计算语言学国际会议 COLING 2022 是计算语言学和自然语言处理领域的重要国际会议,由国际计算语言学委员会(International Committee on Computational Linguistics,ICCL)主办。
有道 AI 在机器翻译方向的研究论文,被 COLING2022 以长文形式正式录用发表。
题目:Semantically Consistent Data Augmentation for Neural Machine Translation via Conditional Masked Language Model
作者:程桥,黄瑾,段亦涛
论文全文请见文末「阅读原文」
研究背景
神经机器翻译(NMT)通常需要大量的双语平行语料进行训练,在小数据的训练集上非常容易过拟合。高质量的双语平行语料比较难获取,通常人工标注语料需要较高的成本。数据增强方法是一种有效扩充数据规模的技术,并且在一些领域取得了显著的效果。比如在视觉领域,训练数据通常会使用诸如裁剪,翻转,弯曲或者颜色变换等方法来扩充。
虽然数据增强方法在视觉领域成为了训练神经网络模型的一项基本的技术,但是在自然语言处理领域,这项技术还没有得到很好的应用。
本论文主要研究了神经机器翻译(NMT)中使用词替换进行数据增强的技术,词替换技术通过替换现有的平行语料库句对中的词汇达到数据扩充的目的。在使用数据增强方法时,我们观察到增强的数据样本如果保留了正确的标签信息,那么就可以有效扩充训练的数据规模,从而提升模型的效果。这个属性我们称为语义一致性(semantic consistency)。
在神经机器翻译系统中,训练数据是以句对形式存在的,包含源端句子和目标端句子。语义一致性要求源端和目标端的句子在各自的语言中都是流利的且语法正确的,同时还要求目标端句子应该是源端句子的高质量翻译。
现有的词替换方法通常是对源端和目标端句子中的单词进行交换、删除或随机的替换。由于自然语言处理的离散性,这些变换不能保持语义的一致性,通常它们可能会削弱双语句子的流畅性或者破坏句对之间的关联性。
我们可以看一个案例:

这个例子是英德平行语料库中的一对句子和一些对英文端进行词替换得到的句子。Case 1 和 2 都是有问题的替换方式,前者虽然与替换的词保持了同样的意思,但在语法上是不正确的,后者虽然语法正确,但和德语句子不是互译的关系了。Case 3因为是一个语法正确,语义也保持一致,所以是一个好的增强样本。
在生成增强数据的过程中,利用上下文和标签信息可以实现更好的增强效果。我们引入了条件掩码语言模型(CMLM) 用于机器翻译的数据增强。掩码语言模型可以同时利用句内双向上下文信息,而 CMLM 是它的一个增强版本,它可以利用更多的标签信息。我们展示了 CMLM 可以通过迫使源端和目标端在进行词替换时保持语义一致性,从而能够生成更好的替换词分布。
此外,为了增强多样性,我们结合了软性数据增强(Soft Cotextual Data Augmentation)方法,这个方法使用词表上的一个分布来替换具体的词。
论文中提出的方法在4个不同规模的数据集上进行了实验,结果都表明该方法相比于之前的词替换技术更有效,翻译质量更高。
方法介绍
我们的目标是改进机器翻译训练中的数据增强方法,使得在增强的过程中,可以保留源句和目标句的语义以及它们之间的跨语言互译关系。
为达到这个目标,我们引入了条件掩码语言模型(CMLM) ,它可以生成上下文相关的替换词分布,从中我们可以选择给定单词最好的替代词。CMLM模型是MLM的一个变种形式,它在预测掩码时会结合标签信息。
在机器翻译场景中,CMLM遵循两点要求:
- 预测掩码时会同时以源端和目标端为条件;
- 在CMLM训练时,只会掩蔽源端的部分词或目标端的部分词,但不会同时掩蔽源端和目标端。
实际训练中可以拼接源端和目标端句子,然后随机掩蔽15%的源端单词,训练一个CMLM去预测掩蔽的源端单词。同样,也可以随机掩蔽15%的目标端单词,训练一个的CMLM基于拼接的双语句子去预测掩蔽的目标端单词。这种依赖双语信息预测某一端掩蔽词的特点是使用CMLM预测词做数据增强能够保持语义一致性的关键。
当使用上述方法训练好CMLM模型后,就可以用来扩充训练用的双语语料了。对于训练的双语语料,掩蔽源端或目标端的某些词,使用CMLM预测出可能候选词的分布,然后在分布中采样某个词替换掉对应位置的词。
由于 CMLM 同时结合了源端和目标端的信息,模型预测的词能很好地保持双语的语义一致性。这种直接替换的方法是比较费时的,如果需要减少采样的方差,就需要生成足够多的候选。为了提升这里的效率,我们结合了软性数据增强的方法。
软性数据增强不采样具体的词,而是根据预测的分布计算在词表上的词向量期望,使用这种软性的词向量替换真实的词向量表示。软性的词向量表示这样计算:

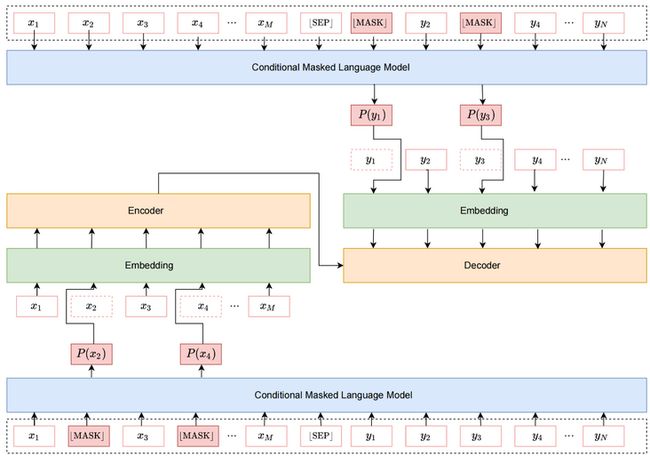
在神经机器翻译训练中使用 CMLM 做数据增强架构如下图所示。这里有两个独立的 CMLM,分别用来增强源端和目标端。我们使用预训练的多语言 BERT 初始化 CMLM,使用前述方法进行微调。在翻译模型训练过程中,CMLM 部分参数固定不动,按一定概率使用 CMLM 生成的软性词向量替换真实的词向量参与机器翻译模型的训练。我们探索了不同替换概率对翻译模型质量的影响。
实验及结果
为了验证论文提出的方法的效果,我们在三个较小规模的数据集:包括IWSLT2014 德语、西班牙语、希伯来语翻译到英语,及一个较大规模的数据集:WMT14 英语翻译到德语,进行了实验验证。
我们将此方法与其他几种数据增强方法进行了比较,包括一些规则的词替换方法,例如单词交换、删除、随机替换,以及两个利用语言模型进行替换的方法。我们还将论文中的方法与句子级增强方法 mixSeq 进行了比较。我们的基线系统是没有使用任何数据增强的系统。
为了对比,我们使用CMLM进行了两组数据增强实验:第一组使用前文描述的软性词向量替换的方法,第二种使用传统的采样替换方法,替换词根据CMLM的预测采样产生。
两种方法都同时应用到源端和目标端,并且使用相同的掩码概率gamma = 0.25,这是我们发现的最优配置。
实验结果如下图所示:

从表格中的结果可以看出,两种使用CMLM做数据增强的方法都显著优于基线系统,其中CMLM软性词向量增强的方法在所有任务上都取得了最优的结果。特别是在 WMT 英译德上取得了 1.9 BLEU 的提升。
除了在公共语料库上的实验,我们还将该方法应用到有道翻译的线上系统中。有道线上翻译系统(http://fanyi.youdao.com)使用近亿句对语料训练,模型大小接近5亿参数量,并使用了多种优化方法,在多个测试集上优于其他产品。在这样领先的商业机器翻译系统上,我们的方法也取得了显著的提升效果。
实际应用
自2007年推出网易有道词典以来,有道 AI 团队持续多年在机器翻译技术上发力。2017年推出有道神经网络翻译引擎(YNMT),使得翻译质量得到质的飞跃。
除网易有道词典之外,有道神经网络翻译技术已经应用于有道翻译官、有道少儿词典、U-Dictionary 等丰富的学习类工具 App 当中,为不同需求的用户提供高质量、可信赖的翻译和语言学习服务。
除软件外,YNMT 技术也已应用于有道词典笔、有道智能学习灯、有道 AI 学习机、有道听力宝等多款智能学习硬件中,并针对硬件产品进行了高性能、低功耗的定制化设计,实现了「 毫秒级点查 」、「 0.5s 指尖查词」等核心功能。

基于自研的 AI 核心技术,结合对学习场景的深刻理解,网易有道已经开拓学习硬件与工具、素养类课程、大学与职场课程、教育信息化等多种业务,致力于帮助用户实现高效学习。未来,有道 AI 会继续进行前沿技术的前瞻性研究,并推动其在产品和真实场景中的落地。
论文全文请见 「阅读原文」:
阅读原文