Springdata-mongodb的基本使用
文章目录
- 一、 SpringData介绍
- 二、 SpringData操作MongoDB的两种方式及实战
-
- 1. MongoTemplate
-
- 1.1 Mongodb Driver Api操作MongoDB
-
- 1.1.2 基本CRUD
- 1.1.3 连接选项
- 1.2 MongoTemplate的基本CRUD
- 1.3 MongoTemplate的聚合查询
-
- 1.3.1 Aggregate
- 1.3.2 MapReduce
- 1.3.3 聚合操作和MapReduce对比
- 1.3.4 Group操作
- 1.3.5 Bucket聚合
- 2. MongoRepository
-
- 2.1 简介
- 2.2 基本CRUD
- 3. MongoTemplate和MongoRepository对比
一、 SpringData介绍
**SpringData****是为了提供一个常见的、一致的数据访问模型,也就是说,它的目标就是为了能为所有数据库(包括关系型和非关系型)提供一致的数据操作接口,并且这些接口名非常通俗易懂,让人一看便知。**它也是基于Spring框架的,即可以直接使用Spring的IoC和AOP等特性。
它的一致性接口是怎么做到的呢?
我们知道,Java对于数据库(关系和非关系型)的操作,最原始的API都是数据库厂商在驱动里提供的,然后java对这些API进行直接使用或者进行封装,形成相应的Java层面的API,例如对于各个关系型数据库,Java将驱动API,封装成JDBC(使得对各个数据库的操作保持统一),对于MongoDB和Redis,Java是直接用驱动里的API,等等。对于每一种数据库,Java层面的API都是不一样的,开发人员使用一种数据库就要记住一套Api,SpringData就是想消除这种不一致性,使得对各种数据库的操作用同一套Api即可。具体来说,它是使用Repository接口来实现的,每一种类型的数据库,都对应一种Repository,这样接口就一致了。例如,JDBC对应SimpleJdbcRepository,MongoDB对应MongoRepository,等等。SpringData的架构如下图:

二、 SpringData操作MongoDB的两种方式及实战
1. MongoTemplate
1.1 Mongodb Driver Api操作MongoDB
mongoTemplate是对mongodb java driver api的封装,我们先了解一下使用mongodb driver api操作mongodb。
1.1.2 基本CRUD
- 引入依赖
mongodb
mongodb
1.0.0-SNAPSHOT
4.0.0
springdata-mongodb
org.mongodb
mongo-java-driver
3.8.2
junit
junit
4.12
- 实体类
package cs.entity;
import java.util.List;
public class User {
private String id;
private String name;
private int age;
private String gender;
private List address;
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public List getAddress() {
return address;
}
public void setAddress(List address) {
this.address = address;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public User(String id, String name, int age, String gender, List address) {
this.id = id;
this.name = name;
this.age = age;
this.gender = gender;
this.address = address;
}
public User(){}
@Override
public String toString() {
return "[id:" + this.id + "; name:" + this.name + "; age:"+ this.age +"; gender:" + this.gender +
"; address:" + this.address + "]";
}
}
- 连接配置信息
在mongodb3.7以后,MongoClient做了一次升级,由原来的com.mongodb.MongoClient升级为com.mongodb.client.MongoClient,它们的区别可以查阅官网,这里不作讨论,推荐直接用新版的,下面例子中新旧版都有,仅作参考,后续只以新版为例讲解。
package cs.connection;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientOptions;
import com.mongodb.MongoCredential;
import com.mongodb.ServerAddress;
import com.mongodb.WriteConcern;
import com.mongodb.client.MongoClients;
public class ConnectionManager {
public static MongoClient connect(){
// 1. 方式1
MongoCredential credential = MongoCredential.createCredential(USERNAME,
AUTH_DB, PWD.toCharArray());
com.mongodb.MongoClient mongoClient = new com.mongodb.MongoClient(new ServerAddress(HOST, PORT),
credential, MongoClientOptions.builder().sslEnabled(false).writeConcern(WriteConcern.ACKNOWLEDGED).build());
// // 2. 方式2
// String uri = String.format("mongodb://%s:%s@%s:%d/?authSource=%s", USERNAME, PWD, HOST, PORT, AUTH_DB);
// MongoClient mongoClient = new MongoClient(new MongoClientURI(uri));
return mongoClient;
}
public static com.mongodb.client.MongoClient connect2(){
// 3. 方式3
com.mongodb.client.MongoClient mongoClient = MongoClients.create(String.format(
"mongodb://%s:%s@%s:%d/?authSource=%s", USERNAME, PWD, HOST, PORT,
AUTH_DB));
return mongoClient;
}
/**
* 服务器
*/
public static final String HOST = "localhost";
/**
* 端口
*/
public static final int PORT = 26501;
/**
* 验证数据库
*/
public static final String AUTH_DB = "admin";
/**
* 用户名
*/
public static final String USERNAME = "admin";
/**
* 密码
*/
public static final String PWD = "fiberhome";
}
- Crud
-
增加
@Test public void testInsert(){ /** * 连接数据库 */ MongoClient mongoClient = ConnectionManager.connect(); MongoDatabase user = mongoClient.getDatabase("user"); MongoCollectionuserCollection = user.getCollection("user"); /** * 1. 插入单个 */ Document doc1 = new Document("name", "bbb").append("age", 35); userCollection.insertOne(doc1); System.out.println("单个插入成功!"); // /** // * 2. 批量插入 // */ // Document doc2 = new Document("name", "aaa").append("age", 51); // Document doc3 = new Document("name", "bb").append("age", 52); // Document doc4 = new Document("name", "ccc").append("age", 60); // Document doc5 = new Document("name", "dddd").append("age", 73); // Document doc6 = new Document("name", "eeee").append("age", 82); // Document doc7 = new Document("name", "eeee").append("age", 23); // Document doc8 = new Document("name", "eeee").append("age", 32); // Document doc9 = new Document("name", "eeee").append("age", 46); // userCollection.insertMany(Arrays.asList(doc2, doc3, doc4, doc5, doc6, doc7, doc8, doc9)); // System.out.println("批量插入成功!"); } -
查询
@Test public void testQuery(){ /** * 连接数据库 */ MongoClient mongoClient = ConnectionManager.connect(); // com.mongodb.client.MongoClient mongoClient = ConnectionManager.connect2(); /** * 1. 查询 * 1.1 查询所有 */ // 获取数据库 MongoDatabase user = mongoClient.getDatabase("user"); for (String collectionName : user.listCollectionNames()) { System.out.println(collectionName); } // 获取user集合 MongoCollectionusers = user.getCollection("user"); // 几种遍历方式 // 1. 使用for遍历 System.out.println("--------------------方式1--------------------"); for (Document document : users.find()) { // 这里可以将document封装成业务对象 // 对于自生成的id,必须用get().toString, 不能用getString() String id = document.get("_id").toString(); String name = document.getString("name"); int age = document.getInteger("age"); String gender = document.getString("gender"); List address = (ArrayList )document.get("address"); User user2 = new User(id, name, age, gender, address); System.out.println(user2); } // 2.使用foreach遍历,以下2种均可 System.out.println("--------------------方式2--------------------"); users.find().forEach((Block )doc -> { // 这里可以将document封装成业务对 System.out.println(doc.toJson()); //封装过程略... }); System.out.println("--------------------方式3--------------------"); users.find().forEach(new Block () { @Override public void apply(Document document) { // 这里可以将document封装成业务对象 System.out.println(document.toJson()); //封装过程略... } }); // 3.使用指针 System.out.println("--------------------方式4--------------------"); MongoCursor cursor = users.find().iterator(); while (cursor.hasNext()) { // 这里可以将document封装成业务对象 System.out.println(cursor.next().toJson()); //封装过程略... } System.out.println("--------------------条件查询--------------------"); /** * 1.2 条件查询 */ // 查询名字为aaa的 FindIterable docs = users.find(eq("name", "aaa")); // 同样可以对docs进行一些遍历操作 // 查询年龄在50-60岁之间的 users.find(and(gte("age", 50), lte("age", 60))); /** * 2. 关闭连接 */ mongoClient.close(); } -
更新
@Test public void testUpdate(){ /** * 连接数据库 */ MongoClient mongoClient = ConnectionManager.connect(); MongoDatabase user = mongoClient.getDatabase("user"); MongoCollectionuserCollection = user.getCollection("user"); /** * 1. 更新单个 */ // userCollection.updateOne(eq("name", "bbb"), combine(set("age", 30), set("gender", "f"))); // System.out.println("更新单个成功!"); /** * 2. 更新多个 */ userCollection.updateMany(eq("name", "bbb"), combine(set("age", 20), set("gender", "f"))); System.out.println("更新多个成功!"); // /** // * 3. 替换,当需要更新的字段很多时,宜用替换 // */ // userCollection.replaceOne(eq("name", "bbb"), new Document("name", "bbb").append("age", 60)); System.out.println("替换成功!"); } -
删除
@Test public void testDel(){ /** * 连接数据库 */ MongoClient mongoClient = ConnectionManager.connect(); MongoDatabase user = mongoClient.getDatabase("user"); MongoCollectionuserCollection = user.getCollection("user"); /** * 1. 删除单个 */ userCollection.deleteOne(eq("name", "zhangh")); System.out.println("删除单个成功!"); /** * 2. 批量删除 */ // userCollection.deleteMany(gt("age", 50)); // System.out.println("批量删除成功!"); }
1.1.3 连接选项
可以使用连接字符串或者MongoClientSettings类设置连接选项,例如,设置ssl连接和最大连接池数:
- 使用连接字符串:
MongoClient mongoClient = MongoClients.create("mongodb://admin:fiberhome@localhost:26501/?authSource=admin&ssl=true");
- 使用MongoClientSettings类:
MongoCredential credential = MongoCredential.createCredential("admin", "admin", "fiberhome".toCharArray());
MongoClientSettings mongoClientSettings = MongoClientSettings.builder()
.credential(credential)
.applyToClusterSettings(builder -> builder.hosts(Arrays.asList(new ServerAddress("localhost", 26501))))
.applyToConnectionPoolSettings(builder -> builder.maxSize(100)) // 最大连接数
.applyToSslSettings(builder -> builder.enabled(true)) // 启用ssl连接
.build();
MongoClient mongoClient2 = MongoClients.create(mongoClientSettings);
- 混用:
MongoClientSettings mongoClientSettings = MongoClientSettings.builder()
.applyToConnectionPoolSettings(builder -> builder.maxSize(100)) // 最大连接数 .applyToSslSettings(builder -> builder.enabled(true)) // 启用ssl连接
.applyConnectionString(new ConnectionString("mongodb://admin:fiberhome@localhost:26501/?authSource=admin")).build();
MongoClient mongoClient2 = MongoClients.create(mongoClientSettings);
注:
一个MongoClient代表了一个连接池,所以对于一个mongodb服务实例(例如一个单体部署的服务实例),只需要一个MongoClient实例即可,即使是在多线程环境中。如果确实使用了多个MongoClient实例,那么:
-
所有的资源使用限制(例如最大连接数等)将作用于每个实例上;
-
使用MongoClient.close()方法关闭MongoClient,释放资源。
可以设置连接池的最大连接数,和超时时间等。上面例子中设置了最大连接数,其他有关线程池的设置,可以参考 官网。
1.2 MongoTemplate的基本CRUD
现在回过头来看MongoTemplate的操作。MongoTemplate的bean的配置,可以用spring xml或者注解@Configuration的方式,其实本质一样,这里只介绍注解方式,本节末附上xml配置。
- 引入依赖:
mongodb
mongodb
1.0.0-SNAPSHOT
4.0.0
springdata-mongodb
org.springframework
spring-context
5.2.9.RELEASE
org.mongodb
mongo-java-driver
3.8.2
org.springframework.data
spring-data-mongodb
2.2.10.RELEASE
org.springframework
spring-test
5.1.3.RELEASE
junit
junit
4.12
- 配置类
· package cs.config;
·
· import cs.connection.ConnectionManager;
· import org.springframework.context.annotation.Bean;
· import org.springframework.context.annotation.Configuration;
· import org.springframework.data.mongodb.MongoDbFactory;
· import org.springframework.data.mongodb.core.MongoTemplate;
· import org.springframework.data.mongodb.core.SimpleMongoClientDbFactory;
· import org.springframework.data.mongodb.core.SimpleMongoDbFactory;
· import org.springframework.data.mongodb.repository.config.EnableMongoRepositories;
·
· @Configuration
· @EnableMongoRepositories("cs.dao") //添加MongoRepository的扫描包,如果不定义,将扫描当前配置类所在的包
· public class AppConfig {
· @Bean
· public MongoDbFactory mongoDbFactory(){
· return new SimpleMongoDbFactory(ConnectionManager.connect(), "user");
· }
·
· @Bean
· public MongoDbFactory mongoDbFactory2(){
· return new SimpleMongoClientDbFactory(ConnectionManager.connect2(), "user");
· }
·
· @Bean
· public MongoTemplate mongoTemplate() {
· // return new MongoTemplate(ConnectionManager.connect(), "user");
· return new MongoTemplate(ConnectionManager.connect2(), "user");
· // return new MongoTemplate(mongoDbFactory());
· // return new MongoTemplate(mongoDbFactory2());
· }
·
·
}
- Crud
- 增删查改:
2. @Autowired
3. private MongoTemplate mongoTemplate;
4. @Test
5. public void testCrud(){
6. /**
7. * insert, save的区别:
8. * 1. save会根据id对象是否存在,存在则进行update,而insert在对象存在时不进行操作;
9. * 2. save插入时,会进行遍历,insert不需要,因此效率高;
10. *
11. * save, upsert, update区别:
12. * 它们都可以进行更新,但update只在对象存在时才更新,否则什么也不做;save和upsert在对象不存在时,会插入
13. * save和upsert之间的区别是,save只会根据pojo的id来判定对象是否存在,更新的内容也是pojo的所有属性;
14. * upsert可以指定匹配条件来判定,并且可以指定要更新的内容
15. */
16. /**
17. * 1. 插入
18. * 1.1 插入单个
19. */
20.// User oneUser = new User("lh", 31);
21.// mongoTemplate.insert(oneUser);
22.
23. /**
24. * 1.2 批量插入
25. */
26. User user1 = new User("1", "aa", 13, "f", Arrays.asList("daye", "wuhan"));
27. User user2 = new User("2", "bb", 33, "f", Arrays.asList("daye", "wuhan"));
28. User user3 = new User("3", "cc", 45, "m", Arrays.asList("daye", "wuhan"));
29. User user4 = new User("4", "dd", 23, "f", Arrays.asList("daye", "wuhan"));
30. User user5 = new User("5", "ee", 50, "m", Arrays.asList("daye", "wuhan"));
31. mongoTemplate.insertAll(Arrays.asList(user1, user2, user3, user4, user5));
32.
33. /**
34. * 2. 查询
35. */
36. User user = mongoTemplate.findOne(query(where("name").is("aaa")), User.class);
37. System.out.println(user);
38.
39. User user22 = mongoTemplate.findById("3", User.class);
40. System.out.println(user22);
41.
42. List users = mongoTemplate.findAll(User.class);
43. for (User userObj : users) {
44. System.out.println(userObj);
45. }
46.
47. /**
48. * 3. 更新
49. * 3.1 使用update
50. */
51.// mongoTemplate.updateFirst(query(where("name").is("zs")), update("age", "26"), User.class);
52.// mongoTemplate.updateMulti(query(where("name").is("zs")), update("age", "26"), User.class);
53.
54. /**
55. * 3.2 使用upsert
56. */
57. /**
58. * upsert和updateFirst类似,查找到文档然后进行更新,但是如果不存在就插入新的数据,插入的数据是
59. * query中的文档和update中的文档的结合。
60. */
61. mongoTemplate.upsert(query(where("name").is("jwli")), update("age", 26), User.class);
62.
63. /**
64. * 3.3 使用findAndModify
65. */
66.// /**
67.// * findAndModify功能更强大,集成了updateFirst和upsert,并且可以设置是否返回新设置的值
68.// */
69.// User newUser = mongoTemplate.findAndModify(query(where("name").is("jwli")), update("age", 31),
70.// new FindAndModifyOptions().returnNew(true).upsert(true), User.class);
71.//
72.
73. /**
74. * 4. 删除
75. */
76. User user33 = mongoTemplate.findOne(query(where("name").is("jwli")), User.class);
77. System.out.println(user33);
78. mongoTemplate.remove(user33);
79.
80.
81. /**
82. * 还有findAndReplace, remove等各种API,大家可以去官网上查阅
83. */
84.
}
- MongoTemplate****的bean xml配置
·
·
·
·
·
·
·
·
·
·
1.3 MongoTemplate的聚合查询
1.3.1 Aggregate
- 2****个概念:pipeline(管道)和stage(阶段)
mongodb中的Aggregate的管道其实就是一个操作的流水线,每个操作对应一个stage(阶段),每个stage的输出,作为下一stage的输入。如下图:
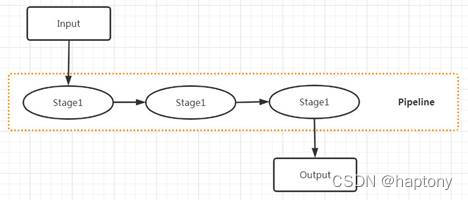
管道做的事归结起来就两点:重新映射文档,产生聚合数据,后面的介绍中可以看到。
- 聚合操作
聚合操作就是一系列的过滤、分组、排序等stage的集合(也即一个管道操作)。下图展示最简单的聚合操作:

- 代码实现
o 例1:基本使用
· @Test
· public void testAggregate01(){
· /**
· * 1. 形式1
· */
· // ProjectionOperation.ProjectionOperationBuilder projectionOperationBuilder =
· // Aggregation.project("name", "age", "gender").and("address");
· // GroupOperation groupOp = Aggregation.group("name").count().as("num");
· // ProjectionOperation projectionOperation2 = Aggregation.project("num").and("name2").previousOperation();
· // SortOperation sortOperation = Aggregation.sort(DESC, "num");
· // List aggregationOperation =
· // Arrays.asList(projectionOperationBuilder, groupOp, projectionOperation2, sortOperation);
· // Aggregation agg = newAggregation(aggregationOperation);
·
· /**
· * 2. 形式2
· */
· Aggregation agg = newAggregation(
· project("name", "age", "gender").and("address"), // 选出哪些列参与聚合
· group("name").count().as("num"), // 对name字段进行分组并进行count计数,统计结果取名num
· project("num").and("name2").previousOperation(), // 选出聚合结果中的num列,将上一个聚合操作gruop的id列(name)也选出来并取名为name2
· sort(DESC, "num")
· );
· // 聚合操作
· AggregationResults results = mongoTemplate.aggregate(agg, "user", UserAggInfo.class);
· List mappedResults = results.getMappedResults();
· for (UserAggInfo mappedResult : mappedResults) {
· System.out.println(mappedResult);
· }
}
实体类:
package cs.entity;
public class UserAggInfo{
String num;
String name2;
public String getNum() {
return num;
}
public void setNum(String num) {
this.num = num;
}
public String getName2() {
return name2;
}
public void setName2(String name2) {
this.name2 = name2;
}
@Override
public String toString() {
return "[" + this.name2 + ":" + this.num + "]";
}
}
o 例2:模拟项目中的一个类型转换错误
o @Test
o public void testAggregate02(){
o Aggregation agg = newAggregation(
o match(where("age").gt(30)),
o unwind("address"), // 将类型为数组的列拆分成多个文档,每个文档的字段名为原字段名,值为每个数组元素。unwind之后投影的列名还是保持原样
o group("name").addToSet("address").as("addss") , // 对name字段进行分组并进行count计数,统计结果取名num
o // 这一步只会产生一个列名addss,name只是作为分组id,不会作为列名
o project("addss").and("name2").previousOperation(), // 选出聚合结果中的addss列,将上一个聚合操作gruop id列(name)也选出来并取名为name2
o sort(DESC, "name2")
o );
o /**
o * 模拟List转为String错误
o */
o AggregationResults results = mongoTemplate.aggregate(agg, "user", UserAggInfo2.class);
o List mappedResults = results.getMappedResults();
o for (UserAggInfo2 mappedResult : mappedResults) {
o System.out.println(mappedResult);
o }
}
实体:
package cs.entity;
import java.util.List;
public class UserAggInfo2{
List addss;
String name2;
public List getAddss() {
return addss;
}
public void setAddss(List addss) {
this.addss = addss;
}
public String getName() {
return name2;
}
public void setName(String name2) {
this.name2 = name2;
}
@Override
public String toString() {
return "[" + this.name2 + ":" + this.addss + "]";
}
}
注:
GroupOperation.push和addToSet方法,对应mongodb的 g r o u p 中 的 group中的 group中的push和$addToSet,这2个操作符作用类似,故只以push为例。类比关系型数据库的group by,分组后,select能选择的列,都只能是与分组相关的数据,比如最大值最小值平均值或者是分组的key值,但是push是将操作得到的结果生成数组,并且取一个别名,具体地,是将push后面的表达式作用于分组中的每条记录,得到一个数组,将此数组作为一个结果返回,这个结果就和平均值最大值最小值一样,都是【分组相关的数据】了。push和addToSet的区别,前者不对数组元素去重,后者去重。
1.3.2 MapReduce
- 简介
MapReduce****是一种并行计算的编程模型,对于复杂任务,总是能抽象成map和reduce两个处理流程。所谓map操作,就是对一批实体数据的字段和值进行重新映射(字段和值就是一对映射),所谓reduce,就是将map的的结果进行聚合操作,如求最大值,最小值,平均值等。将map和reduce均拆分成多个子任务,使它们均能被多个处理程序并行处理。例如,统计1000万份文档中的词频(假设所有文档中出现的单词只有3000个),那么最终我们想得到3000个{“单词N”: 数量}这种数据,怎么做呢?在横向上,将1000万个文档分配到10000台机器(mapper)上,每台机器只负责1000个文档的统计,各个mapper的处理过程是并行的, 所以理论上时间会压缩10000倍;在纵向上,3000个单词分配到100台机器(reducer)上,每个机器只处理其中30个单词的统计,各个reducer的处理过程也是并行的,所以理论上时间会再压缩1000倍。如下图:

mongodb中的map-reduce也借鉴了这一模型,不过我们更关注它的map和reduce操作,并行计算并没有涉及,可以理解成上面例子中的单个mapper和单个reducer,简言之,就是使用map方法重新映射字段和值,然后使用reduce方法进行聚合。如下图:
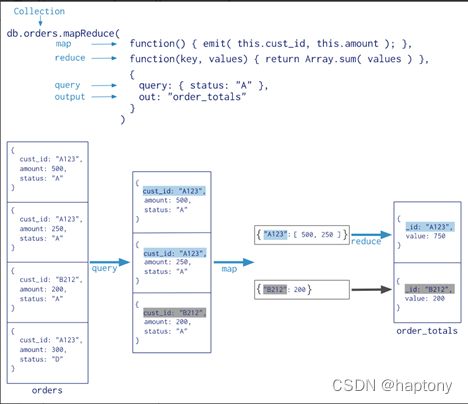
- Mongodb****中使用mapreduce
· var mapFunction2 = function() {
· for (var idx = 0; idx < this.items.length; idx++) {
· var key = this.items[idx].sku;
· var value = { count: 1, qty: this.items[idx].qty };
·
· emit(key, value);
· }
· };
· // 注意,如果key只有1个,不会走reduce方法!
· var reduceFunction2 = function(keySKU, countObjVals) {
· // 注意,这里取名必须与map函数中的一致,也就是必须是count, qty!
· reducedVal = { count: countObjVals[0].count, qty: countObjVals[0].qty, info:"aaa" };
·
· for (var idx = 1; idx < countObjVals.length; idx++) {
· reducedVal.count += countObjVals[idx].count;
· reducedVal.qty += countObjVals[idx].qty;
· }
·
· return reducedVal;
· };
·
· var finalizeFunction2 = function (key, reducedVal) {
· reducedVal.avg = reducedVal.qty/reducedVal.count;
· return reducedVal;
· };
·
· db.orders.mapReduce(
· mapFunction2,
· reduceFunction2,
· {
· out: { merge: "map_reduce_example2" },
· query: { ord_date: { $gte: new Date("2020-03-01") } },
· finalize: finalizeFunction2
· }
);
- 代码实现
· @Test
· public void testMapReduce02() throws Exception {
· // java的Date类型与mongodb的Date类型对应
· Date date = new SimpleDateFormat("yyyy-MM-dd").parse("2020-03-10");
· MapReduceResults results = mongoTemplate.mapReduce(query(where("ord_date").gte(date)),
· "orders", "classpath:map02.js", "classpath:reduce02.js",
· options().outputCollection("map_reduce_out2").finalizeFunction("function(key, countVals){\n" +
· " countVals.avg = countVals.qty / countVals.count;\n" +
· " return countVals;\n" +
· "}"), ValueObject02.class);
· // MapReduceResults results = mongoTemplate.mapReduce(query(where("ord_date").gte(date)),
· // "orders", "classpath:map02.js", "classpath:reduce02.js",
· // options().outputCollection("map_reduce_out2").finalizeFunction("classpath:finalize02.js"),
· // ValueObject02.class);
· for (ValueObject02 result : results) {
· System.out.println(result);
· }
·
}
1.3.3 聚合操作和MapReduce对比
Aggregation pipeline****比mapreduce有更好的性能和更清晰的语法,并且大量的mapreduce操作都和aggregate中的操作等价,但是mapreduce的很多操作都更灵活,例如,处理一个文档时,map-reduce可以有多个key-value映射,也可以一个都没有; mapreduce还可以使用自定义的js函数对处理的结果进行最终的处理等。
在项目中,可以根据具体场景来选用。
1.3.4 Group操作
Mongodb官网上说了,group方法(不是 g r o u p 操 作 符 ) 从 3.4 版 开 始 , 被 废 弃 了 , 可 以 用 聚 合 操 作 中 的 group操作符)从3.4版开始,被废弃了,可以用聚合操作中的 group操作符)从3.4版开始,被废弃了,可以用聚合操作中的group或者Mapreduce取代,所以这里不再讲解,之所以提一下,是因为我有看到springdata-mongodb有group方法,我很好奇它和聚合操作有什么区别。有兴趣的可以研究下mongodb官网3.4版本以前的group方法以及spring官网中mongoTemplate的group方法。
1.3.5 Bucket聚合
Mongodb中还有一种聚合bucket(桶)聚合聚合,对应mongodb的aggregate操作中的$bucket阶段。
前面讲的聚合都是根据分组字段的具体值进行分组的,而bucket****是根据分组字段的区间进行分组的,具体地,是将每个区间作为一个分组(桶),Mongodb会自动遍历每个文档,决定每个文档属于哪个分组(桶)(落在哪个区间),然后我们对分组(桶)内的文档进行聚合,聚合后,每个分组(桶)以一个文档输出,文档的id值就是区间的下界值。
- Mongodb****中使用$bucket语法:
- 语法:
2. {
3. $bucket: {
4. groupBy: ,
5. boundaries: [ , , ... ],
6. default: ,
7. output: {
8. : { <$accumulator expression> },
9. ...
10. : { <$accumulator expression> }
11. }
12. }
}
13.使用
14.db.user.aggregate([
15. {
16. $bucket: {
17. groupBy: "$age",
18. boundaries: [10, 20, 30],
19. default: "other",
20. output: {
21. "count": {$sum: 1},
22. "maxAge": {$max: "$age"},
23. "name": {$addToSet: "$name"}
24. }
25. }
26. }
])
// 多面bucket操作
db.user.aggregate([
{
$facet: {
info1: [
{
$bucket: {
groupBy: "$age",
boundaries: [0, 30, 60, 100],
default: "other",
output: {
"name": {$addToSet: "$name"},
"maxAge": {$max: "$age"}
}
}
}
],
info2: [
{
$bucket: {
groupBy: "$age",
boundaries: [0, 50, 100],
default: "other",
output: {
"info": {
$addToSet: {$concat: ["$name", ":", "_id"]}
}
}
}
}
]
}
}
])
**注:**这两段脚本的运行结果最好用json视图查看,不然会很晕。
·
· 代码实现
· @Test
· public void testBucket(){
· Aggregation agg = newAggregation(
· bucket("age").withBoundaries(10, 20, 30).withDefaultBucket("other")
· .andOutputCount().as("count2").andOutput("age").max().as("maxAge")
· .andOutput("name").addToSet().as("name")
· );
· // 聚合操作
· AggregationResultsbucketAuto不需要手动指定边界,它会根据我们指定的个数,来自动划定区间,并且以区间的左右临界值组成文档后作为id的值,形如“_id”: {“min”:0, “max”:40}。
· group****聚合和桶聚合的区别是什么?
前者是根据分组字段的某个具体的值进行分组,后者是根据分组字段的区间进行分组,而它们内部的聚合操作本质上是一样的。
2. MongoRepository
2.1 简介
MongoRepository对MongoTemplate进行了封装,前面讲的都是MongoTemplate的用法,现在再看看MongoRepository的用法。使用MongoRepository,我们只需要自己写一个接口(其实是一个代理),继承MongoRepository接口,然后就可以直接使用了, 之所以可以直接使用,是因为MongoRepository有如下的继承结构:

并且,我们的自定义接口实际上是一个动态代理,代理的MongoRepository,具体是SimpleMongoRepository对象。进行数据库操作时,代理对象内部会调用目标对象SimpleMongoRepository中的相应方法。
定义了接口后,我们可以直接使用的方法(以查询方法为例),包括一系列增删改查,分页,排序等方法,如下:
findAll, findOne, findById, find, findAndRemove
以及一些符合命名规范的方法,如下:


还可以自己使用@Query注解来自定义查询方法(见后面的例子)。
哪里能看出来MongoRepository封装了MongoTemplate呢,看下面源码:
ArticleDao:

CrudRepository:
![]()
SimpleMongoRepository

2.2 基本CRUD
· dao
· package cs.dao;
·
· import cs.entity.Article;
· import org.springframework.data.mongodb.repository.MongoRepository;
· import org.springframework.data.mongodb.repository.Query;
·
· import java.util.List;
·
·
· /**
· * 注意,由于spring会使用动态代理产生实现类,所以并不需要我们自己注册该接口的子类对象到spring容器中,
· * spring底层会将代理子类的对象注册到spring容器中。
· */
· public interface ArticleDao extends MongoRepository {
· // 根据Repository的命名规则,可以自定义查询方法
· List findArticleByTitleLike(String title);
· List findByContentIsStartingWith(String startContent);
· @Query(value = "{$and: [{'_id': ?0}, {'title': /?1/}]}")
· List findArticle(String id, String title);
}
· Crud
· package cs.test;
·
· import cs.config.AppConfig;
· import cs.dao.ArticleDao;
· import cs.entity.Article;
· import org.junit.Test;
· import org.junit.runner.RunWith;
· import org.springframework.beans.factory.annotation.Autowired;
· import org.springframework.data.domain.Page;
· import org.springframework.data.domain.PageRequest;
· import org.springframework.data.domain.Pageable;
· import org.springframework.data.domain.Sort;
· import org.springframework.test.context.ContextConfiguration;
· import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
·
· import java.util.Arrays;
· import java.util.List;
·
· import static org.springframework.data.domain.Sort.Direction.DESC;
·
·
· @RunWith(SpringJUnit4ClassRunner.class)
· //@ContextConfiguration("classpath:applicationContext.xml")
· @ContextConfiguration(classes = AppConfig.class)
· public class TestMongoRepository {
· @Autowired
· private ArticleDao articleDao;
· @Test
· public void testSave(){
· Article article = new Article();
· article.setId("1");
· article.setTitle("China is developing fast.");
· article.setContent("Now, china is developing fast, it will exceed America soon.");
· // 当id已经存在时,save方法,会进行覆盖
· articleDao.save(article);
· }
·
· @Test
· public void testSaveBatch(){
· Article article = new Article();
· article.setId("2");
· article.setTitle("Good Fly.");
· article.setContent("Look! the bird is flying happily.");
·
· Article article3 = new Article();
· article3.setId("3");
· article3.setTitle("Yes you can.");
· article3.setContent("You can do it!");
· articleDao.saveAll(Arrays.asList(article, article3));
· }
·
· @Test
· public void testUpdate(){
· Article article = articleDao.findById("1").get();
· article.setTitle("Go well.");
· article.setContent("Don't be afraid, all will go well.");
· articleDao.save(article);
· }
·
· @Test
· public void testDelete(){
· // articleDao.deleteById("2");
· Article article = new Article();
· article.setId("3");
· // 只需要id相同即可删除
· articleDao.delete(article);
·
· // articleDao.deleteAll();
· }
·
· @Test
· /**
· * 使用MongoRepository自带的查询方法
· */
· public void testFind(){
·
· Article article = articleDao.findById("1").get();
· System.out.println(article);
· }
·
· @Test
· /**
· * 使用根据命名规则定义的查询方法
· */
· public void testQuryByConvention(){
· // like方法里不需要加%%
· List articles = articleDao.findArticleByTitleLike("China");
· for (Article article : articles) {
· System.out.println(article);
· }
·
· List articles1 = articleDao.findByContentIsStartingWith("You");
· for (Article article : articles1) {
· System.out.println(article);
· }
·
· List articles2 = articleDao.findArticle("1", "China");
· for (Article article : articles2) {
· System.out.println(article);
· }
· }
·
· @Test
· /**
· * 使用MongoRepository自动的方法进行分页和排序
· */
· public void testFindAllWithPage(){
· // 按title降序排列
· Sort sort = Sort.by(DESC, "titile");
· // 第2页,最大大小为1,页数从0开始,并排序
· Pageable pageable = PageRequest.of(0, 1, sort);
· Page pageData = articleDao.findAll(pageable);
· List articles = pageData.getContent(); // 获取当前页的内容
· long totalElements = pageData.getTotalElements(); // 获取全部元素的数量
· int totalPages = pageData.getTotalPages(); // 获取总页数
· for (Article article : articles) {
· System.out.println(article);
· }
· }
· }
3. MongoTemplate和MongoRepository对比
前面我们知道了,MongoRepository是对MongoTemplate的封装,但是实际开发中,这两者还是会存在选型问题的,该怎么选呢?通过上面的操作,我们看到,作为Dao层时,使用MongoRepository,我们不用自己写实现类就可以实现简单的增删改查,分页,排序等,但是复杂的操作,就比较费劲了;而使用MongoTemplate时,需要自己去写CRUD操作,但是这些操作都可以自己控制,所以可以拼很复杂的查询,并且它支持聚合操作。
所以在实际开发中,对于简单的操作,可以直接使用MongoRepository; 对于复杂的操作和聚合查询等,就使用MongoTemplate,或者有的情境下,可以两者混用。