推荐算法面试集锦--算法模型
- youtubeNet和sdm对比
两者均是基于用户历史行为序列进行召回,均采用ANN向量检索的方式。YoutubeNet网络结构更简单,SDM使用长短期兴趣网络结合的方式,采用多头attention机制,降低序列中不稳定点击的影响,增加不同兴趣点的挖掘,更有利于深入挖掘历史序列中的item之间的联系,做出更多多样性的探索。
在SDM实际的应用中,对于电商商品推荐的产品,在处理数据集样本的时候,历史长短期session的定义比较灵活,在数据量不是足够多的情况下,可以采用限制长、短期相对长度的方法构造所谓的session。序列前后是否去重对于离线测试的召回率影响较大。实际测试中发现推荐历史序列里的物品效果往往会更好。 - 深度学习面试50题:https://zhuanlan.zhihu.com/p/231171098
- attention原理与作用
本质上是从关注全部到关注重点。
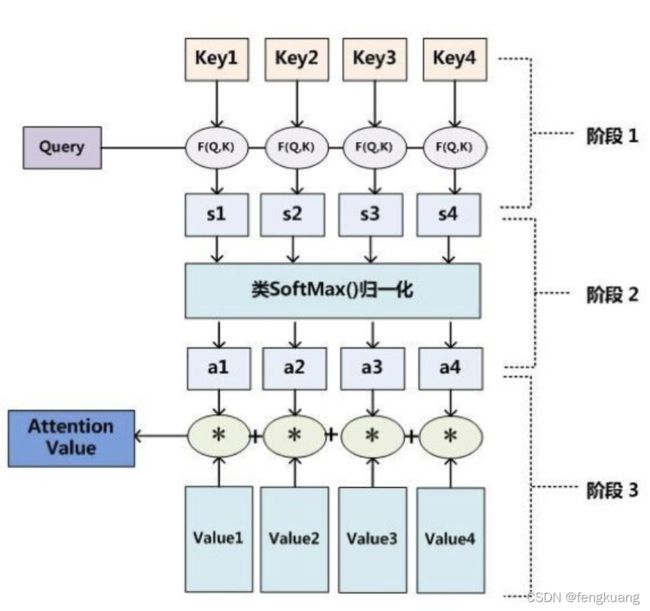
优点:参数少,速度快,效果好。
在计算attention时主要分为三步:
- 第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;
- 第二步一般是使用一个softmax函数对这些权重进行归一化;
- 最后将权重和相应的键值value进行加权求和得到最后的attention。通常key和value常常都是同一个,即key=value。
- FM原理及应用:FM因子分解机的原理、公式推导、Python实现和应用
FM用于特征交叉的稀疏高维矩阵的因式分解训练,对于用户和物品冷启动样本比较友好。当交叉特征共现样本少的情况下,依然能对交叉特征进行有效学习训练。
FM模型重要的超参:
- 迭代次数
- regParams(r0, r1, r2)
- k 特征分解向量的维度
- stepSize: weightsNew(i) = weightsOld(i) - thisIterStepSize * (gradient(i) + r1 * weightsOld(i))
- optimizer:SGD,ALS,LBFGS
FM模型应用之召回:https://zhuanlan.zhihu.com/p/58160982
FM做统一召回与多路召回优缺点对比:
- FM可将多路召回增减变成特征级别的增减,容易在下游排序模型中体现该特征,减少召回与排序迭代的不一致。但每次都要训练新模型,灵活度上不高
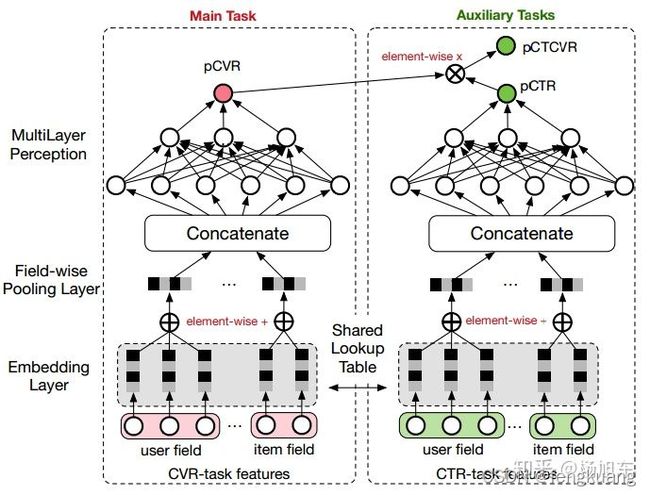
- ESMM多目标排序模型:CVR预估的新思路:完整空间多任务模型
多目标网络结构的任务训练表达式:pCTCVR = pCVR * pCTR
适用于子任务具有链式依赖关系的多任务场景中,且ESMM提出的动机是为了解决推荐系统中的样本选择偏差(Sample Selection Bias,SSB)和数据稀疏性(Data Sparisity,DS)问题。ctr和cvr贡献底层embedding,对于cvr任务来说,也可以学习到ctr的信息,这对于两个很相关的任务一般是正向的。直接优化的是ctr和ctcvr,所以可以直接拿曝光全域的数据来做,而不是选取曝光点击的部分数据单独的去做cvr。典型的shared-bottom结构。多任务学习中有个问题就是如果子任务差异很大,往往导致多任务模型效果不佳。
- GBDT与GBRT区别
GBDT用于解决二分类任务,GBRT用于解决回归问题。损失函数不同,前者是MSE,后者是交叉熵损失函数。GBRT可以用于解决分类任务,需要确定一个阈值来实现转化成分类标签。 - xgb与GBDT区别
-
两者都属于boosting方法,但是基学习器不同,gbdt一般使用CART决策树(基于gini指数计算增益)或者ID3算法(采用entropy计算增益)、ID4.5(采用信息增益率),xgb除CART外还可以支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。xgb采用的树节点分裂采用的增益计算根据目标函数倒推的融入一阶导、二阶导。
- 决策树ID3,ID4.5,CART
- xgb增益计算方法:

-
目标函数不同,xgb支持自定义,gbdt只有交叉熵损失,且xgb损失函数中加入了针对树节点数和叶子值L2正则项,降低树结构风险和经验风险,降低过拟合风险。xgb目标函数:


-
对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
-
工程优化,并行计算:
- 特征粒度:特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
- wide&deep模型原理及其应用
Wide&Deep模型的主要思路正如其名,是由单层的Wide部分和多层的Deep部分组成的混合模型。其中,Wide部分的主要作用是让模型具有较强的“记忆能力”;Deep部分的主要作用是让模型具有“泛化能力”,正是这样的结构特点,使模型兼具了逻辑回归和深度神经网络的优点-----能够快速处理并记忆大量历史行为特征,并且具有强大的表达能力,不仅在当时迅速成为业界争相应用的主流模型,而且衍生出了大量以Wide&Deep模型为基础结构的混合模型,影响力一直延续至今。
wide的部分和deep的部分使用其输出对数几率的加权和作为预测,然后将其输入到联合训练的一个共同的逻辑损失函数。注意到这里的联合训练和集成学习是有区别的。 - LSTM模型原理及应用
LSTM是循环神经网络RNN的变种,包含三个门,分别是输入门,遗忘门和输出门。
LSTM 与 GRU区别
- LSTM和GRU的性能在很多任务上不分伯仲;
- GRU参数更少,因此更容易收敛,但是在大数据集的情况下,LSTM性能表现更好;
- GRU 只有两个门(update和reset),LSTM 有三个门(forget,input,output),GRU 直接将hidden state 传给下一个单元,而 LSTM 用memory cell 把hidden state 包装起来。
-
LinUCB模型原理及应用
LinUCB(Linear Upper Confidence Bound)是一种context feature-based bandit算法。线性指的是它采用了线性奖赏函数。UCB就是以均值的置信上限为来代表它的预估值即. UCB思想是乐观地面对不确定性,以item回报的置信上限作为回报预估值的一类算法,其基本思想是:我们对某个item尝试的次数越多,对该item回报估计的置信区间越窄、估计的不确定性降低,那些均值更大的item倾向于被多次选择,这是算法保守的部分(exploitation)对某个item的尝试次数越少,置信区间越宽,不确定性较高,置信区间较宽的item倾向于被多次选择,这是算法激进的部分exploration。
LinUCB算法
总结一下LinUCB算法,有以下优点:
1)由于加入了特征,所以收敛比UCB更快(论文有证明);
2)特征构建是效果的关键,也是工程上最麻烦和值的发挥的地方;
3)由于参与计算的是特征,所以可以处理动态的推荐候选池,编辑可以增删文章;
4)特征降维很有必要,关系到计算效率。
5)是一种在线学习算法。 -
HNSW算法原理及应用: HNSW原理及应用
HNSW(Hierarchical Navigable Small World)首先理解NSW小世界网络,小世界网络是介于随机图和正则图之间的一种网络结构。NSW算法基于六度分离理论将小世界的特性用于近邻检索, 提出了基于图结构的检索方案。
在NSW的基础上,HNSW利用多层的图结构来完成图的构建和检索,使得通过将节点随机划分到不同的layer, 从上层图到下层图的检索中,越往下层节点之间的距离越近, 随机性也越差,聚类系数越高。 HNSW通过从上到下的检索,完成了NSW中Long Link高速公路快速检索的作用,通过最后底层的近邻检索, 完成局部最近邻的查找。 -
Logistic逻辑回归模型
逻辑回归是一种广义线性分类模型,假设因变量y遵循伯努利分布,自变量x遵循高斯分布,利用逻辑函数sigmoid引入非线性因素,通过极大似然的方法,运用梯度下降法来求解参数,轻松处理0/1二分类问题。 -
艺术图片情感多模态模型ArtEmis
- 共享卷积网络抽取特征向量
- 文本网络:原始模型采用一句英文描述作为标签;采用TimeDistributed层、BiLSTM、AttentionDecoder
- 图片网络:情感类别作为类别标签的多分类网络
-
YoutubeNet模型
原理:利用softmax将召回转化成一个多分类问题,学习user和item的向量,实现向量召回。
网络结构:
-
SDM深度序列召回模型
原理:目前在工业界中基于物品的协同过滤算放被广泛应用于召回。然而,这种方法无法有效的对用户动态的不断变化的偏好建模。SDM模型对用户短期会话(short-term sessions)和长期行为(long-term behaviors)建模,来捕捉用户动态偏好。
SDM提出了两个相应的组件来对用户行为序列建模:- multi-head self-attention module:其用于捕捉多种类型的特征
- long-short term gated fusion module:其用户融合长短期特征
网络结构:

-
常用的embedding模型有哪些? 推荐系统 embedding 技术实践总结
- 词向量:word2vec, item2vec; DSSM, YoutubeNet, SDM
- hash embedding:通过哈希函数,简单粗暴的embedding方法
- Graph Embedding: Deep walk; EGES;Node2vec
-
如何评价embedding质量?
目前没有标准方案,embedding的获得来源于某种确定的模型,比如word2vec或者SDM,那么在线下测试的时候,通常还要跟向量召回的具体工具有关系(通常用faiss、HNSW等)。在召回阶段的话,可以通过构造测试集,对召回率进行对比。 -
CTR都有哪些模型?
CTR预估模型可粗糙的分为浅层模型和深层模型。一些代表包括:- 浅层模型:LR, Degree-2 Polynomial, FM, FFM, FwFM以及本文的FvFM和FmFM
- 深层模型:FNN、PNN、Wide&Deep, DeepFM, xDeepFM, AutoInt等
-
FmFm模型原理及应用:优雅的浅层CTR模型FmFM(Field-matrixed FM, FwFM改进版)
FM, FwFM, FvFM模型都可以被统一到FmFM框架下。
Factorization Machines (FM):对Poly2中的权重矩阵W做矩阵分解,为每个特征学一个k为的向量表示。两个向量的内积表示特征对的重要性。
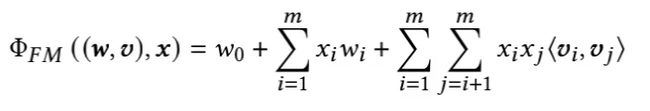
- 优点:FM可以捕获特征交互,同时可以在稀疏场景下有效的学习。
- 缺点:FM忽略了这样一个事实: 当一个特性与来自其他域(Field)的特性交互时,它的行为可能会有所不同。
Field-aware Factorization Machines (FFM):为每个特征学习n-1(n为feild个数)个向量表示,与来自不同域的特征交互时使用不同的向量表示。

- 优点:FFM可以捕获特征交互,考虑了Field信息。
- 缺点:参数量为O(m+mnk), 在实际的生产系统中,FFM中大量的参数是不可接受的。
Field-weighted Factorization Machines (FwFM):显式地建模了不同的Field相互交互的强度。
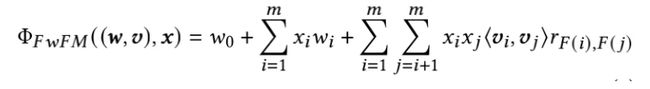
- 优点:FwFM可以捕获特征交互,考虑了Field信息,相比FM仅仅增加了n*(n-1)/2个需要学习的参数(n一般仅为几十或几百),仅用FFM 4%左右的参数便可达到相媲美的效果[2]。FwFM已经被部署到很多大厂的广告系统中。
- 缺点:FwFM仅用一个标量来表达域交互的强度,自由度不够、表达能力有限。
Field-matrixed Factorization Machines (FmFM): 相比于FwFM仅用一个标量r来建模域交互的强度,FmFM用了自由度更高的matrix。形式化描述为:

模型的计算过程可以分为三步:(对应下图由底向上)
-
Embedding Lookup: 从Embedding table中找到三个特征的向量 ;
-
Transformation: ,分别计算,获得两组对应的中间向量
-
Dot product: 最后通过简单的点积计算获得最后的交互项。

- LFM、SVD、SVD++、FM原理及区别
LFM
(Latent Factor Model)隐语义模型,核心思想是通过隐含特征(Latent factor)联系用户和物品,该算法最早在文本挖掘领域中被提出用于找到文本的隐含语义。LFM 在建模过程中,假设有 M * 个用户、 N 个物品、 K 条用户对物品的行为记录,如果是 F 个隐类,那么它离线计算的空间复杂度是 (∗(+)) ,迭代 S次则时间复杂度为 (∗∗)。当 M(用户数量)和 N(物品数量)很大时LFM相对于ItemCF和UserCF可以很好地节省离线计算的内存,在时间复杂度由于LFM会多次迭代上所以和ItemCF、UserCF*没有质的差别。
同时,遗憾的是,LFM 无法进行在线实时推荐,即当用户有了新的行为后,他的推荐列表不会发生变化。而从 LFM的预测公式可以看到, LFM 在给用户生成推荐列表时,需要计算用户对所有物品的兴趣权重,然后排名,返回权重最大的 N 个物品。那么,在物品数很多时,这一过程的时间复杂度非常高,可达 (∗∗) 。因此, LFM 不太适合用于物品数非常庞大的系统,如果要用,我们也需要一个比较快的算法给用户先计算一个比较小的候选列表,然后再用LFM重新排名。另一方面,LFM 在生成一个用户推荐列表时速度太慢,因此不能在线实时计算,而需要离线将所有用户的推荐结果事先计算好存储在数据库中。
SVD
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设我们的矩阵A是一个m×n的矩阵,那么我们定义矩阵A的SVD为:
![]()
其中 U是一个 m x m 的矩阵, Σ \Sigma Σ 是一个 m x n 的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V 是一个 n x n的矩阵。 U和 V 都是酉矩阵,即满足 U T U = I , V T V = I \mathbf{U}^\mathsf{T}\mathbf{U}=I, \mathbf{V}^\mathsf{T}\mathbf{V}=I UTU=I,VTV=I
由于SVD可以实现并行化,因此更是大展身手。
![]()
SVD++
在实际应用中,会存在以下情况:相比于其他用户,有些用户给分就是偏高或偏低。相比于其他物品,有些物品就是能得到偏高的评分。
SVD++ 就是在 SVD 模型中融入用户对物品的隐式行为。我们可以认为 评分=显式兴趣 + 隐式兴趣 + 偏见。

其中, Σ x u \Sigma{\mathbf{x}_u} Σxu是指用户u看过的所有的电影的向量的和,N是看过的电影总和,除以N是为了平均,N开根号是为了两两内积方便。
我们先讨论了LFM然后引出MF然后SVD SVD++,以上这些LFM技术我们都可以认为是FM。
FM是指因子分解机,即将一个矩阵分解成两个矩阵相乘,具体到点击率预估处,我们使用FM做一层embedding(即WX),然后再内积进行二阶特征组合。
21. LDA模型原理及应用。
在机器学习领域,LDA是两个常用模型的简称:Linear Discriminant Analysis 和 Latent Dirichlet Allocation。这里指的是后者,LDA 在主题模型中占有非常重要的地位,常用来文本分类,推测文档的主题分布。
LDA涉及到的先验知识有:二项分布、Gamma函数、Beta分布、多项分布、Dirichlet分布、马尔科夫链、MCMC、Gibs Sampling、EM算法等。
Beta分布可以用Gamma函数表示;beta分布是二项分布的共轭先验分布,dirichlet分布是多项分布的共轭先验分布。
先验分布为Dirichlet分布+多向分布的数据知识 = 后验分布为dirichlet的分布

