理。输入文本是包含美利坚合众国独立宣言的古腾堡计划电子书的开头:
text ="""
The United States Declaration of Independence was the first Etext
released by Project Gutenberg, early in 1971. The title was stored
in an emailed instruction set which required a tape or diskpack be
hand mounted for retrieval. The diskpack was the size of a large
cake in a cake carrier, cost $1500, and contained 5 megabytes, of
which this file took 1-2%. Two tape backups were kept plus one on
paper tape. The 10,000 files we hope to have online by the end of
2001 should take about 1-2% of a comparably priced drive in 2001.
"""然后我们调用我们的summarize函数并发送我们想要总结的文本和总结的最大长度:
print("Number of characters:",len(text))
summary=summarize(text,50)
print ("\n\nSummarized text: \n",summary)输出显示我们发送534的字符、预处理的原始文本(基本事实)和摘要(预测):
Number of characters: 534
Preprocessed and prepared text:
summarize: The United States Declaration of Independence...
Summarized text:
the united states declaration of independence was the first etext published by project gutenberg, early in 1971. the 10,000 files we hope to have online by the end of2001 should take about 1-2% of a comparably priced drive in 2001. the united states declaration of independence was the first Etext released by project gutenberg, early in 1971让我们现在使用 T5 进行更困难的总结。
权利法案样本
以下取自《权利法案》的样本比较困难,因为它表达了一个人的特殊权利:
#Bill of Rights,V
text ="""
No person shall be held to answer for a capital, or otherwise infamous crime,
unless on a presentment or indictment of a Grand Jury, except in cases arising
in the land or naval forces, or in the Militia, when in actual service
in time of War or public danger; nor shall any person be subject for
the same offense to be twice put in jeopardy of life or limb;
nor shall be compelled in any criminal case to be a witness against himself,
nor be deprived of life, liberty, or property, without due process of law;
nor shall private property be taken for public use without just compensation.
"""
print("Number of characters:",len(text))
summary=summarize(text,50)
print ("\n\nSummarized text: \n",summary)请记住,转换器是随机算法,因此每次运行时输出可能会有所不同。话虽如此,我们可以看到 T5 并没有真正总结输入文本,而是简单地将其缩短:
Number of characters: 591
Preprocessed and prepared text:
summarize: No person shall be held to answer..
Summarized text:
no person shall be held to answer for a capital, or otherwise infamous crime. except in cases arisingin the land or naval forces or in the militia, when in actual service in time of war or public danger该示例很重要,因为它显示了任何 Transformer 模型或其他 NLP 模型在面对诸如此类的文本时所面临的限制。我们不能只提供始终有效的样本,让用户相信 Transformer 已经解决了我们面临的所有 NLP 挑战,无论它们多么创新。
也许我们应该提供更长的文本来总结,使用其他参数,使用更大的模型,或者改变 T5 模型的结构。然而,无论你多么努力地尝试用 NLP 模型总结复杂的文本,你总会发现模型无法总结的文档。
当模型在一项任务上失败时,我们必须谦虚并承认这一点。SuperGLUE 人类基线是一个难以超越的基线。我们需要耐心,更加努力地工作,并改进变压器模型,直到它们能够比现在表现得更好。仍有很大的进步空间。
拉菲尔等人。(2018) 选择了一个合适的标题来描述他们的 T5 方法:使用统一的文本到文本转换器探索迁移学习的限制。
花点时间尝试在法律文件中找到的您自己的示例。作为现代 NLP 先驱,探索迁移学习的极限!有时你会发现令人兴奋的结果,有时你会发现需要改进的地方。
现在,让我们尝试一个公司法示例。
公司法样本
公司的法律包含许多法律细节,使得总结任务相当棘手。
该样本的输入是美国蒙大拿州公司法的摘录:
#Montana Corporate Law
#https://corporations.uslegal.com/state-corporation-law/montana-corporation-law/#:~:text=Montana%20Corporation%20Law,carrying%20out%20its%20business%20activities.
text ="""The law regarding corporations prescribes that a corporation can be incorporated in the state of Montana to serve any lawful purpose. In the state of Montana, a corporation has all the powers of a natural person for carrying out its business activities. The corporation can sue and be sued in its corporate name. It has perpetual succession. The corporation can buy, sell or otherwise acquire an interest in a real or personal property. It can conduct business, carry on operations, and have offices and exercise the powers in a state, territory or district in possession of the U.S., or in a foreign country. It can appoint officers and agents of the corporation for various duties and fix their compensation.
The name of a corporation must contain the word "corporation" or its abbreviation "corp." The name of a corporation should not be deceptively similar to the name of another corporation incorporated in the same state. It should not be deceptively identical to the fictitious name adopted by a foreign corporation having business transactions in the state.
The corporation is formed by one or more natural persons by executing and filing articles of incorporation to the secretary of state of filing. The qualifications for directors are fixed either by articles of incorporation or bylaws. The names and addresses of the initial directors and purpose of incorporation should be set forth in the articles of incorporation. The articles of incorporation should contain the corporate name, the number of shares authorized to issue, a brief statement of the character of business carried out by the corporation, the names and addresses of the directors until successors are elected, and name and addresses of incorporators. The shareholders have the power to change the size of board of directors.
"""
print("Number of characters:",len(text))
summary=summarize(text,50)
print ("\n\nSummarized text: \n",summary)这结果令人满意:
Number of characters: 1816
Preprocessed and prepared text:
summarize: The law regarding the corporation prescribes that a corporation...
Summarized text:
a corporations can be incorporated in the state of Montana to serve any lawful purpose. a corporation can sue and be sued in its corporate name, and it has perpetual succession. it can conduct business, carry on operations and have offices这一次,T5找到了文中的一些重要方面进行总结。花一些时间来合并您自己的样本,看看会发生什么。使用参数来查看它是否会影响结果。
我们已经实现了 T5 来总结文本。是时候尝试使用 OpenAI GPT-3 引擎进行汇总了。
使用 GPT-3 进行总结
了解 T5 变压器的架构至关重要。我们还将看到 GPT-3 如何引擎在其中一个文本上运行。目标不是对公司和模型进行基准测试。目标是让工业 4.0 人工智能大师拥有广泛的 NLP 知识。
首先,访问OpenAI并注册并登录。
然后转到示例页面并为二年级学生选择总结:

图 8.8:GPT-3 示例页面
将打开一个窗口,我们可以输入我们的提示。
我们将上一节的企业样本的文本T提交给 GPT-3 模型。
提示是P = E + T + S:
- E告诉模型使解释简单:
My second grader asked me what this passage means:
- 文本T与上一节中的相同,并用引号引起来:
"""The law regarding corporations prescribes that a corporation can be incorporated in the state of Montana to serve any lawful purpose. In the state of Montana, a corporation has all the powers of a natural person for carrying out its business activities..../...The shareholders have the power to change the size of board of directors."""
- S显示预期的任务类型:
I rephrased it for him, in plain language a second grader can understand: """响应GPT-3 达芬奇引擎所产生的效果相当有说服力:
A corporation is a business.
A corporation is a person.
Corporations can do everything people can do.
Corporations can be sued.
Corporations can buy, sell, or trade things.
A corporation has its own name that is different from the names of the people who own it.
Corporations are formed by people who want to start a business, and they file papers with the government to make it official.
我们可以保留T并修改E和S:
- E可以改成:
My MBA college student asked me what this passage means:
- S可以改为:
I rephrased it for him, in MBA college language :
GPT-3 引擎生成了上一个请求的响应,但添加了对大学生有用的信息:
Corporations can have directors who are in charge of making decisions for the business. The directors are elected by the shareholders. Shareholders can change the size of the board of directors.
GPT-3 型号非常有说服力,代表了Cloud AI的崛起力量。我们将在第 16 章“变压器驱动副驾驶的出现”中深入总结提示。然而,在我们这样做之前,还有更多更多的东西需要探索。
概括
在本章中,我们看到了 T5 Transformer 模型如何标准化原始 Transformer 的编码器和解码器堆栈的输入。原始的 Transformer 架构对于编码器和解码器堆栈的每个块(或层)具有相同的结构。但是,最初的 Transformer 没有用于 NLP 任务的标准化输入格式。
拉菲尔等人。(2018 年)通过定义文本到文本模型,为各种 NLP 任务设计了标准输入。他们为输入序列添加了前缀,指示要解决的 NLP 问题类型。这导致了标准的文本到文本格式。文本到文本传输转换器( T5 )诞生了。我们看到,这种看似简单的演变使得在广泛的 NLP 任务中使用相同的模型和超参数成为可能。T5的发明使变压器模型的标准化进程更进一步。
然后我们实现了一个可以总结任何文本的 T5 模型。我们在不属于即用型训练数据集的文本上测试了模型。我们在宪法和公司样本上测试了模型。结果很有趣,但我们也发现了变压器模型的一些局限性,正如Raffel等人所预测的那样。(2018 年)。
最后,我们探讨了 GPT-3 引擎的方法论和计算效率的巨大威力。展示变压器是一种绝妙的方法。拥有世界上最强大的变压器引擎之一有助于获得有效但并不总是完美的结果。
目标不是对公司和模型进行基准测试,而是让工业 4.0 人工智能大师对变压器有深入的了解。
在下一章,第 9 章,匹配分词器和数据集,我们将探索分词器的局限性,并定义可能改进 NLP 任务的方法。