毫米波雷达在检测、分割、深度估计等多个方向的近期工作及简要介绍
前情回顾
在之前,我已经有介绍过毫米波雷达在2D视觉任务上的一些经典网络[自动驾驶中雷达与相机融合的目标检测工作(多模态目标检测)整理 - Naca yu的文章 - 知乎],总结概括而言,其本质上都是对视觉任务的一种提升和辅助,主要的工作在于如何较好地在FOV视角中融合两种模态,其中不乏有concate\add\product两个模态的特征,或者使用radar对视觉局部特征增强,其中比较知名的工作CRFNet经常用来作为baseline,其并没有对毫米波这个模态做特殊的处理,仅是作为视觉特征的补充融入到传统的2D检测pipeline中,但是其消融实验提出了许多值的考虑的优化方向:包括噪声滤除、BlackIn这两个,一个代表了对于毫米波这类有较多噪声的数据进行“理想化”的噪声过滤,结果提升了接近10个点。二是通过BlackIn对于弱模态-毫米波点云加大学习权重(通过对训练时图像的缺失)来提高网络对于高噪声弱模态的拟合能力也能提点。
在近些年,2D检测任务在AL的热度递减,取而代之的是3D任务,毕竟现在的实际场景一直多是基于3D场景。但是在3D检测或者分割等任务中,雷达赋予了一个不一样的角色,在之前FOV视角中,毫米波点云大多为了与FOV特征融合,都是通过投影这一种方法,而放到3D场景中,自然就有LIdar的相关角色赋予毫米波雷达,相应的,毫米波的角色从FOV到了BEV,它的下游任务,也从辅助为主到BEV下的分割、深度估计、生成密集点云等。
这也是我这篇文章的重点,文章的主要工作放在毫米波角色的转换中,从3D检测、深度估计、GAN(非重点),分割(非重点)几个方面列举我看到的一些工作并做简单介绍和总结,同时对毫米波算法的发展提出自己的一些拙见,由于个人能力有限,无法通过一篇文章就把radar的脉络梳理出来,所以后面还会继续以各个子章节细化,组成系列文章。
介绍的工作都比较冷门,很少有源码开放,因此对一些细节分析可能并不到位,欢迎大家在评论区讨论,提出自己的宝贵意见,指正我的一些偏见。
一、3D Detection
1.1 GCN:图卷积用于毫米波目标检测
1.1.1 GCN用于毫米波点云
Radar-PointGNN: Graph Based Object Recognition for Unstructured Radar Point-cloud Data(2021 IEEE Radar Conference)
之前我发过一篇文章:用于毫米波雷达的GNN:Radar-PointGNN: Graph Based Object Recognition for Unstructured Radar Point-cloud Data - Naca yu的文章 - 知乎
1.1.2 GCN用于原始毫米波信号
Graph Convolutional Networks for 3D Object Detection on Radar Data (2021 ICCVW)
建议在阅读这篇工作前,先阅读一篇关于雷达数据处理的文章以了解RD和RadarPointCloud的区别:
毫米波雷达:信号处理 - 巫婆塔里的工程师的文章 - 知乎 https://zhuanlan.zhihu.com/p/524371087
- Abstract:作者借鉴GCN,基于毫米波原始数据Range-beam-Dropler tensor进行3D目标检测,相比作者自设定的baseline(grid-based-convolutional baseline也就是voxel这类方法)提升约10%,同时作者在真实环境下验证模型效果,相比于其他模态,作者提出的网络检测距离能够达到20m-100m,大幅度提升检测范围。
- 网络结构:
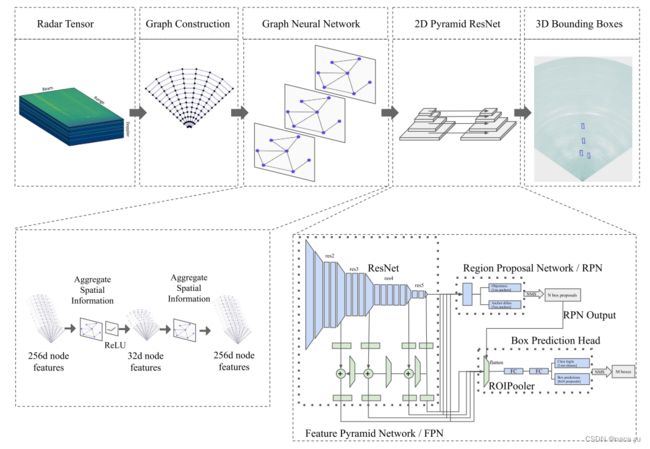
这项工作的输入数据,并不是常见的雷达点云形式,这类点云是经过CFAR等算法处理后的结果,这类算法处理后的结果会导致原始信息丢失的问题(部分工作将CFAR更换为DL模型后能够有效降低点云噪声),近期的一些工作例如CRUW数据集,提供点云的上层数据-Range-Doppler数据,这类数据能够以较小损失的条件下保留较多的原始信息,但是,相对点云原始数据无法直接将数据用于检测等现有任务并且数据的直观性和结构化降低。在GCN中,RD不能够直接用于构建Graph,作者将其处理为range-beam-doppler坐标系下的voxel用于构建节点,edge则采用两种方案:根据节点的距离确定和固定权重。 - 重要部分:
(1) 极坐标和笛卡尔坐标系
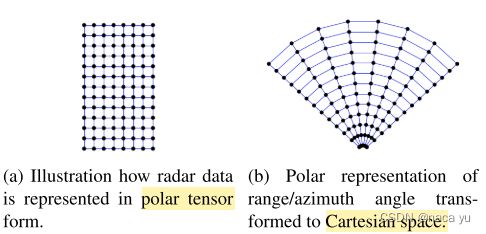
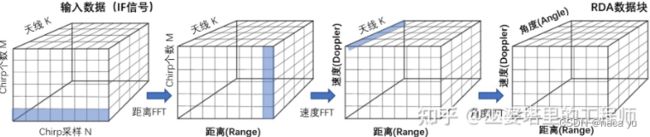
这里简单聊一下毫米波数据的转换过程,具体可以参考:毫米波雷达:信号处理,如上图所示,从左到右经过三次FFT变换,从原始的传感器采集到的MNK维度的IF信号到最后的RD数据,就是我们所需要的原始雷达数据,对RD数据进一步处理,得到点云数据信息,我们需要的是上图中最后一个数据的形式。
(2)图的构建
- 边的定义
首先,Radar-Doppler-Tensor作为输入数据(HWC),然后将输入切分成range-beam为单位的cell作为基本单元,每个cell(256 channels doppler)作为node feature,这样就完成了节点的原始特征定义。对于edge的定义如下(图的边则连接相邻range或者相邻angle的节点,边的权重与欧式空间中节点距离成反比(实验证明这个权重的设置并不重要):

- 点的定义
首先,Radar-Doppler-Tensor作为输入数据(HWC),然后将输入切分成range-beam为单位的cell作为基本单元,每个cell(256 channels doppler)作为node feature,这样就完成了节点的原始特征定义。对于edge的定义如下(图的边则连接相邻range或者相邻angle的节点,边的权重与欧式空间中节点距离成反比(实验证明这个权重的设置并不重要):

4. 实验:
如下,作者采集自真实场景的数据集各项参数:
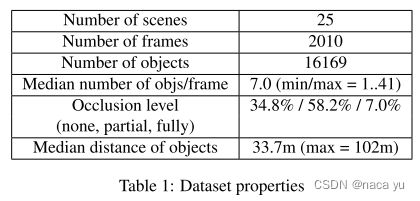
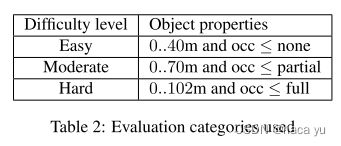
如下,数据集中对于目标检测难度的定义:从距离和遮挡程度两者考虑
作者提出的baseline(RT-Net):将上述的两层图卷积网络替换为普通的2D卷积,激活函数等设置相同,作者模拟的是不同grid-based-method(voxel)和graph-based-method两者的异同。

- 可以看到,作者设置了两种对比,GRT-Net即作者提出的模型,第二三个模型的edge权重是不同的(cartesian-based和identical edge weights),通过12实验对比,可以得到,graph-based-method得到了全面的性能提升,23实验对比,identical的edge weights是有优势的。
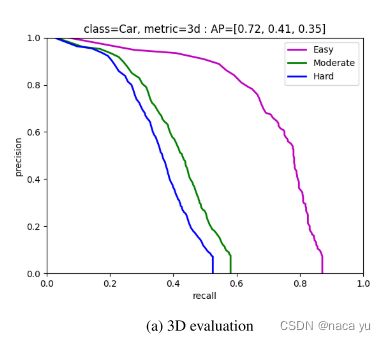
- 以上结果是IoU=0.3的情况下,三类样本的PR曲线。
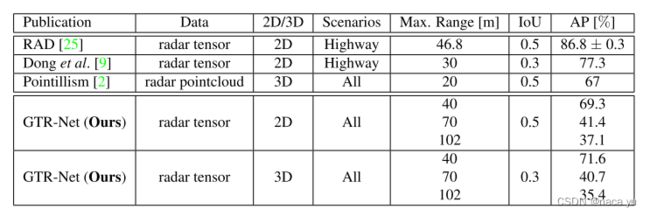
以上作者只与baseline进行了对比,其他的工作只是列举了他们的实验细节,也可以从这一节看出,在非毫米波点云数据的工作中(当然点云数据集也仍然没有高度公认的),还没有大部分工作都认同的数据集,我猜测:一是不同毫米波传感器之间的属性差别大难以统一、二是毫米波的论文开源工作较少,目前我找到的大部分工作都是只有论文,细节描述不清,因此难以复现出原本的性能。三是开源的大型数据集较少。希望未来大家能够将自己的工作开源,至少说明足够复现的细节。
总结
GCN和Voxel两类网络对比:在复杂度方面,graph-based的计算复杂度与点云数量呈线性相关性,而grid-based方法检测性能不仅受到grid大小,大量的voxel等于0值造成计算资源浪费,并且也受到检测距离的关系而需要在检测精度和效率之间做trade-off。在中心特征计算方面,radar pointcloud的点云过于稀疏,许多前景目标仅投影个位数的点云,通过voxel等方法会造成过度降采样和中心特征丢失。当前各类榜单上grid-based方法能够有效避免point数量过大导致的复杂度过高的问题而成为主流超越point-wise的方法,但是由于radar的稀疏性(Nuscenes中radar和lidar大概是50:1的关系),采用point-wise的方法并不会导致很大的延迟。
Radar检测优劣:优势:另一方面,radar由于其长波优势,探测的距离也较大,对于高速公路这类检测目标单一且方向等属性较为单一的场景下,radar有着较大的优势。劣势:由于两个工作并不是同一数据集,所以两者无法横向对比,能够得到的几点是:毫米波所包含的信息是能够独立地进行3D检测,但是仅对于车辆(卡车、汽车、建造车辆等)大型反射性良好的目标进行检测,而对于弱反射的交通目标则检测效果较差。
两种数据对比:基于radar点云的检测都是需要预定义每个需要检测的类的bouding box大小,毫米波在辨别物体时有一定的优势,但是在物体的regression任务上缺乏可参考的尺寸特征(仅有RCS),在回归任务上需要预设大小。相比之下,在RD原始数据中显示地带有了目标的横截面积反射强度等信息(Doppler),工作2**(暂定没有预设尺寸)**可以在没有预设尺寸情况下较好回归目标属性。但是,在高度属性等地面垂直方向属性预测上,雷达这种平面数据无法有效预测。
1.2 Reference to Lidar
这类工作主要对Lidar Based方法进行改进,用于Radar。
1.2.1 Point-wise 的检测方法
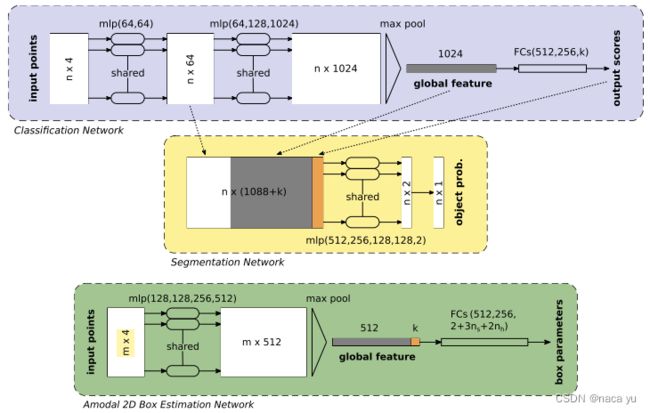
2D Car Detection in Radar Data with PointNets (2019 IEEE Intelligent Transportation Systems Conference)
出发点: 在point-level借鉴frustum-pointnet和pointnet进行3D目标检测。
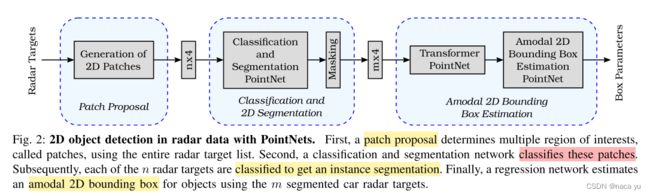
作者基于Frustum-Pointnet和Pointnet进行了改进,提出一种point-wise的3D目标检测网络。
整个模块分为三个部分:
- 第一部分基于现有的radar points生成2D的Patch Proposals,相当于FrustumPointnet中的Frustum,用于聚合局部特征,现定某个patch内部的point点数为n,相当于对每个patch内部的点做一系列的操作,Patch Proposal的输入为n x 4(2D spatial data, ego motion compensated Doppler velocity and RCS information.)。
- 第二部分将proposal内部的点云提取局部和全局特征,经过对clutter和radar-target的点云过滤,输出mx4的筛选后的radar targets向量(与原始数据一致)。
- 最后一部分,将筛选出来的点经过传统的T-NET和Box-Estimation输出最后的各项属性。
下面是更详细的结构图:
1.3 多模态融合
1.3.1 point-wise fusion和object-wise fusion(feature-level & decision level)集合用于多模态检测
Bridging the View Disparity of Radar and Camera Features for Multi-modal Fusion 3D Object Detection (2021 8月 arxiv 清华)
出发点: 在BEV空间,在point level和object level两个层面实现图像特征和点云特征的融合。
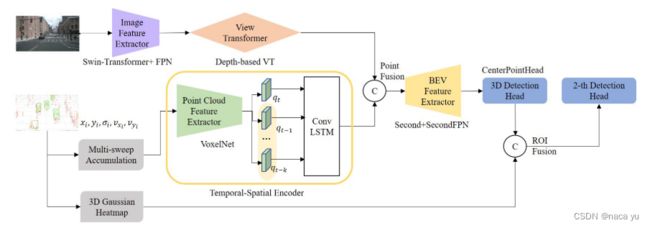
- 该模型主要解决在3D检测中,毫米波和相机数据的异构融合检测问题,提出了一种Point-fusion和ROI fusion两种融合并存互补的想法。
- 模型架构:
- 图像分支:通过LSS的方法将图像特征转换到BEV空间,并通过ConvLSTM融合多帧的毫米波grid-based特征作为时序radar特征,与图像BEV特征进行point-wise的concate后,通过BEV特征编码器完成模态融合并基于此进行heatmap生成。
- radar分支:通过对radar特征图的heatmap生成并与图像的heatmap进行融合,送入最终检测头预测。
- 融合分支:采用point-wise fusion和object-wise fusion两种融合兼顾的方式。
- 模型细节:
(1) point-fusion和ROI fusion两种融合并存互补的想法;
(2) two-stage-fusion方法:两个模态分支各自完成heatmap生成后,再次进行融合,在特征细粒度和全局信息融合上都有考虑到,融合结构如下所示:在融合之前,不用保持分辨率的一致,在point-wise融合时两个不同分辨率的模态要分别经过上下采样统一后融合。
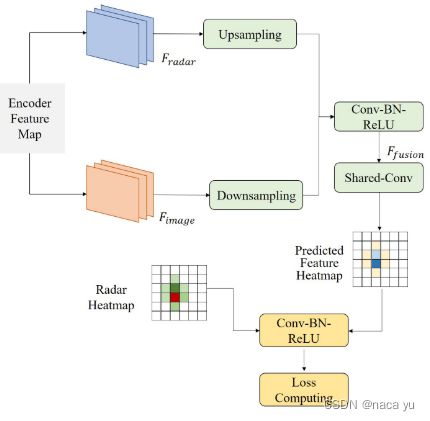
(3) 在radar上使用conv-lstm这类方法进行时序雷达信息融合,作者以此解决点云的部分噪声问题:杂波和数据稀疏,但是没有通过消融实验证明lstm结构的合理性;
(4) 雷达数据处理:temporal-spatial feature encoder
- 每一帧的雷达点云都经过转换到current frame,输入的raw radar包含:x, y, vr, RCS;
- 空间特征提取:使用常用的voxelnet或者pointpillars;
- 时序特征:ConvLSTM,对空间特征特征图提取时序特征到Temporal Encoder中,具体结构可参考如下结构,将卷积和lstm结合起来,使得模型同时具有提取空间和时序特征的能力,这个在天气预测有一些应用;

(5) 图像特征提取:LSS
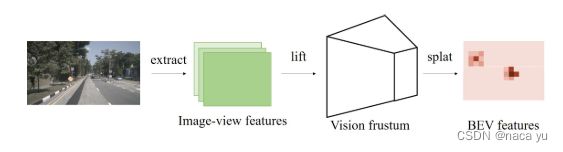
和BEVDet的方法一致,提取feature-map后,经过一系列的转换(lift)将特征转换为基于视锥分布的深度特征图,后通过pooling的方式(splat)特征到BEV空间。
- 评价总结
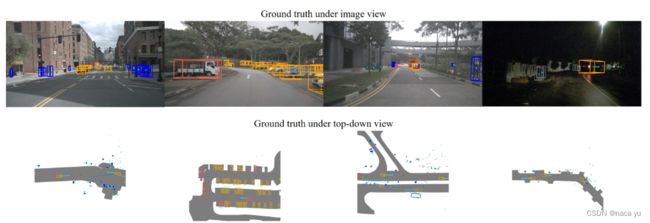
作者在BEV空间中以top-down的形式检测,没有引入先验的目标尺寸信息,而是通过中心点回归其他信息。
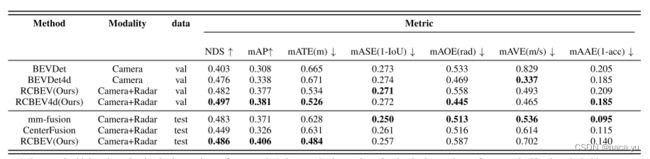
- baseline对比:
相比未引入时序信息的bevdet,RCBEV在整体性能提高的基础上,在mAVE上尤其明显,毫米波雷达的引入,时序特征的提取对网络的速度性能提升非常大,相比BEVFORMER和BEVDET4D预测速度,通过融合毫米波雷达能够在避免多帧图像的计算复杂度增加的同时,提高速度的预测能力。但是通过conv-lstm的方法完成雷达时序特征的提取相对其他方法并没有体现出其优势,这个可以对比目前的camera+radar主流方法的mAVE来看。
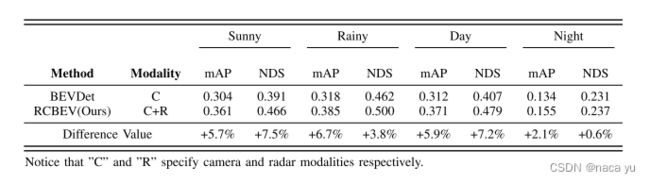
- 模态消融实验:
相比晴天,雨天毫米波雷达带来的提升更大,也能证明这种融合方式的鲁棒性。在光照对比上,白天带来的提升更加明显,总体上,本篇工作确实在多个极端天气下达到了良好的性能。
1.3.2 用图像分割增强毫米波点云的检测效果
RadSegNet: A Reliable Approach to Radar Camera Fusion (2022 年 8月)
出发点: 用语义分割结果渲染点云图,对毫米波点云引入图像语义信息用于3D检测。
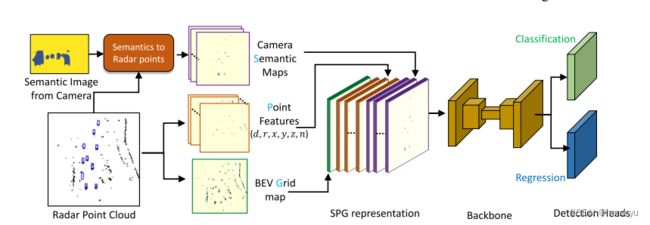
- 模型架构:
这里融合的方式并不复杂,因此不做过多介绍,这篇文论的精彩之处我认为在于SPG representation的前面:
类比与pointpainting的方式,将雷达点云赋予语义信息(图像经过pretrained maskrcnn的分割后的全景分割图像),生成semantic map用于渲染投影到FOV后对应的毫米波点云,然后分别与对应的点云的特征和BEV occupy map进行叠加,到此完成特征的对齐和不同特征向量的叠加。后利用UNet网络提取多尺度特征,分别送入分类和回归检测头。
-
模型细节:
(1) 点云渲染
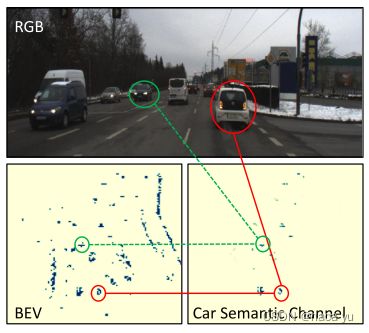
通过对比,可以看出在语义通道中,毫米波通过语义分割渲染后的点云带有图像本身的语义信息,能够直观反映了其能够弥补毫米波缺少类别特征的劣势。(2)检测头
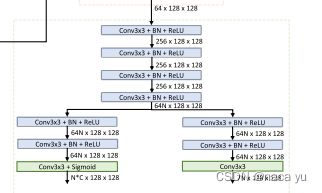
- 最后两个检测头分别预测NC128128也就是N个anchor的类别,而另一个输出为7N128128,7为每个anchor的属性,包括x, y, z, w, h, l, theta这7个属性。
(3)天气模拟
作者使用图像增强库模拟增加极端天气:大雾、大雪等天气,可以控制雪花大小、下降速度等参数模拟真实环境。
(4)模型输入:- 分为BEV occupy grid, RadarPoint Feature, Semantic Maps,共计22 dims,在输入模型前全部通过concate完成grid-level的特征对齐。
- 作者将点云格式化为grid-based feature map,如果多个点投影到同一grid,那么就计算平均值,同时y设置为7个channel代表不同的高度,弥补毫米波雷达不含有高度信息的缺点,n表示点云投影到grid的个数。数据由I(u,v)为0、1代表是否为空,d,r代表dropler和intensity。
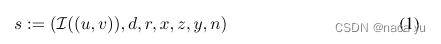
-
分析总结
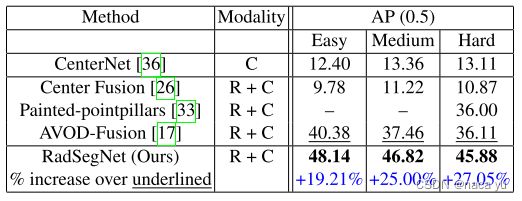
作者在Astyx dataset数据集完成训练任务,在RADIATE进行测试。RADIATE相比训练的数据集,极端环境的占比更多,对模型的鲁棒性要求更高。
(1)在Astyx数据集对比中:baseline选取Perspective-view-based方法当时的SOTA-Centerfusion进行比较,为了保持公平,将预训练的centernet微调到新数据集中,实验结果也证明微调后的网络比from-scratch的centernet网络表现更好,作者基于此对centernet进行了微调并用于centerfusion。centerfusion性能下降很多,但是作者没有给出足够的细节,我能推测出来的:RadSegNet在BEV下3D检测的结果与Centerfusion的FOV检测结果相比较。
(2)作者使用segmentation后的结果渲染point,所以融合的效果严重依赖于分割的效果,在极端天气下的分割效果如下图所示,点云的语义特征会严重退化;

(3) lidar vs radar

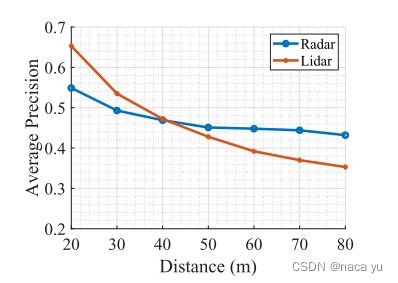
作者将pointcloud换成lidar进行了对比试验,可以看出,在近处激光雷达的效果要优于毫米波,在远处发生了目标的重叠并且lidar点云的密度急剧下降,作者计算了不同的感知距离上限下性能的变化,可以看出radar在远距离检测的优越性。毫米波作为长波,相比激光雷达,在穿透性和感知距离上都要更优,但是同时也导致了毫米波雷达的多路径干扰等问题。
(4) 相比nuscenes,作者使用的这两个采集自真实场景的数据集由于其极端环境的占比较高,因此对于算法的鲁棒性要求更高,在nuscenes数据集上,点云过于稀疏同时极端的环境占比并不高,因此在验证radar的鲁棒性等作用时,其他具有稠密点云或者极端天气比例较高的数据集也可以考虑,增加我们的实验严谨性。
二、Depth Estimation
2.1 毫米波雷达辅助视觉进行深度估计
题目:Depth Estimation From Monocular Images and Sparse Radar Using Deep Ordinal Regression Network (ICIP,2021,九月)
作者出发点: 随着lidar-based的深度估计方法用于3D目标检测(BEVDepth),radar-based方法也通过改进,根据radar特性设计了一些深度估计的方法。作者结合DORN网络并进行改进,引入radar分支用于深度检测。
源代码:https://github.com/lochenchou/DORN radar
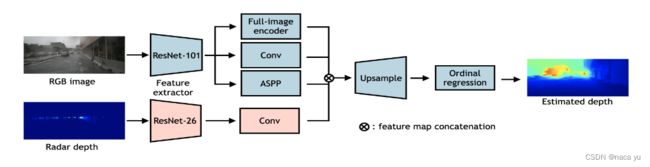
-
网络架构:由图可以看出,两个模态在FOV分别通过resnet提取feature后(要注意,此时的radar并不是raw data,而是通过滤波后的深度值),分别通过DORN深度估计网络和普通的卷积进行编码,随后concate并上采样,最后通过序数回归对深度进行估计,其中蓝色部分与DORN保持一致,只是将深度估计问题变成分类问题(ordinal regression)。整体结构并不复杂,重要的是作者如何将radar用于深度估计的流程。
-
主要创新点:一个是将点云扩展高度变成line,提高毫米波点云的"感受野",增强深度估计效果。一个是将多模态引入单模态深度估计DORN网络。
-
模型细节
(1) 作者将毫米波雷达的困难定义为:稀疏、噪声比大、无高度信息(影响的高度范围有限),通过预处理,生成一个height-extended multi-frame denoised radar。
(2) 雷达预处理流程如下:1. 高度扩展,类似于crfnet,将点云扩展0.25~2m的范围内,变成一条直线;2. 滤波:将不符合深度阈值的毫米波点云滤除,阈值定义如下,滤波过程和生成radar-depth特征的过程可参考[Depth Estimation from Monocular Images and Sparse Radar Data]。 -
总结
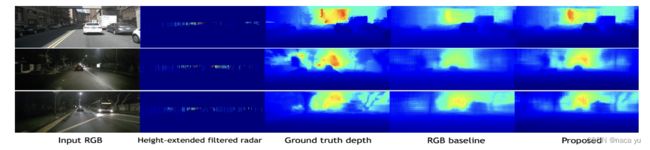
可以看出,提出的方法比baseline在深度预测上更接近真实值。

- 评价指标:
第一个评价值代表深度估计值和真实值的最大差异
RMSE是平均深度差值
ABSREL是相对的平均深度差值
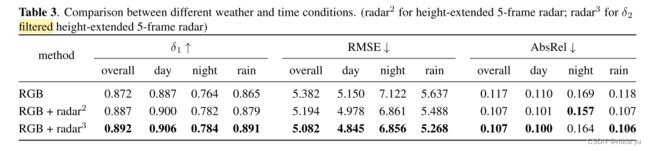
由上图,可以看出滤波的有效性
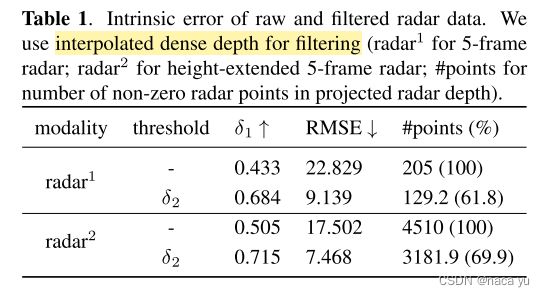
由上图可以看出预处理中毫米波高度扩展的有效性
三、Segmentation
3.1 多模态融合的map分割
A Simple Baseline for BEV Perception Without LiDAR(2022, MIT)
作者的出发点: 在BEV上通过BEVFORMER的方式"无参数化"地完成Lift操作(将图像特征转换到BEV空间),融合雷达点云特征图,用于分割任务,性能超越了之前的分割模型。
- 网络结构:
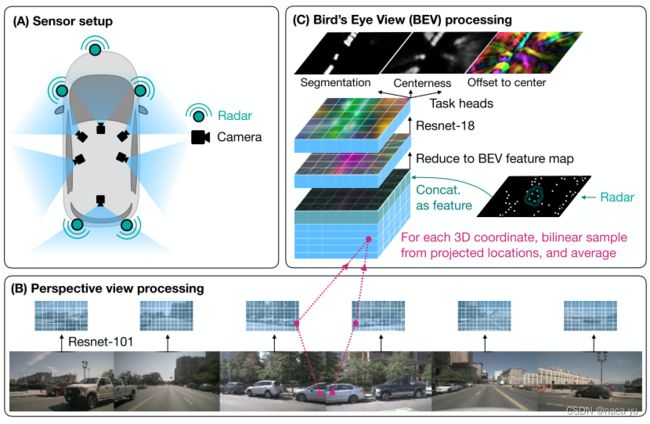
- 论文如其名,网络结构比较简单,可以看出很多论文的影子(例如BEVFORMER),作者就是通过显式的BEVqueries采样图像特征,并且concate雷达特征并通过卷积进行模态对齐与融合,后面用于分割任务。
- 总结分析:
-
雷达信息处理:

由多个特征维度构成:0\1的occupy map,nuscenes提供的所有特征(RCS,X,Y,Z,V…)作为输入concate到一起作为输入特征。检测范围是[-100, 100m],网格的大小是200x200。 -
性能提升
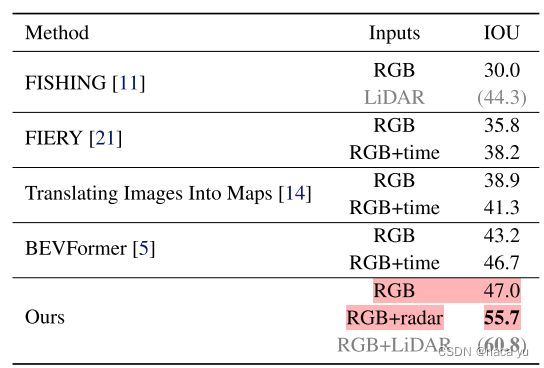
和主流的工作相比,作者的确在分割上提升非常大,作者将这归功于毫米波的功劳, -
消融实验

总结为三点:对于分割任务,输入过多的属性提升不明显(occupy only已经达到53),对multi-path的毫米波雷达点滤除反而导致性能下降(意料之中,因为multi-path的毫米波虽然会导致噪声,但是其扫描到的物体可能正是位于被遮挡的区域),增加sweeps的数量性能也会提升(毕竟点云密度大了)。
四、Dense Pointcloud Generation
4.1 GAN
4.1.1 通过密集点云监督radar生成密集点云
See Through Smoke: Robust Indoor Mapping with Low-cost mmWave Radar (2020, 斯坦福)

4.2 Lidar Supervision
4.2.1 激光雷达点云监督毫米波生成occupy grid map
Radar Occupancy Prediction With Lidar Supervision While Preserving Long-Range Sensing and Penetrating Capabilities
作者的出发点: 通过lidar这种数据质量较高的模态,监督毫米波雷达生成质量较高的占据栅格地图,解决在这个过程中的两个问题:一解决occupy网格生成存在于传感器之间的内生性问题:传感器感知距离不一,传感器穿透性不一问题;二解决长距离网格生成问题;生成的occpy grid map可用于下游的路径规划等问题。
- 本文一些基本定义:
-
极坐标系与笛卡尔坐标转化
作者以笛卡尔坐标系的x,y中心为极坐标系的中心,笛卡尔坐标系的一周等同于极坐标系的一段(如下图所示的蓝色红色对应关系)

-
作者将radar中lidar的感知区域定位trainning-region,将其他范围内的毫米波点云作为inference的输入,如下图所示

-
毫米波雷达噪声来源:
multipath reflection, speckle noise, receiver saturation, and ring-shaped noise -
本文各类颜色含义
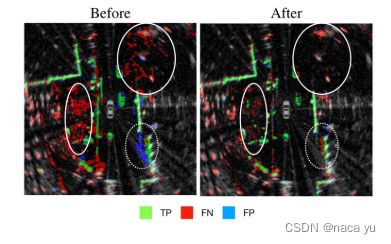
为了称呼方便,将生成的occupy grid map中的unit统称为点云,其中,绿色代表模型生成的正确点云,红色代表lidar检测到但是模型没有生成的点云,蓝色代表模型生成但是GT不存在的点云。
- 模型架构:使用传统的UNet生成occupy grid map,输入是BEV表示下的Radar的点云,输出为occupy grid。
- 模型细节:
-
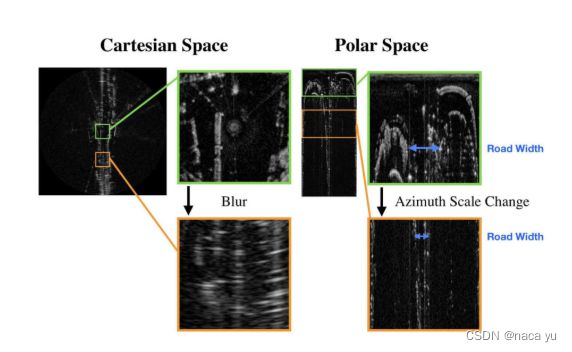
为什么在极坐标系下检测?
作者提到,CNN对于尺度变化的鲁棒性要强于对方向形状的鲁棒性变化。下图所示,在polar space中路宽相较于cartesian space变化更大,但是cartesian space的两侧点云出现了blur。
-
毫米波数据预处理
考虑到这样一个问题:毫米波本来检测不到的目标,是否应该强制使其检测?
答案肯定是否,因为毫米波和lidar的性质差异,对于树木等一些反射性相对较差的目标,毫米波是检测不到的,同时radar检测到被遮挡的物体,此时lidar又是检测不到的,两个传感器之间的差异,如果强制检测,会导致相当多的FP预测,因而会降低性能;
因此,通过数据预处理,首先过滤反射强度低于某个阈值的点云,然后将lidar提供的GT数据中radar无法检测到的数据滤除,得到训练数据。
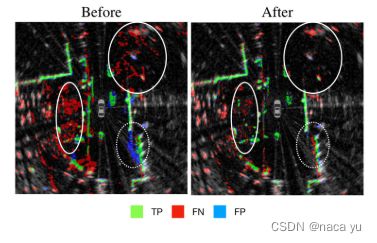
如上图所示,由实验得到,通过预处理,模型的FP大大降低; -
如何解决传感器检测距离差异问题呢?
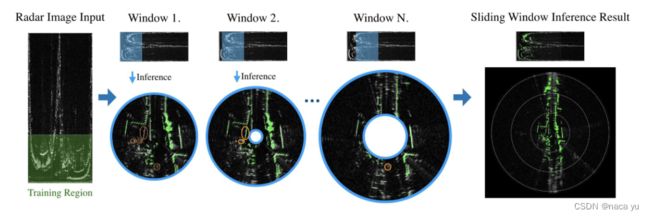
POLAR SLIDING WINDOW INFERENCE:将lidar检测区域内的点云作为GT用作traning region,然后逐步滑动窗口,每次窗口所包含的radar点云仅作为inference,生成occupy map。简单来说,就是lidar内的有限数据用于训练,而lidar外的radar用于推理生成occupy map并拼接生成最终的远距离occupy map。
流程如下图所示,这里的内外圆之间的距离是检测的范围,也就是滑动窗口,训练是通过对比不同的滑动窗口的内容与网络预测的同心圆之内的检测结果进行对比训练。
-
如何保持radar的透视性能?
通过上面所述的滑动窗口,可以完美解决lidar监督数据下,lidar-invisible的目标但是radar-invisible的目标点云没有输入而导致的透视性能丧失问题,因为在t窗口不能看到的点云,可以在别的窗口看到。
- 总结:
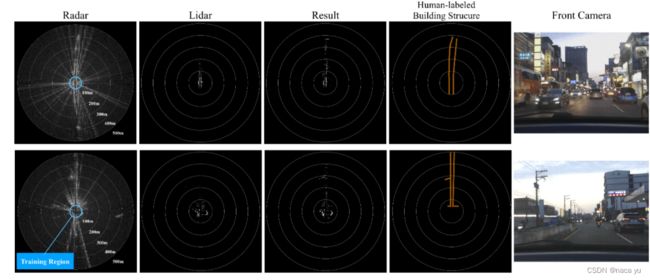
以上是效果图,可以看到,原本的radar输入是非常混乱的,带有非常多的噪声,第二列是训练数据可以看到lidar的点云非常规则能够反映区域内比较完整的几何信息,第三列是输出的结果,通过lidar数据的监督,能够在lidar区域以外,生成噪声较小,能够反映路面分布的点云图。第四列是人工标注的GT,最后生成的result与GT相较radar更为接近。
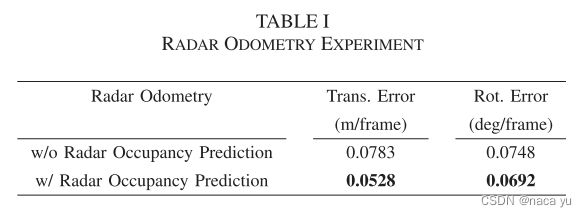
以上是效果图,可以看到,原本的radar输入是非常混乱的,带有非常多的噪声,第二列是训练数据可以看到lidar的点云非常规则能够反映区域内比较完整的几何信息,第三列是输出的结果,通过lidar数据的监督,能够在lidar区域以外,生成噪声较小,能够反映路面分布的点云图。第四列是人工标注的GT,最后生成的result与GT相较radar更为接近。在BEVDepth对网络预测深度监督时,深度本身的模态无关的信息,不加改变地监督深度预测网络是可行的,但是对于radar和lidar两种模态,各自有各自的特性,强制地把一种模态地特征监督另一种模态而不加变化,势必会导致本文中出现的虚警等情况,