Hadoop完全分布式(开发重点)
开发重点,Hadoop完全分布式搭建
1. 将hadoop100上的拷贝到101和102上
2. ssh免密登录
3. 集群配置
4. 制作并使用xsync分发脚本(可忽略)
5. 群起集群并测试
1. 将hadoop100上的拷贝到101和102上
(1)scp(secure copy)安全拷贝
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
(3)案例实操(可以从hadoop100上推到101和102上,对应下列(a)操作,也可以在101和102上从hadoop100上拉取,对应下列(b)操作,其实a,b任选一个即可)
(a)在hadoop100上,将hadoop100中/opt/module/jdk1.8.0_212目录拷贝到hadoop101,hadoop102上。
# 都在hadoop100上操作,将jdk和hadoop分别推给101和102
sudo scp -r jdk1.8.0_212/ [用户名]@hadoop101:/opt/module
sudo scp -r hadoop-3.1.3/ [用户名]@hadoop101:/opt/module
sudo scp -r jdk1.8.0_212/ [用户名]@hadoop102:/opt/module
sudo scp -r hadoop-3.1.3/ [用户名]@hadoop102:/opt/module注意:这个地方可能会报一个错误说没有权限,那么我们需要登录到目标机器上也就是101上,修改权限。102同理
sudo chmod 777 module
sudo chmod 777 software(b)在hadoop101和102上,将hadoop100中/opt/module/hadoop-3.1.3目录拷贝到hadoop101,102上。
# 在hadoop101上操作,将100上的jdk和hadoop拉了过来
scp -r [用户名]@hadoop100:/opt/module/hadoop-3.1.3 ./
scp -r [用户名]@hadoop100:/opt/module/hadoop-3.1.3 ./
# 在hadoop102上操作,将100上的jdk和hadoop拉了过来
scp -r [用户名]@hadoop100:/opt/module/hadoop-3.1.3 ./
scp -r [用户名]@hadoop100:/opt/module/hadoop-3.1.3 ./2. ssh免密登录
(1)免密登录原理
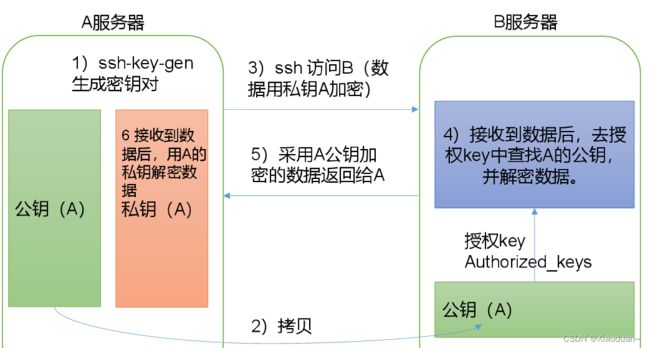
(2)生成公钥和私钥
ssh-keygen -t rsa然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop100
ssh-copy-id hadoop101
ssh-copy-id hadoop102注意:
还需要在hadoop103上配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop104上配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop102上配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
(4).ssh文件夹下(~/.ssh)的文件功能解释
| known_hosts |
记录ssh访问过计算机的公钥(public key) |
| id_rsa |
生成的私钥 |
| id_rsa.pub |
生成的公钥 |
| authorized_keys |
存放授权过的无密登录服务器公钥 |
3. 集群配置
(1)集群部署规划
注意:
1. NameNode和SecondaryNameNode不要安装在同一台服务器
2. ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop100 |
hadoop101 |
hadoop102 |
|
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
(2)配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 要获取的默认文件 |
文件存放在Hadoop的jar包中的位置 |
| [core-default.xml] |
hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] |
hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] |
hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] |
hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
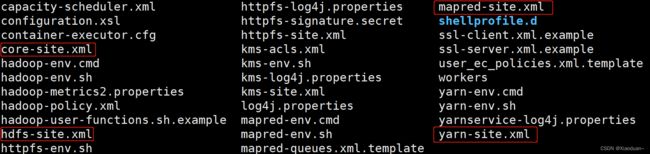
(3)配置集群
(1)核心配置文件:配置core-site.xml
cd /opt/module/hadoop-3.1.3/etc/hadoop
vim core-site.xml
# 配置内容如下
fs.defaultFS
hdfs://hadoop100:8020
hadoop.tmp.dir
/opt/module/hadoop-3.1.3/data
hadoop.http.staticuser.user
[用户名]
(2) HDFS配置文件:配置hdfs-site.xml
cd /opt/module/hadoop-3.1.3/etc/hadoop
vim hdfs-site.xml
dfs.namenode.http-address
hadoop100:9870
dfs.namenode.secondary.http-address
hadoop102:9868
(3)YARN配置文件: 配置yarn-site.xml
cd /opt/module/hadoop-3.1.3/etc/hadoop
vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop101
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
(4)MapReduce配置文件:配置mapred-site.xml
默认是在本地运行,通过自定义的配置让mapredece在YARN的资源调度下运行
cd /opt/module/hadoop-3.1.3/etc/hadoop
vim mapred-site.xml
mapreduce.framework.name
yarn
目前我们只是在hadoop100上将自定义的文件进行了配置,而101和102上并没有,那么我们需要将配置好的文件分别分发到101和102上。
(5)配置workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers 
注意:这个配置文件中,千万不要又空格或者空行
4. 制作并使用xsync分发脚本(如果大家想要在每个机子上自己手动修改这四个配置文件,那么可以忽略这一步,只是为了简便操作)
我们期望写一个xsync的脚本,在任何路径下都可以使用,也就是全局的环境变量,那么我们只需要打印看一下全局的环境变量都有哪些,然后找一个目录下边进行创建即可。
查看所有的全局环境变量: echo $PATH
![]()
发现在我们的用户目录下即可
脚本实现:
在/home/[用户名]/bin目录下创建xsync文件
cd /home/[用户名]
mkdir bin
cd bin
vim xsync在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop100 hadoop101 hadoop102
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done# 修改脚本 xsync 具有执行权限
chmod +x xsync
# 测试脚本,同步分发一个bin目录尝试一下,这个自定义的命令能不能使用
xsync /home/[用户名]/bin
*! 注意此时的xsync命令虽然可以分发,但是如果一些需要传输权限的为文件还没有解决
同步分发脚本做完以后,将我们刚才在hadoop100上修改的配置文件同时分发到101和102服务器上。同时把修改的workers也分发给每个机器
# 分发修改完的hadoop配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
# 查看是否分发成功,在101和102机子上输入
cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
# 分发修改完的workers
xsync /opt/module/hadoop-3.1.3/etc5. 群起集群并测试
(1)启动集群
1)如果集群是第一次启动,需要在hadoop100节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
# 格式化namenode
hdfs namenode -format2)启动HDFS:进入到hadoop-3.1.3目录下执行 sbin/start-dfs.sh
注意:再此启动阶段报了错如下图:
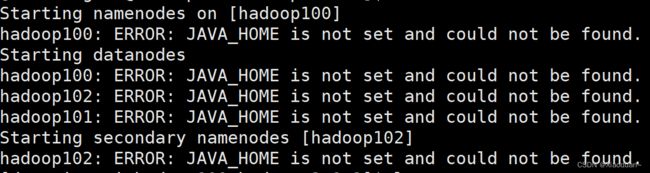
明明已经配置了jdk呀,每个机子也都能查到,如果小伙伴们碰到了同样问题
解决方法:
在hadoop-env.sh中,再显示地重新声明一遍JAVA_HOME
![]()
 成功!!!
成功!!!
(3)Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop100:9870
(b)查看HDFS上存储的数据信息
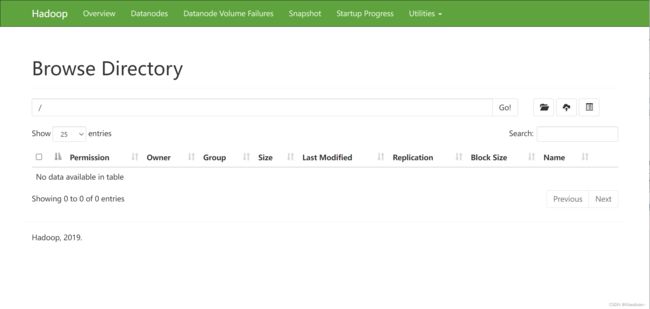
(4)在配置了ResourceManager的节点(hadoop101)启动YARN: sbin/start-yarn.sh
(5)Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop101:8088
(b)查看YARN上运行的Job信息

当我们设置完成了以后可以跟我们得需求图对比一下:
| hadoop100 |
hadoop101 |
hadoop102 |
|
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
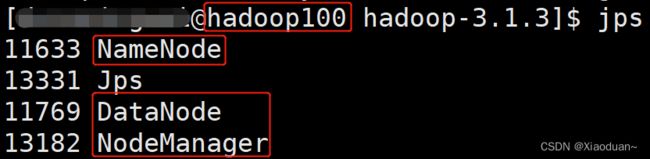
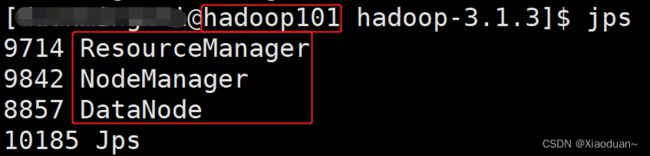
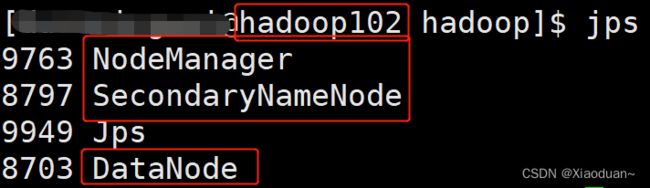
(2)集群基本测试
1)上传文件到集群
# 在根目录下创建一个input
hadoop fs -mkdir /wcinput
# 把word.txt上传上去
hadoop fs -put /opt/module/hadoop-3.1.3/wcinput/word.txt /wcinput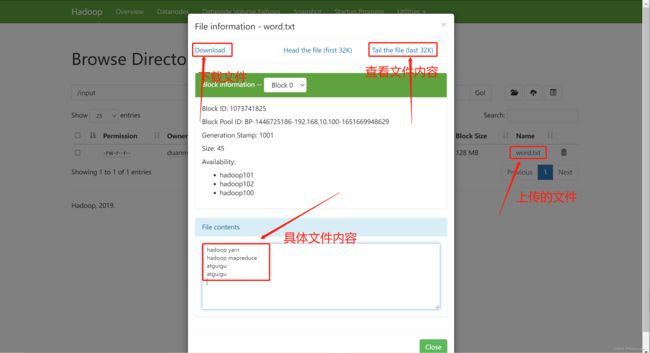
那么这只是一个页面的显示,而实际的数据是存储在这个路径下的。
 3)执行wordcount程序(还是以wordcount为例,只不过这次我们使用集群的方式)
3)执行wordcount程序(还是以wordcount为例,只不过这次我们使用集群的方式)
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output注意这个地方在使用集群的方式运行wordcount的时候又又又出错了,报错信息如下图
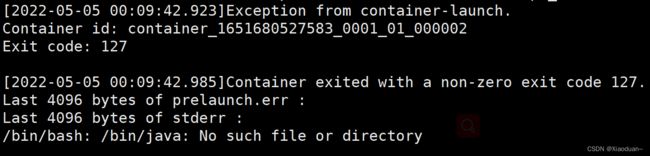
这个提示也很明显说java环境不好使了,提供一下我得解决办法
cd etc/hadoop
vim hadoop-env.sh
# 添加一个全局的java环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_212 