语义分割-CyCADA: Cycle-Consistent Adversarial Domain Adaptation.循环一致对抗领域自适应
CyCADA: Cycle-Consistent Adversarial Domain Adaptation.
- 0.摘要
- 1.概述
- 2.相关工作
- 3.循环一致性对抗领域自适应
- 4.实验
-
- 4.1.数字数据集适应
- 4.2.语义分割自适应
-
- 4.2.1.季节之间的自适应
- 4.2.2.虚拟到现实之间的适应
- 5.结论
- 6.附加内容
-
- 6.1.应用细节
-
- 6.2.2.语义分割实验
论文地址
代码地址
0.摘要
领域适应对于在新的、看不见的环境中取得成功至关重要。应用于特征空间的对抗性适应模型可以发现域不变的表示,但很难可视化,有时无法捕获像素级和低级别的域偏移。最近的研究表明,生成性对抗网络与周期一致性约束相结合,即使不使用对齐的图像对,在域之间映射图像时也出人意料地有效。我们提出了一种新的区分训练周期一致性对抗域适应模型。CyCADA在像素级和功能级都适应表示,在利用任务丢失的同时加强循环一致性,并且不需要对齐对。我们的模型可以应用于各种视觉识别和预测设置。我们展示了多种适应任务的最新成果,包括数字分类和道路场景的语义分割,展示了从合成域到现实域的转换。
1.概述
深度神经网络擅长从大量数据中学习,但在将所学知识推广到新的数据集或环境方面可能很差。即使稍微偏离网络的训练领域,也可能导致网络做出虚假预测,并严重损害其性能(Tzeng等人,2017年)。视觉领域从非照片级真实感合成数据向真实图像的转变带来了更大的挑战。虽然我们希望根据大量合成数据(如从图形游戏引擎收集的数据)来训练模型,但此类模型无法推广到真实世界的图像。例如,在合成dashcam数据上训练的最先进的语义分割模型无法在真实图像中分割道路,其整体每像素标签精度从93%(如果在真实图像上训练)下降到54%(如果仅在合成数据上训练,见表6)。
特征级无监督域自适应方法通过在源域(例如合成域)和目标域(例如真实域)之间对齐从网络中提取的特征来解决这个问题,而不需要任何标记的目标样本。校准通常涉及最小化源和目标特征分布之间距离的一些度量,例如最大平均差异(Long&Wang,2015)、相关距离(Sun&Saenko,2016)或对抗性鉴别器精度(加宁和莱姆皮茨基,2015;曾等,2017)。这类技术有两个主要局限性。首先,对齐边缘分布并不强制任何语义一致性,例如,汽车的目标特征可能映射到自行车的源特征。第二,深层表征的更高层次上的对齐可能无法模拟对最终视觉任务至关重要的低层次外观差异。
生成像素级域自适应模型不在特征空间中执行类似的分布对齐,而是在原始像素空间中执行类似的分布对齐,将源数据转换为目标域的“样式”。最近的方法可以学习在两个领域仅提供无监督数据的情况下翻译图像(Bousmalis等人,2017b;Liu&Tuzel,2016b;Shrivastava等人,2017)。结果在视觉上令人信服,但此类图像空间模型仅适用于较小的图像大小和有限的域移动。最近的一种方法(Bousmalis等人,2017a)适用于更大(但仍然不是高分辨率)的图像,但适用于机器人应用的视觉控制图像。此外,它们也不一定保留内容:虽然翻译后的图像可能“看起来”像来自正确的域,但关键的语义信息可能会丢失。例如,一个从线条图改编为照片的模型可以学会让猫的线条图看起来像狗的照片。
我们如何鼓励模型在分布对齐过程中保留语义信息?在本文中,我们探索了一个简单而强大的想法:为模型提供一个额外的目标,从修改后的版本重建原始数据。循环一致性最近在跨域图像生成GAN模型CycleGAN(Zhu等人,2017)中提出,该模型显示了图像到图像的转换生成结果,但对任何特定任务都是不确定的
我们提出了循环一致对抗域适应算法(CyCADA),该算法在像素级和特征级对表示进行适应,同时通过像素循环一致性和语义损失实现局部和全局结构一致性。CyCADA整合了之前的特征级别(Ganin & Lempitsky, 2015;Tzeng等人,2017)和图像级别(Liu & Tuzel, 2016b;Bousmalis等,2017b;Shrivastava等人,2017)对抗域自适应方法和循环一致的图像到图像翻译技术(Zhu等人,2017),如表1所示。它适用于一系列深度架构和/或表示级别,与现有的无监督领域适应方法相比有几个优势。我们使用重构(循环一致性)损失来鼓励跨域转换以保留局部结构信息,使用语义损失来加强语义一致性。
我们将CyCADA模型应用于跨域数字识别和跨域城市场景语义分割。实验表明,我们的模型在数字适应、合成数据的跨季节适应和具有挑战性的合成到真实场景上都达到了最先进的结果。在后一种情况下,它将逐像素精度从54%提高到82%,接近于目标训练模型的差距。
我们的实验证实,领域自适应可以大大受益于循环一致的像素转换,这对于当代FCN架构的像素级语义分割尤其重要。此外,我们发现,像素级和表示级的自适应可以通过联合像素空间和特征自适应提供互补的改进,从而实现数字分类任务的最高执行模型。
2.相关工作
Saenko等人(2010)在引入两两度量变换解决方案的同时引入了视觉域自适应问题,并通过对视觉数据集偏差的广泛研究进一步推广了这一问题(Torralba & Efros, 2011)。早期的深度自适应研究通过最小化源和目标一阶或二阶特征空间统计量之间的距离来实现特征空间对齐(Tzeng et al., 2014;龙、王,2015)。通过使用领域对抗目标进一步改进了这些潜在分布对齐方法,在学习领域表示的同时训练领域分类器区分源和目标表示,从而最大限度地提高领域分类器的误差。使用标准极大极小目标(Ganin & Lempitsky, 2015)、对称混淆目标(Tzeng et al., 2015)或倒置标签目标(Tzeng et al., 2017)对表示进行了优化。这些目标都与生成式对抗网络相关的文献(Goodfellow等人,2014),以及改进这些网络培训程序的后续工作(Salimans等人,2016b;Arjovsky等人,2017)。
上面描述的特征空间自适应方法侧重于对区别表示空间的修改。相比之下,最近的其他方法则使用各种生成方法来寻求像素空间的适应性。正如我们所展示的,像素空间适应的一个优点是,结果可能更容易被人理解,因为来自一个领域的图像现在可以在一个新的领域中可视化。CoGANs (Liu & Tuzel, 2016b)通过特定层的显式权重共享共同学习源和目标表示,而每个源和目标都有一个独特的生成对抗目标。ghhifary等人(2016)在目标域中使用额外的重建目标,以鼓励在无监督的适应环境中对齐
相反,另一种方法是直接将目标图像转换为源样式的图像(或反之亦然),主要基于生成式对抗网络(GANs) (Goodfellow等人,2014)。研究人员已经成功地将GANs应用于各种应用,如图像生成(Denton et al., 2015;Radford等人,2015;Zhao等人,2016)、图像编辑(Zhu等人,2016)和特征学习(Salimans等人,2016a;Donahue等人,2017)。最近的工作(Isola et al., 2016;Sangkloy等人,2016;Karacan et al., 2016)对于这些图像到图像的翻译问题采用了条件GAN (Mirza & Osindero, 2014) (Isola et al., 2016),但它们需要输入-输出图像对进行训练,这在一般的领域自适应问题中是不可用的
也有一些行业没有提供这样的训练对。Yoo等人(2016)在用于预测人们穿着的服装的重建上学习一个源来目标编码器-解码器和生成对抗目标。域转移网络(Domain Transfer Network)(Taigman等人,2017b)通过增强嵌入空间的一致性,训练生成器将源图像转换为目标图像。Shrivastava等人(2017)使用L1重建损失来迫使生成的目标图像与原始源图像相似。这适用于像素空间中相似的有限域移动,但对于较大域移动的设置可能太过有限。Bousmalis等(2017b)使用内容相似度损失来确保生成的目标图像与原始源图像相似;然而,这需要预先知道图像的哪些部分跨域保持相同(例如前景)。我们的方法不需要预先定义域之间共享的内容,而是简单地将图像转换回它们的原始域,同时确保它们与原始版本保持一致。BiGAN (Donahue et al., 2017)和ALI (Dumoulin et al., 2016)采用了同时学习像素和潜在空间之间转换的方法。最近,循环一致性对抗网络(CycleGAN) (Zhu等人,2017)产生了引人注目的图像翻译结果,如从印象派绘画中生成逼真的图像,或使用循环一致性损失以高分辨率将马转化为斑马。这个损失同时由Yi et al.(2017)和Kim et al.(2017)提出,也产生了很大的影响。我们的动机来自于这些关于循环一致性损失有效性的发现。
明确地研究语义分割任务的视觉域适应问题的文献很少。Levinkov和Fritz(2013)首先研究了简单道路场景中天气条件的适应性。最近,一种基于卷积域对抗的方法被提出,用于更一般的驾驶场景,并用于从模拟环境到真实环境的适应(Hoffman等人,2016)。Ros等人(2016b)通过串联所有可用标记数据来学习多源模型,并学习单个大模型,然后通过蒸馏转移到稀疏标记的目标域(Hinton等人,2015)。Chen等人(2017)使用对抗目标来对齐全局和特定于类的统计数据,同时从街景数据集中挖掘额外的时间数据,以便提前了解静态对象。Zhang等人(2017)通过对齐图像中全球和超像素之间的标签分布来实现分割适应
3.循环一致性对抗领域自适应
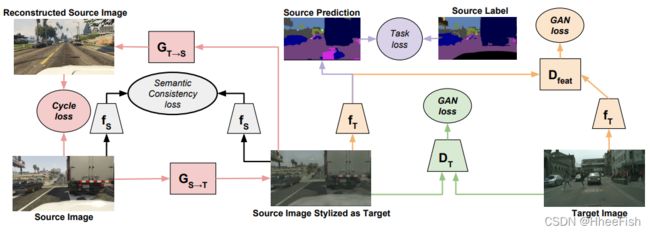
图2:像素空间输入的周期一致对抗适应。通过直接将源训练数据映射到目标域,我们消除了域之间的低级差异,确保我们的任务模型在目标数据上是良好的。我们在这里描述了图像级GAN损失(绿色)、特征级GAN损失(橙色)、源和目标语义一致性损失(黑色)、源周期损失(红色)和源任务损失(紫色)。为了清楚起见,省略了目标周期。
我们考虑无监督适应的问题,提供源数据XS、源标签YS和目标数据XT,但没有目标标签。目标是学习能够正确预测目标数据XT的标签的模型f。我们可以从学习可以在源数据上执行任务的源模型fS开始。对于交叉熵损失的k路分类,这对应于
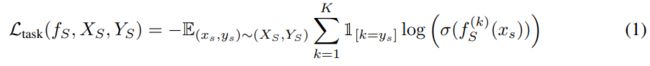
式中,σ为softmax函数。然而,虽然学习的模型fS可以在源数据上很好地执行,但通常情况下,在源和目标域之间的域转移会导致在评估目标数据时降低性能。为了减轻领域转移的影响,我们遵循之前的对抗适应方法,并学习跨领域映射样本,这样对抗鉴别器就无法区分领域。通过将样本映射到公共空间,我们可以使我们的模型在学习源数据的同时仍能泛化到目标数据。
为此,我们引入了一个从源到目标的GS→T映射,并训练它生成目标样本,愚弄对抗鉴别器DT。相反,对抗鉴别器试图从源目标数据中分类真实目标数据。这对应于损失函数
![]()
这一目标确保给定源样品的GS→T能产生令人信服的目标样品。反过来,这种在域之间直接映射样本的能力允许我们通过最小化Ltask(fT, GS→T(XS), YS)来学习目标模型fT(见图2绿色部分)。
然而,虽然以前优化类似目标的方法已经显示出有效的结果,但在实践中,它们往往不稳定,容易失败。虽然方程2中的GAN损耗保证了某些xs的GS→T (xs)与XT得出的数据相似,但无法保证GS→T(xs)保留了原始样本xs的结构或内容。
为了鼓励在转换过程中保存源内容,我们对自适应方法施加了循环一致性约束(Zhu et al., 2017;Yi等人,2017;Kim等人,2017)(见图2红色部分)。为此,我们引入另一种从目标到源GT→S的映射,并根据相同GAN损耗LGAN(GT→S, DS, XS, XT)对其进行训练。然后,我们要求将源样本从源映射到目标,并返回到源,从而复制原始样本,从而实现周期一致性。换句话说,我们希望GT→S(GS→T (xs))≈xs, GS→T (GT→S(xt))≈xt。这是通过对重构误差施加L1惩罚来实现的,这被称为循环一致性损失:
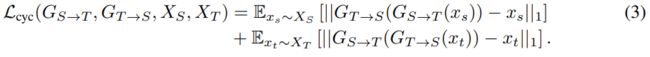
此外,由于我们可以访问源标记的数据,我们明确地鼓励图像翻译前后的高语义一致性。我们预先训练一个源任务模型fS,固定权重,我们使用这个模型作为一个有噪声的标签器,通过这个标签器,我们鼓励图像在翻译后按照与翻译前相同的方式进行分类。让我们为给定的输入X定义来自固定分类器f的预测标签为p(f, X) = argmax(f (X))。那么我们可以定义图像翻译前后的语义一致性,如下所示:

参见图2黑色部分。这可以被视为类似于风格转移(Gatys等人,2016)或像素适应(Taigman等人,2017a)中的内容损失,其中要保存的共享内容由源任务模型fS决定
到目前为止,我们已经描述了一种结合循环一致性、语义一致性和对抗目标来生成最终目标模型的自适应方法。作为一种像素级方法,对抗目标由一个鉴别器组成,用于区分两组图像集,如变换后的源图像和真实目标图像。注意,我们还可以考虑一种特征级方法,它可以区分在任务网络下查看的两个图像集的特征或语义。这将导致额外的特征级GAN损失(见图2的橙色部分):
![]()
综上所述,这些损失函数构成了我们的完整目标:

这最终对应的是根据优化问题求解目标模型fT
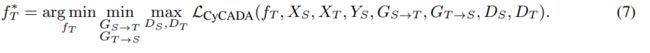
我们介绍了一种无监督自适应方法,它将对抗性目标概括为在像素或特征级别上操作。此外,我们引入了循环一致性和语义转换约束的使用,以引导从一个领域到另一个领域的映射。在这项工作中,我们将CyCADA应用于数字自适应和语义分割。我们将G实现为像素到像素的卷积网络,f实现为卷积分类器或全卷积网络(FCN), D实现为具有二进制输出的卷积网络。
4.实验
我们在几个无监督的适应场景中评估CyCADA。我们首先关注使用MNIST(LeCun et al.,1998)、USPS和街景房屋编号(SVHN)(Netzer et al.,2011)数据集对数字分类的适应性。之后,我们使用SYNTHIA(Ros et al.,2016a)、GTA(Richter et al.,2016)和CityScapes(Cordts et al.,2016)数据集展示语义图像分割任务的结果。
4.1.数字数据集适应

表2:跨数字数据集的无监督域自适应。我们的模型在每一次换班中都与最先进的模型相竞争,或优于最先进的模型。对于SVHN向MNIST的艰难转变,我们还注意到,除了仅像素自适应之外,特征空间自适应还提供了额外的好处。
我们在学习阶段使用完整的训练集,并在标准测试集上进行评估,评估USPS到MNIST、MNIST到USPS、SVHN到MNIST的适应转变。我们在表2中报告了每种变化的分类精度,并发现我们的方法平均优于竞争方法。我们用于所有数字移位的方法的分类器使用了LeNet架构的一种变体(有关完整的实现细节,请参见6.1.1)。请注意,Bousmalis等人(2017b)最近的像素级领域自适应方法仅给出了MNIST到USPS偏移的结果,并报告了95.9%的准确率,而我们的方法达到了95.6%的准确率。然而,像素级领域自适应方法与一些标记数据交叉验证,这些标记数据不是等效的评估设置。
消融实验:像素级与特征级转换。我们首先评估像素空间和特征空间转移的贡献。我们发现,在USPS和MNIST之间的小域转移的情况下,我们使用CycleGAN翻译的图像来训练分类器的像素空间自适应(Zhu等人,2017)表现非常好,优于或可与之前的自适应方法相比。在这种小像素偏移的情况下,功能级自适应提供了一个小好处。然而,对于SVHN向MNIST的更困难的转变,我们发现特征级自适应优于像素级自适应,重要的是,两者可以结合起来产生一个整体模型,其性能优于所有竞争方法。
消融实验:没有语义一致性(Semantic Consistency)。我们在不增加语义一致性损失的情况下进行了实验,发现标准的无监督CycleGAN方法在将SVHN训练为经常遭受随机标签翻转的MNIST时出现了分歧。图3(a)展示了两个示例,其中仅循环约束无法为我们的最终任务提供所需的行为。SVHN图像映射到令人信服的MNIST类型图像,并返回到具有正确语义的SVHN图像。然而,类似MNIST的图像具有不匹配的语义。我们的改进版本使用源标签来训练弱分类模型,该模型可用于在翻译前后加强语义一致性,解决了这个问题,并产生了强大的性能。

图3:语义或循环一致性的影响——没有语义一致性损失的翻译失败的例子。每个三元组包含原始SVHN图像(左)、翻译成MNIST样式的图像(中),以及重建回SVHN的图像(右)。(a) 在没有语义损失的情况下,可以同时满足GAN和cycle约束(翻译后的图像与MNIST风格匹配,重建后的图像与原始图像匹配),但翻译到目标域的图像缺乏正确的语义。(b) 在没有循环损失的情况下,重建并不令人满意,尽管语义一致性导致了一些成功的语义翻译(上图),但仍有标签翻转的情况(下图)。
4.2.语义分割自适应
该任务是为输入图像中的每个像素指定一个语义标签,例如道路、建筑等。我们将评估限制在无监督的自适应设置中,其中标签仅在源域中可用,但我们仅根据目标域中的性能进行评估。我们的三个评价指标分别是平均相交与并集(mIoU)、频率加权相交与并集(fwIoU)和像素精度。
周期一致对抗自适应是通用的,可以应用于网络的任何层。由于在公式6中优化完整的CyCADA目标在实践中是内存密集型的,所以我们分阶段训练我们的模型。
- 首先,我们执行图像空间适应并将源数据映射到目标域。
- 接下来,使用经过调整的源数据和原始源标签,我们了解了一个适合于操作目标数据的任务模型。
- 最后,利用任务模型的中间层,在特征空间中对调整后的源数据和目标数据进行另一轮适配。
此外,我们在分割实验中不使用语义损失,因为它需要将生成器、鉴别器和一个额外的语义分割器同时加载到内存中。在提交的时候,我们没有所需的内存,但把它留给未来的工作来部署模型并行性或使用更大的GPU内存进行实验。
对于我们的第一个评估,我们考虑SYNTHIA数据集(Ros等人,2016a),它包含城市场景的合成渲染。我们使用SYNTHIA视频序列,它在各种环境、天气条件和光照条件下呈现。这为评估适应技术提供了一个综合试验台。与之前的工作相比,我们的工作重点是季节之间的适应。我们在序列中只使用了正面的视图,以模仿行车记录仪的图像,并适应从秋天到冬天。我们使用的数据集的子集包含13个类,包括10,852张秋季图像和7,654张冬季图像。
为了进一步证明我们的方法对现实世界适应场景的适用性,我们还在一个具有挑战性的合成到现实适应场景中评估了我们的模型。对于我们的合成源域,我们使用从游戏《侠盗猎车手V》中提取的GTA5数据集(Richter et al., 2016),其中包含24966张图像。我们考虑从GTA5到真实世界的城市景观数据集(Cordts et al., 2016)的适应性,其中我们使用了19998张没有标注的图像进行训练,并使用500张图像进行验证。这两个数据集在同一组19个类上进行评估,允许在两个领域之间进行直接的适应。
图像空间自适应还使我们能够直观地检查自适应方法的结果。与不透明的特征空间自适应方法相比,这是一个明显的优势,特别是在真正无监督的环境中——没有标签,没有办法经验地评估自适应模型,因此也没有办法验证自适应正在改善任务性能。从视觉上确认源图像和目标图像之间的转换是合理的,虽然不能保证改进的任务性能,但可以作为一种健全检查,以确保适应不是完全发散的。这个过程如图2所示。实施细则见附录6.1.2
4.2.1.季节之间的自适应

图4:跨季图像翻译。SYNTHIA季节适应设置的图像-空间转换示例。我们展示了来自每个域(秋季和冬季)的真实样本,以及到相反域的转换。
表3:SYNTHIA数据集季节间的适应。我们报告每个类别的IoU、平均IoU、频率加权IoU和像素精度。我们的CyCADA方法在所有类别中都达到了最先进的平均性能。∗FCNs in the wild 是Hoffman等人(2016)的作品。
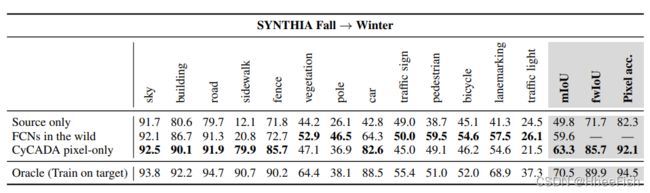
我们首先探索像素空间自适应(使用FCN8s架构)在合成数据中设置跨季节适应的能力。为此,我们使用SYNTHIA数据集,并根据秋季和冬季的天气条件进行调整。通常在无监督的适应设置中,很难解释适应后性能提高的原因。因此,我们以这个设置为例,我们可以直接将秋冬转换可视化,并检查我们算法的中间像素级自适应结果。在图4中,我们展示了从秋季域图像(a)生成冬季域图像(b)和反之亦然(c-d)时,只对像素进行适应性调整的结果。我们可以清楚地看到加雪和除雪的变化。这个视觉上可解释的结果符合我们对这些领域之间真正转移的预期,从秋季到冬季,确实产生了良好的最终语义分割性能,如表3所示。我们发现CyCADA在该任务中仅通过图像空间自适应就取得了最先进的性能,但并不能完全恢复监督学习性能(目标训练)。一些示例错误包括在人行道上添加雪,但没有添加到道路上,而在真正的冬季领域中,雪出现在两个位置。然而,即使是这个错误也很有趣,因为它暗示了在像素适应过程中,模型正在学习区分道路和人行道,尽管缺乏像素标注。
周期一致的对抗适应达到了最先进的适应性能。我们看到,在fwIoU和像素精度指标下,CyCADA接近oracle性能,仅差几个点,尽管完全没有监督。这表明CyCADA在纠正数据集中最常见的类方面非常有效。这一结论得到了表3中个别类的检验的支持,在表3中,我们看到了道路和人行道等常见类的最大改进。
4.2.2.虚拟到现实之间的适应

从GTA5到城市景观语义分割。每个测试cityscape图像(a)以及来自源模型(b)和我们的CyCADA模型©的相应预测都被显示出来,并可以与地面真相注释(d)进行比较。
GTA5和城市景观之间的自适应,显示每个类别的IoU以及平均IoU、频率加权IoU和像素精度。CyCADA的表现明显优于基线,在像素精度方面几乎与目标训练有素的甲骨文差距。∗野生FCNs由霍夫曼等人(2016)撰写。我们使用两种基本语义分段架构(A)VGG16-FCN8s(Long等人,2015)基本网络和(B)DRN-26(YU等人,2017)对我们的模型进行了比较。
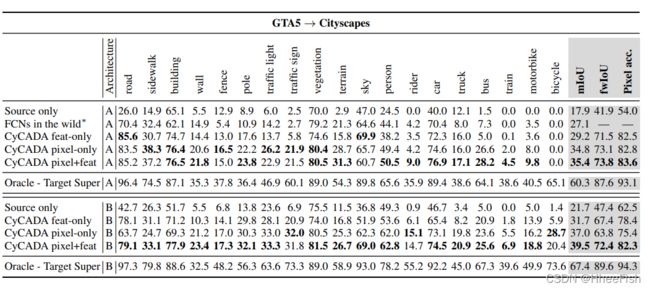
为了评估我们的方法对现实世界适应设置的适用性,我们研究了从合成到现实世界图像的适应。评估结果如表4所示,定性结果如图5所示。再一次,CyCADA取得了最先进的结果,恢复了约40%的性能损失的领域转移。CyCADA还改进或维护了所有19个类的性能。对fwIoU、像素精度以及单个类iou的检测表明,我们的方法在大多数常见类上都表现良好。尽管有些类别(如火车和自行车)几乎没有改善,但我们注意到这些类别在《GTA5》数据中表现不佳,这使得识别非常困难。在此设置下,我们将我们的模型与Shrivastava等人(2017)进行了比较,但发现这种方法并不收敛,并且比源模型的性能更差(详情请参阅附录)。
我们将GTA5和cityscape之间的图像空间适应结果可视化,如图6所示。原始图像和改编后的图像之间最明显的区别是饱和度——《GTA5》的图像比《cityscape》的图像生动得多,所以改编调整了颜色来弥补。我们还观察到纹理的变化,这可能在道路中最为明显:在游戏中,道路看起来很粗糙,有许多瑕疵,但城市场景中的道路在外观上是相当统一的,所以在从《侠盗猎车手5》转换到城市场景时,我们的模型删除了大部分纹理。有趣的是,我们的模型倾向于在图像的底部添加一个引擎盖装饰,虽然这可能与分割任务无关,但这进一步表明图像空间适应性正在产生合理的结果。
5.结论
我们提出了一种周期一致性对抗域自适应方法,该方法将周期一致性对抗模型与对抗性自适应方法相结合。CyCADA即使在没有目标标签的情况下也能适应,并且广泛适用于像素级和特征空间。CyCADA的图像空间适配实例还提供了额外的可解释性,是验证适配成功的有用方法。最后,我们在各种适应任务上对我们的模型进行了实验验证:在多个评估环境中的最新结果表明了它的有效性,即使是在具有挑战性的合成到真实任务中。
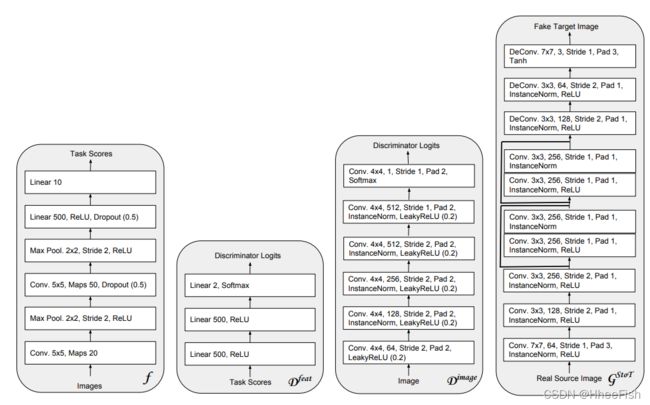
图7:用于数字实验的网络架构。我们在这里展示了任务网(f)、特征级自适应鉴别器(Dfeat)、图像级自适应鉴别器(Dimage)和源到目标的生成器(G)——用于目标到源的相同网络。
6.附加内容
6.1.应用细节
首先,我们使用标记的源数据上的任务丢失对源任务模型fs进行预训练。接下来,我们使用图像空间丢失、语义一致性和循环一致性丢失来执行像素级自适应。这将学习图像变换的参数GS→T和GT→S、 图像鉴别器DS和DT,以及任务模型fT的初始设置,fT使用像素变换的源图像和相应的源像素标签进行训练。最后,我们进行特征空间调整,以更新目标语义模型fT,使其在映射到目标样式的源图像和真实目标图像之间对齐。在这一阶段,我们学习了特征鉴别器Dfeat,并使用它来指导表示更新到fT。一般来说,我们的方法也可以同时执行第2阶段和第3阶段,但这将需要更多的GPU内存,在这些实验时可用。
对于所有的特征空间自适应,我们对生成器和鉴别器的损失进行同等加权。我们只在鉴别器在最后一批(数字)或最后100次迭代(语义分段)中的准确率高于60%时更新生成器——这降低了不稳定训练的可能性。如果在一个历元(整个传递数据集)之后没有找到合适的鉴别器,则特征自适应将停止,否则将继续,直到达到最大迭代次数。
6.2.2.语义分割实验
我们对VGG16-FCN8s Long等人(2015年)的体系结构以及DRN-26 Yu等人(2017年)的体系结构进行了实验。对于FCN8s,我们使用学习率为1e-3、动量为0.9的SGD对源语义分割模型进行100k次迭代训练。对于DRN-26体系结构,我们使用学习率为1e-3、动量为0.9的SGD训练115K次迭代的源语义分割模型。我们使用600x600的裁剪尺寸和8的批量尺寸进行此训练。对于周期一致的图像级自适应,我们遵循CycleGAN的网络架构和超参数(Zhu等人,2017)。在保持纵横比的情况下,所有图像都被调整为1024像素的宽度,并使用大小为400×400的随机裁剪面片进行训练。此外,由于数据集很大,我们只训练了20个时代。对于特征级别的自适应,我们使用SGD进行训练,动量为0.99,学习率为1e-5。为了方便起见,我们将代表性损失的权重比鉴别器损失的权重小十倍,因为否则鉴别器在一个时期内无法学习到合适的模型。然后利用自适应源图像和源数据的地面真值标签分别训练分割模型。由于内存限制,我们一次只能包含一个源图像和一个目标图像(大小为768x768的作物),这个小批量是使用高动量参数的主要原因之一。