【得物技术】浅谈本地缓存与分布式缓存
引言
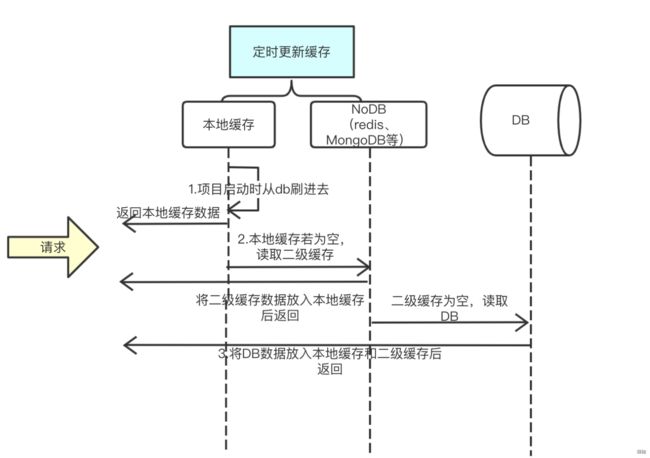
在互联网电商行业,由于订单履约物流等核心业务的特殊性,要求在保证业务正确性的基础上,这些链路的响应时间不能过高,否则会影响上下游的的其他业务。为了解决这个问题,一般的做法是尽可能利用缓存,减少直接访问DB来降低响应时间,但这种方案会导致读写缓存的策略变得更为复杂。大部分场景下大致流程如下:
缓存淘汰算法
在业务中大量使用缓存之前,有必要了解缓存相关原理及淘汰算法,合理使用,才能保障线上业务的稳定性。
简单来说,缓存会设置一个最大存储量,当缓存存储的数量超过最大空间时,为了保证在稳定服务的同时有效提升命中率,设计适合自身数据特征的淘汰算法能够有效提升缓存命中率。常见的淘汰算法有如下几种。
FIFO
FIF0(first in first out):即「先进先出」。最先进入缓存的数据在缓存空间不够的情况下(超出最大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。策略算法主要比较缓存元素的创建时间。
这种算法适用于「保证高频数据有效性场景,优先保障最新数据可用」。
LFU
LFU(less frequently used):即「最少使用」。无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。策略算法主要比较元素的hitCount(命中次数)。
这种算法适用于「保证高频数据有效性场景」。
LRU
LRU(least recently used):即「最近最少使用」。无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。策略算法主要比较元素最近一次被get使用时间。
这种算法适用于「热点数据场景,优先保证热点数据的有效性」。
本地缓存
本地缓存也可以理解为进程内的缓存,特点是速度快,不会受到网络阻塞的干扰,但是因为是存放在jvm的内存中(堆的老年代)所以容量较小且各个进程间的缓存不能共享,不会持久化。随着服务的重启,所占用的空间会释放掉,所以适用于缓存一些应用中基本不会变化又频繁会被访问的数据,比如物流行业维护的仓库地址等信息。
优势
本地缓存相对于IO操作速度快、效率高。Redis是一种优秀的分布式缓存实现,但受限于网卡等原因,远水救不了近火,因此DB + Redis + LocalCache = 高效存储&高效访问。访问速度和花费的关系如下图所示:
图片来源-知乎
技术实现
HashMap
使用hashmap是最简单基础方式,是JDK的自带类,因为其内部为KV结构,存储对应的键值对,在需要时,可以通过key获得相应的value,因为不是线程安全的类,所以在需要保证线程安全时可以使用ConcurrentHashMap。这种方式使用简单但是对象的有效性和周期性不能保证(也就是没有缓存淘汰算法),容易造成内存的急剧上升,适用于业务简单,数据量小且对并发量没有太高要求的场景。
/*** 定义全局变量*/private static Map
/*** 定义全局变量*/private static Map
/**
* 定义全局变量
*/
private static Map CACHE_MAP;
/**
* 获取缓存map中的值
* @param key
* @return
*/
public static Object getCacheMapValue(String key){
Object value = getCacheMap().get(key);
return value == null ? null : value ;
}
/**
* 存放键值对
* @param key
* @param value
*/
public static void putCache(String key,Object value){
getCacheMap().put(key,value);
}
/**
* 删除
* @param key
*/
public static void removeCache(String key){
getCacheMap().remove(key);
}
/**
* 获取map
* @return
*/
public static Map getCacheMap(){
if(CACHE_MAP == null ){
CACHE_MAP = new HashMap<>();
}
return CACHE_MAP;
}
public static void main(String[] args) {
putCache("1","test1");
putCache("2","test2");
putCache("3","test3");
System.out.println(getCacheMapValue("1")); //返回test1
removeCache("1");
System.out.println(getCacheMapValue("1")); //返回nul
} GuavaCache
官方地址:https://github.com/google/guava/wiki/CachesExplained
Guava是google开源的一个公共java库,类似于Apache Commons,它提供了集合,反射,缓存,科学计算,xml,io等一些工具类库。cache只是其中的一个模块。使用GuavaCache能够方便快速的构建本地缓存。
特点
-
GuavaCache缓存的容器为Cache
-
实现原理基于ConcurrentHashMap(jdk1.7之前Segment分离锁原理),所以能够保障线程安全,在多线程高并发的场景下能够保证程序中共享数据的准确性
-
对于数据的回收与ConcurrentHashMap不同,ConcurrentHashMap会保留所有添加的元素,直到将它显性删除为止,GuavaCache提供了三种缓存回收方式(基于容量回收、定时回收和基于引用回收)来限制内存的占用量;
-
封装了原子性的put/get的操作;
基本用法
先在pom文件中添加依赖:
com.google.guava
guava
25.0-jre
构建缓存对象
GuavaCache的创建为建造者模式,每次调用方法后返回的是对象本身,可以直接通过CacheBuilder.build()的创建,以下为最简单的创建方式。
创建一个缓存对象,key和value均为String类型:
Cache cache = CacheBuilder.newBuilder().build();
cache.put("word","Hello World");
System.out.println(cache.getIfPresent("word")); 在创建cache时设置过期时间、最大存储容量、并发级别等。
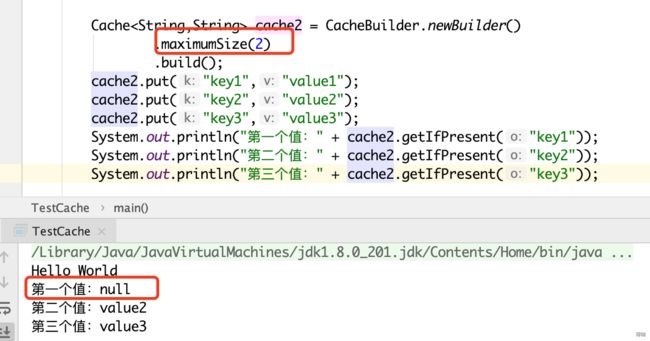
Cache cache1 = CacheBuilder.newBuilder()
.concurrencyLevel(8) //并发级别为8,表示只有8个线程可以同时写缓存
.expireAfterWrite(10, TimeUnit.SECONDS) //写入缓存10秒后过期
.initialCapacity(10) //容器初始容量为10
.maximumSize(15) //容器最大存储容量为15
.build(); 注意:容器的最大存储容量maximumSize,设置了15但后续如果put的个数超过15,就会按照LRU算法来移除最近最少被使用的缓存项,例如指定为2,put了3个GuavaCache依照LRU算法就会默认移除第一个被put的数据。
缓存回收方式
GuavaCache提供了三种基本的回收方式,基于容量回收、定时回收和基于引用回收。基于容量回收就是指定容量后超过预设阀值就依照LRU算法进行回收,定时回收就是指定缓存失效时间。
-
基于引用回收
可以通过weakKeys和weakValues指定GuavaCache中的key和value为弱引用,这样当垃圾回收器运行时若没有被其他强引用指定则会被回收,避免内存占用过多。
Cache cache3 = CacheBuilder.newBuilder()
.weakKeys()
.weakValues()
.build(); 注意:由于垃圾回收是依赖==进行判断是否相等,因此这样会导致整个缓存也会使用==来比较键的相等性,而不是使用equals();所以在利用缓存的key比较时需要用==,这一点官方文档也有说明。
-
显式回收
除了设置过期时间来将时间范围内未被访问的缓存项删除之外,还能通过以下方法将缓存显式删除:
-
使用Cache.invalidate(key)单个移除;
-
使用Cache.invalidteAll(keys)批量移除;
-
使用Cache.invalidateAll()移除全部。
Cache cache4 = CacheBuilder.newBuilder().build();
cache4.put("1","1");
cache4.put("2","2");
cache4.put("3","3");
//cache4.invalidate("1"); //单个删除key为1的缓存项
List keyList=new ArrayList<>();
keyList.add("1");
keyList.add("2");
cache4.invalidateAll(keyList); //将key为1和2的缓存项批量移除
cache4.invalidateAll(); //将cache4中的缓存项全部移除 两种缓存接口
Cache
Cache是通过CacheBuilder的build()方法构建,它是Gauva提供的最基本的缓存接口,并且它提供了一些常用的缓存api,上面介绍的就是基于Cache。
LoadingCache
LoadingCache是Cache的子类,它能够通过CacheLoader自发的加载缓存,在构建时需要实现CacheLoader的load方法。当调用LoadingCache的get方法时,如果缓存不存在对应key的记录,则CacheLoader会依据load方法中返回结果作为value,并从get方法返回。如果load方法中返回空,则抛出异常。
LoadingCache loadingCache = CacheBuilder.newBuilder().build(
new CacheLoader() {
@Override
public Object load(String s) throws Exception {
if(s.equals("key1")){
return "value";
}
return null;
}
});
System.out.println(loadingCache.get("key1")); //返回load方法中指定的“value”
System.out.println(loadingCache.get("key2")); //不满足load方法的if判断,返回空,抛出ExecutionException Caffeine
Caffeine是Java8对Guava缓存的重写版本,支持多种缓存过期策略,底层数据存储使用的也是面向JDK8的ConcurrentHashMap(增加了红黑树,在hash冲突时也保持读性能)。Guava Cache 功能虽然强大,但是只是对 LRU 的一层封装,在复杂的业务场景下,LRU 淘汰策略显得力不从心。为此基于 W-TinyLFU(LFU+LRU算法的变种) 淘汰策略的进程内缓存 —— Caffeine Cache 诞生了。也就是说Caffeine与GuavaCache相比,在功能基本一致的情况下,通过对算法和部分逻辑的优化完成了对性能和缓存命中率的提升。
基本用法
构建缓存对象
与GuavaCache基本上没有太大区别,都是通过builder方式进行构建,设置过期方式,刷新时间,统计信息等。但是在使用LoadingCache设置自动加载缓存时,若为空,GuavaCache会抛错,caffeine直接返回null值。
//--自动填充--
LoadingCache cache = Caffeine.newBuilder()
.build(key -> load());
//缓存数据来源
public String load(){
return null;
}
System.out.println(cache.get("key1")); //直接返回空
//--手动填充--
Cache cache2 = Caffeine.newBuilder().build();
//先从缓存中查询,1.缓存中能找到,直接返回,2.找不到调用自定义的方法返回
Integer age2 = cache2.get("张三",k->{
//在实际业务中这里可以把我们代码中的mapper传入进去,进行数据源的刷新。
return 18;
});
System.out.println(age2);
//--异步手动填充--
AsyncCache cache = Caffeine.newBuilder().buildAsync();
//会返回一个 future对象, 调用future对象的get方法会一直卡住直到得到返回,和多线程的submit一样
CompletableFuture ageFuture = cache.get("张三", name -> {
System.out.println("name:" + name);
return 18;
});
Integer age = ageFuture.get();
System.out.println("age:" + age); 缓存清除
Caffeine的缓存清除是惰性的,可能发生在读请求后或者写请求后,比如说有一条数据过期后,不会立即删除,需要下一次读/写操作后触发删除。与GuavaCache一样,Caffeine的缓存清除也有三种:
-
基于大小
有两种方式,一种是基于内存的大小,一种是基于权重,基于内存大小的清除设置,设置基于内存大小的清除缓存,会使用maximumSize指定缓存大小,当超过该阀值会使用W-TinyLFU算法来淘汰掉最近很久没有被访问的或不常被使用的数据。示例如下:
//基于设置的内存大小清除缓存
Cache cache5 = Caffeine.newBuilder().maximumSize(1)
.build();
cache5.put("测试1", "test1");
cache5.put("测试2", "test2");
cache5.cleanUp();
System.out.println(cache5.getIfPresent("测试1"));
System.out.println(cache5.getIfPresent("测试2")); -
基于时间
expireAfterWrite:在最后一次写入缓存后开始计时,在指定时间后过期:
Cache cache6 = Caffeine.newBuilder().maximumSize(1).
expireAfterWrite(2,TimeUnit.MINUTES)
.build();
cache6.put("test1","1");
Thread.sleep(1*1000);
System.out.println(cache.getIfPresent("test1")); //还存在值
Thread.sleep(1*1000);
System.out.println(cache.getIfPresent("test1")); //缓存过期,返回null
Thread.sleep(1*1000);
System.out.println(cache.getIfPresent("test1")); //缓存过期,返回null
最后的结果:在第二次时打印null -
基于引用
expireAfterAccess:在最后一次读或写之前开始计时,在指定时间后若没有没有访问引用到这个值才会过期:
Cache cache7 = Caffeine.newBuilder()
// 最大容量为1
.maximumSize(1)
.expireAfterAccess(2, TimeUnit.SECONDS) //设置2秒后无访问引用过期
.build();
cache7.put("1","test1");
Thread.sleep(1*1000);
System.out.println(cache7.getIfPresent("1")); //线程等待1秒后访问,返回test1
Thread.sleep(1*1000);
System.out.println(cache7.getIfPresent("1")); //线程等待1秒后访问,返回test1
Thread.sleep(3001);
System.out.println(cache7.getIfPresent("1")); //线程等待3秒后超过过期时间且无访问,返回null -
显式回收
除了设置过期时间来将时间范围内未被访问的缓存项删除之外,还能通过以下方法将缓存显式删除,功能与guavaCache相同,分成
-
使用Cache.invalidate(key)单个移除;
-
使用Cache.invalidteAll(keys)批量移除;
-
使用Cache.invalidateAll()移除全部。
两种缓存接口
与GuavaCache相同,也是会有Cache和支持自定义加载方式的LoadingCache两种。
更新缓存
refreshAfterWrite:设置创建缓存 或者 最近一次更新缓存后指定时间刷新缓存,在业务项目中因为一些配置数据的变更会对返回的结果有影响所以常用该参数设置 更新配置后刷新缓存的时间。
@PostConstruct
public void init() {
sellerIdAndParkCodeCache = Caffeine.newBuilder()
.refreshAfterWrite(5, TimeUnit.MINUTES) //5分钟更新
.build(key -> refreshCache());
}缓存刷新
缓存刷新有两种方式,refreshAfterWrite和expireAfterWrite。两者都是在每次更新之后的指定时间让缓存失效,然后重新加载缓存。
expireAfterWrite:会严格限制只有1个线程在进行加载操作,旧值会被删除,其他线程会阻塞等待这个线程加载操作完成后,释放锁,然后他们获取锁在拿到更新后的值,能保证数据的准确性但是对性能有损耗。
refreshAfterWrite:会严格限制只有1个线程在进行加载操作异步刷新,旧值不会被删除,其他线程先返回旧值,这样能减少锁等待,但是因为不能保证每一次的加载都获得新值,会造成加载失败后会拿到旧值的问题,不能保证数据的准确性。
结论:对于互联网高并发的场景,refreshAfterWrites这种使用异步刷新缓存的方法应该是我们首先考虑的,取到一个过期的旧值总比大量线程全都被block要好,不然可能会导致请求大量堆积,连接数不够等一些列问题。
分布式缓存
本地缓存是与业务系统耦合在一起,不同应用直接无法共享缓存内容,每个应用需要维护自己的缓存,分布式缓存自身就是一个独立的多个应用可以共享缓存,常见的分布式缓存有redis,MemCached等。
Redis
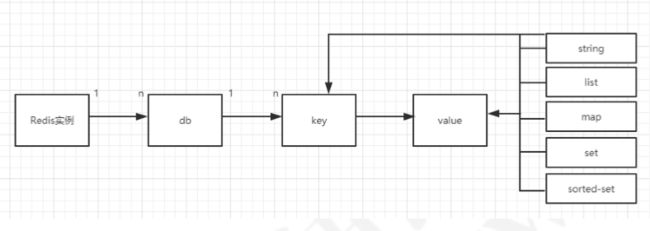
redis也是一个单进程单线程的KV的数据结构的缓存中间件,用集群部署、主从同步实现读写分离,还可用来做分布式锁,使用setnx获取锁,expire给锁加上过期时间,数据结构如下:
持久机制
redis为内存数据库,数据保存在内存中,为防止变化和丢失,redis有持久化机制AOF和RDB(默认)。
-
RDB
数据以快照的形式保存,在指定时间间隔内将内存中的数据集快照写入磁盘,在fork子进程执行写入期间,其余线程会阻塞直到RDB完成为止,性能高,但是在子进程持久化时,父进程修改的数据不会被保存。
-
ADF
使用日志记录,redis将收到的每一个写命令使用write函数追加到文件中,保证数据不会丢失,但随着数据量的变大,日志文件也会相应变大。所以一般持久化机制是两者都用,先用RDB快速恢复后用AOF数据补全。
淘汰机制
在 Redis 当中,还是使用的LRU算法,但是对传统的LRU算法做了改进,因为传统的 LRU 算法存在 2 个问题:
-
需要额外的空间进行存储。
-
可能存在某些 key 值使用很频繁,但是最近没被使用,从而被 LRU 算法删除。
为了避免以上 2 个问题,Redis 当中对传统的 LRU 算法进行了改造,通过抽样的方式进行删除。配置文件中提供了一个属性 maxmemory_samples 5,默认值就是 5,表示随机抽取 5 个 key 值,然后对这 5 个 key 值按照 LRU 算法进行删除,(也就是随机抽5个值,删除这个5个值中 最近最少 被使用的)所以很明显,key 值越大,删除的准确度越高。对抽样 LRU 算法和传统的 LRU 算法,Redis 官网当中有一个对比图:
-
浅灰色带是被删除的对象。
-
灰色带是未被删除的对象。
-
绿色是添加的对象。
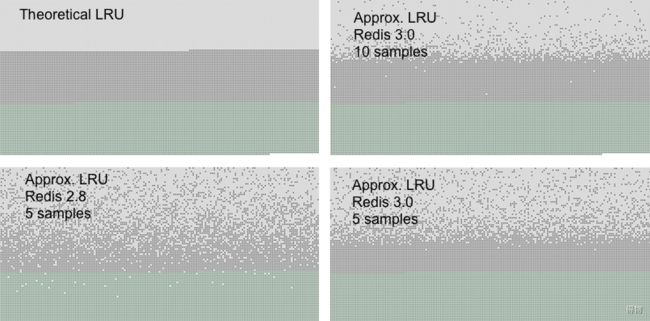
左上角第一幅图代表传统 LRU 算法,可以看到当抽样数达到 10个(右上角),已经和传统的 LRU 算法非常接近了。
常见用法
Redis官方推荐的面向Java的操作Redis的客户端是Jedis,但spring提供的redisTemplate完成了对JedisApi的封装,使用更加简单,redis支持String、List、Set、Hash、sortedSet五种数据类型,redisTemplate封装了对这五种数据类型的操作。
redisTemplate.opsForValue();//操作字符串
redisTemplate.opsForHash();//操作hash
redisTemplate.opsForList();//操作list
redisTemplate.opsForSet();//操作set
redisTemplate.opsForZSet();//操作有序set引入依赖
org.springframework.boot
spring-boot-starter-data-redis
基本服务
@Service
public class RedisServiceImpl implements CacheService {
@Resource
private RedisTemplate redisTemplate;
//获取值--String类型
@Override
public String getFromString(String key) {
return redisTemplate.opsForValue().get(key);
}
//设置值和对应的过期时间
@Override
public void setString(String key, String value, Long timeout) {
redisTemplate.opsForValue().set(key, value, timeout, TimeUnit.SECONDS);
}
//删除
@Override
public boolean delString(String key) {
return redisTemplate.delete(key);
}
//获取值--Hash类型
@Override
public void put(String HKey, String key, Object str) {
redisTemplate.opsForHash().put(HKey, key, str);
}
//设置hash类型的值对应的过期时间
@Override
public void expire(String HKey, long time) {
redisTemplate.expire(HKey, time, TimeUnit.SECONDS);
}
//获取k为传入的key对应的值
@Override
public List 双写一致性
从理论上来说,给缓存设置过期时间,是保证数据库与缓存最终一致性的解决方案。这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
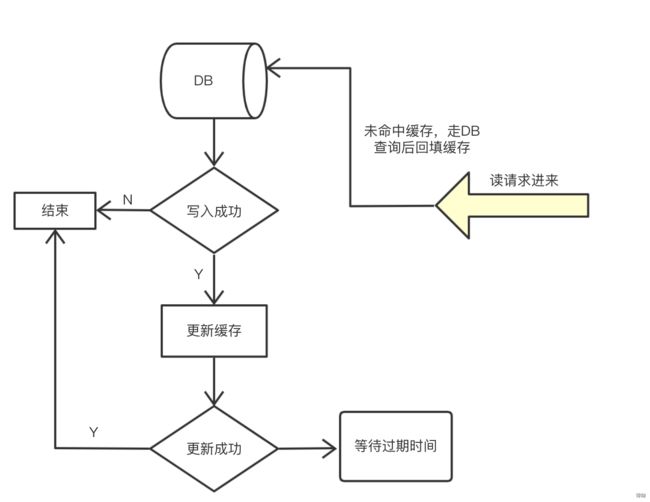
当未设置过期时间时,常用以下三种:
-
先更新数据库,再更新缓存;
-
先删除缓存,再更新数据库;
-
先更新数据库,再删除缓存。
常见问题
缓存击穿
指大并发下操作热点数据,该数据在缓存中无法查询(一般是缓存时间到),导致大并发量的请求直接进入DB,造成数据库巨大的压力。解决方案如下:
-
热点数据永不过期,缺点:无法识别热点数据且浪费存储空间,不推荐;
-
互斥锁,使用redis分布式锁,只有一个线程去查DB,其余线程阻塞等待,等当前线程查到数据并放入缓存后,其余线程都可以从缓存中取。缺点:只能针对于同一个key的情况。
缓存雪崩
缓存整体出现错误,大批量缓存数据过期不能正常工作,所有请求都到DB中,导致服务挂掉。解决方案如下:
-
使用redis的哨兵集群模式实现redis集群的高可用,监听主从服务器的状态,当master宕机后自动将slave切换成master,发布订阅通知其他从服务器;或采用多机房部署,将热点数据分布在不同的缓存数据库中;
-
过期时间加上一个随机值,防止过期时间集中;
-
采用多级缓存;
缓存穿透
上游不断的发起请求在缓存和DB中都查不到的数据,造成数据库压力,例如一些恶意攻击,在一些订单报表页面,伪造一些不存在的订单号然后并发请求页面的查询接口,这些数据在缓存和数据库都查不到,容易造成服务超时甚至宕机。解决方案如下:
-
恶意输入在前端或请求查询前提前拦截,如输入订单号、id这些肯定不会为负数的字段,添加<=0的条件提前过滤
-
通过布隆过滤器。查询缓存之前先去布隆过滤器查询下这个数据是否存在。如果数据不存在,然后直接返回空。这样的话也会减少底层系统的查询压力;
总结
对于不同的业务场景,缓存有各自不同的用法。具体还需要结合业务场景,毕竟只有具体的业务,没有通用的方法。
文|帕琪
关注得物技术,携手走向技术的云端